yolo.py代码精读
1.parse_model函数,读入模型yaml中的参数定义
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelistch
input channels

第一列,即全是-1的这一列,代表输入层,如果是-1就代表是上一层。而Focus这一列是模块的名字,卷积核个数后面分别是卷积核尺寸和降采样尺寸。
m = eval(m) if isinstance(m, str) else meval
在全局变量和局部变量的上下文中计算给定的源。m是module
下面这些是解析args里面的str
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except NameError:
pass像这种:

ch
在下面用到:
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out从函数入口传进来:
def parse_model(d, ch):引用:
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch])在__init__里面定成3:
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None):所以最上面 c2 = ch[-1] 取了个c2 = 3 出来
报错1
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except NameError:
passmake_divisivle()
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
def make_divisible(x, divisor):
# Returns x evenly divisible by divisor
return math.ceil(x / divisor) * divisorn
从这里进来:
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']):经过:
n = n_ = max(round(n * gd), 1) if n > 1 else n插回去(当然只有在m是这几种的情况下):
if m in [BottleneckCSP, C3, C3TR, C3Ghost]:
args.insert(2, n) # number of repeats
n = 1c2
m
m接了module的值,经过:
m = eval(m) if isinstance(m, str) else m # eval stringsm='Conv'
变成:
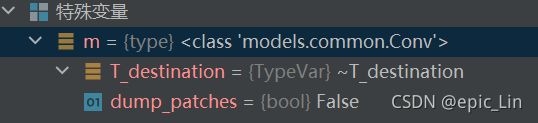

m_是真正有各种参数的module,m更多只是一个名字
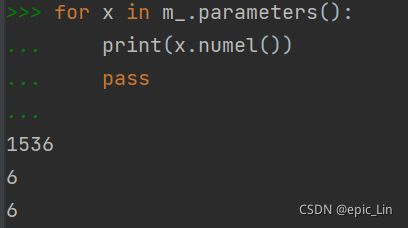
 x = m_.parameters()是一个迭代器:
x = m_.parameters()是一个迭代器:

迭代出三个东西:
save
非常神奇:
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistregister_buffer()
self.register_buffer(‘my_buffer’, self.tensor):my_buffer是名字,str类型;self.tensor是需要进行register登记的张量。这样我们就得到了一个新的张量,这个张量会保存在model.state_dict()中,也就可以随着模型一起通过.cuda()复制到gpu上。
2. class Detect
x
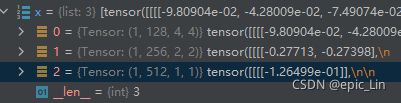
经过:
x[i] = self.m[i](x[i])得到(1,256,4,4)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()变成:(na=3,ny=nx=4,no=85)
![]()
这里就是最后的feature map了,nx=ny=4是feature map的大小,这里每个像素对应一个grid,3是channal个数。
onnx_dynamic
这个东西是什么意思
na、nl:
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchorsna是感受野的个数,nl是每个感受野的anchor个数,这里附上yolos.yaml中的anchor:

解析结果
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i] * self.stride[i]) # xy #最后一维就是85那个的解析
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh #2,3是w,hself.grid[i]是第几个格,大小是(1,3,4,4,2),y大小是[1,3,4,4,85], self.stride[i]是每个grid代表的原图中的像素倍数,即放大倍数
inplace
应该是本地计算的意思另外一个分支,else部分注释有AWS,是云计算的架构。
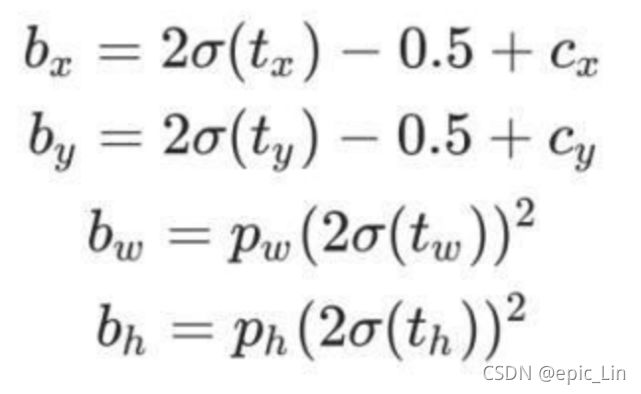
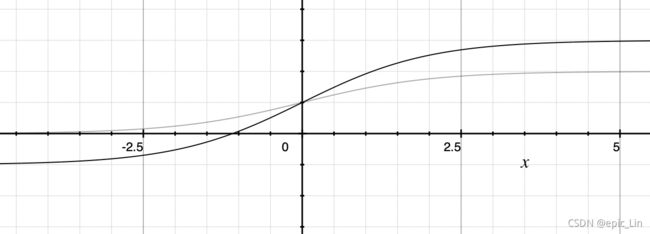

两个函数的对比,优化之后的在[-0.5,1.5],优化之前的sigmoid在[0,1],可以在超出一个格子的地方活动
整个Detect的forward过程
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no)) # no = 85, y.view=[1,3*80*80,85] y(1,3,80,80,85)
return x if self.training else (torch.cat(z, 1), x)每次i的循环,产生一个z,在我的例子中z的大小z[0]=(1,19200,85),z[1]=(1,4800,85),z[2]=(1,1200,85),19200=3*80*80,在dim=1上cat起来得到(1,25200,85)
_make_grid()
这里制造参数grid:
grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()用在:
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i]grid的形状是(1,3,4,4,2),y的形状是[1,3,4,4,85],grid中最后一维2对应x,y