用 Python 分析了 6000 款 App,看看哪些神器你还没用过?
摘要: 如今移动互联网越来越发达,各式各样的 App 层出不穷,也就产生了优劣之分,相比于普通 App,我们肯定愿意去使用那些良心佳软,但去发现这些 App 并不太容易,本文使用 Scrapy 框架爬取了著名应用下载市场「酷安网」上的 6000 余款 App,通过分析,发现了各个类别领域下的佼佼者,这些 App 堪称真正的良心之作,使用它们将会给你带来全新的手机使用体验。
1. 分析背景
1.1. 为什么选择酷安
如果说 GitHub 是程序员的天堂,那么 酷安 则是手机 App 爱好者们(别称「搞机」爱好者)的天堂,相比于那些传统的手机应用下载市场,酷安有三点特别之处:
第一、可以搜索下载到各种 神器、佳软,其他应用下载市场几乎很难找得到。比如之前的文章中说过的终端桌面「Aris」、安卓最强阅读器「静读天下」、RSS 阅读器 「Feedme」 等。
第二、可以找到很多 App 的 破解版。我们提倡「为好东西付费」,但是有些 App 很蛋疼,比如「百度网盘」,在这里面就可以找到很多 App 的破解版。
第三、可以找到 App 的 历史版本。很多人喜欢用最新版本的 App,一有更新就马上升级,但是现在很多 App 越来越功利、越更新越臃肿、广告满天飞,倒不如 回归本源,使用体积小巧、功能精简、无广告的早期版本。
作为一名 App 爱好者,我在酷安上发现了很多不错的 App,越用越感觉自己知道的仅仅是冰山一角,便想扒一扒这个网站上到底有多少好东西,手动一个个去找肯定是不现实了,自然想到最好的方法——用爬虫来解决,为了实现此目的,最近就学习了一下 Scrapy 爬虫框架,爬取了该网 6000 款左右的 App,通过分析,找到了不同领域下的精品 App,下面我们就来一探究竟。
1.2. 分析内容
-
总体分析 6000 款 App 的评分、下载量、体积等指标。
-
根据日常使用功能场景,将 App 划分为:系统工具、资讯阅读、社交娱乐等 10 大类别,筛选出每个类别下的精品 App。
1.3. 分析工具
-
Python
-
Scrapy
-
MongoDB
-
Pyecharts
-
Matplotlib
2. 数据抓取
由于酷安手机端 App 设置了反扒措施,使用 Charles 尝试后发现无法抓包, 暂退而求其次,使用 Scrapy 抓取网页端的 App 信息。抓取时期截止到 2018 年 11 月 23日,共计 6086 款 App,共抓取 了 8 个字段信息:App 名称、下载量、评分、评分人数、评论数、关注人数、体积、App 分类标签。
2.1. 目标网站分析
这是我们要抓取的 目标网页,点击翻页可以发现两点有用的信息:
-
每页显示了 10 条 App 信息,一共有610页,也就是 6100 个左右的 App 。
-
网页请求是 GET 形式,URL 只有一个页数递增参数,构造翻页非常简单。
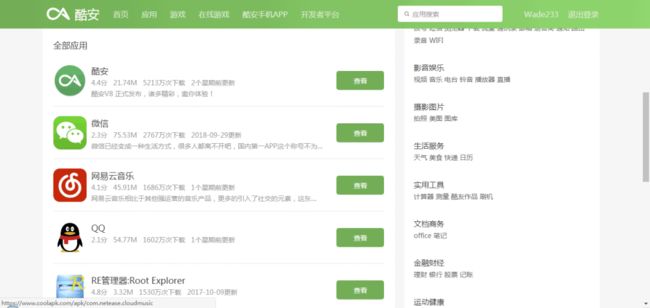
接下来,我们来看看选择抓取哪些信息,可以看到,主页面内显示了 App 名称、下载量、评分等信息,我们再点击 App 图标进入详情页,可以看到提供了更齐全的信息,包括:分类标签、评分人数、关注人数等。由于,我们后续需要对 App 进行分类筛选,故分类标签很有用,所以这里我们选择进入每个 App 主页抓取所需信息指标。
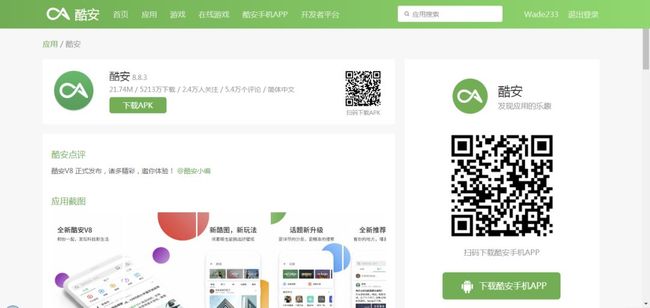
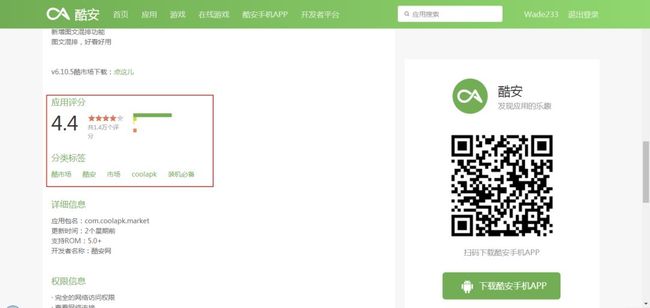
通过上述分析,我们就可以确定抓取流程了,首先遍历主页面 ,抓取 10 个 App 的详情页 URL,然后详情页再抓取每个 App 的指标,如此遍历下来,我们需要抓取 6000 个左右网页内容,抓取工作量不算小,所以,我们接下来尝试使用 Scrapy 框架进行抓取。
2.2. Scrapy 框架介绍
介绍 Scrapy 框架之前,我们先回忆一下 Pyspider 框架,我们之前使用它爬取了 虎嗅网 5 万篇文章 ,它是由国内大神编写的一个爬虫利器, Github Star 超过 10K,但是它的整体功能还是相对单薄一些,还有比它更强大的框架么?有的,就是这里要说的 Scrapy 框架,Github Star 超过 30K,是 Python 爬虫界使用最广泛的爬虫框架,玩爬虫这个框架必须得会。
网上关于 Scrapy 的官方文档和教程很多,这里罗列几个。
Scrapy 中文文档
崔庆才的 Scrapy 专栏
Scrapy 爬拉勾
Scrapy 爬豆瓣电影
Scrapy 框架相对于 Pyspider 相对要复杂一些,有不同的处理模块,项目文件也由好几个程序组成,不同的爬虫模块需要放在不同的程序中去,所以刚开始入门会觉得程序七零八散,容易把人搞晕,建议采取以下思路快速入门 Scrapy:
-
首先,快速过一下上面的参考教程,了解 Scrapy 的爬虫逻辑和各程序的用途与配合。
-
接着,看上面两个实操案例,熟悉在 Scrapy 中怎么写爬虫。
-
最后,找个自己感兴趣的网站作为爬虫项目,遇到不懂的就看教程或者 Google。
这样的学习路径是比较快速而有效的,比一直抠教程不动手要好很多。下面,我们就以酷安网为例,用 Scrapy 来爬取一下。
2.3. 抓取数据
首先要安装好 Scrapy 框架,如果是 Windwos 系统,且已经安装了 Anaconda,那么安装 Scrapy 框架就非常简单,只需打开 Anaconda Prompt 命令窗口,输入下面一句命令即可,会自动帮我们安装好 Scrapy 所有需要安装和依赖的库。
1conda pip scrapy
2.3.1. 创建项目
接着,我们需要创建一个爬虫项目,所以我们先从根目录切换到需要放置项目的工作路径,比如我这里设置的存放路径为:E:\my_Python\training\kuan,接着继续输入下面一行代码即可创建 kuan 爬虫项目:
1# 切换工作路径
2e:
3cd E:\my_Python\training\kuan
4# 生成项目
5scrapy startproject kuspider
执行上面的命令后,就会生成一个名为 kuan 的 scrapy 爬虫项目,包含以下几个文件:
1scrapy. cfg # Scrapy 部署时的配置文件
2kuan # 项目的模块,需要从这里引入
3_init__.py
4items.py # 定义爬取的数据结构
5middlewares.py # Middlewares 中间件
6pipelines.py # 数据管道文件,可用于后续存储
7settings.py # 配置文件
8spiders # 爬取主程序文件夹
9_init_.py
下面,我们需要再 spiders 文件夹中创建一个爬取主程序:kuan.py,接着运行下面两行命令即可:
1cd kuan # 进入刚才生成的 kuan 项目文件夹
2scrapy genspider kuan www.coolapk.com # 生成爬虫主程序文件 kuan.py
2.3.2. 声明 item
项目文件创建好以后,我们就可以开始写爬虫程序了。
首先,需要在 items.py 文件中,预先定义好要爬取的字段信息名称,如下所示:
1class KuanItem(scrapy.Item):
2# define the fields for your item here like:
3name = scrapy.Field()
4volume = scrapy.Field()
5download = scrapy.Field()
6follow = scrapy.Field()
7comment = scrapy.Field()
8tags = scrapy.Field()
9score = scrapy.Field()
10num_score = scrapy.Field()
这里的字段信息就是我们前面在网页中定位的 8 个字段信息,包括:name 表示 App 名称、volume 表示体积、download 表示下载数量。在这里定义好之后,我们在后续的爬取主程序中会利用到这些字段信息。
2.3.3. 爬取主程序
创建好 kuan 项目后,Scrapy 框架会自动生成爬取的部分代码,我们接下来就需要在 parse 方法中增加网页抓取的字段解析内容。
1class KuanspiderSpider(scrapy.Spider):
2 name = 'kuan'
3 allowed_domains = ['www.coolapk.com']
4 start_urls = ['http://www.coolapk.com/']
5
6 def parse(self, response):
7 pass
打开主页 Dev Tools,找到每项抓取指标的节点位置,然后可以采用 CSS、Xpath、正则等方法进行提取解析,这些方法 Scrapy 都支持,可随意选择,这里我们选用 CSS 语法来定位节点,不过需要注意的是,Scrapy 的 CSS 语法和之前我们利用 pyquery 使用的 CSS 语法稍有不同,举几个例子,对比说明一下。
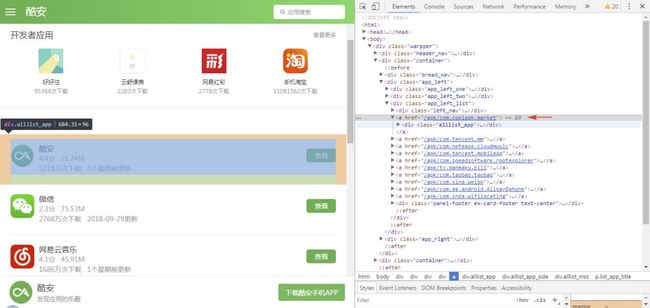
首先,我们定位到第一个 APP 的主页 URL 节点,可以看到 URL 节点位于 class 属性为 app_left_list 的 div 节点下的 a 节点中,其 href 属性就是我们需要的 URL 信息,这里是相对地址,拼接后就是完整的 URL。
接着我们进入酷安详情页,选择 App 名称并进行定位,可以看到 App 名称节点位于 class 属性为 .detail_app_title 的 p 节点的文本中。
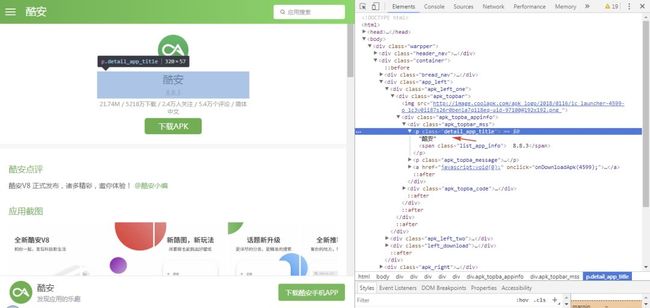
定位到这两个节点之后,我们就可以使用 CSS 提取字段信息了,这里对比一下常规写法和 Scrapy 中的写法:
1# 常规写法
2url = item('.app_left_list>a').attr('href')
3name = item('.list_app_title').text()
4# Scrapy 写法
5url = item.css('::attr("href")').extract_first()
6name = item.css('.detail_app_title::text').extract_first()
可以看到,要获取 href 或者 text 属性,需要用 :: 表示,比如获取 text,则用 ::text。extract_first() 表示提取第一个元素,如果有多个元素,则用 extract() 。接着,我们就可以参照写出 8 个字段信息的解析代码。
首先,我们需要在主页提取 App 的 URL 列表,然后再进入每个 App 的详情页进一步提取 8 个字段信息。
1def parse(self, response):
2 contents = response.css('.app_left_list>a')
3 for content in contents:
4 url = content.css('::attr("href")').extract_first()
5 url = response.urljoin(url) # 拼接相对 url 为绝对 url
6 yield scrapy.Request(url,callback=self.parse_url)
这里,利用 response.urljoin() 方法将提取出的相对 URL 拼接为完整的 URL,然后利用 scrapy.Request() 方法构造每个 App 详情页的请求,这里我们传递两个参数:url 和 callback,url 为详情页 URL,callback 是回调函数,它将主页 URL 请求返回的响应 response 传给专门用来解析字段内容的 parse_url() 方法,如下所示:
1def parse_url(self,response):
2 item = KuanItem()
3 item['name'] = response.css('.detail_app_title::text').extract_first()
4 results = self.get_comment(response)
5 item['volume'] = results[0]
6 item['download'] = results[1]
7 item['follow'] = results[2]
8 item['comment'] = results[3]
9 item['tags'] = self.get_tags(response)
10 item['score'] = response.css('.rank_num::text').extract_first()
11 num_score = response.css('.apk_rank_p1::text').extract_first()
12 item['num_score'] = re.search('共(.*?)个评分',num_score).group(1)
13 yield item
14
15def get_comment(self,response):
16 messages = response.css('.apk_topba_message::text').extract_first()
17 result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages) # \s+ 表示匹配任意空白字符一次以上
18 if result: # 不为空
19 results = list(result[0]) # 提取出list 中第一个元素
20 return results
21
22def get_tags(self,response):
23 data = response.css('.apk_left_span2')
24 tags = [item.css('::text').extract_first() for item in data]
25 return tags
这里,单独定义了 get_comment() 和 get_tags() 两个方法.
get_comment() 方法通过正则匹配提取 volume、download、follow、comment 四个字段信息,正则匹配结果如下:
1result = re.findall(r'\s+(.*?)\s+/\s+(.*?)下载\s+/\s+(.*?)人关注\s+/\s+(.*?)个评论.*?',messages)
2print(result) # 输出第一页的结果信息
3# 结果如下:
4[('21.74M', '5218万', '2.4万', '5.4万')]
5[('75.53M', '2768万', '2.3万', '3.0万')]
6[('46.21M', '1686万', '2.3万', '3.4万')]
7[('54.77M', '1603万', '3.8万', '4.9万')]
8[('3.32M', '1530万', '1.5万', '3343')]
9[('75.07M', '1127万', '1.6万', '2.2万')]
10[('92.70M', '1108万', '9167', '1.3万')]
11[('68.94M', '1072万', '5718', '9869')]
12[('61.45M', '935万', '1.1万', '1.6万')]
13[('23.96M', '925万', '4157', '1956')]
然后利用 result[0]、result[1] 等分别提取出四项信息,以 volume 为例,输出第一页的提取结果:
1item['volume'] = results[0]
2print(item['volume'])
321.74M
475.53M
546.21M
654.77M
73.32M
875.07M
992.70M
1068.94M
1161.45M
1223.96M
这样一来,第一页 10 款 App 的所有字段信息都被成功提取出来,然后返回到 yied item 生成器中,我们输出一下它的内容:
1[
2{'name': '酷安', 'volume': '21.74M', 'download': '5218万', 'follow': '2.4万', 'comment': '5.4万', 'tags': "['酷市场', '酷安', '市场', 'coolapk', '装机必备']", 'score': '4.4', 'num_score': '1.4万'},
3{'name': '微信', 'volume': '75.53M', 'download': '2768万', 'follow': '2.3万', 'comment': '3.0万', 'tags': "['微信', 'qq', '腾讯', 'tencent', '即时聊天', '装机必备']",'score': '2.3', 'num_score': '1.1万'},
4...
5]
2.3.4. 分页爬取
以上,我们爬取了第一页内容,接下去需要遍历爬取全部 610 页的内容,这里有两种思路:
-
第一种是提取翻页的节点信息,然后构造出下一页的请求,然后重复调用 parse 方法进行解析,如此循环往复,直到解析完最后一页。
-
第二种是先直接构造出 610 页的 URL 地址,然后批量调用 parse 方法进行解析。
这里,我们分别写出两种方法的解析代码,第一种方法很简单,直接接着 parse 方法继续添加以下几行代码即可:
1def parse(self, response):
2 contents = response.css('.app_left_list>a')
3 for content in contents:
4 ...
5
6 next_page = response.css('.pagination li:nth-child(8) a::attr(href)').extract_first()
7 url = response.urljoin(next_page)
8 yield scrapy.Request(url,callback=self.parse )
第二种方法,我们在最开头的 parse() 方法前,定义一个 start_requests() 方法,用来批量生成 610 页的 URL,然后通过 scrapy.Request() 方法中的 callback 参数,传递给下面的 parse() 方法进行解析。
1def start_requests(self):
2 pages = []
3 for page in range(1,610): # 一共有610页
4 url = 'https://www.coolapk.com/apk/?page=%s'%page
5 page = scrapy.Request(url,callback=self.parse)
6 pages.append(page)
7 return pages
以上就是全部页面的爬取思路,爬取成功后,我们需要存储下来。这里,我面选择存储到 MongoDB 中,不得不说,相比 MySQL,MongoDB 要方便省事很多。
2.3.5. 存储结果
我们在 pipelines.py 程序中,定义数据存储方法,MongoDB 的一些参数,比如地址和数据库名称,需单独存放在 settings.py 设置文件中去,然后在 pipelines 程序中进行调用即可。
1import pymongo
2class MongoPipeline(object):
3 def __init__(self,mongo_url,mongo_db):
4 self.mongo_url = mongo_url
5 self.mongo_db = mongo_db
6 @classmethod
7 def from_crawler(cls,crawler):
8 return cls(
9 mongo_url = crawler.settings.get('MONGO_URL'),
10 mongo_db = crawler.settings.get('MONGO_DB')
11 )
12 def open_spider(self,spider):
13 self.client = pymongo.MongoClient(self.mongo_url)
14 self.db = self.client[self.mongo_db]
15 def process_item(self,item,spider):
16 name = item.__class__.__name__
17 self.db[name].insert(dict(item))
18 return item
19 def close_spider(self,spider):
20 self.client.close()
首先,我们定义一个 MongoPipeline()存储类,里面定义了几个方法,简单进行一下说明:
from crawler() 是一个类方法,用 @class method 标识,这个方法的作用主要是用来获取我们在 settings.py 中设置的这几项参数:
1MONGO_URL = 'localhost'
2MONGO_DB = 'KuAn'
3ITEM_PIPELINES = {
4 'kuan.pipelines.MongoPipeline': 300,
5}
open_spider() 方法主要进行一些初始化操作 ,在 Spider 开启时,这个方法就会被调用 。
process_item() 方法是最重要的方法,实现插入数据到 MongoDB 中。
完成上述代码以后,输入下面一行命令就可以开始整个爬虫的抓取和存储过程了,单机跑的话,6000 个网页需要不少时间才能完成,保持耐心。
1scrapy crawl kuan
这里,还有两点补充:
第一,为了减轻网站压力,我们最好在每个请求之间设置几秒延时,可以在 KuanSpider() 方法开头出,加入以下几行代码:
1custom_settings = {
2 "DOWNLOAD_DELAY": 3, # 延迟3s,默认是0,即不延迟
3 "CONCURRENT_REQUESTS_PER_DOMAIN": 8 # 每秒默认并发8次,可适当降低
4 }
第二,为了更好监控爬虫程序运行,有必要 设置输出日志文件,可以通过 Python 自带的 logging 包实现:
1import logging
2
3logging.basicConfig(filename='kuan.log',filemode='w',level=logging.WARNING,format='%(asctime)s %(message)s',datefmt='%Y/%m/%d %I:%M:%S %p')
4logging.warning("warn message")
5logging.error("error message")
这里的 level 参数表示警告级别,严重程度从低到高分别是:DEBUG < INFO < WARNING < ERROR < CRITICAL,如果想日志文件不要记录太多内容,可以设置高一点的级别,这里设置为 WARNING,意味着只有 WARNING 级别以上的信息才会输出到日志中去。
添加 datefmt 参数是为了在每条日志前面加具体的时间,这点很有用处。
以上,我们就完成了整个数据的抓取,有了数据我们就可以着手进行分析,不过这之前还需简单地对数据做一下清洗和处理。
3. 数据清洗处理
首先,我们从 MongoDB 中读取数据并转化为 DataFrame,然后查看一下数据的基本情况。
1def parse_kuan():
2 client = pymongo.MongoClient(host='localhost', port=27017)
3 db = client['KuAn']
4 collection = db['KuAnItem']
5 # 将数据库数据转为DataFrame
6 data = pd.DataFrame(list(collection.find()))
7 print(data.head())
8 print(df.shape)
9 print(df.info())
10 print(df.describe())
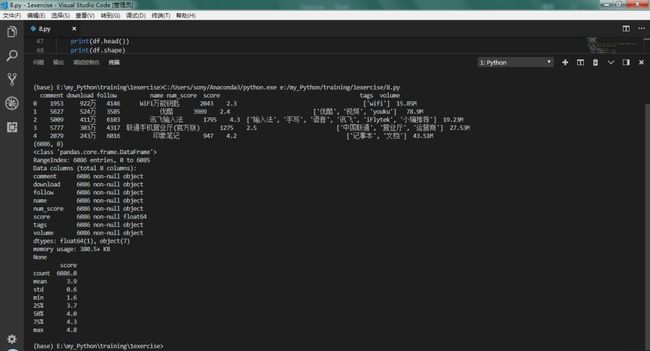
从 data.head() 输出的前 5 行数据中可以看到,除了 score 列是 float 格式以外,其他列都是 object 文本类型。
comment、download、follow、num_score 这 5 列数据中部分行带有「万」字后缀,需要将字符去掉再转换为数值型;volume 体积列,则分别带有「M」和「K」后缀,为了统一大小,则需将「K」除以 1024,转换为 「M」体积。
整个数据一共有 6086 行 x 8 列,每列均没有缺失值。
df.describe() 方法对 score 列做了基本统计,可以看到,所有 App 的平均得分是 3.9 分(5 分制),最低得分 1.6 分,最高得分 4.8 分。
下面,我们将以上几列文本型数据转换为数值型数据,代码实现如下:
1def data_processing(df):
2#处理'comment','download','follow','num_score','volume' 5列数据,将单位万转换为单位1,再转换为数值型
3 str = '_ori'
4 cols = ['comment','download','follow','num_score','volume']
5 for col in cols:
6 colori = col+str
7 df[colori] = df[col] # 复制保留原始列
8 if not (col == 'volume'):
9 df[col] = clean_symbol(df,col)# 处理原始列生成新列
10 else:
11 df[col] = clean_symbol2(df,col)# 处理原始列生成新列
12
13 # 将download单独转换为万单位
14 df['download'] = df['download'].apply(lambda x:x/10000)
15 # 批量转为数值型
16 df = df.apply(pd.to_numeric,errors='ignore')
17
18def clean_symbol(df,col):
19 # 将字符“万”替换为空
20 con = df[col].str.contains('万$')
21 df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('万','')) * 10000
22 df[col] = pd.to_numeric(df[col])
23 return df[col]
24
25def clean_symbol2(df,col):
26 # 字符M替换为空
27 df[col] = df[col].str.replace('M$','')
28 # 体积为K的除以 1024 转换为M
29 con = df[col].str.contains('K$')
30 df.loc[con,col] = pd.to_numeric(df.loc[con,col].str.replace('K$',''))/1024
31 df[col] = pd.to_numeric(df[col])
32 return df[col]
以上,就完成了几列文本型数据的转换,我们再来查看一下基本情况:
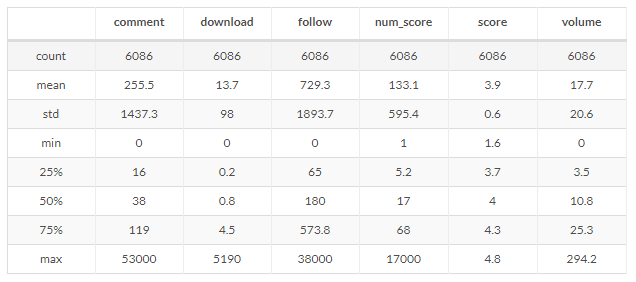
download 列为 App 下载数量,下载量最多的 App 有 5190 万次,最少的为 0 (很少很少),平均下载次数为 14 万次;从中可以看出以下几点信息:
-
volume 列为 App 体积,体积最大的 App 达到近 300M,体积最小的几乎为 0,平均体积在 18M 左右。
-
comment 列为 App 评分,评分数最多的达到了 5 万多条,平均有 200 多条。
以上,就完成了基本的数据清洗处理过程,下面将对数据进行探索性分析。
4. 数据分析
我们主要从总体和分类两个维度对 App 下载量、评分、体积等指标进行分析。
4.1. 总体情况
4.1.1. 下载量排名
首先来看一下 App 的下载量情况,很多时候我们下载一个 App ,下载量是一个非常重要的参考指标,由于绝大多数 App 的下载量都相对较少,直方图无法看出趋势,所以我们择将数据进行分段,离散化为柱状图,绘图工具采用的是 Pyecharts。
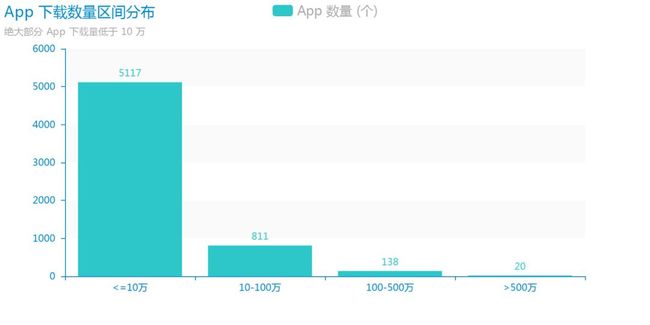
可以看到多达 5517 款(占总数 84%)App 的下载量不到 10 万, 而下载量超过 500 万的仅有 20 款,开发一个要想盈利的 App ,用户下载量尤为重要,从这一点来看,大部分 App 的处境都比较尴尬,至少是在酷安平台上。
代码实现如下:
1from pyecharts import Bar
2# 下载量分布
3bins = [0,10,100,500,10000]
4group_names = ['<=10万','10-100万','100-500万','>500万']
5cats = pd.cut(df['download'],bins,labels=group_names) # 用 pd.cut() 方法进行分段
6cats = pd.value_counts(cats)
7bar = Bar('App 下载数量区间分布','绝大部分 App 下载量低于 10 万')
8# bar.use_theme('macarons')
9bar.add(
10 'App 数量 (个)',
11 list(cats.index),
12 list(cats.values),
13 is_label_show = True,
14 is_splitline_show = False,
15)
16bar.render(path='download_interval.png',pixel_ration=1)
接下来,我们看看 下载量最多的 20 款 App 是哪些:
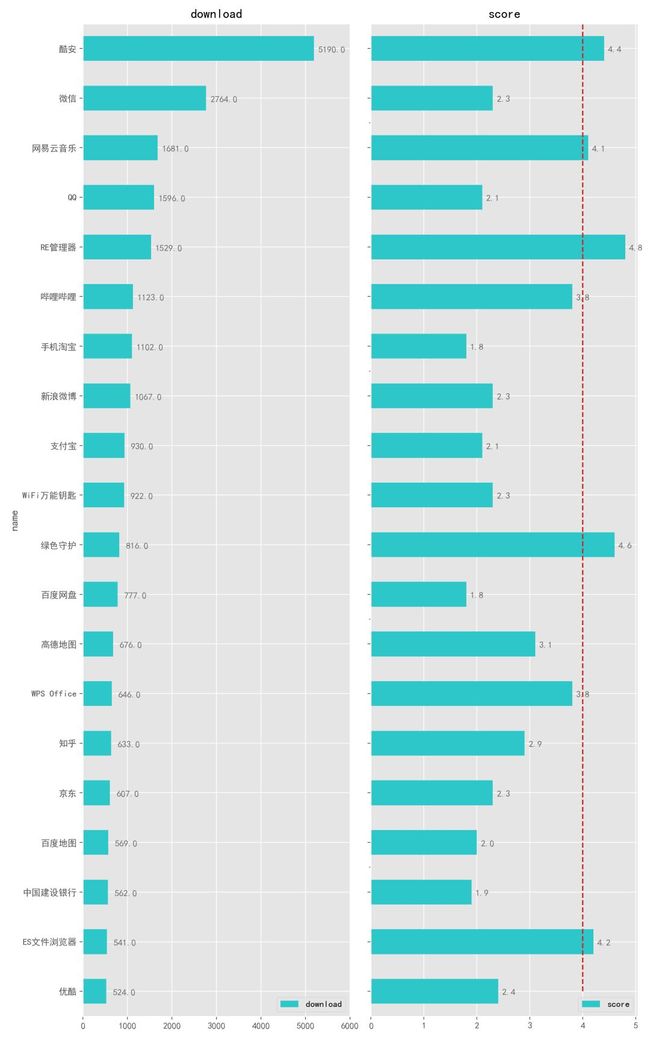
可以看到,这里「酷安」App 以 5000 万+ 次的下载量遥遥领先,是第二名微信 2700 万下载量的近两倍,这么巨大的优势也很容易理解,毕竟是自家的 App,如果你手机上没有「酷安」,说明你还不算是一个真正的「搞机爱好者」,从图中我们还可以看出以下几点信息:
-
TOP 20 款 App 中,很多都是装机必备,算是比较大众型的 App。
-
右侧 App 评分图中可以看到仅有 5 款 App 评分超过了 4 分(5 分制),绝大多数的评分都不到 3 分,甚至到不到 2 分,到底是因为这些 App 开发者做不出好 App 还是根本不想做出来?
-
相较于其他 App,RE 管理器、绿色守护 这几款非常突出,其中 RE 管理器在如此高的下载量下,仍然能够得到 4.8 分(最高分)并且体积只有几 M,实属难得,什么是「良心 App」,这类就是。
作为对比,我们再来看看下载量最少的 20 款 App。
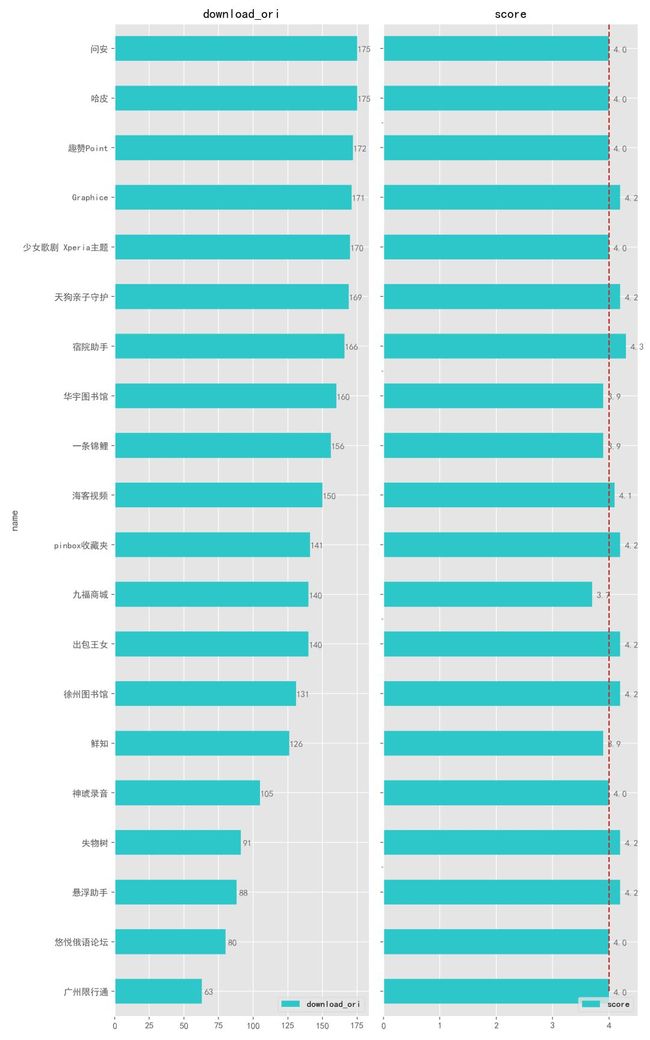
可以看到,与上面的那些下载量多的 App 相比,这些就相形见绌了,下载量最少的 「广州限行通」更是只有 63 次下载。
这也不奇怪,可能是 App 没有宣传、也可能是刚开发出来,这么少的下载量评分还不错,也还能继续更新,为这些开发者点赞。
其实,这类 App 不算囧,真正囧的应该是那些 下载量很多、评分却低到不能再低 的 App,给人的感觉是:「我就这么烂爱咋咋地,有本事别用」。
4.1.2. 评分排名
接下来,我们看看 App 的总体得分情况。这里,将得分分为了以下 4 个区间段,并且为不同分数定义了相应的等级。
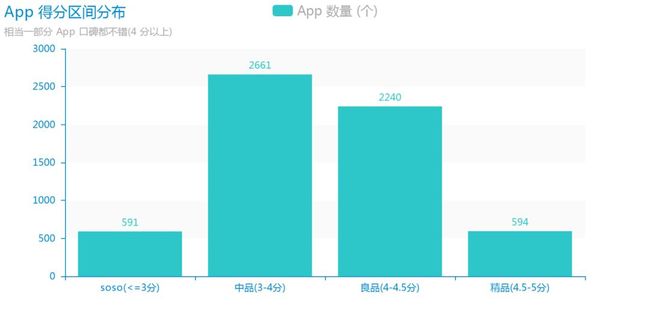
可以发现这么几点有意思的现象:
-
3 分以下的软件非常少,只占不到 10%,而之前下载量最多的 20 款 APP 中,微信、QQ、淘宝、支付宝等大多数软件的得分都不到 3 分,这就有点尴尬了。
-
中品也就是中等得分的 App 数量最多。
-
4 分以上的 高分 APP 数量占了近一半(46%),可能是这些 App 的确还不错,也可能是由于评分数量过少,为了优中选优,后续有必要设置一定筛选门槛。
接下来,我们看看评分最高的 20 款 App 有哪些,很多时候我们下载 App 都是跟着「哪个评分高,下载哪个」这种感觉走。
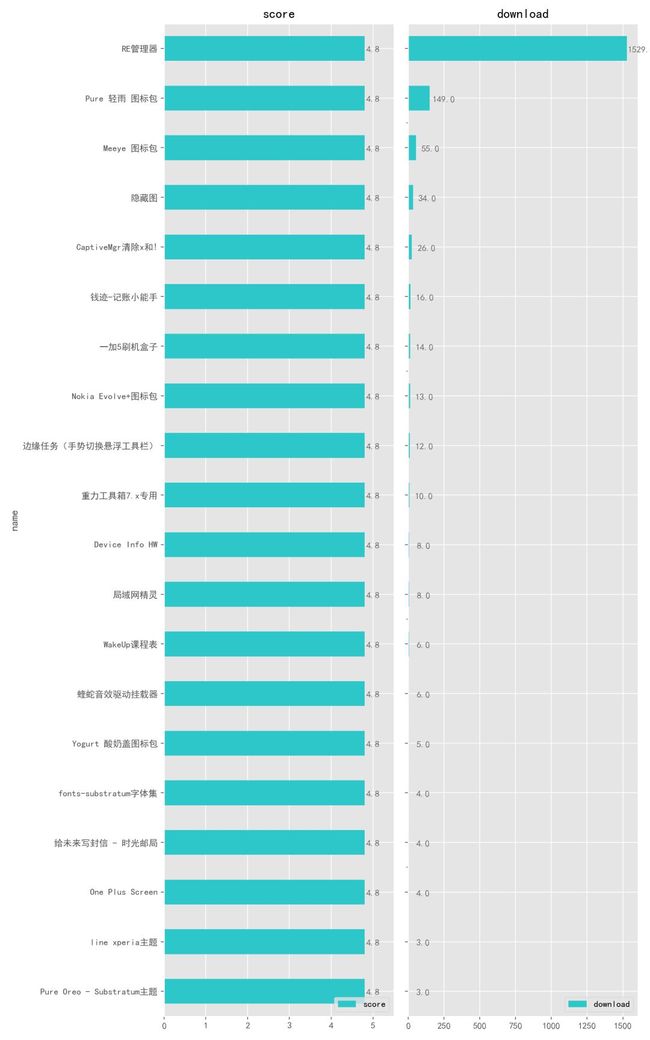
可以看到,评分最高的 20 个 App,它们都得到了 4.8 分 ,包括:RE 管理器(再次出现)、Pure 轻雨图标包等,还有一些不太常见,可能这些都是不错的 App,不过我们还需要结合看一下下载量,它们的下载量都在 1 万以上,有了一定的下载量,评分才算比较可靠,我们就能放心的下载下来体验一下了。
经过上面的总体分析,我们大致发现了一些不错的 App ,但还不够,所以接下来将进行细分并设置一定筛选条件。
4.2. 分类情况
按照 App 功能和日常使用场景,将 App 分为以下 9 大类别,然后 从每个类别中筛选出 20 款最棒的 App。

为了尽可能找出最好的 App,这里不妨设置 3 个条件:
-
评分不低于 4 分
-
下载量不低于 1 万
-
设置一个总分评价指标(总分 = 下载量 * 评分),再标准化为满分 1000 分,作为 App 的排名参照指标。
经过评选之后,我们依次得到了各个类别下分数最高的 20 款 App,这些 App 大部分的确是良心软件。
4.2.1. 系统工具
系统工具包括了:输入法、文件管理 、系统清理、桌面、插件、锁屏等。
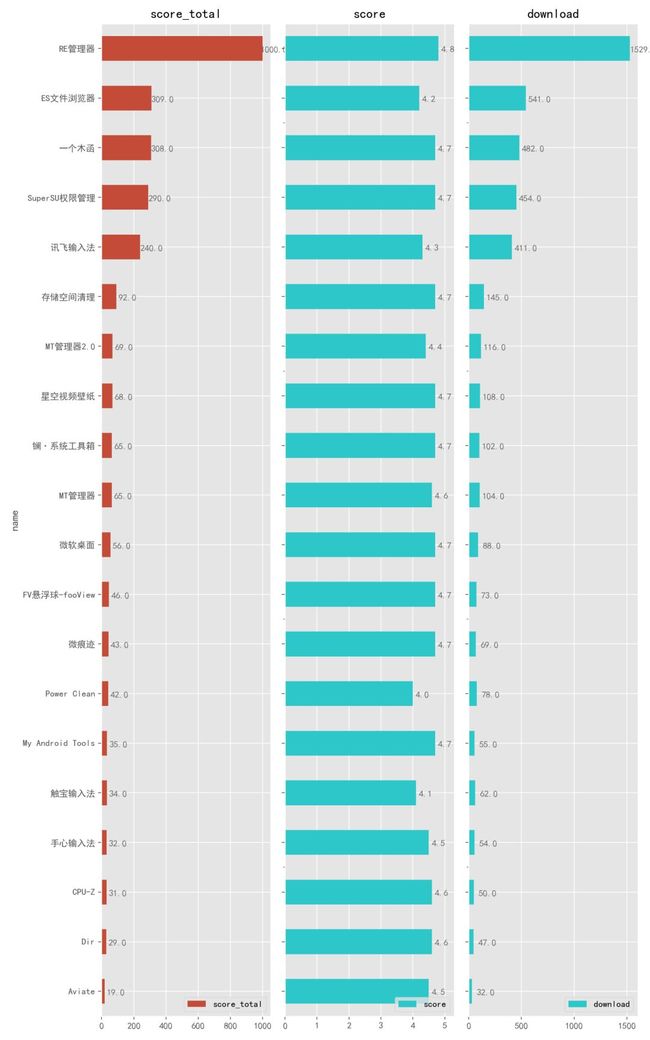
可以看到,第一名是大名鼎鼎的老牌文件管理器「RE 管理器」,仅有 5 M 大小的它除了具备普通文件管理器的各项功能以外,最大的特点是能够卸载手机自带的 App,不过需要 Root。
「ES 文件浏览器」的文件分析器功能非常强大,能够有效清理臃肿的手机空间。
「一个木函」这款 App 就比较牛逼了,正如它的软件介绍「拥有很多,不如有我」所说,打开它你能发现它提供了好几十项实用功能,比如:翻译、以图搜图、快递查询、制作表情包等等。
再往下的「Super SU」、「存储空间清理」、「镧」、「MT 管理器」、「My Android Tools」都力荐,总之,这份榜单上的 App 可以说都值得进入你的手机 App 使用名单。
4.2.2. 社交聊天
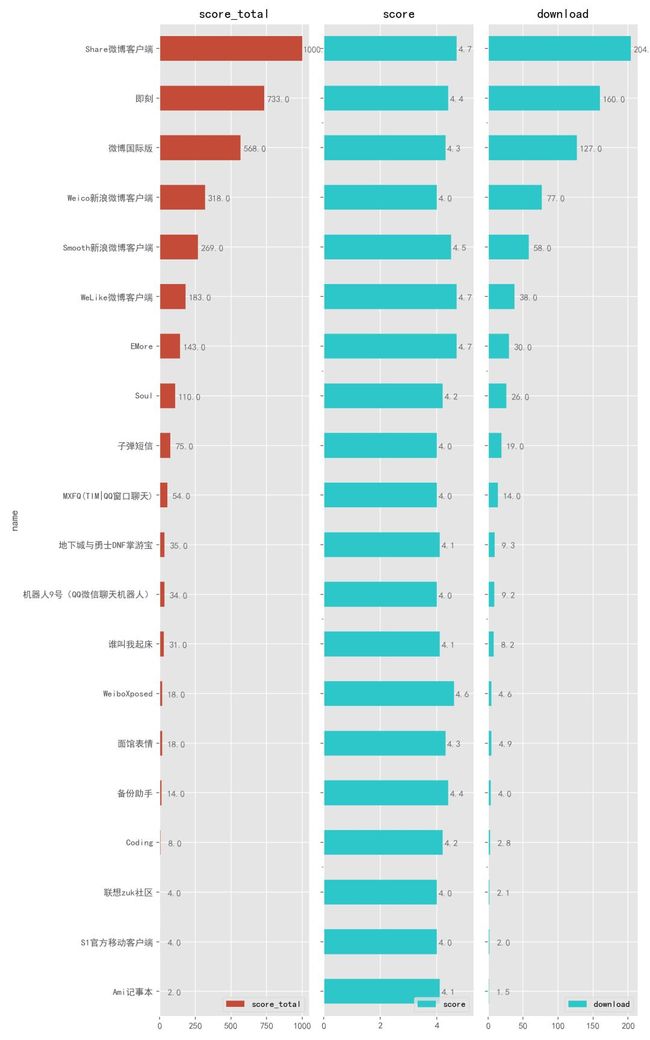
社交聊天类中, 「Share 微博客户端」位居第一,作为一款第三方客户端 App,它自然有比官方版本好的地方,比如相比正版 70M 的体积,它只有其十分之一大小,也几乎没有广告,还有额外强大的诸多功能,如果你爱刷微博,那么不妨尝试下这款「Share」。
「即刻」这款 App 也相当不错,再往下还能看到前阵子很火的「子弹短信」,宣称将要取代微信,看来短期内应该是做不到了。
你可能会发现,这份社交榜单上没有出现「知乎」、「豆瓣」、「简书」这类常见的 App,是因为它们的评分都比较低,分别只有 2.9分、3.5分和 2.9 分,自然进入不了这份名单,如果你一定想用它们,推荐去使用它们的第三方客户端或者历史版本。
4.2.3. 资讯阅读
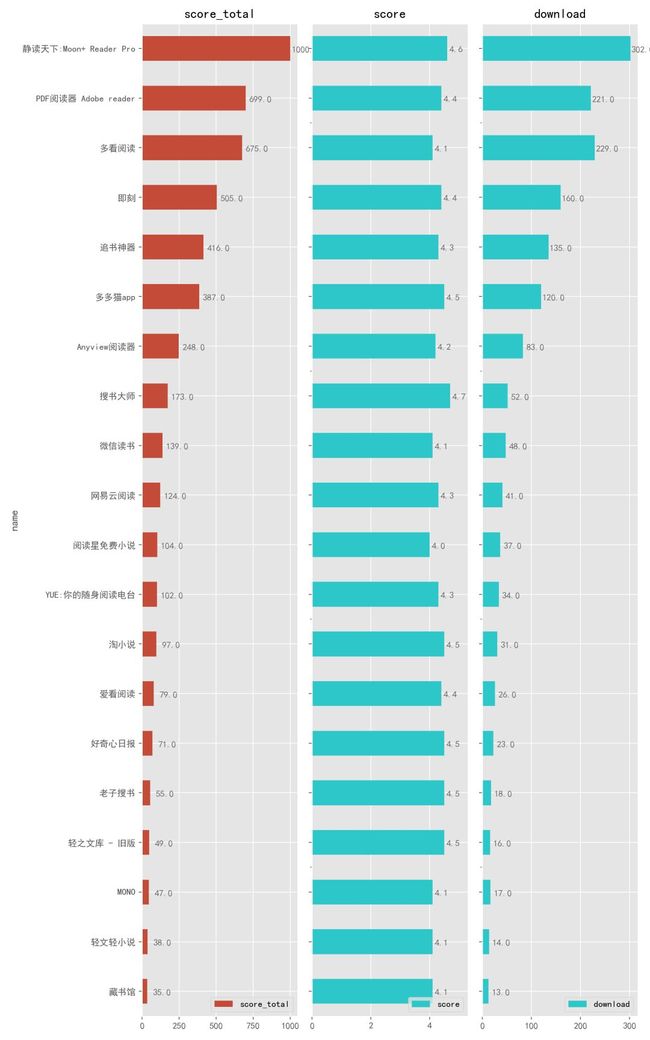
可以看到,在资讯阅读类中,「静读天下」牢牢占据了第一名,我之前专门写过一篇文章介绍它:安卓最强阅读器。
同类别中的「多看阅读」、「追书神器」、「微信读书」也都进入了榜单。
另外,如果你经常为不知道去哪里下载电子书而头疼,那不妨试一下「搜书大师」、「老子搜书」。
4.2.4. 影音娱乐
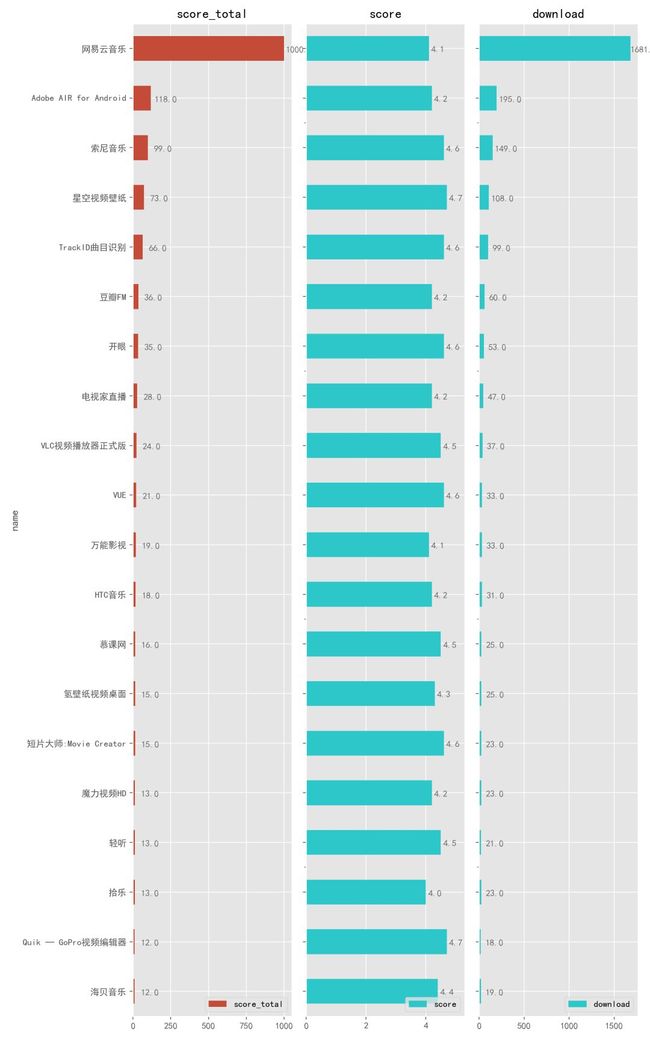
接下来是影音娱乐版块,网易家的「网易云音乐」毫无压力地占据头名,难得的大厂精品。
如果你爱玩游戏,那么 「Adobe AIR」应该尝试一下。
如果你很文艺,那么应该会喜欢「VUE」这款短视频拍摄 App,创作好以后发到朋友圈绝对能装逼。
最后一位的「海贝音乐」很赞,最近发现它有一个强大的功能是结合百度网盘使用,它能够自动识别音频文件然后播放。
4.2.5. 通讯网络
下面到了通讯网络类别,这个类别主要包括:浏览器、通讯录、通知、邮箱等小类。
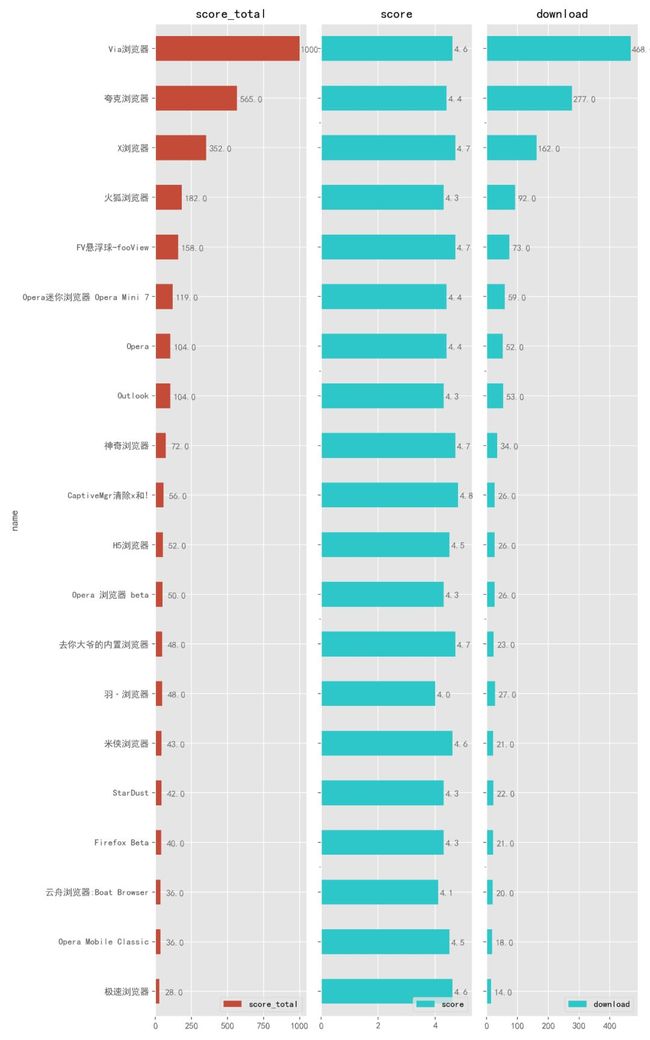
浏览器,我们每个人手机上都有,用的也五花八门,有些人就用手机自带的浏览器,有些人用 Chrome、火狐这类大牌浏览器。
不过你会发现榜单上的前三位你可能听都没听过,但是它们真的很牛逼,用「极简高效、清爽极速」来形容再适合不过,其中 「Via 」和 「X 浏览器」 体积不到 1M ,真正的「麻雀虽小、五脏俱全」,强烈推荐。
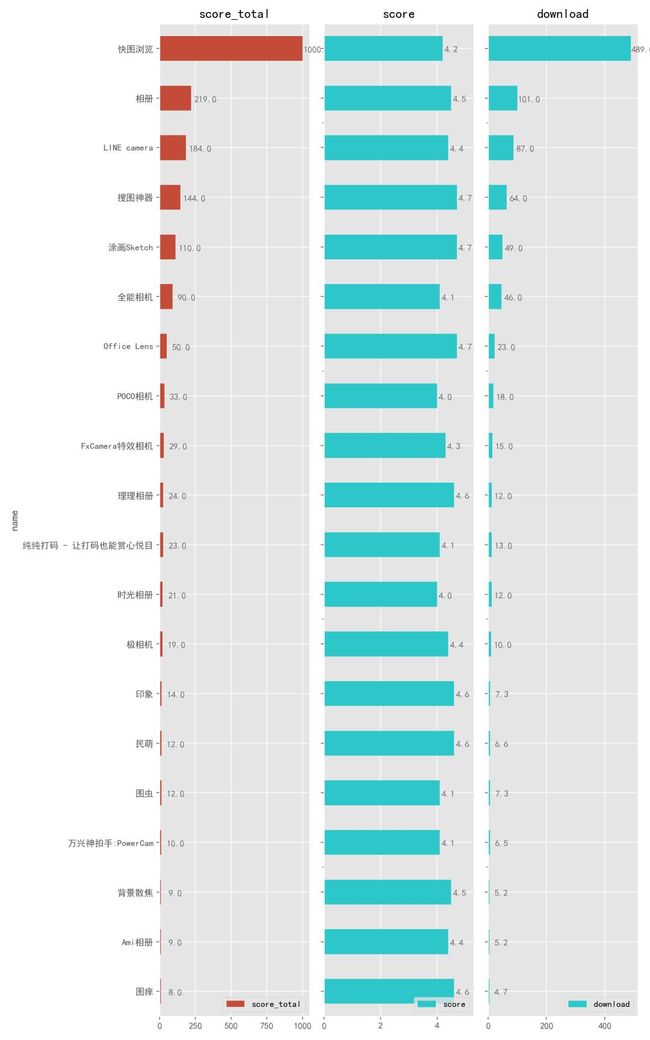
4.2.6. 摄影图片
拍照修图也是我们常用的功能。也许你有自己的图片管理软件,但是这里要强烈推荐第一名「快图浏览」这款 App,只有 3M 大小的它,能够瞬间发现和加载上万张图片,如果你是拍照狂魔,用它打开再多的照片也能秒开,另外还拥有隐藏私密照片、自动备份百度网盘等功能。它是我使用时间最久的 App 之一。
4.2.7. 文档写作
我们时常需要在手机上写作、做备忘录,那么自然需要好的文档写作类 App。
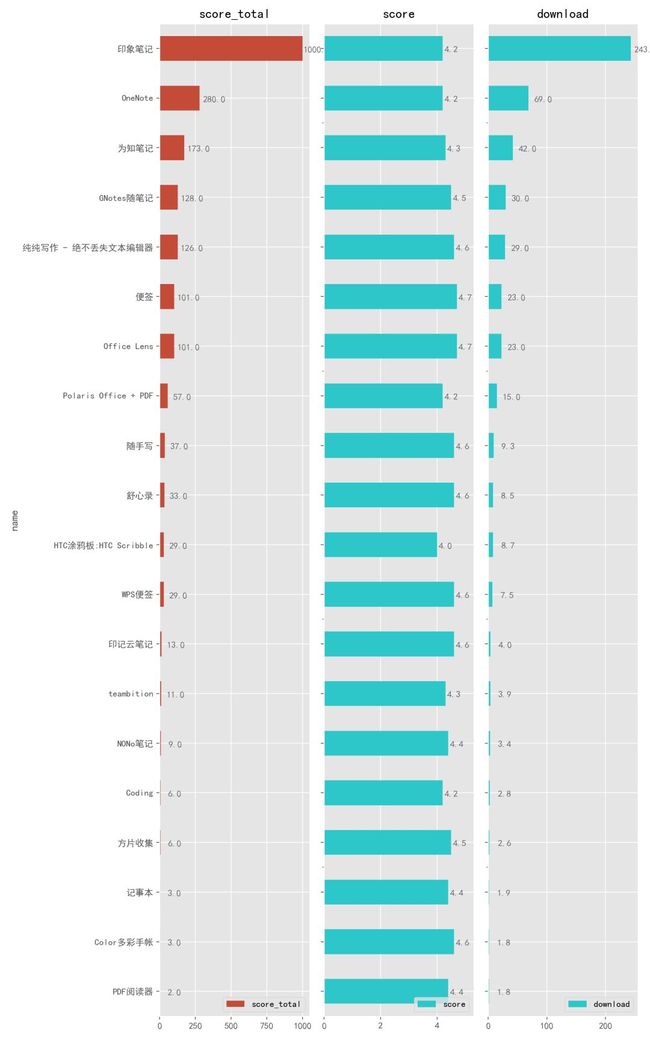
「印象笔记」就不用多说了,我觉得最好用的笔记总结类 App。
如果你喜欢使用 Markdown 写作,那么「纯纯写作」这款精巧的 App 应该会很适合你。
体积不到 3M 却拥有云备份、生成长图、中英文自动空格等数十项功能,即使这样,仍然保持了蕴繁于简的设计风格,这大概就是两三个月之内,下载量就从两三万飙升了十倍的原因,而这款 App 的背后是一位 牺牲了几年的业余时间不断开发和更新的大佬,值得敬佩。
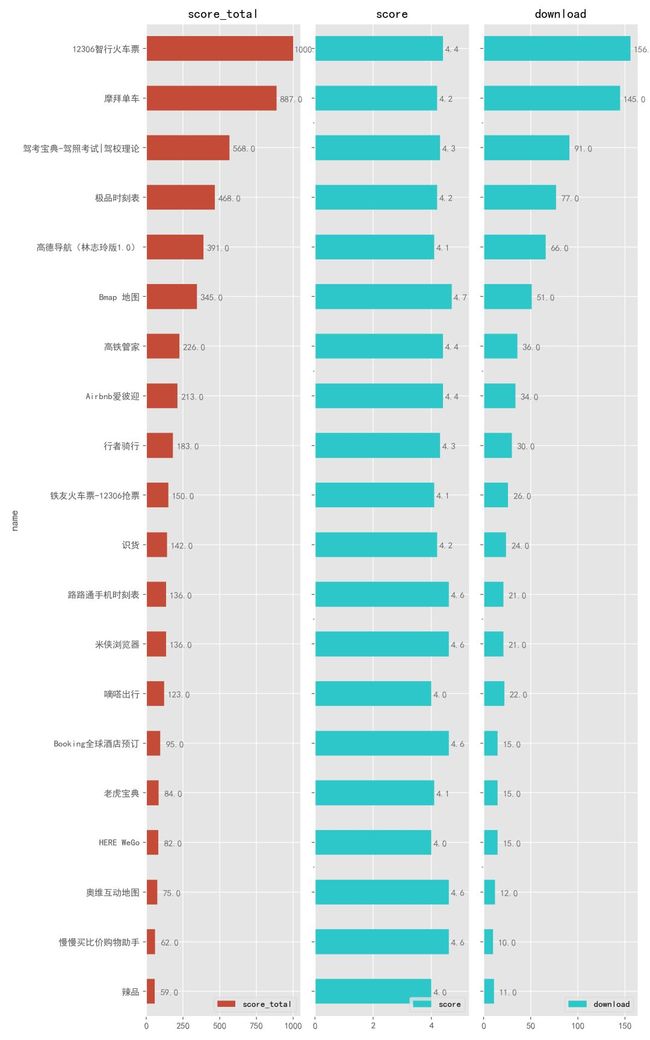
4.2.8. 出行交通购物
这个类别中,排名第一的居然是 12306,一提起它,就会想起那一张张奇葩的验证码,不过这里的 App 不是官网的 ,而是第三方开发的。最牛逼的功能应该就是「抢票了」,如果你还在靠发朋友圈来抢票的话,那不妨试一下它。
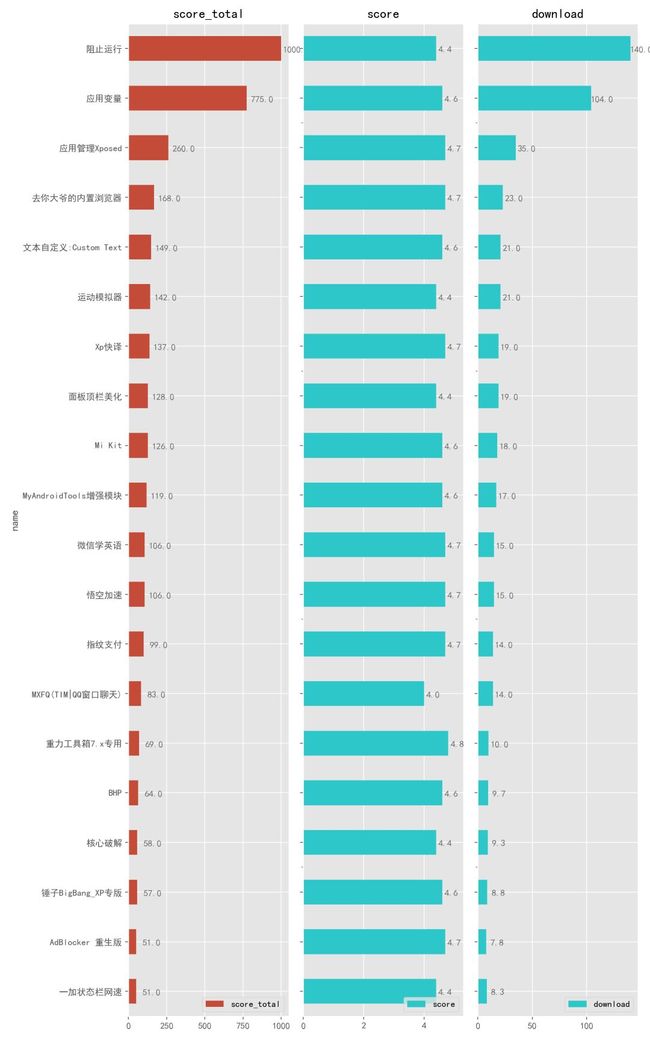
4.2.9. Xposed 插件
最后一个类别是 Xposed,很多人应该不太熟悉,但是一提微信上的抢红包、防撤回功能,应该很多人就知道了。这些牛逼又不同寻常的功能就用到了 Xposed 框架里的各种模块功能。这个框架由国外著名的 XDA 手机论坛,你经常听到的一些所谓由 XDA 大神破解的软件,就是来自这个论坛。
简单地说就是,安装了 Xposed 这个框架之后,就可以在里面安装一些好玩有趣的插件,有了这些插件,你的手机就能实现更多更大的功能。比如:能够去除广告、破解 App 付费功能、杀死耗电的自启动进程、虚拟手机定位等功能。
不过使用这个框架和这些插件需要刷机、ROOT,门槛有点高。
5. 小结
-
本文使用 Scrapy 框架爬取分析了酷安网的 6000 款 App,初学 Scrapy 可能会觉得程序写起来比较散乱,所以可以尝试先使用普通的函数方法,把程序完整地写在一起,再分块拆分到 Scrapy 项目中,这样也有助于从单一程序到框架写法的思维转变,之后会写单独写一篇文章。
-
由于网页版的 App 数量比 App 中的少,所以还有很多好用的 App 没有包括进来,比如 Chrome 、MX player、Snapseed 等,建议使用酷安 App,那里有更多好玩的东西。
以上就是整篇文章的爬取与分析过程,文中涉及了很多精品佳软,如有兴趣可以去尝试下载体验一下,为了更方便你,我这里也收集好了 24 款精品 App。
「pk哥」以梦为马,不负韶华

觉得不错,点赞、赞赏、转发朋友圈都是一种支持。
欢迎点击下方小程序留言。
推荐阅读:
一行代码能实现什么丧心病狂的功能?
小白也会用爬虫利器:you-get,让天下没有难爬的网页
介绍一款反爬虫页面的爬虫利器 Puppeteer
凌晨三点,你手机上的APP在自动签到
换种方式写脚本,10倍提高你的工作效率
用Django框架快速搭建博客