Flink学习之环境搭建,项目结构
1.Flink安装准备
-
Flink 是一个以 Java 及 Scala 作为开发语言的开源大数据项目,代码开源在 GitHub 上,并使用 Maven 来编译和构建项目。对于大部分使用 Flink 的同学来说,Java、Maven 和 Git 这三个工具是必不可少的,另外一个强大的 IDE 有助于我们更快的阅读代码、开发新功能以及修复 Bug。因为篇幅所限,我们不会详述每个工具的安装细节,但会给出必要的安装建议。
-
关于开发测试环境,Mac OS、Linux 系统或者 Windows 都可以。如果使用的是 Windows 10 系统,建议使用 Windows 10 系统的 Linux 子系统来编译和运行。
-
工具 注释 Java Java8以上 Maven 必须使用Maven3以上版本 Git Flink 的代码仓库是: https://github.com/apache/flink
2.Flink代码编译,安装
-
可以在Git上下载源码以后直接用IDE编译,编译生成的三个文件需要留意
版本 注释 flink-1.10.0.tar.gz Binary的压缩包 flink-1.10.0-bin/flink-1.10.0 解压后的 Flink binary 目录 flink-dist_2.11-1.10.0.jar 包含 Flink 核心功能的 jar 包 -
目前公司环境是从官网下载的binary包安装完成
3.Flink运行
1.单机standalone运行
1.基本启动流程
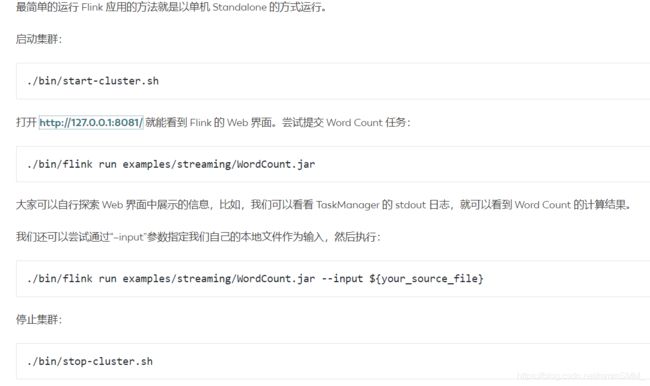

2.常用配置需求
conf / slaves
conf / slaves 用于配置 TaskManager 的部署,默认配置下只会启动一个 TaskManager 进程,如果想增加一个 TaskManager 进程的,只需要文件中追加一行“localhost”。
也可以直接通过“ ./bin/taskmanager.sh start ”这个命令来追加一个新的 TaskManager:
conf/flink-conf.yaml
conf/flink-conf.yaml 用于配置 JM 和 TM 的运行参数
3.日志查看需求
JobManager 和 TaskManager 的启动日志可以在 Flink binary 目录下的 Log 子目录中找到。Log 目录中以“flink-{id}-${hostname}”为前缀的文件对应的是 JobManager 的输出,其中有三个文件:
- flink- u s e r − s t a n d a l o n e s e s s i o n − {user}-standalonesession- user−standalonesession−{id}-${hostname}.log:代码中的日志输出
- flink- u s e r − s t a n d a l o n e s e s s i o n − {user}-standalonesession- user−standalonesession−{id}-${hostname}.out:进程执行时的stdout输出
- flink- u s e r − s t a n d a l o n e s e s s i o n − {user}-standalonesession- user−standalonesession−{id}-${hostname}-gc.log:JVM的GC的日志
Log 目录中以“flink-{id}-${hostname}”为前缀的文件对应的是 TaskManager 的输出,也包括三个文件,和 JobManager 的输出一致。
日志的配置文件在 Flink binary 目录的 conf 子目录下,其中:
- log4j-cli.properties:用 Flink 命令行时用的 log 配置,比如执行“ flink run”命令
- log4j-yarn-session.properties:用 yarn-session.sh 启动时命令行执行时用的 log 配置
- log4j.properties:无论是 Standalone 还是 Yarn 模式,JobManager 和 TaskManager 上用的 log 配置都是 log4j.properties
这三个“log4j.*properties”文件分别有三个“logback.*xml”文件与之对应,如果想使用 Logback 的同学,之需要把与之对应的“log4j.*properties”文件删掉即可,对应关系如下:
- log4j-cli.properties -> logback-console.xml
- log4j-yarn-session.properties -> logback-yarn.xml
- log4j.properties -> logback.xml
需要注意的是,“flink-{id}-和{user}-taskexecutor-{hostname}”都带有“,{id}”表示本进程在本机上该角色(JobManager 或 TaskManager)的所有进程中的启动顺序,默认从 0 开始。
2.使用Yarn模式运行FlinkJob
1.优点
相对于 Standalone 模式,Yarn 模式允许 Flink job 的好处有:
-
资源按需使用,提高集群的资源利用率
-
任务有优先级,根据优先级运行作业
-
基于 Yarn 调度系统,能够自动化地处理各个角色的 Failover
○ JobManager 进程和 TaskManager 进程都由 Yarn NodeManager 监控
○ 如果 JobManager 进程异常退出,则 Yarn ResourceManager 会重新调度 JobManager 到其他机器
○ 如果 TaskManager 进程异常退出,JobManager 会收到消息并重新向 Yarn ResourceManager 申请资源,重新启动 TaskManager
2.目前提交方式------Job Cluster 模式
./bin/flink run -m yarn-cluster -yn 2 examples/streaming/WordCount.jar --input hdfs:*****
output hdfs:*******
常用的配置有:
- -yn,–yarncontainer Number of Task Managers
- -yqu,–yarnqueue Specify YARN queue.
- -ys,–yarnslots Number of slots per TaskManager
- -yqu,–yarnqueue Specify YARN queue.
以下为Flink各个模块之间的层级关系

作为软件堆栈,Flink是一个分层系统。堆栈的不同层构建在彼此之上,并提高它们接受的程序表示的抽象级别:
- 运行层(runtime layer)以JobGraph的形式接收程序。JobGraph是一个通用的并行数据流,具有消费和产生数据流的任意任务。
- DataStream API和DataSet API都通过单独的编译过程生成JobGraphs。DataSet API使用优化器来确定程序的最佳计划,而DataStream API使用流构建器。
- JobGraph根据Flink中提供的各种部署选项执行(例如,本地,远程,YARN等)
- 与Flink捆绑在一起的库和API生成DataSet或DataStream API程序。这些是用于基于逻辑表的查询,用于机器学习的FlinkML和用于图形处理的Gelly。
新版本支持
Apache Flink 1.10.0 于 2020年02月11日正式发布。Flink 1.10 是一个历时非常长、代码变动非常大的版本,也是 Flink 社区迄今为止规模最大的一次版本升级,Flink 1.10 容纳了超过 200 位贡献者对超过 1200 个 issue 的开发实现,包含对 Flink 作业的整体性能及稳定性的显著优化、对原生 Kubernetes 的初步集成以及对 Python 支持(PyFlink)的重大优化。
托管内存扩展
扩展了托管内存,以解决RocksDBStateBackend的内存使用问题。虽然批处理作业可以使用堆上或堆外的内存,但是带有 RocksDBStateBackend的流作业只能使用堆上的内存。因此,为了允许用户在流执行和批处理执行之间切换而不必修改集群配置,托管内存现在始终处于堆外状态。
简化的RocksDB配置
配置像RocksDB这样的堆外状态后端曾经需要进行大量的手动调整,例如减小JVM堆大小或将Flink设置为使用堆外内存。现在可以通过Flink的现成配置来实现,调整“RocksDBStateBackend”的内存预算就像调整托管内存大小一样简单。
统一作业提交的逻辑
在Flink 1.10中,作业提交逻辑被抽象到通用的 Executor界面(FLIP-73[2])。附加的 ExecutorCLI(FLIP-81[3])引入了一种统一的方式来为 任何 执行目标指定配置参数。为了完善这项工作,结果检索的过程也与工作提交分离,引入了 JobClient(FLINK-74[4]),负责获取 JobExecutionResult。
Table API/SQL:生产就绪的Hive集成
Hive集成在Flink 1.9中宣布为预览功能。此第一个实现允许用户使用SQL DDL将特定于Flink的元数据保留在Hive Metastore中,调用在Hive中定义的UDF,并使用Flink读取和写入Hive表。Flink 1.10通过进一步的开发使这项工作更加完善,这些开发使Flink可以进行生产就绪的Hive集成。
批处理SQL的原生分区支持
到目前为止,仅支持对未分区的Hive表进行写入。在Flink 1.10中,Flink SQL语法已通过 INSERT OVERWRITE和 PARTITION进行了扩展(FLIP-63),使用户可以在Hive中写入静态和动态分区。
静态分区写入
||INSERT { INTO | OVERWRITE } TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;||
动态分区编写
||INSERT { INTO | OVERWRITE } TABLE tablename1 select_statement1 FROM from_statement;||
完全支持的分区表使用户可以利用读取时的分区修剪功能,通过减少需要扫描的数据量来显着提高这些操作的性能。
其他优化
除分区修剪外,Flink 1.10还为Hive集成引入了更多的读取优化,例如:
- 投影下推(Projection pushdown) : Flink通过省略表扫描中不必要的字段,利用投影下推来最大程度地减少Flink和Hive表之间的数据传输。这对于具有大量列的表尤其有利。
- LIMIT下推(LIMIT pushdown) :对于带有LIMIT子句的查询,Flink将尽可能限制输出记录的数量,以最大程度地减少通过网络传输的数据量。
- 读取时进行ORC矢量化(ORC Vectorization on Read) :可以提高ORC文件的读取性能,Flink现在默认使用本机ORC矢量化阅读器,用于高于2.0.0的Hive版本和具有非复杂数据类型的列。
Table API / SQL的其他改进
SQL DDL中的水印和计算列
Flink 1.10支持特定于流的语法扩展,以在Flink SQL DDL中定义时间属性和水印生成(FLIP-66[7])。这允许基于时间的操作(例如加窗)以及表上的水印策略的定义使用DDL语句创建的。

此版本还引入了对虚拟计算列的支持(FLIP-70[8])可以基于同一表中的其他列或确定性表达式(即字面值,UDF和内置函数)派生。在Flink中,计算列可用于定义创建表时的时间属性。
SQL DDL的其他扩展
现在,temporary/persistent和system/catalog函数之间有明显的区别(FLIP-57[9])。这不仅消除了函数引用中的歧义,而且允许确定性的函数解析顺序(即,在命名冲突的情况下,系统函数将在目录函数之前,而临时函数在这两个维度上都将优先于持久函数)。
遵循FLIP-57的基础,我们扩展了SQL DDL语法,以支持创建目录功能,临时功能和临时系统功能(FLIP-79[10]):

可插拔模块作为Flink系统对象(Beta)
Flink 1.10为Flink table core中的可插拔模块引入了一种通用机制,首先着眼于系统功能(FLIP-68[6])。使用模块,用户可以扩展Flink的系统对象,例如使用行为类似于Flink系统功能的Hive内置函数。此版本附带预先实现的“ HiveModule”,支持多个Hive版本,但用户也可以编写自己的可插拔模块。
4.Flink项目架构
├── flink-annotations 代码行数:108 Flink里面的一些注解
├── flink-clients 代码行数:7838
│ ├── pom.xml
│ └── src
├── flink-connectors 代码行数:52165 flink所有支持的连接器以及不同版本支持,经常用在source和sink
│ ├── flink-connector-cassandra
│ ├── flink-connector-elasticsearch2
│ ├── flink-connector-elasticsearch5
│ ├── flink-connector-elasticsearch6
│ ├── flink-connector-elasticsearch7
│ ├── flink-connector-elasticsearch-base
│ ├── flink-connector-filesystem
│ ├── flink-connector-gcp-pubsub
│ ├── flink-connector-hive
│ ├── flink-connector-kafka
│ ├── flink-connector-kafka-0.10
│ ├── flink-connector-kafka-0.11
│ ├── flink-connector-kafka-base
│ ├── flink-connector-kinesis
│ ├── flink-connector-nifi
│ ├── flink-connector-rabbitmq
│ ├── flink-connector-twitter
│ ├── flink-hadoop-compatibility
│ ├── flink-hbase
│ ├── flink-hcatalog
│ ├── flink-jdbc
│ ├── flink-sql-connector-elasticsearch6
│ ├── flink-sql-connector-elasticsearch7
│ ├── flink-sql-connector-kafka
│ ├── flink-sql-connector-kafka-0.10
│ ├── flink-sql-connector-kafka-0.11
│ └── pom.xml
├── flink-container flink job部署在Docker和kubernetes 容器上
│ ├── docker
│ ├── kubernetes
│ ├── pom.xml
│ └── src
├── flink-contrib 代码行数:421 用于新模块准备或者孵化的区域
│ ├── docker-flink
│ ├── flink-connector-wikiedits
│ ├── pom.xml
│ └── README.md
├── flink-core 代码行数:80561 api,资源分配,内存管理,配置等核心代码
│ ├── pom.xml
│ └── src
├── flink-dist 编译完成的flink在这里,bin目录和conf目录下的脚本配置在这里指定,比如启动、停止的一些脚本
│ ├── pom.xml
│ └── src
├── flink-docs 代码行数:593 创建HTML文件的生成器
│ ├── pom.xml
│ ├── README.md
│ └── src
├── flink-end-to-end-tests 代码行数:2039 一些例如es、kafka的测试类
│ ├── flink-batch-sql-test
│ ├── flink-bucketing-sink-test
│ ├── flink-cli-test
│ ├── flink-confluent-schema-registry
│ ├── flink-connector-gcp-pubsub-emulator-tests
│ ├── flink-dataset-allround-test
│ ├── flink-dataset-fine-grained-recovery-test
│ ├── flink-datastream-allround-test
│ ├── flink-distributed-cache-via-blob-test
│ ├── flink-elasticsearch5-test
│ ├── flink-elasticsearch6-test
│ ├── flink-elasticsearch7-test
│ ├── flink-end-to-end-tests-common
│ ├── flink-end-to-end-tests-common-kafka
│ ├── flink-heavy-deployment-stress-test
│ ├── flink-high-parallelism-iterations-test
│ ├── flink-local-recovery-and-allocation-test
│ ├── flink-metrics-availability-test
│ ├── flink-metrics-reporter-prometheus-test
│ ├── flink-parent-child-classloading-test-lib-package
│ ├── flink-parent-child-classloading-test-program
│ ├── flink-plugins-test
│ ├── flink-queryable-state-test
│ ├── flink-quickstart-test
│ ├── flink-rocksdb-state-memory-control-test
│ ├── flink-sql-client-test
│ ├── flink-state-evolution-test
│ ├── flink-streaming-file-sink-test
│ ├── flink-streaming-kafka010-test
│ ├── flink-streaming-kafka011-test
│ ├── flink-streaming-kafka-test
│ ├── flink-streaming-kafka-test-base
│ ├── flink-streaming-kinesis-test
│ ├── flink-stream-sql-test
│ ├── flink-stream-stateful-job-upgrade-test
│ ├── flink-stream-state-ttl-test
│ ├── flink-tpcds-test
│ ├── flink-tpch-test
│ ├── pom.xml
│ ├── README.md
│ ├── run-nightly-tests.sh
│ ├── run-pre-commit-tests.sh
│ ├── run-single-test.sh
│ └── test-scripts
├── flink-examples 代码行数:6018 flink流处理、批处理,table表的demo
│ ├── flink-examples-batch
│ ├── flink-examples-build-helper
│ ├── flink-examples-streaming
│ ├── flink-examples-table
│ └── pom.xml
├── flink-filesystems 代码行数:7190 flink支持的文件系统 Hadoop,mapr,s3,swift
│ ├── flink-azure-fs-hadoop
│ ├── flink-fs-hadoop-shaded
│ ├── flink-hadoop-fs
│ ├── flink-mapr-fs
│ ├── flink-oss-fs-hadoop
│ ├── flink-s3-fs-base
│ ├── flink-s3-fs-hadoop
│ ├── flink-s3-fs-presto
│ ├── flink-swift-fs-hadoop
│ └── pom.xml
├── flink-formats 代码行数:9187 flink格式化 avro,json,parquet等数据格式
│ ├── flink-avro
│ ├── flink-avro-confluent-registry
│ ├── flink-compress
│ ├── flink-csv
│ ├── flink-json
│ ├── flink-orc
│ ├── flink-orc-nohive
│ ├── flink-parquet
│ ├── flink-sequence-file
│ └── pom.xml
├── flink-fs-tests 代码行数:1592 文件系统测试类
│ ├── pom.xml
│ └── src
├── flink-java 代码行数:30106 flink里面例如flatMap、reduce等各种聚合计算方法、算子操作、数据格式输入输出
│ ├── pom.xml
│ └── src
├── flink-jepsen 一个基于Jepsen框架的Clojure项目,用于查找Apache Flink®分布式协调中的bug
│ ├── bin
│ ├── docker
│ ├── project.clj
│ ├── README.md
│ ├── src
│ └── test
├── flink-kubernetes 代码行数:4210 Blink才会有的,为了支持Flink在k8s上运行
│ ├── pom.xml
│ └── src
├── flink-libraries 代码行数:175695
│ ├── flink-cep 复杂时间编程
│ ├── flink-cep-scala
│ ├── flink-gelly Gelly是Flink的图形API。目前Java和Scala都支持它。Scala方法是作为基本Java操作之上的包装器实现的。该API包含一组用于图数据分析的实用函数,支持迭代图数据处理,并引入了一个图数据算法库
│ ├── flink-gelly-examples
│ ├── flink-gelly-scala
│ ├── flink-state-processing-api Apache Flink的状态处理器API为使用Flink的批数据集API读取、写入和修改保存点和检查点提供了强大的功能。由于数据集和表API的互操作性,甚至可以使用关系表API或SQL查询来分析和处理状态数据。
│ └── pom.xml
├── flink-mesos 代码行数:5543 支持flink在mesos运行
│ ├── pom.xml
│ └── src
├── flink-metrics 代码行数:3292 flink的metric
信息,支持各种dog,dropwizard,ganglia,graphilte,jmx,prometheus,slf4j,如果要对flink做监控,从这里入手
│ ├── flink-metrics-core
│ ├── flink-metrics-datadog
│ ├── flink-metrics-dropwizard
│ ├── flink-metrics-graphite
│ ├── flink-metrics-influxdb
│ ├── flink-metrics-jmx
│ ├── flink-metrics-prometheus
│ ├── flink-metrics-slf4j
│ ├── flink-metrics-statsd
│ └── pom.xml
├── flink-ml-parent 机器学习
│ ├── flink-ml-api
│ ├── flink-ml-lib
│ └── pom.xml
├── flink-optimizer 代码行数:25339 flink优化器,优化计算执行效率更高
│ ├── pom.xml
│ └── src
├── flink-python 新支持,python支持
│ ├── bin
│ ├── dev
│ ├── docs
│ ├── lib
│ ├── MANIFEST.in
│ ├── pom.xml
│ ├── pyflink
│ ├── README.md
│ ├── setup.cfg
│ ├── setup.py
│ ├── src
│ └── tox.ini
├── flink-queryable-state 代码行数:6276 flink状态管理机制
│ ├── flink-queryable-state-client-java
│ ├── flink-queryable-state-runtime
│ └── pom.xml
├── flink-quickstart 代码行数:32 在idea快速生成项目
│ ├── flink-quickstart-java
│ ├── flink-quickstart-scala
│ └── pom.xml
├── flink-runtime 270253 Flink RunTime是介于底层部署与DataSteamApi或DataSetApi之间的一层,以JobGraph形式接收程序,将任务task提交到集群上执行,RunTime层可以适用不同底层部署模式。
│ ├── pom.xml
│ └── src
├── flink-runtime-web 5302 flink任务webUI
│ ├── pom.xml
│ ├── README.md
│ ├── src
│ └── web-dashboard
├── flink-scala
│ ├── pom.xml
│ └── src
├── flink-scala-shell
│ ├── pom.xml
│ ├── src
│ └── start-script
├── flink-state-backends 代码行数:7992 flink状态管理存储位置,支持rocksdb
│ ├── flink-statebackend-heap-spillable
│ ├── flink-statebackend-rocksdb
│ └── pom.xml
├── flink-streaming-java 76105 流计算中的算子操作
│ ├── pom.xml
│ └── src
├── flink-streaming-scala
│ ├── pom.xml
│ └── src
├── flink-table flink sql相关
│ ├── flink-sql-client
│ ├── flink-sql-parser
│ ├── flink-table-api-java
│ ├── flink-table-api-java-bridge
│ ├── flink-table-api-scala
│ ├── flink-table-api-scala-bridge
│ ├── flink-table-common
│ ├── flink-table-planner
│ ├── flink-table-planner-blink
│ ├── flink-table-runtime-blink
│ ├── flink-table-uber
│ ├── flink-table-uber-blink
│ └── pom.xml
├── flink-tests 37499
│ ├── pom.xml
│ └── src
├── flink-test-utils-parent 3374
│ ├── flink-test-utils
│ ├── flink-test-utils-junit
│ └── pom.xml
├── flink-walkthroughs
│ ├── flink-walkthrough-common
│ ├── flink-walkthrough-datastream-java
│ ├── flink-walkthrough-datastream-scala
│ ├── flink-walkthrough-table-java
│ ├── flink-walkthrough-table-scala
│ └── pom.xml
├── flink-yarn 支持flink在yarn上运行
│ ├── pom.xml
│ └── src
├── flink-yarn-tests
│ ├── pom.xml
│ └── src