【yolov3详解】一文让你读懂yolov3目标检测原理
yolov3目标检测原理目录
-
- 前言
- 一、详细过程
- 二、yolov3检测流程原理(重点)
-
- 第一步:从特征获取预测结果
- 第二步:预测结果的解码
- 第三步:对预测出的边界框得分排序与非极大抑制筛选
前言
本文是自己在b站视频讲解学习,并且查阅理解许多文章后,做的通俗理解与总结,欢迎评论交流。
yolov3检测分两步:
1、确定检测对象位置
2、对检测对象分类(是什么东西)
即在识别图片是什么的基础上,还需定位识别对象的位置,并框出。
我们首先上一幅图宏观理解下

图中的红框是通过在yolov3检测最后得出的边界框(bounding box),又如下图的黄色框也是边界框

yolov3处理图片过程如下
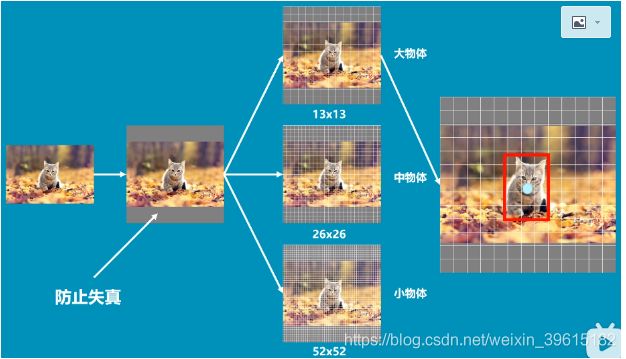
首先一张图片传进yolo,yolo会将其转化为416×416大小的网格,增加灰度条用于防止失真,之后图片会分成三个网格图片(13×13,26×26,52×52)
一、详细过程
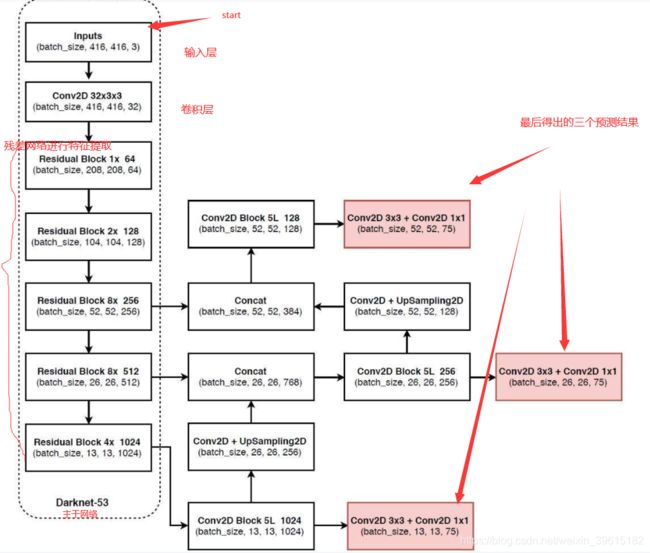
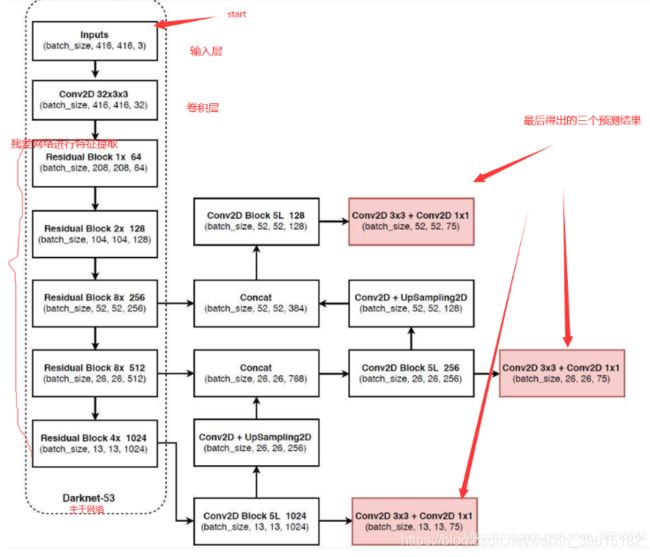
先上流程图,该图是基于voc数据集讲解的,voc数据集有20个类别,最下面红框中(13,13,75)表示预测结果的shape,实际上是13,13,3×25,表示有13*13的网格,每个网格有3个先验框(又称锚框,anchors,先验框下面有解释),每个先验框有25个参数(20个类别+5个参数),这5个参数分别是x_offset、y_offset、height、width与置信度confidence,用这3个框去试探,试探是否框中有物体,如果有,就会把这个物体给框起来。如果是基于coco的数据集就会有80种类别,最后的维度应该为3x(80+5)=255,最上面两个预测结果shape同理
yolov3主干网络为Darknet53,重要的是使用了残差网络Residual,darknet53的每一个卷积部分使用了特有的DarknetConv2D结构,每一次卷积的时候进行l2正则化,完成卷积后进行BatchNormalization标准化与LeakyReLU激活函数
对应代码如下:
#--------------------------------------------------#
# 单次卷积
#--------------------------------------------------#
@wraps(Conv2D)
def DarknetConv2D(*args, **kwargs):
darknet_conv_kwargs = {
'kernel_regularizer': l2(5e-4)}
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2,2) else 'same'
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)
#---------------------------------------------------#
# 卷积块
# DarknetConv2D + BatchNormalization + LeakyReLU
#---------------------------------------------------#
def DarknetConv2D_BN_Leaky(*args, **kwargs):
no_bias_kwargs = {
'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),# 调用单次卷积函数进行正则化
BatchNormalization(), # 标准化
LeakyReLU(alpha=0.1)) # 激活函数
讲解流程之前的基本概念了解一下,后面不记得回来再看看
x_offset:表示网格左上角相对x轴的距离(偏移量)
y_offset:表示网格左上角相对y轴的距离(偏移量)
上采样:缩小图像(或称为下采样(subsampled),如池化)的主要目的有两个:1、使得图像符合显示区域的大小;2、生成对应图像的缩略图。放大图像(或称为上采样(upSampling)或图像插值(interpolating))的主要目的是放大原图像,从而可以显示在更高分辨率的显示设备上。
先验框(anchor box):就是帮助我们定好了常见目标的宽和高,在进行预测的时候,我们可以利用这个已经定好的宽和高来进行处理,可以帮助我们进行预测,作用就是辅助处理x_offset、y_offset、h和w。如下图所示,用的是coco数据集,输出是(13,13,(80+5)*3),乘3表示,有3个先验框,每个先验框都有85个参数,下图就有3个蓝色框,也即先验框,可以理解成给你的建议框,识别的对象可能在这些建议框中,目的是带你得到更高的IOU,即更高置信度、更可能有对象得部分,黄色框为真实最后显示的边界框,红色框表示中心位置。

置信度(confidence):就是预测的先验框和真实框ground truth box(真实对象的框)的IOU值,即先验框是否有对象的概率Pr(Object),如进行人脸识别,一张图中有房子,树,车,人等,识别时背景和人的身体都没有脸这个需要识别的对象,那么这些地方的置信度就是0,框中的人脸越多,置信度(有对象概率)就越大,置信度是检测中非常重要的参数
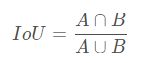
IOU表示交并比
为什么要使用残差(Residual)神经网络?
答:网络越深,梯度消失的现象就越来越明显,网络的训练效果也不会很好。残差神经网络就是为了在加深网络的情况下又解决梯度消失的问题。残差结构可以不通过卷积,直接从前面一个特征层映射到后面的特征层(跳跃连接),有助于训练,也有助于特征的提取,容易优化。
二、yolov3检测流程原理(重点)
第一步:从特征获取预测结果
1、yolov3提取多特征层进行目标检测,一共提取三个特征层,三个特征层位于主干特征提取网络darknet53的不同位置,分别位于中间层,中下层,底层,三个特征层的shape分别为(52,52,256)、(26,26,512)、(13,13,1024),这三个特征层后面用于与上采样后的其他特征层堆叠拼接(Concat)
2、第三个特征层(13,13,1024)进行5次卷积处理(为了特征提取),处理完后一部分用于卷积+上采样UpSampling,另一部分用于输出对应的预测结果(13,13,75),Conv2D 3×3和Conv2D1×1两个卷积起通道调整的作用,调整成输出需要的大小。
3、卷积+上采样后得到(26,26,256)的特征层,然后与Darknet53网络中的特征层(26,26,512)进行拼接,得到的shape为(26,26,768),再进行5次卷积,处理完后一部分用于卷积上采样,另一部分用于输出对应的预测结果(26,26,75),Conv2D 3×3和Conv2D1×1同上为通道调整
4、之后再将3中卷积+上采样的特征层与shape为(52,52,256)的特征层拼接(Concat),再进行卷积得到shape为(52,52,128)的特征层,最后再Conv2D 3×3和Conv2D1×1两个卷积,得到(52,52,75)特征层
最后图中有三个红框原因就是有些物体相对在图中较大,就用13×13检测,物体在图中比较小,就会归为52×52来检测
第二步:预测结果的解码
预测结果解码原因:预测结果(红框)并不对应着最终的预测框在图片上的位置,还需要解码)
yolov3的预测原理是分别将整幅图分为13x13、26x26、52x52的网格,每个网络点负责一个区域的检测。解码过程就是计算得出最后显示的边界框的坐标bx,by,以及宽高bw,bh,这样就得出了边界框的位置,计算过程如图(b–为bounding box 缩写)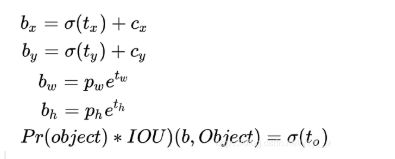
(cx,cy):该点所在网格的左上角距离最左上角相差的格子数。
(pw,ph):先验框的边长
(tx,ty):目标中心点相对于该点所在网格左上角的偏移量
(tw,th):预测边框的宽和高
σ:激活函数,论文作者用的是sigmoid函数,[0,1]之间概率,之所以用sigmoid取代之前版本的softmax,原因是softmax会扩大最大类别概率值而抑制其他类别概率值 ,图解如下 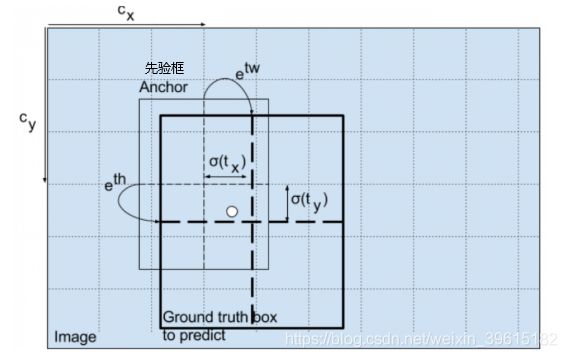
注:最终得到的边框坐标值是bx,by,bw,bh.而网络学习目标是tx,ty,tw,th。
另外cy向下此处为正向
第三步:对预测出的边界框得分排序与非极大抑制筛选
得分排序与非极大抑制筛选
这步就是将最大概率的框筛选出来
1、取出每一类得分大于一定阈值的框和得分进行排序。
2、利用框的位置和得分进行非极大抑制。最后可以得出概率最大的边界框,也就是最后显示出的框
如下几幅图,一步步筛选得到最终边界框

找到第一个

找到第二个

以上就是全过程啦,希望对点开阅读的你有帮助。
参考博客与视频讲解:
https://blog.csdn.net/paoxungan5156/article/details/99578828
https://blog.csdn.net/weixin_45755332/article/details/107874775
https://blog.csdn.net/weixin_44791964/article/details/103276106
https://www.bilibili.com/video/BV1XJ411D7wF
有兴趣可以看我这两篇博文练练玩玩yolov3:
1、yolov3检测和平精英视频中人物及物体
2、yolov3+keras训练自己的模型并预测
3、yolov4-keras实现抽烟检测