网络编程补充
网络编程补充
- 1.认识
- 2.Socket网络编程
- 3.TCP通讯
- 4.echo模型
- 5.UDP
- 6.UDP广播
- 7.HTTP
- 8.HTTP响应
- 9.建立响应目录
- 10.动态请求处理
- 11.urllib3
- 12.twisted模块认识
- 13.twisted开发TCP程序
- 14.使用twisted开发UDP程序
- 15.Deferred
1.认识
- 网络编程的核心功能就是 IO 操作
- 两台主机的通信要保证两点:
- 线路畅通
- 双方遵守协议
- 在进行网络程序开发的过程中一般都会考虑两种不同的开发模式:
- C/S模式(Client/Server—客户端/服务端架构)
- 需要编写两套不同的程序(客户端与服务端)
- 项目维护需要进行两套项目的维护,维护成本比较高
- 但是这种程序一般使用特定的协议(TCP),特定的数据结构,隐藏的端口等,安全性比较高
- B/S模式(Browser/Server–浏览器与服务端架构)
- 基于WEB设计的一种架构,基于浏览器的形式作为客户端进行访问,
- 在程序开发时,成本较低,用户使用门槛较低
- 但这种开发一般基于HTTP协议完成处理,安全性不高,使用的是80端口,极易遭到攻击
- C/S模式(Client/Server—客户端/服务端架构)
- OSI 7层模型 (开放式系统互联)
- 网络程序开发不仅仅是一个简单的数据交互过程,还包含一些数据的处理逻辑,而所有的网络设备一定会由不同的硬件厂商生产,所以为了保证数据传输的可靠性以及标准性,就定义了 OSI 7层模型
| No | 议成名称 | 描述 |
|---|---|---|
| 1 | 应用层 | 提供网络服务操作接口 |
| 2 | 表示层 | 对要传输的数据进行处理,例如:数据编码 |
| 3 | 会话层 | 管理不同的通讯节点之间的连接信息 |
| 4 | 传输层 | 建立不同节点之间的网络连接,为数据追加段信息 |
| 5 | 网络层 | 将网络地址映射为mac地址实现数据包转发,为数据追加包信息 |
| 6 | 数据链路层 | 将要发送的数据包转换为数据帧,是其在不可靠的物理链路上进行可靠的数据传输,为数据追加帧信息 |
| 7 | 物理层 | 利用物理设备实现数据的传输(二进制数据传输) |
- 有了这7层不同的网络数据的处理分类,所以任何的硬件厂商生产的设备(不管加入多少辅助技术),其核心是不变的
- Python属于高级语言,所以对于所有的网络程序开发不可能让开发者自行处理具体的OSI模型,应该采用统一的模式进行定义,这才有了Socket编程
2.Socket网络编程
Socket(套接字),是一种对TCP/UDP 网络协议进行的一种包装(或者称为协议的一种抽象应用),本身的特点提供了不同进程之间的数据通讯操作
- TCP(传输控制协议)
- 采用有状态的通讯机制进行传输,在通讯时会通过三次握手机制保证与一个指定节点的数据传输的可靠性,在通讯完毕会通过四次挥手的机制关闭连接,由于每次数据的通讯前都需要消耗大量的时间进行连接控制,所以执行性能低,且资源占用较大
- UDP(数据报协议 /用户数据报协议)
- 采用无状态的通讯机制进行传输。没有了TCP中复杂的握手与挥手处理机制,这样就节约了大量的系统资源,同时数据传输性能较高,但由于不保存单个节点的连接状态,所以发送的数据不一定可以被全部接受。
- UDP不需要链接就可以直接发送数据,并且多个接受端都可以同时接受同样的信息,所以UDP适合于广播操作
不论是TCP还是UDP协议,都是对传输层操作的保证,数据按照OSI 七层模型来说 一定要通过网络层进行路由的配置,同时利用数据链路层添加数据帧,最终利用物理层发出,但是由于Socket机制的存在,所以开发者只需要编写处理的核心代码,而具体的传输,协议操作就完全被包装了
3.TCP通讯
TCP是面向连接的网络传输协议,在进行TCP通讯的过程中其安全性以及稳定性都是最高的,虽然性能会差些,但是对于当前网络环境来讲主要还是使用TCP协议的居多
python中使用socket.socket类即可实现TCP程序开发:
| No | 函数 | 类型 | 描述 |
|---|---|---|---|
| 1 | socket() | 构造 | 获取socket类对象 |
| 2 | bind(hostname,port) | 方法 | 在指定主机的端口绑定监听 |
| 3 | listen() | 方法 | 在绑定的端口上开启监听 |
| 4 | accept() | 方法 | 等待客户端连接,连接后返回客户端地址 |
| 5 | send(data) | 方法 | 发送数据 |
| 6 | recv(buffer) | 方法 | 接收数据 |
| 7 | close() | 方法 | 关闭套接字连接 |
| 8 | connect(hostname,port) | 方法 | 设置连接的主机名称与端口号 |
- 客户端开发过程:
- 创建TCP客户端套接字
- 和服务端套接字建立连接
- 发送数据给服务端
- 接收服务端数据
- 关闭套接字
- 服务端开发过程
- 创建服务端套接字对象
- 设置端口端口号复用–让服务端关闭后端口号立即释放
- 绑定端口号
- 设置监听
- 等待接受客户端连接(接收客户端的套接字与端口)
- 接受数据
- 发送数据
- 关闭套接字(关闭客户端套接字与服务端套接字)
整个Socket网络编程之中基本的核心流程就是服务端开启监听端口,等待客户端连接,而客户端想要访问服务器就必须进行服务器的地址连接,而后进行响应的数据的请求或响应内容的接收
#-------------这是服务端--------
import socket
#服务端的地址端口
SERVER_HOST='localhost'
SERVER_PORT=8080
def main():
#socket网络服务每一次处理完成之后一定要使用close()关闭,所以使用with结构定义
with socket.socket() as server_socket:#创建服务端Socket
server_socket.bind((SERVER_HOST,SERVER_PORT))#绑定服务端主机与端口
server_socket.listen()#开启监听
print('[服务端]服务端启动完成,在%s端口上监听等待客户端连接。。。'%SERVER_PORT)
new_socket,iport=server_socket.accept()#等待客户端连接,处于阻塞状态
new_socket.send('你好,这里是服务端!'.encode())
print(iport,'连接成功! 响应:',new_socket.recv(128).decode())
if __name__ == '__main__':
main()
#------------这是客户端----------
import socket
SERVER_HOST='127.0.0.1'#要连接的服务端的主机名称或ip地址
SERVER_PORT=8080
def main():
with socket.socket() as client_socket:#建立客户端socket
client_socket.connect((SERVER_HOST,SERVER_PORT))#连接服务器
print('服务端响应数据:%s'%client_socket.recv(128).decode())#接收数据长度为128字
client_socket.send('你好,这里是客户端!'.encode())#发送消息
if __name__ == '__main__':
main()
4.echo模型
echo程序模型来源于echo命令,在操作系统内部提供一个echo命令进行内容的回显
echo指令 输入什么–返回什么
将echo的概念扩大到网络环境中,就可以理解为客户端输入一组数据发送到服务端,那么服务端接受之后对该数据进行响应,这种模型就是网络编程echo模型
在整个网络编程中,由于所有网络程序一定要有一个绑定的端口号存在,所以一个端口只允许绑定一个服务,如果出现端口被占用的情况,那么程序将无法正常启动
对于当前服务端程序如果想要测试,简单可以直接通过telnet命令来完成,每当用户输入一个内容之后就会立即将此内容发送到服务端,但window命令行采用的GBK编码,会造成乱码,但是可以测试服务端是正确的
#-------------这是服务端--------
import socket
#服务端的地址端口
SERVER_HOST='localhost'
SERVER_PORT=8080
def main():
#socket网络服务每一次处理完成之后一定要使用close()关闭,所以使用with结构定义
with socket.socket() as server_socket:#创建服务端Socket
server_socket.bind((SERVER_HOST,SERVER_PORT))#绑定服务端主机与端口
server_socket.listen()#开启监听
print('[服务端]服务端启动完成,在%s端口上监听等待客户端连接。。。'%SERVER_PORT)
cli_socket,iport=server_socket.accept()#等待客户端连接,处于阻塞状态
with cli_socket:#进行客户端的处理
while True:#不断进行信息的接收与响应
data = cli_socket.recv(128).decode() # 接收客户端传过来的数据
if data.upper()=='BYEBYE':#客户端输入此指令
cli_socket.send('exit'.encode())
break#结束循环
else:#进行正常的响应
cli_socket.send(('echo %s'%data).encode())#向客户端进行去请求响应
if __name__ == '__main__':
main()
#------------这是客户端----------
import socket
SERVER_HOST='127.0.0.1'#要连接的服务端的主机名称或ip地址
SERVER_PORT=8080
def main():
with socket.socket() as client_socket:#建立客户端socket
client_socket.connect((SERVER_HOST,SERVER_PORT))#连接服务器
while True:#客户端要不断与服务端交互
input_data=input('请输入要发送的数据(输入byebye结束):')
client_socket.send(input_data.encode())#数据发送
echo_data=client_socket.recv(100).decode()
if echo_data.upper()=='EXIT':#结束
break#断开连接
else:
print(echo_data)#输出服务端响应内容
if __name__ == '__main__':
main()
当服务器端引入并发编程的概念之后,那么就可以同时进行多个客户端的请求处理,在开发行业内有一个“高并发”指的就是连接客户端比较多,所以这个时候如何处理好服务端处理性能就成为项目设计的关键
#-------------这是服务端--------
import multiprocessing
import socket
#服务端的地址端口
SERVER_HOST='localhost'
SERVER_PORT=8080
def echo_handle(cli_socket,iport):#进程处理函数
print('[服务端],在%s端口上监听客户端。。。' % iport[1])
with cli_socket: # 进行客户端的处理
while True: # 不断进行信息的接收与响应
data = cli_socket.recv(128).decode() # 接收客户端传过来的数据
if data.upper() == 'BYEBYE': # 客户端输入此指令
cli_socket.send('exit'.encode())
break # 结束循环
else: # 进行正常的响应
cli_socket.send(('echo %s' % data).encode()) # 向客户端进行去请求响应
def main():
#socket网络服务每一次处理完成之后一定要使用close()关闭,所以使用with结构定义
with socket.socket() as server_socket:#创建服务端Socket
server_socket.bind((SERVER_HOST,SERVER_PORT))#绑定服务端主机与端口
server_socket.listen()#开启监听
while True:#不断接受请求
print('[服务端]服务端启动完成,在%s端口上监听等待客户端连接。。。' % SERVER_PORT)
cli_socket, iport = server_socket.accept() # 等待客户端连接,处于阻塞状态
process=multiprocessing.Process(target=echo_handle,args=(cli_socket,iport),name='客户端进程-%s'%iport[1])#定义进程
process.start()#启动进程
if __name__ == '__main__':
main()
5.UDP
UDP也是网络传输层上的一种协议,但与TCP相比,UDP本身采用的是不安全的连接,所以来讲每一次通过UDP发送对1数据不一定可以接收到,但是由于其性能比较好,所以未来会有广阔的发展前景
在Python中对于TCP/UDP本身的实现结构差别不大,都是通过socket.socket类完成的,只需要设置一些参数即可将其设为UDP(数据报协议)
UDP与TCP服务端最大的区别是不再需要过多的考虑到数据稳定性的连接问题了,所以也不再设置有具体的监听操作,在每次接收到请求之后只需要获取客户端的原始地址,直接根据原路返回即可
#-------------这是服务端--------
import socket
#服务端的地址端口
SERVER_HOST='localhost'
SERVER_PORT=8080
def main():
#socket网络服务每一次处理完成之后一定要使用close()关闭,所以使用with结构定义
#socket.AF_INET ip4网络协议进行服务端创建
#socket.SOCK_DGRAM创建一个数据报协议的服务端(UDP)
with socket.socket(socket.AF_INET,socket.SOCK_DGRAM) as server_socket:#创建服务端Socket
server_socket.bind((SERVER_HOST,SERVER_PORT))#绑定服务端主机与端口
print('[服务端]服务端启动完成,在%s端口上监听等待客户端连接。。。'%SERVER_PORT)
while True:#不断进行接收
data,iport=server_socket.recvfrom(30)#接收客户端发送的数据
print(iport, '连接成功! 响应:')
echo_data=('echo %s'%data.decode()).encode()#响应数据 从哪来会那去
server_socket.sendto(echo_data,iport)#将内容响应到发送端上
if __name__ == '__main__':
main()
#------------这是客户端----------
import socket
SERVER_HOST='127.0.0.1'#要连接的服务端的主机名称或ip地址
SERVER_PORT=8080
def main():
with socket.socket(socket.AF_INET,socket.SOCK_DGRAM) as client_socket:#建立客户端socket
while True:#客户端要不断与服务端交互
input_data=input('请输入要发送的数据(输入byebye结束):')
client_socket.sendto(input_data.encode(),(SERVER_HOST,SERVER_PORT))#数据发送
if input_data:#如果有数据
echo_data=client_socket.recv(100).decode()#响应数据
print('服务端响应数据: %s'%echo_data)#输出内容
else:#没有数据 (直接回车表示程序结束)
break #退出交互
if __name__ == '__main__':
main()
6.UDP广播
使用UDP除了可以建立快速的网络通讯之外,实际还有一个主要的功能就是实现数据广播的操作,它可以实现一个局域网内的所有主机信息的广播处理,要实现UDP广播操作,则一定要在程序之中使用如下的方法进行定义:
setsockopt(self,level:int,optname:int,value:Union[int,bytes])
#level:设置选项所在的协议层编号,有如下四个可用的配置项
#socket.SOL_SOCKET:基本套接字接口
#socket.IPPROTO_IP:IP4套接字接口
#socket.IPPROTO_IPV6:IPv6套接字接口
#socket.IPPROTO_TCP:TCP套接字接口
#optname:设置选项名称,例如,如果要进行广播则可以使用 socket.BROADCAST
#value:设置选项的具体内容
如果要进行广播肯定要有广播的接收端,而接收端不一定可以接收到广播,但只要打开接收端就可以接收到广播
#------------这是广播接收端----------
import socket
BROADCAST_CLIENT_ADDR=('0.0.0.0',21567)#客户端的绑定地址 当前主机
SERVER_HOST='127.0.0.1'#要连接的服务端的主机名称或ip地址
SERVER_PORT=8080
def main():
with socket.socket(socket.AF_INET,socket.SOCK_DGRAM) as client_socket:#建立客户端socket
client_socket.setsockopt(socket.SOL_SOCKET,socket.SO_BROADCAST,1)#设置广播模式
client_socket.bind(BROADCAST_CLIENT_ADDR)#绑定广播客户端地址
while True:#不断进行接收
message,iport=client_socket.recvfrom(100)#接收广播信息
print('接收的消息内容为%s,消息来源%s,消息端口%s'%(message.decode(),iport[0],iport[1]))
if __name__ == '__main__':
main()
当客户端执行后就持续等待服务端消息的发送,就跟所有手机一样,如果手机没有待机的状态轮询服务器,那么就不可能接听电话或者短息。
#-------------这是广播发送端--------
import socket
BROADCAST_SERVER_ADDR=('' ,21567)#设置广播地址
def main():
#socket网络服务每一次处理完成之后一定要使用close()关闭,所以使用with结构定义
#socket.AF_INET ip4网络协议进行服务端创建
#socket.SOCK_DGRAM创建一个数据报协议的服务端(UDP)
with socket.socket(socket.AF_INET,socket.SOCK_DGRAM) as server_socket:#创建服务端Socket
server_socket.setsockopt(socket.SOL_SOCKET,socket.SO_BROADCAST,1)#设置广播模式
server_socket.sendto('这是广播发送端'.encode(),BROADCAST_SERVER_ADDR)
if __name__ == '__main__':
main()
在进行广播处理的时候只需要设置一个《 broadcast》地址就可以实现广播的处理,而对于接收端而言则不能保证信息可以正常接收
7.HTTP
在标准的网络通信之中使用的是socket编程,而socket编程是对TCP/UDP协议进行抽象实现,在整个实现之中,可以清楚的发现,几乎不需要过多的考虑TCP/UDP实现细节,而后完全基于socket就可以非常简单的实现了
但是socket编程本身会存在一个问题,就是必须提供两个程序端:客户端/服务端,服务端是整个网络编程的核心所在,但是如果每一次服务端的升级都需要进行客户端的强制更新,那么这种做法就会显得非常麻烦了,所以在传统网络编程的基础上就形成了HTTP协议(是针对TCP协议的一种更高级的包装,TCP协议本身存有性能问题,所以HTTP实现也可能产生更大的性能问题,所以未来可能在UDP协议基础上实现HTTP协议)。
HTTP协议是一种应用在www万维网上实现数据传输的一种数据交互协议。客户端基于浏览器向服务器端发送HTTP服务请求,服务端会根据用户的请求进行数据文件的加载,并将要回应的数据信息以HTML文件格式进行传输,当浏览器接收到此数据信息时就可以直接进行代码的解析并将数据信息显示给用户浏览
在整个的HTTP开发流程之中,最为重要的设计就放在HTML代码的编写上,对于WEB服务器开发者而言更为重要是清楚HTTP服务器的开发
虽然HTTP是基于TCP协议基础之上开发的新协议,但其本质并没有脱离传统的TCP协议(可靠连接,数据交互),随后在TCP协议的基础上扩充了HTTP自己的内容,就成为了新的协议,而这些内容实际上都是随着每一次请求和响应的头部信息来进行发送的

在整个HTTP请求和响应的处理过程中,核心问题就在于:请求和响应的头部信息有哪些,响应状态码(HTTP服务请求之后的状态码是确定响应能否正确执行的关键部分)
在HTTP协议之中,为了便于用户的请求,所以设计有多种请求模式(比较常见的就是get/post),对于一些流行的Restful设计的结构,有可能会进行这些不同模式的请求区分,随着HTTP版本的不断提升,请求的模式也在不断的增加
| No | 方法 | 描述 |
|---|---|---|
| 1 | GET | 请求指定的页面信息,并返回实体主体 |
| 2 | HEAD | 类似于get请求,只不过返回的响应中没有具体的内容,用于获取请求头部数据 |
| 3 | POST | 向指定的资源提交数据进行处理请求(例如提交表单或上传文件) |
| 4 | PUT | 从客户端向服务器传输数据取代替指定文档的内容 |
| 5 | DELETE | 请求服务器删除指定的页面 |
| 6 | CONNECT | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器 |
| 7 | OPTIONS | 允许客户端查看服务器的性能 |
| 8 | TRACE | 回显服务器接收到的请求,主要用于测试或诊断 |
在每一次客户端发送HTTP请求的时候除了真实的内容之外,还会包含有许多的头部信息
| No | 头部信息 | 描述 | 实例 |
|---|---|---|---|
| 1 | Accept | 设置客户端显示类型 | Accept: text/html,application |
| 2 | Accept-Encoding | 设置浏览器可以支持的压缩编码类型 | Accept-Encoding: gzip, deflate, br |
| 3 | Accept-Language | 浏览器可接受的语言 | Accept-Language: zh-CN,zh;q=0.9 |
| 4 | Cookie | 将客户端保存的数据发送到服务器 | Cookie:name=lsf |
| 5 | Content-Length | 请求内容的长度 | Content-Length:348 |
| 6 | Content-Type | 请求与实体对应的MIME信息 | |
| 7 | HOST | 请求主机 | HOST:www.baidu.com |
| 8 | Referer | 访问来路 | Referer:https://www.baidu.com.html |
服务器能否正常运行,还有一个关键性的问题,就是服务器端对于请求的响应编码回应
| 分类 | 描述 |
|---|---|
| 1** | 信息,服务器接收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发送了错误 |
在每一次HTTP服务器响应的时候实际也存在各种头信息,这些头信息实际上就是告诉浏览器该如何解释代码
| No | 头信息 | 描述 |
|---|---|---|
| 1 | Content-Encoding | 返回压缩编码类型 |
| 2 | Content-Language | 响应内容支持的语言 |
| 3 | Content-Length | 响应内容的长度 |
| 4 | Content-Type | 响应数据的MIME类型 |
| 5 | Last-Modified | 请求资源的最后修改时间 |
| 6 | Location | 重定向路径 |
| 7 | refersh | 资源定时刷新配置 |
| 8 | Server | web服务器软件名称 |
| 9 | Set-Cookie | 设置Http C ookie |
8.HTTP响应
在HTTP编程之中核心的本质依旧是进行请求和响应,只不过这个响应处理数据之外还需包含头信息,这些内容一定要被浏览器进行解析,浏览器在进行请求的时候需要依据服务器的主机名称和访问端口进行请求的发送,
所有的HTTP服务器一定要通过浏览器进行访问,服务器绑定在本机的80端口上,那么就可直接进行本地服务访问,浏览器输入:http://localhost
#---------------http基础服务端---------
import socket #http是基于TCP协议,所以一定使用socket
import multiprocessing #考虑到性能问题,为每一次请求开启一个新的进程
class HttpServer:
'''服务器的程序类'''
def __init__(self,port):#服务器要有一个监听的端口
self.server_socket=socket.socket(socket.AF_INET,socket.SOCK_STREAM)#创建socket实例
#考虑到不同系统的问题,80端口是一个必争端口,该端口属于系统的核心端口,所以将核心任务与核心端口绑定
self.server_socket.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
self.server_socket.bind(('0.0.0.0',port))#绑定核心端口
self.server_socket.listen()#启动监听
def start(self):
'''服务器开始提供服务'''
while True:#持续提供服务
cli_socket,iport=self.server_socket.accept()#接收客户端请求
print('新的客户端连接,客户端ip:%s,客户端端口:%s'%(iport[0],iport[1]))#输出客户端信息
#将客户端都设置为一个独立的进程存在 都分别进行请求的回应
handle_cli_process=multiprocessing.Process(target=self.handle_response,args=(cli_socket,))
handle_cli_process.start()#进程启动
def handle_response(self,cli_socket):
'''对每一个指定的客户端进行响应'''
request_headers=cli_socket.recv(1024)#用户通过浏览器发送的请求本身就携带头信息
print('客户端请求头信息:%s'%request_headers.decode())#输入用户请求头信息
response_start_line='HTTP/1.1 200 OK'#本次的响应成功
response_headers='Server: wph Server\r\nContent-Type:text/html\r\n'#可以添加更多的响应头信息
response_body= ''\
' '\
' 测试 '\
' '\
' '\
''\
' 测试页面
'\
''\
''
response=response_start_line+response_headers+'\r\n'+response_body#最终的响应内容
cli_socket.send((response).encode())#服务端响应
cli_socket.close()#HTTP不保留用户状态,所以每次处理后都断开连接,否则会造成性能开支,且这些开支是无意义的
def main():
http_server=HttpServer(80)#80为服务器的默认端口,可以不用输入,直接输入域名即可
http_server.start()#开启服务
if __name__ == '__main__':
main()
9.建立响应目录
如果html代码以字符串的形式出现在整个Python程序里面,那么这样的HTML代码是很难被前端进行维护的,前端需要的是一个可以进行响应的处理目录,相当于建立一个专属的html响应代码目录,而后所有要响应的内容都要保存在此目录之中
#---------------http基础服务端---------
import socket #http是基于TCP协议,所以一定使用socket
import re
import os #进行文件路径的定义
#os.getcwd() 当前文件的根目录 os.sep \
HTML_ROOT_DIR=os.getcwd()+os.sep#响应目录
import multiprocessing #考虑到性能问题,为每一次请求开启一个新的进程
class HttpServer:
'''服务器的程序类'''
def __init__(self,port):#服务器要有一个监听的端口
self.server_socket=socket.socket(socket.AF_INET,socket.SOCK_STREAM)#创建socket实例
#考虑到不同系统的问题,80端口是一个必争端口,该端口属于系统的核心端口,所以将核心任务与核心端口绑定
self.server_socket.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
self.server_socket.bind(('0.0.0.0',port))#绑定核心端口
self.server_socket.listen()#启动监听
def start(self):
'''服务器开始提供服务'''
while True:#持续提供服务
cli_socket,iport=self.server_socket.accept()#接收客户端请求
print('新的客户端连接,客户端ip:%s,客户端端口:%s'%(iport[0],iport[1]))#输出客户端信息
#将客户端都设置为一个独立的进程存在 都分别进行请求的回应
handle_cli_process=multiprocessing.Process(target=self.handle_response,args=(cli_socket,))
handle_cli_process.start()#进程启动
def handle_response(self,cli_socket):
'''对每一个指定的客户端进行响应'''
request_headers=cli_socket.recv(1024)#用户通过浏览器发送的请求本身就携带头信息
#使用正则提取请求头信息
file_name=re.match(r'\w+ +(/[^ ]*)',request_headers.decode().split('\r\n')[0]).group(1)
# file_name=request_headers.decode().split(' ',2)[1]
if file_name=='/':
file_name= 'wenjian/index.html' #为根目录
if file_name.endswith('.wenjian') or file_name.endswith('.htm'):
cli_socket.send(self.get_html_data(file_name).encode())#服务端响应
else:#二进制图表内容
cli_socket.send(self.get_binary_data(file_name))#响应二进制数据
cli_socket.close()#HTTP不保留用户状态,所以每次处理后都断开连接,否则会造成性能开支,且这些开支是无意义的
def read_file(self,file_name):#读文件数据
file_path=os.path.normpath(HTML_ROOT_DIR+file_name)#文件的完整路径
file=open(file_path,'rb')#采用二进制流的形式读取
file_data=file.read()#读取文件内容
file.close()
return file_data #返回读取的数据
def get_binary_data(self,file_name):#二进制文件的读取
response_body=self.read_file(file_name)
return response_body
def get_html_data(self,file_name):#读取指定文件
response_start_line = 'HTTP/2 200 OK\r\n'
# 响应头
response_headers = 'Server PWS/2.0\r\n' # 可以添加更多的响应头信息
response_body =self.read_file(file_name).decode()#设置响应内容
response = response_start_line + response_headers + '\r\n' + response_body # 最终的响应内容
return response
def main():
http_server=HttpServer(80)#80为服务器的默认端口,可以不用输入,直接输入域名即可
http_server.start()#开启服务
if __name__ == '__main__':
main()
10.动态请求处理
对于web开发来说,分为两个处理阶段:静态web处理,动态web处理,在之前设置的响应目录实际上就是属于静态web处理,而动态web是可以进行动态的判断来决定最终返回的数据内容。
#---------------http基础服务端---------
import socket #http是基于TCP协议,所以一定使用socket
import re
import os #进行文件路径的定义
import sys #模块加载定位
sys.path.append('page')#追加模块加载路径
#os.getcwd() 当前文件的根目录 os.sep \
# HTML_ROOT_DIR=os.getcwd()+os.sep#响应目录
# HTML_ROOT_DIR=r'F:\pythonstudy\python-Study\静态Web服务器搭建\wenjian\static'#响应目录
HTML_ROOT_DIR=r'F:\pythonstudy\python-Study\静态Web服务器搭建\wenjian'#响应目录
import multiprocessing #考虑到性能问题,为每一次请求开启一个新的进程
class HttpServer:
'''服务器的程序类'''
def __init__(self,port):#服务器要有一个监听的端口
self.server_socket=socket.socket(socket.AF_INET,socket.SOCK_STREAM)#创建socket实例
#考虑到不同系统的问题,80端口是一个必争端口,该端口属于系统的核心端口,所以将核心任务与核心端口绑定
self.server_socket.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
self.server_socket.bind(('0.0.0.0',port))#绑定核心端口
self.server_socket.listen()#启动监听
def start(self):
'''服务器开始提供服务'''
while True:#持续提供服务
cli_socket,iport=self.server_socket.accept()#接收客户端请求
print('新的客户端连接,客户端ip:%s,客户端端口:%s'%(iport[0],iport[1]))#输出客户端信息
#将客户端都设置为一个独立的进程存在 都分别进行请求的回应
handle_cli_process=multiprocessing.Process(target=self.handle_response,args=(cli_socket,))
handle_cli_process.start()#进程启动
def handle_response(self,cli_socket):
'''对每一个指定的客户端进行响应'''
request_headers=cli_socket.recv(1024)#用户通过浏览器发送的请求本身就携带头信息
print(request_headers.decode())
#使用正则提取请求头信息
# file_name=re.match(r'\w+ +(/[^ ]*)',request_headers.decode().split('\r\n')[0]).group(1)
file_name=request_headers.decode().split(' ',2)[1]
if file_name.startswith('/page'):#要访问的是一个动态页面
request_name=file_name[file_name.index('/',1)+1:]#访问路径
print('访问路径:"',request_name)
param_value=""#请求参数
if request_name.__contains__('?'):#参数路径分隔符
request_param=request_name[request_name.index('?')+1:]
param_value=request_param.split('=')[1]#获取参数名称
request_name=request_name[0:request_name.index('?')]#获取模块名称
model_name=request_name.split('/')[0]#模块名称
method_name=request_name.split('/')[1]#函数名称
model=__import__(model_name)#加载模块
method=getattr(model,method_name)
response_body=method(param_value)
response_start_line = 'HTTP/2 200 OK\r\n'
response_headers = 'Server PWS/2.0\r\n' # 可以添加更多的响应头信息
response = response_start_line + response_headers + '\r\n' + response_body # 最终的响应内容
cli_socket.send(response.encode())
cli_socket.close()#HTTP不保留用户状态,所以每次处理后都断开连接,否则会造成性能开支,且这些开支是无意义的
def main():
http_server=HttpServer(80)#80为服务器的默认端口,可以不用输入,直接输入域名即可
http_server.start()#开启服务
if __name__ == '__main__':
main()
#page包中echo.py文件
def service(param):#响应的处理函数
if param:#如果此时的param有数据
return ''
+param+''
else:
return 'NO found
'
#访问路径:http://localhost/page/echo/service?param=
11.urllib3
urllib是Python中提供的一个url请求访问的模块,利用该模块可以实现浏览器的模拟访问,而urllib3是此模块的升级版,主要是为Python3服务的,两者功能类似,只不过有一些细微的差别
#--------------urllib3--------------
import urllib3
url='http://www.baidu.com'#页面的访问路径
def main():
request_headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4676.0 Safari/537.36'
}
http=urllib3.PoolManager(num_pools=5,headers=request_headers)#获取urllib3进程管理对象
response=http.urlopen('GET',url)#发送get请求
print(response.headers)#响应头信息
print(response.data.decode())#响应文件
pass
if __name__ == '__main__':
main()
12.twisted模块认识
java中的IO:
- 传统BIO模型–同步阻塞IO
- 伪异步IO模型–以BIO为基础,通过线程方式维护所有IO线程,实现相对高效的线程开销及管理
- NIO模型–一种同步非阻塞IO
twisted类似NIO,是Python之中提供的专门实现异步处理的IO概念,它的主要功能是提升服务端数据的处理能力
难道使用多进程,多线程等并发技术不能良好的解决性能问题吗?
要想理解twisted设计思想,那么首先就必须清楚传统服务器端程序开发中存在的问题?
为了让服务端的程序更加高效的客户端请求处理,所以引入并发编程,将每一个客户端单独启动一个进程或线程,这样就可以实现服务器的并发响应

对于此时的开发架构已经充分的发挥出了电脑硬件性能的作用,使用硬件提供的核心支持,进行并发编程实现,但需要清楚的是早期的电脑硬件是没有这样所谓的多核CPU概念的,早期的设计里面使用的单核CPU,需要非常细致的解决不同进程以及线程彼此间所谓的等待与唤醒机制(死锁问题),虽然单进程性能不高,但是却可以有效的解决所谓的不同进程或线程之间可能产生的死锁问题。
如果不使用并发编程的形式,那么就不会有并发编程之中的问题(资源切换,系统调度,同步与等待所带来的性能损耗)
所有的传统服务端,如果采用的是阻塞的模式,那么就会持续发生等待的操作问题,而这种等待的问题是严重的损耗服务端性能的,即便服务端硬件在强大,损耗也挺严重。
阻塞IO本质:使用水壶烧开水,在旁边盯着看,怕水开后,水壶烧坏
非阻塞IO本质:不盯着水壶,对水壶进行定期的不断轮询,没开就继续干其他事,开了就结束烧水
twisted是一个事件驱动的网络引擎,最大特点是提供有一个事件循环处理,当外部事件发生时使用回调机制来触发相应的处理操作,多个任务在一个线程中执行,,这种方式可以使程序尽可能的减少对于其他线程的依赖,也使得程序开发人员不在关注线程安全问题
twsited中所有处理事件(注册,注销,运行,回调处理等)全部交由reactor进行统一管理,在整个程序运行过程中,reactor循环会以单线程的模式持续运行,当需要执行回调处理时reactor会暂停循环,当回调操作执行完毕后将继续采用循环的形式进行其他任务处理,由于这种操作是从平台行为中抽象出来的,这样就使得网络协议栈的任何位置很容易的进行事件响应

13.twisted开发TCP程序
使用twisted最大的特点是进行服务端程序的开发,这样的开发会为服务端的资源利用带来极大的便利
使用twisted实现echo程序
如果要实现echo服务端程序的开发,那么让服务端的处理类继承一个twisted.internet.protocol.Protocol 父类,随后就根据自己的需要来选择要复写的方法
#-------twisted服务端程序----------
import twisted #pip install Twisted
import twisted.internet.protocol
import twisted.internet.reactor
SERVER_PORT=8080#设置监听端口
class Server(twisted.internet.protocol.Protocol):#服务端一定要设置一个继承父类
def connectionMade(self):#客户端连接时触发
print('客户端地址:%s'%self.transport.getPeer().host)
def dataReceived(self,data):#接收客户端数据
print('服务端接受到的数据%s'%data.decode())#输出接收到的数据
self.transport.write(('echo %s'%data.decode()).encode())#回应
class DefaultServerFactory(twisted.internet.protocol.Factory):#定义处理工厂类
protocol=Server#注册回调操作
def main():
twisted.internet.reactor.listenTCP(SERVER_PORT,DefaultServerFactory())#服务监听
print('服务启动完毕,等待客户端连接。。。')
twisted.internet.reactor.run()#事件轮询
if __name__ == '__main__':
main()
处理流程:定义事件的处理回调操作程序–工厂中注册–Reactor依据工厂来获得相应的事件回调处理操作类
#---------------twisted客户端----------
import twisted
import twisted.internet.protocol
import twisted.internet.reactor
SERVER_HOST='localhost'#服务主机
SERVER_PORT=8080#连接端口
class Client(twisted.internet.protocol.Protocol):#定义用户端处理类
def connectionMade(self):
print('服务器连接成功,可以进行数据交互,若要结束,则直接回车,,')
self.send()#建立连接后就进行数据的发送
def dataReceived(self,data):#接收服务端的数据
print('服务端 接收到数据:%s'%data.decode())#输出接收到的数据
self.send()#继续发送
def send(self):#数据发送 自定义的方法
input_data=input('请输入要发送的数据:')
if input_data:#如果有数据
self.transport.write(input_data.encode())
else:#没有输入内容,表示操作的结束
self.transport.loseConnection()#关闭连接
class DefaultClientFactory(twisted.internet.protocol.ClientFactory):#客户端工厂
protocol=Client#定义回调
clientConnectionLost=clientConnectionFailed=lambda self,connector,reason:twisted.internet.reactor.stop()#停止循环
def main():
twisted.internet.reactor.connectTCP(SERVER_HOST,SERVER_PORT,DefaultClientFactory())#连接主机服务
twisted.internet.reactor.run()#程序运行
if __name__ == '__main__':
main()
通过程序执行结果可以发现,此处避免了非常繁琐的并发控制的操作,没有了多进程或多线程的操作控制部分,整个执行流程都是基于单线程的运行模式完成(Python中的多线程存在GIL全局锁问题,这就解决了此类问题)
14.使用twisted开发UDP程序
TCP是面向连接的可靠的网络服务,所以不管使用的是socket还是twisted都需要进行连接的操作控制,这样一定会造成不必要的性能开支,所以twisted内部也支持有UDP程序开发,因为UDP不需要保证可靠连接,所以只需要定义好用户的处理回调操作即可。
#----------UDP twisted服务端-------
import twisted
import twisted.internet.protocol
import twisted.internet.reactor
SERVER_PORT=8080
class EchoServer(twisted.internet.protocol.DatagramProtocol):#数据报协议
def datagramReceived(self,datagram,addr):#接收数据处理
print('服务端 接收到消息,消息来源IP:%s,来源端口:%s'% addr)
print('服务端 接收到数据消息:%s'%datagram.decode())
echo_data='echo %s'%datagram.decode()#设置回应信息
self.transport.write(echo_data.encode(),addr)#将信息返回给指定客户端
def main():
twisted.internet.reactor.listenUDP(SERVER_PORT,EchoServer())#服务监听
print('服务器启动完成,等待客户端连接。。。')
twisted.internet.reactor.run()#事件循环
if __name__ == '__main__':
main()
使用UDP进行处理的时候不在需要使用那些连接的控制,同时也不在需要通过工厂才可以与Reactor进行衔接,从结构上更加的简单了
#------------UDP twisted客户端操作---------
import twisted
import twisted.internet.reactor
import twisted.internet.protocol
SERVER_HOST='127.0.0.1'
SERVER_PORT=8080
CLIENT_PORT=0#客户端地址
class EchoClient(twisted.internet.protocol.DatagramProtocol):#UDP客户端1
def startProtocol(self):#连接的回调
self.transport.connect(SERVER_HOST,SERVER_PORT)#连接
print('服务器连接成功,可以进行数据交互,如果要结束会话,直接回车')
self.send()#消息发送
def datagramReceived(self,datagram,addr):#接收数据处理
print(datagram.decode())
self.send()#下一次数据发送
def send(self):#数据发送 自定义方法
input_data=input('请输入要发送的信息:')
if input_data:
self.transport.write(input_data.encode())
else:
twisted.internet.reactor.stop()#停止轮询
def main():
twisted.internet.reactor.listenUDP(CLIENT_PORT,EchoClient())#服务监听
twisted.internet.reactor.run()#开启事件循环
if __name__ == '__main__':
main()
所有网络程序进行开发的过程中实际上只有一个核心的目的:提升服务端的资源的可用性(发挥出最大的性能),减少操作的延迟,但是,UDP当今的应用都是在即时消息通讯操作上,而对于TCP的开发操作依然是主流
15.Deferred
在网络开发之中,对于服务端性能提升可以使用twisted直接完成,但是在一些客户端与网络服务器端交互的过程之中,有可能下载需要下载一些比较庞大的文件内容(图片,视频等等),按照传统的客户端的开发模型来讲,此时就需要持续进行下载,而对于当前的客户端也将进入到一个阻塞的开发状态,那么在这样的情况下为了解决客户端的阻塞问题,就提供了Deferred的概念
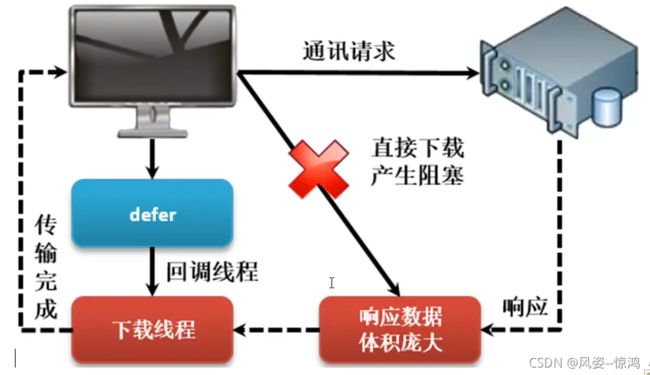
在twisted设计之中最大的特点就是持续的强调采用非阻塞的形式来完成,同时尽可能的减少并发操作,通过事件轮询的方式来提升程序的可用资源,基于事件轮询的机制设计出一套Deferred的模型

#------------defered模拟--------
import twisted
import twisted.internet.reactor
import twisted.internet.defer
import time
class DeferHandle:#设置一个回调处理类
def __init__(self):
self.defer=twisted.internet.defer.Deferred()#获取defer对象
def get_defer(self):#让外部获得实例对象
return self.defer
def work(self):#模拟网络下载
print('模拟网络下载延时操作,等待3秒。。。')
time.sleep(3)
self.defer.callback('finish')#执行回调
def handle_success(self,result):
print('处理完成,进行参数的接收:%s'%result)#处理完毕后的信息输出
def handle_error(self,exp):#错误回调
print('程序出错:%s'%exp)
def stop():
twisted.internet.reactor.stop()
print('服务调用结束~~~~')
def main():
defer_client=DeferHandle()#获得当前的回调操作
twisted.internet.reactor.callWhenRunning(defer_client.work)#执行耗时操作
defer_client.get_defer().addCallback(defer_client.handle_success)#设置回调处理 执行完毕后的回调
defer_client.get_defer().addErrback(defer_client.handle_error)#错误输出时的回调
twisted.internet.reactor.callLater(5,stop)#5秒后停止Reactor调用
twisted.internet.reactor.run()#启用事件的循环
if __name__ == '__main__':
main()
在整个程序执行完毕后,就可以直接利用所设置的calback()操作进行操作完成后的调用,基于这样的操作模型就减少了并发编程的使用,但使用twisted程序都是在解决网络通讯的性能问题,那么最佳的做法肯定就是Defered应用在网络的开发环境中。
通过Deffer模型实现TCP的echo客户端
#----------defer TCP 客户端-------
import twisted
import twisted.internet.defer
import twisted.internet.protocol
import twisted.internet.reactor
import twisted.internet.threads#自己控制的线程
import time
SERVER_HOST='localhost'
SERVER_PORT=8080
class DeferClient(twisted.internet.protocol.Protocol):#回调处理类
def connectionMade(self):#创建连接
print('服务器连接成功,可以进行通信,如果要结束会话,直接回车即可')
self.send()#信息发送
def dataReceived(self,data):#接收服务端发送的数据
content=data.decode()#接收服务端发送的数据
twisted.internet.threads.deferToThread(self.handle_request,content).addCallback(self.handle_success)
def handle_request(self,content):#数据处理过程
print('客户端 对服务端的数据 %s 进行处理,可能会产生1~2秒延迟。。。'%content)
time.sleep(1)
return content #返回处理结果
def handle_success(self,result):#操作处理完毕
print('处理完成,进行参数的接收:%s'%result)
self.send()#下一的数据发送
def send(self):#数据发送 自定义方法
input_data=input('请输入要发送的信息:')
if input_data:
self.transport.write(input_data.encode())
else:
self.transport.loseConnection()#关闭连接
class DefaultClientFactory(twisted.internet.protocol.ClientFactory):#客户端工厂
protocol=DeferClient#设置回调处理
clientConnectionLost=clientConnectionFailed=lambda self,connector,reason:twisted.internet.reactor.stop()
def main():
twisted.internet.reactor.connectTCP(SERVER_HOST,SERVER_PORT,DefaultClientFactory())#服务监听
twisted.internet.reactor.run()#程序运行
if __name__ == '__main__':
main()
这种交互的模型主要是Deferred优化了客户端之中的处理结构,在实际开发中,一个服务端有可能继续调用其他的服务器端,而这个服务器还有可能同时要处理用户的请求
- 无智亦无得,以无所得故