yolov5中的Focus模块的理解
序言
v5出来这么久,一直搜不到网上对Focus的理解,还想着白嫖一下结论,但是发现搜出来的都是一知半解,讲的全都是Focus做了什么,愣是没说为什么要这么做。没办法只好自己花点时间深入学习一下,本人也记录一下本人对Focus模块的一些理解,如果有理解错误的地方,还请评论区告知。
一、Focus模块的原理
Focus模块在v5中是图片进入backbone前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长的差不多,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
以yolov5s为例,原始的640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 × 12的特征图,再经过一次卷积操作,最终变成320 × 320 × 32的特征图。切片操作如下:
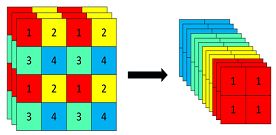
具体代码实现:
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act) # 这里输入通道变成了4倍
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
二、Focus的作用
在讨论Focus的作用之前,先了解两个概念:
参数数量(params):关系到模型大小,单位通常是M,通常参数用float32表示,所以模型大小是参数数量的4倍。
计算量(FLOPs):即浮点运算数,可以用来衡量算法/模型的复杂度,这关系到算法速度,大模型的单位通常为G,小模型单位通常为M;通常只考虑乘加操作的数量,而且只考虑Conv和FC等参数层的计算量,忽略BN和PReLU等,一般情况下,Conv和FC层也会忽略仅纯加操作的计算量,如bias偏置加和shoutcut残差加等,目前技术有BN和CNN可以不加bias。
params计算公式:
Kh × Kw × Cin × Cout
FLOPs计算公式:
Kh × Kw × Cin × Cout × H × W = 即(当前层filter × 输出的feature map)= params × H × W
总所周知,图片在经过Focus模块后,最直观的是起到了下采样的作用,但是和常用的卷积下采样有些不一样,可以对Focus的计算量和普通卷积的下采样计算量进行做个对比:
在yolov5s的网络结构中,可以看到,Focus模块的卷积核是3 × 3,输出通道是32:
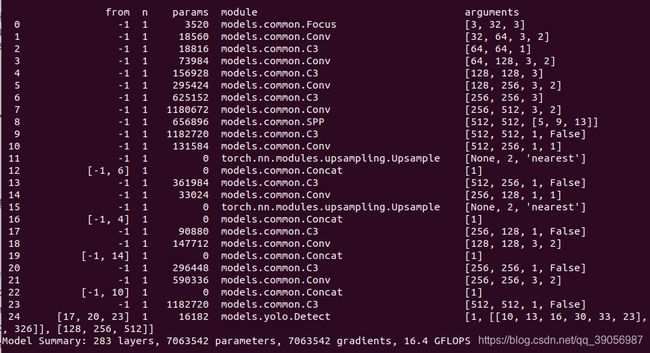
那么做个对比:
普通下采样:即将一张640 × 640 × 3的图片输入3 × 3的卷积中,步长为2,输出通道32,下采样后得到320 × 320 × 32的特征图,那么普通卷积下采样理论的计算量为:
FLOPs(conv) = 3 × 3 × 3 × 32 × 320 × 320 = 88473600(不考虑bias情况下)
params参数量(conv) = 3 × 3 × 3 × 32 +32 +32 = 928 (后面两个32分别为bias和BN层参数)
Focus:将640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 × 12的特征图,再经过3 × 3的卷积操作,输出通道32,最终变成320 × 320 × 32的特征图,那么Focus理论的计算量为:
FLOPs(Focus) = 3 × 3 × 12 × 32 × 320 × 320 = 353894400(不考虑bias情况下)
params参数量(Focus)= 3 × 3 × 12 × 32 +32 +32 =3520 (为了呼应上图输出的参数量,将后面两个32分别为bias和BN层的参数考虑进去,通常这两个占比比较小可以忽略)
可以明显的看到,Focus的计算量和参数量要比普通卷积要多一些,是普通卷积的4倍,但是下采样时没有信息的丢失。(结论已修改,请看后续更新)
综上所述,其实就可以得出结论,Focus的作用无非是使图片在下采样的过程中,不带来信息丢失的情况下,将W、H的信息集中到通道上,再使用3 × 3的卷积对其进行特征提取,使得特征提取得更加的充分。虽然增加了一点点的计算量,但是为后续的特征提取保留了更完整的图片下采样信息。
2021-07-01更新:作者有在issues中提到Focus是为了提速,和mAP无关,但是也没有说是什么原理,我也是一知半解,本文也仅从计算量和参数量去分析该模块,如果有看懂作者这样作法的同学望评论区告知。
2021-08-16更新:作者终于在issues上做了具体的解答,和之前分析的思路一样,都是从计算量和参数量出发,不同的是,在作者解答之前我们并不知道作者改进的出发点是什么,也就是不清楚他在何结构上进行的改进,文中我理解为只是对一层普通下采样卷积做的改进,实际上有三层,所以经过改进后参数量其实还是变少了的,也确实达到了提速的效果,具体内容可以结合本文分析过程和作者给的issues结合起来看。
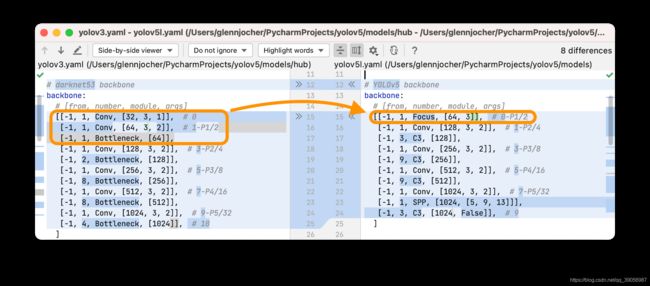
最后
千呼万唤始出来的结论,终于解开了我这么长时间的疑惑,虽然之前文中的结论和作者实际的结论是相反的;主要原因还是因为不知道作者改进的出发点在哪里,所以分析过程虽然是对的,但是结论却是反着了;知道了改进的出发点后,再把过程重新梳理一下,就很好理解了。最后也感谢大家的讨论