nonnegative matrix factorization (NMF)的R实现
非负矩阵分解(NMF)是一种最新的特征提取算法,与主成分分析(PCA)或独立成分分析(ICA)类似,非负矩阵分解(NMF)的目的是使用有限的基础成分来解释观察到的数据,这些成分组合在一起时尽可能准确地接近原始数据。换句话来说,NMF是一种降维方法。
NMF的显著特点是,代表基础成分的矩阵以及混合系数矩阵都被限制为非负项,并且没有对基础成分施加正交性或独立性的限制。
当有许多属性,并且这些属性是模糊的或具有较弱的可预测性时,NMF是有用的。通过组合属性,NMF可以产生有意义的模式、话题或主题。无标签的文档或文本集变得越来越大,这很常见,也很明显;挖掘这样的数据集是一项具有挑战性的任务。在模型应用过程中,NMF模型将原始数据映射到模型发现的新属性集(特征)。
NMF方法已成功应用于多个领域,包括图像和模式识别、信号处理和文本挖掘。NMF还被应用于获得基于基因表达芯片的癌症类型发现的新见解,用于基因的功能表征,从位置字数矩阵中预测顺式调控元素,最近还被用于使用跨平台芯片数据的表型预测。
R实现:
数据来源: RPubs - Analyze text content of multiple websites.
m <- read.csv(file="D:/R_Files/corpus/tdm.csv")
head(m)## X d1.txt d2.txt d3.txt
## 1 additional 1 0 0
## 2 administrative 1 0 0
## 3 affairs 1 1 0
## 4 affected 2 0 0
## 5 affecting 1 0 0
## 6 afternoon 1 0 0rownames(m) <- m[,1]
m[,1] <- NULL
res <- nmf(m, 3,"KL")
w <- basis(res) # W user feature matrix matrix
dim(w)## [1] 622 3df <- as.data.frame(w)
head(df,10)## V1 V2 V3
## additional 2.220446e-16 2.220446e-16 16.15177
## administrative 2.220446e-16 2.220446e-16 16.15177
## affairs 2.220446e-16 1.364603e+01 16.15177
## affected 2.220446e-16 2.220446e-16 32.30354
## affecting 2.220446e-16 2.220446e-16 16.15177
## afternoon 2.220446e-16 2.220446e-16 16.15177
## also 2.220446e-16 4.093808e+01 16.15177
## although 2.220446e-16 2.220446e-16 16.15177
## amid 2.220446e-16 2.220446e-16 16.15177
## anantharaman 2.220446e-16 2.220446e-16 16.15177df$total <- rowSums(df)
df$word<-rownames(df)
colnames(df) <- c("doc1","doc2","doc3","total","word")
df <-df[order(-df$total),]
head(df,20)## doc1 doc2 doc3 total word
## taiwan 1.182388e+02 8.187616e+01 1.130624e+02 313.17734 taiwan
## august 2.220446e-16 2.046904e+02 2.220446e-16 204.69040 august
## said 2.220446e-16 4.093808e+01 1.615177e+02 202.45579 said
## power 2.220446e-16 2.220446e-16 1.938213e+02 193.82125 power
## chinese 1.970646e+01 8.187616e+01 2.220446e-16 101.58262 chinese
## foundation 9.853232e+01 2.220446e-16 2.220446e-16 98.53232 foundation
## heritage 9.853232e+01 2.220446e-16 2.220446e-16 98.53232 heritage
## taiwans 2.220446e-16 5.458411e+01 3.230354e+01 86.88765 taiwans
## relations 5.911939e+01 2.729205e+01 2.220446e-16 86.41145 relations
## government 3.941293e+01 1.364603e+01 3.230354e+01 85.36250 government
## president 3.941293e+01 1.364603e+01 3.230354e+01 85.36250 president
## air 2.220446e-16 8.187616e+01 2.220446e-16 81.87616 air
## blackout 2.220446e-16 2.220446e-16 8.075886e+01 80.75886 blackout
## director 7.882586e+01 2.220446e-16 2.220446e-16 78.82586 director
## min 5.911939e+01 2.220446e-16 1.615177e+01 75.27116 min
## read 5.911939e+01 2.220446e-16 1.615177e+01 75.27116 read
## security 5.911939e+01 2.220446e-16 1.615177e+01 75.27116 security
## aircraft 2.220446e-16 6.823013e+01 2.220446e-16 68.23013 aircraft
## defense 2.220446e-16 6.823013e+01 2.220446e-16 68.23013 defense
## caused 2.220446e-16 1.364603e+01 4.845531e+01 62.10134 causedwordMatrix = as.data.frame(w)
wordMatrix$word<-rownames(wordMatrix)
colnames(wordMatrix) <- c("doc1","doc2","doc3","word")
# Topic 1
newdata <-wordMatrix[order(-wordMatrix$doc1),]
head(newdata)## doc1 doc2 doc3 word
## taiwan 118.23879 8.187616e+01 1.130624e+02 taiwan
## foundation 98.53232 2.220446e-16 2.220446e-16 foundation
## heritage 98.53232 2.220446e-16 2.220446e-16 heritage
## director 78.82586 2.220446e-16 2.220446e-16 director
## min 59.11939 2.220446e-16 1.615177e+01 min
## read 59.11939 2.220446e-16 1.615177e+01 readd <- newdata
df <- as.data.frame(cbind(d[1:10,]$word,as.numeric(d[1:10,]$doc1)))
colnames(df)<- c("Word","Frequency")
# for ggplot to understand the order of words, you need to specify factor order
df$Word <- factor(df$Word, levels = df$Word[order(df$Frequency)])
ggplot(df, aes(x=Word, y=Frequency)) +
geom_bar(stat="identity", fill="lightgreen", color="grey50")+
coord_flip()+
ggtitle("Topic 1")
# Topic 2
newdata <-wordMatrix[order(-wordMatrix$doc2),]
head(newdata)## doc1 doc2 doc3 word
## august 2.220446e-16 204.69040 2.220446e-16 august
## taiwan 1.182388e+02 81.87616 1.130624e+02 taiwan
## air 2.220446e-16 81.87616 2.220446e-16 air
## chinese 1.970646e+01 81.87616 2.220446e-16 chinese
## aircraft 2.220446e-16 68.23013 2.220446e-16 aircraft
## defense 2.220446e-16 68.23013 2.220446e-16 defensed <- newdata
df <- as.data.frame(cbind(d[1:15,]$word,as.numeric(d[1:15,]$doc2)))
colnames(df)<- c("Word","Frequency")
df$Word <- factor(df$Word, levels = df$Word[order(df$Frequency)])
ggplot(df, aes(x=Word, y=Frequency)) +
geom_bar(stat="identity", fill="lightgreen", color="grey50")+
coord_flip()+
ggtitle("Topic 2")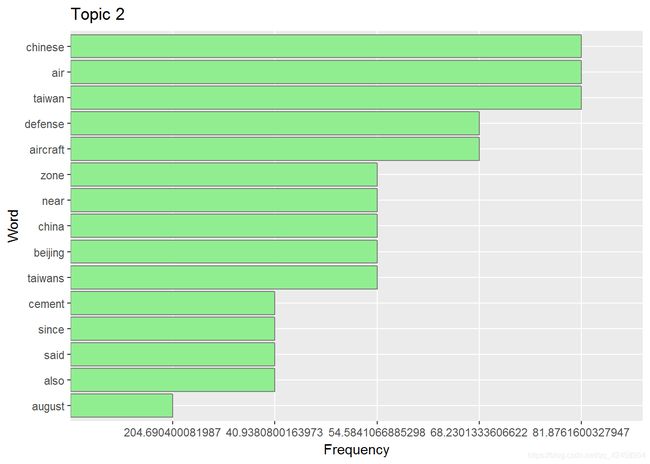
# Topic 3
newdata <-wordMatrix[order(-wordMatrix$doc3),]
head(newdata)## doc1 doc2 doc3 word
## power 2.220446e-16 2.220446e-16 193.82125 power
## said 2.220446e-16 4.093808e+01 161.51771 said
## taiwan 1.182388e+02 8.187616e+01 113.06240 taiwan
## blackout 2.220446e-16 2.220446e-16 80.75886 blackout
## caused 2.220446e-16 1.364603e+01 48.45531 caused
## corp 2.220446e-16 2.220446e-16 48.45531 corpd <- newdata
df <- as.data.frame(cbind(d[1:15,]$word,as.numeric(d[1:15,]$doc3)))
colnames(df)<- c("Word","Frequency")
df$Word <- factor(df$Word, levels = df$Word[order(df$Frequency)])
ggplot(df, aes(x=Word, y=Frequency)) +
geom_bar(stat="identity", fill="lightgreen", color="grey50")+
coord_flip()+
ggtitle("Topic 3")
ref:RPubs - NMF(Non-negative matrix factorization) for topic modeling
Gaujoux R, Seoighe C. A flexible R package for nonnegative matrix factorization. BMC bioinformatics. 2010 Dec;11(1):1-9.