Python3,25行代码,清理电脑版微信重复缓存,电脑从此健步如飞,建议收藏!!
清理微信重复缓存
- 1、引言
- 2、glob模块
-
- 2.1 缓存路径介绍
-
- 2.1.1电脑端
- 2.1.2 手机端
- 2.2 glob介绍
-
- 2.2.1 通配符介绍
- 2.2.2 方法介绍
- 2.2.3 提升效率
- 2.3 crc32
- 3、代码实战
1、引言
小屌丝:鱼哥,磁盘多少钱?
小鱼:你想要啥样的:拼多多上的, 淘宝上的,京东上的,还是实体店里的?
小屌丝:我就是单纯的想把我的电脑增加点容量~何苦这么难为我??
小鱼:我记得你的电脑,不是刚增加不就,怎么又满了?
小屌丝:说的我那啥似的…我这都是微信缓存占的!
小鱼:说的像真的似的,如果不是微信缓存的原因,咋办?
小屌丝:你先处理完…再说~ ~
小鱼:这…整吧…
2、glob模块
2.1 缓存路径介绍
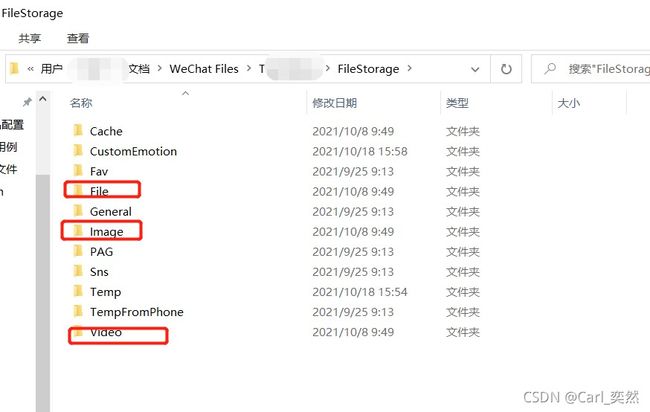
在介绍glob模块之前,我们先来说一下缓存的路径。
2.1.1电脑端
电脑端路径:
C:\Users\用户名\Documents\WeChat Files\微信名\FileStorage,
这是默认安装,存储的路径地址;
如果自定义安装,那地址另议。
2.1.2 手机端
手机端存储路径:
内部存储设备→Android→data→com.tecent.mm→MicroMsg→Download
这就拿Android手机举例;
2.2 glob介绍
2.2.1 通配符介绍
| 符号 | 功能 |
|---|---|
| * | 匹配0或多个字符 |
| ** | 匹配所有文件,目录,子目录和子目录里面的文件 |
| ? | 匹配一个字符,这里与正则表达式? (正则?匹配前面表达式0次或者1次) |
| [] | 匹配指定范围内的字符,如: [1-9]匹配1至9内的字符 |
| [!] | 匹配不在指定范围内的字符 |
2.2.2 方法介绍
1、当前文件下所有py路径:
#当前文件下所有py路径
for ftname in glob.glob("**/*.py",recursive=True):
print(f'文件输出结果为{
ftname}')
2、当前路径文件tmp下py文件
#当前路径文件tmp下py文件
for ftname in glob.glob("./tmp/*.py"):
print(f'文件输出结果为{
ftname}')
3、单字通配符?,当前路径文件下以file开头后有一个字符的py文件:
#当前路径文件下以file开头后有一个字符的py文件
for ftname in glob.glob("./file?.py"):
print(f'文件输出结果为{
ftname}')
4、范围通配符[],当前路径文件下以file开头后一个数字符的py文件:
#当前路径文件下以file开头后一个数字符的py文件
for ftname in glob.glob("./file[0-9].py"):
print(f'文件输出结果为{
ftname}')
5、范围通配符[],当前路径文件下以file开头后一个非数字符的py文件:
#当前路径文件下以file开头后一个非数字符的py文件
for ftname in glob.glob("./file[!0-9].py"):
print(f'文件输出结果为{
ftname}')
2.2.3 提升效率
小屌丝:鱼哥,你这返回的执行速度不够快啊!
小鱼:也对,鉴于你每天撩妹的信息量巨大,我要使用杀手锏。
鉴于小屌丝这种情况,我们就使用glob模块iglob, 返回iterator执行效率更高,代码如下:
#当前路径文件tmp下py文件,使用iglob,返回迭代器效率更高
for ftname in glob.iglob("./tmp/*.py"):
print(f'文件输出结果为{
ftname}')

2.3 crc32
- CRC32 算法概述 CRC 全称 Cyclic Redundancy Check,又叫循环冗余校验。
- 和 md5 码一样都是 hash 的。
- 当两个文件内容的 CRC32 相同的时候,这个文件也就是相同的。
- 反之,两个文件就是不同的文件。
编写代码
# -*- coding: utf-8 -*-
# @Time : 2021-10-17
# @Author : carl_DJ
def crc32(file_path):
with open(file_path, 'rb') as fh:
hash = 0
while True:
s = fh.read(1024)
if not s:
break
hash = zlib.crc32(s, hash)
return "%08X" % (hash & 0xFFFFFFFF)
3、代码实战
写代码之前,我们先捋一下思路,很简单,就三步:
- 第一步,使用glob进行全盘扫描文件
- 第二步,扫描的文件的crc32值放入字典中
- 第三步,删除字典中crc32的值
编写代码
# -*- coding: utf-8 -*-
# @Time : 2021-10-17
# @Author : carl_DJ
'''
1、使用glob.glob进行全盘文件扫描
2、把文件的crc32值放入字典中
3、删除字典中的crc32的值
'''
import os
import zlib
import glob
#扫描文件,并删除重复文件
def scan_floder(glob_path):
#设置一个空字典
crc32Dict = {
}
#查找当前路径下的文件
for ftname in glob.glob(glob_path,recursive=True):
if os.path.isfile(ftname):
#crc32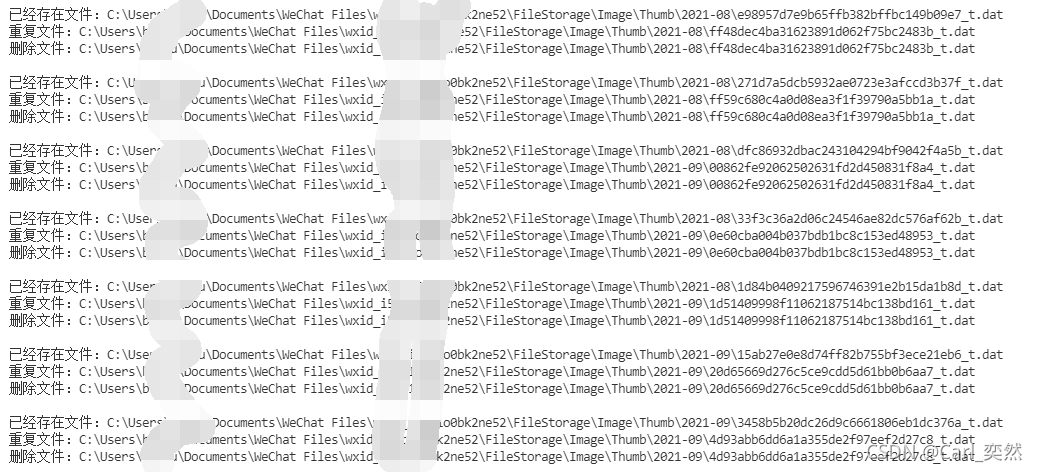
crc = crc32(ftname)
if crc in crc32Dict:
print(f'已经存在的文件:{
crc32Dict.get(crc)}')
print(f'重复文件:{
ftname}')
print(f'删除文件:{
ftname}')
#删除重复的文件
os.remove(ftname)
else:
crc32Dict[crc] = ftname
#把文件的crc32值存入到字典中
def crc32(file_path):
with open(file_path,'rb') as f:
hash = 0
while True:
s = f.read(1024)
if not s:
break
hash = zlib.crc32(s,hash)
return "%08X" %(hash & 0xFFFFFFFF)
if __name__ == '__main__':
scan_floder(r'C:\Users\用户名\Documents\WeChat Files\微信名称\FileStorage\xxx')
运行结果
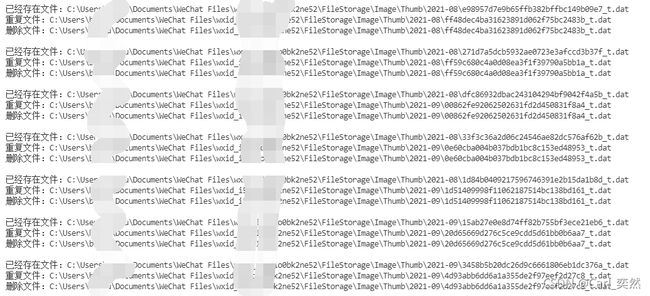
小屌丝:我去~ 可以啊鱼哥。
小鱼:必须的,是不是突然觉得腰不疼腿不酸,CUP运行可起劲了!
小屌丝:鱼哥,还是你懂我~ ~
小鱼:给你一个眼神,自己体会!

其实手机端跟电脑端的清理机制差不多, 只是路径不一样。
所以,手机版的,我就不展示了。
1.手机USB链接电脑,
2.代码中路径输入手机端的路径即可。