深度学习:使用pytorch训练cifar10数据集(基于Lenet网络)
文档基于b站视频:https://www.bilibili.com/video/BV187411T7Ye
流程
- model.py ——定义LeNet网络模型
- train.py ——加载数据集并训练,训练集计算loss,测试集计算accuracy,保存训练好的网络参数
- predict.py——得到训练好的网络参数后,用自己找的图像进行分类测试
文件目录结构截图:
1. model.py
先给出代码,模型是基于LeNet做简单修改,层数很浅,容易理解:
# 使用torch.nn包来构建神经网络.
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module): # 继承于nn.Module这个父类
def __init__(self): # 初始化网络结构
super(LeNet, self).__init__() # 多继承需用到super函数
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x): # 正向传播过程
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
需注意:
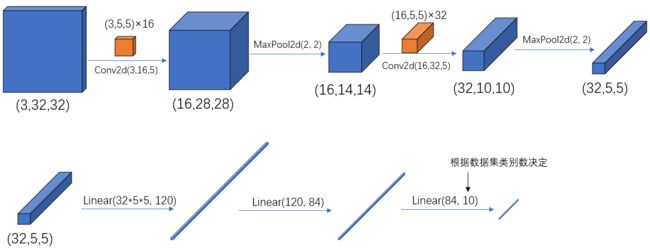
- pytorch 中 tensor(也就是输入输出层)的 通道排序为:
[batch, channel, height, width] - pytorch中的卷积、池化、输入输出层中参数的含义与位置,可配合下图一起食用:
2. train.py
2.1 导入数据集
导入包
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import time
数据预处理
对输入的图像数据做预处理,即由shape (H x W x C) in the range [0, 255] → shape (C x H x W) in the range [0.0, 1.0]
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
此demo用的是CIFAR10数据集,也是一个很经典的图像分类数据集,由 Hinton 的学生 Alex Krizhevsky 和 Ilya Sutskever 整理的一个用于识别普适物体的小型数据集,一共包含 10 个类别的 RGB 彩色图片。

导入、加载 训练集和测试集
import torch
import torchvision
import torch.nn as nn
from LeNetTest.model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import time
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
# 加载训练集,实际过程需要分批次(batch)训练
train_loader = torch.utils.data.DataLoader(train_set, batch_size=50,
shuffle=True, num_workers=0)
# 10000张测试图片
test_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=10000,
shuffle=False, num_workers=0)
# classes = ('plane', 'car', 'bird', 'cat',
# 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 获取测试集中的图像和标签,用于accuracy计算
test_data_iter = iter(test_loader)
test_image, test_label = test_data_iter.next()
#
# def imshow(img): # 展示测试集图片和标签
# img = img / 2 + 0.5 # unnormalize
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
#
# # print labels
# print(' '.join('%5s' % classes[test_label[j]] for j in range(4)))
# # show images
# imshow(torchvision.utils.make_grid(test_label))2.2 训练过程
| 名词 | 定义 |
|---|---|
| epoch | 对训练集的全部数据进行一次完整的训练,称为 一次 epoch |
| batch | 由于硬件算力有限,实际训练时将训练集分成多个批次训练,每批数据的大小为 batch_size |
| iteration 或 step | 对一个batch的数据训练的过程称为 一个 iteration 或 step |
以本demo为例,训练集一共有50000个样本,batch_size=50,那么完整的训练一次样本:iteration或step=1000,epoch=1
net = LeNet() # 定义训练的网络模型
loss_function = nn.CrossEntropyLoss() # 定义损失函数为交叉熵损失函数
optimizer = optim.Adam(net.parameters(), lr=0.001) # 定义优化器(训练参数,学习率)
for epoch in range(5): # 一个epoch即对整个训练集进行一次训练
running_loss = 0.0
time_start = time.perf_counter()
for step, data in enumerate(train_loader, start=0): # 遍历训练集,step从0开始计算
inputs, labels = data # 获取训练集的图像和标签
optimizer.zero_grad() # 清除历史梯度
# forward + backward + optimize
outputs = net(inputs) # 正向传播
loss = loss_function(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 优化器更新参数
# 打印耗时、损失、准确率等数据
running_loss += loss.item()
if step % 1000 == 999: # print every 1000 mini-batches,每1000步打印一次
with torch.no_grad(): # 在以下步骤中(验证过程中)不用计算每个节点的损失梯度,防止内存占用
outputs = net(test_image) # 测试集传入网络(test_batch_size=10000),output维度为[10000,10]
predict_y = torch.max(outputs, dim=1)[1] # 以output中值最大位置对应的索引(标签)作为预测输出
accuracy = (predict_y == test_label).sum().item() / test_label.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' % # 打印epoch,step,loss,accuracy
(epoch + 1, step + 1, running_loss / 500, accuracy))
print('%f s' % (time.perf_counter() - time_start)) # 打印耗时
running_loss = 0.0
print('Finished Training')
# 保存训练得到的参数
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
2.3 使用GPU/CPU训练
使用下面语句可以在有GPU时使用GPU,无GPU时使用CPU进行训练
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
对应的,需要用to()函数来将Tensor在CPU和GPU之间相互移动,分配到指定的device中计算
net = LeNet()
net.to(device) # 将网络分配到指定的device中
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
for epoch in range(5):
running_loss = 0.0
time_start = time.perf_counter()
for step, data in enumerate(train_loader, start=0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs.to(device)) # 将inputs分配到指定的device中
loss = loss_function(outputs, labels.to(device)) # 将labels分配到指定的device中
loss.backward()
optimizer.step()
running_loss += loss.item()
if step % 1000 == 999:
with torch.no_grad():
outputs = net(test_image.to(device)) # 将test_image分配到指定的device中
predict_y = torch.max(outputs, dim=1)[1]
accuracy = (predict_y == test_label.to(device)).sum().item() / test_label.size(0) # 将test_label分配到指定的device中
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 1000, accuracy))
print('%f s' % (time.perf_counter() - time_start))
running_loss = 0.0
print('Finished Training')
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
打印信息如下:

可以看到,用GPU训练时,速度提升明显,耗时缩小。
3. predict.py
随便搜一张图片放入根目录下面,然后导入:

# 导入包
import torch
import torchvision.transforms as transforms
from PIL import Image
from LeNetTest.model import LeNet
# 数据预处理
transform = transforms.Compose(
[transforms.Resize((32, 32)), # 首先需resize成跟训练集图像一样的大小
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
im = Image.open("plane.jpg")
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # 对数据增加一个新维度,因为tensor的参数是[batch, channel, height, width]
# 实例化网络,加载训练好的模型参数
net = LeNet()
net.load_state_dict(torch.load('Lenet.pth'))
# 预测
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
with torch.no_grad():
outputs = net(im)
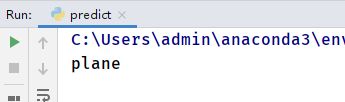
predict = torch.max(outputs, dim=1)[1].data.numpy()
print(classes[int(predict)])输出即为预测的标签。
其实预测结果也可以用 softmax 表示,输出10个概率:
with torch.no_grad():
outputs = net(im)
predict = torch.softmax(outputs, dim=1)
print(predict)