Centos7虚拟机部署安装Hadoop集群
CentOS7安装Hadoop
相关软件下载
| 系统镜像/软件 | 下载地址 |
|---|---|
| CentOS-7-x86_64-DVD-2009.iso | 下载链接 |
| jdk-8u202-linux-x64.tar.gz | 下载链接 |
| hadoop-2.7.7.tar.gz | 下载链接 |
一、搭建集群、配置主机
1. 永久修改主机名
hostnamectl set-hostname 主机名
2. MAC地址配置
网络适配器高级设置、随机生成MAC
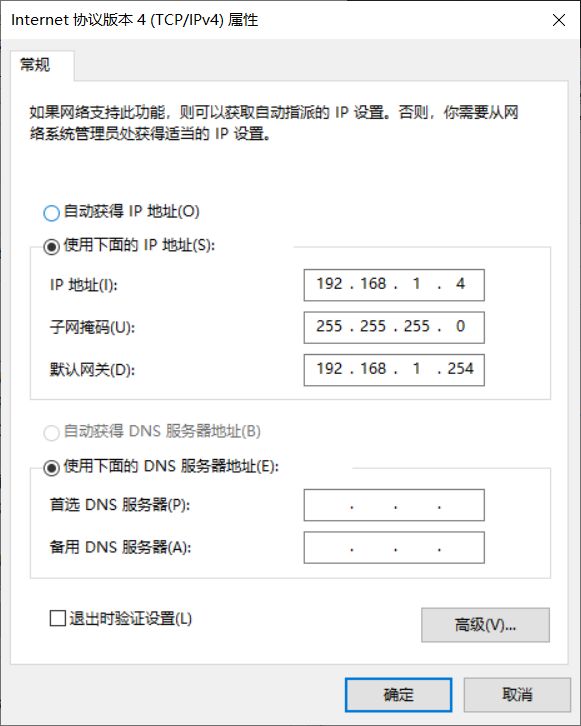
3. ip地址配置1
master:192.168.1.1
slave1:192.168.1.2
slave2:192.168.1.3
gateway:192.168.1.254
netmask:255.255.255.0
windows(VMnet8):192.168.1.4
修改网卡配置信息
cd /etc/sysconfig/network-scripts/
vim ifcfg-ens33
[root@master ~]#
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="e896b704-392e-4e44-ad67-a8ba4357a546"
DEVICE="ens33"
IPADDR=192.168.1.1
NETMASK=255.255.255.0
GATEWAY=192.168.1.254
ONBOOT="yes"
| [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1zP3DHaW-1636618470102)(https://i.loli.net/2021/09/15/zRZiKorvChAbla2.png)] |
|---|
 |
|---|
重启网络服务
systemctl restart network
4. 主机名与IP映射1
#编辑hosts
vi /etc/hosts
添加映射关系(每个主机都要配置)
192.168.1.1 master
192.168.1.2 slave1
192.168.1.3 slave2
5. 配置SSH免密登录
此项只需在master中配置
#进入用户目录
cd /home/sunshj
#生成密钥,回车即可
ssh-keygen -t rsa
#到.ssh目录下
cd .ssh/
#将id_rsa.pub添加到authorized_keys目录
cp id_rsa.pub authorized_keys
ssh-copy-id -i slave1
ssh-copy-id -i slave2
二、安装配置java环境
1. 安装包安装
解压到home/用户文件夹
tar -zxvf jdk-8u202-linux-x64.tar.gz
修改目录名
mv jdk1.8.0_202 jdk1.8
2. 配置环境变量
配置用户级环境变量
这里只需要配置用户级环境变量
vim .bashrc
添加变量
export JAVA_HOME=/home/sunshj/jdk1.8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
立即生效
source .bashrc
3. 复制文件到子节点
复制jdk1.8到子节点
scp -r /home/sunshj/jdk1.8 sunshj@slave1:/home/sunshj/
scp -r /home/sunshj/jdk1.8 sunshj@slave2:/home/sunshj/
复制.bashrc到子节点
scp -r .bashrc sunshj@slave1:/home/sunshj/
scp -r .bashrc sunshj@slave2:/home/sunshj/
立即生效
source .bashrc
三、安装配置Hadoop
1. 安装包安装
tar -zxvf hadoop-2.7.7.tar.gz
2. 配置.bashrc环境变量
export HADOOP_HOME=/home/sunshj/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
3. 修改hadoop配置文件
cd hadoop-2.7.7/etc/hadoop/
core-site.xml
vim core-site.xml
在configuration中添加
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/home/sunshj/hadoop-2.7.7/tmpvalue>
<description>Abase for other temporary directories.description>
property>
hadoop-env.sh添加内容
export JAVA_HOME=/home/sunshj/jdk1.8
hdfs-site.xml
vim hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>master:50090value>
property>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/home/sunshj/hadoop-2.7.7/tmp/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/home/sunshj/hadoop-2.7.7/tmp/dfs/datavalue>
property>
mapred-site.xml.template --> mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>master:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>master:19888value>
property>
yarn-site.xml
vim yarn-site.xml
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mastervalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
slaves
vim slaves
#删除localhost
slave1
slave2
4. 复制文件到子节点
复制hadoop到子节点
scp -r /home/sunshj/hadoop-2.7.7 sunshj@slave1:/home/sunshj/
scp -r /home/sunshj/hadoop-2.7.7 sunshj@slave2:/home/sunshj/
复制.bashrc到子节点
scp -r .bashrc sunshj@slave1:/home/sunshj/
scp -r .bashrc sunshj@slave2:/home/sunshj/
立即生效
source .bashrc
5. 格式化1
关闭enforce
切换到root用户
vi /etc/selinux/config
修改SELINUX
SELINUX=disabled
退出root,格式化
hdfs namenode -format
6. 启动hadoop
请在启动前打开集群
运行全部
start-all.sh
关闭全部
stop-all.sh
- NameNode and Datanode: http://master:50070
- mapreduce: http://master:8088/cluster
五、注意事项
!关闭hadoop
关闭虚拟机前关闭hadoop!!!
每个节点都需操作此步骤 ↩︎ ↩︎ ↩︎