全国大学生大数据技能竞赛(数仓部署)
系列文章目录
全国大学生大数据技能竞赛(Hadoop集群搭建)
全国大学生大数据技能竞赛(Spark on Yarn安装)
文章目录
- 系列文章目录
- 前言
- 资料链接
- 数仓部署详解
-
- (一)hbase安装
-
- 1.1解压缩
- 1.2修改配置文件
- 1.3.分发 hbase
- 1.4.配置环境变量
- 1.5.运行和测试
- (二)数仓搭建(远程模式)MySQL和hive的安装
-
- 1.远程部署
- 2.安装MySQL
-
- 2.1前提:修改本地源
- 2.2下载MySQL
- 2.3启动服务
- 2.4设置密码
- 2.5远程登录
- 3.Slave1 上安装 hive
- 4.master作为客户端
- 5.启动hive
前言
本篇博客将根据往年全国大学生大数据技能竞赛的资料和今年的培训来进行数仓部署,如图hive包括客户端和服务器端。每一个步骤都有相应的执行的截图。以下博客仅作为个人搭建数据仓库过程的记录~如有不足之处欢迎指出,共同学习进步。附上资料链接。

资料链接
第四届全国大学生大数据技能竞赛中关于搭建数据仓库的培训链接:
https://www.qingjiaoclass.com/market/detail/7611
所有环境工具百度网盘链接:
https://pan.baidu.com/s/1oOW7WqHK4fiqv4Xja5f7gQ
提取码:vvi7
在自己练习搭建数据仓库时尽量每一步都拍快照,防止出现错误解决不了然后不得不重新搭建,非常麻烦
数仓部署详解
(一)hbase安装
1.1解压缩
1.将hbase安装包传至根目录,建立工作路径/usr/hbase,将根目录下的 hbase 解压到工作路径中。
mkdir /usr/hbase
tar -zxvf hbase-1.2.4-bin.tar.gz -C /usr/hbase

1.2修改配置文件
2.进入hbase的conf目录下,修改配置文件hbase-env.sh
cd /usr/hbase/hbase-1.2.4/conf
vi hbase-env.sh

修改以下内容
在第21行添加
export HBASE_MANAGES_ZK=false

在第28行添加
export JAVA_HOME=/usr/java/jdk1.8.0_171
在第30行修改
export HBASE_CLASSPATH=/usr/hadoop/hadoop-2.7.3/etc/Hadoop

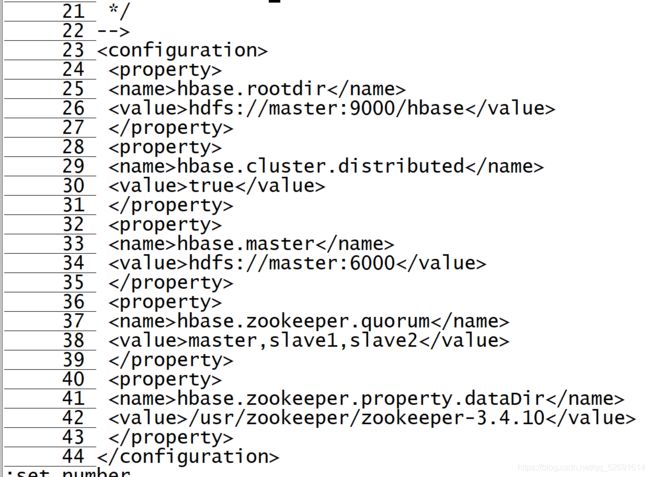
3.配置 hbase-site.xml
vi hbase-site.xml
添加内容到23行左右
hbase.rootdir</name>
hdfs://master:9000/hbase</value>
</property>
hbase.cluster.distributed</name>
true</value>
</property>
hbase.master</name>
hdfs://master:6000</value>
</property>
hbase.zookeeper.quorum</name>
master,slave1,slave2</value>
</property>
hbase.zookeeper.property.dataDir</name>
/usr/zookeeper/zookeeper-3.4.10</value>
</property>
</configuration>
4.配置 regionservers
在这里列出了希望运行的全部 HRegionServer,一行写一个 host。列在这里
的 server 会随着集群的启动而启动,集群的停止而停止
vi regionservers

5.hadoop 配置文件拷入 hbase 的 conf 目录下:(当前位置为 hbased 的conf 配置文件夹)
cp /usr/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml .
cp /usr/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml .
![]()
1.3.分发 hbase
6.分发 hbase
scp -r /usr/hbase root@slave1:/usr/
scp -r /usr/hbase root@slave2:/usr/
等待执行完毕~

1.4.配置环境变量
7.配置环境变量
vi /etc/profile
在第64行添加以下内容
# set hbase environment
export HBASE_HOME=/usr/hbase/hbase-1.2.4
export PATH=$PATH:$HBASE_HOME/bin

生效环境变量
source /etc/profile

1.5.运行和测试
8.运行和测试
开启hadoop(master上执行)
cd /usr/hadoop/hadoop-2.7.3/
sbin/start-all.sh

开启zookeeper(每台虚拟机都执行)
cd /usr/zookeeper/zookeeper-3.4.10/
bin/zkServer.sh start

再在 master 上执行:
cd /usr/hbase/hbase-1.2.4/
bin/start-hbase.sh

再在3台虚拟机分别执行
jps
出现下图中框起来的内容,恭喜你~hbase搭建成功!



9.访问 master 的 hbase web 界面
http://master IP:16010/master-status

10.查看hbase版本
hbase shell
status
version

(二)数仓搭建(远程模式)MySQL和hive的安装
1.远程部署

2.安装MySQL
slave2 上安装 mysql server
2.1前提:修改本地源
yum -y install epel-release(如果安装了epel源就不修改)
怎么查看是否安装了epel源?
执行yum repolist,如果出现下图,不修改本地源。
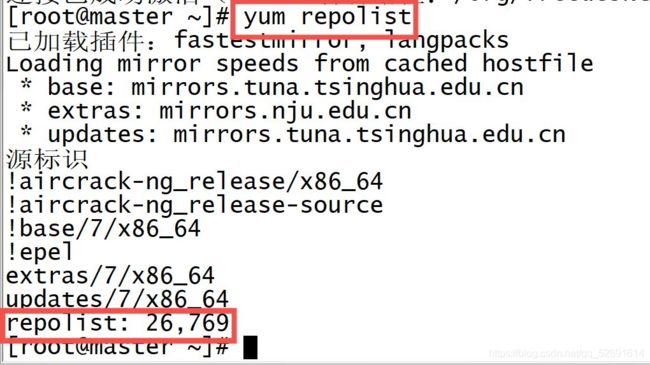
没有出现的话,执行yum -y install epel-release
2.2下载MySQL
wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm

安装源
rpm -ivh mysql57-community-release-el7-8.noarch.rpm

查看是否有包:
mysql-community.repo
mysql-community-source.repo
cd /etc/yum.repos.d
ls或ll

安装包
yum -y install mysql-community-server
等待安装完毕…

2.3启动服务
重载所有修改过的配置文件:
systemctl daemon-reload
开启服务:
systemctl start mysqld
开机自启:
systemctl enable mysqld

2.4设置密码
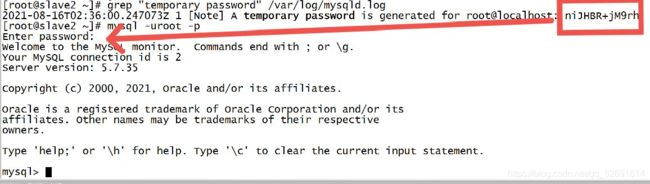
1.安装完毕后,/var/log/mysqld.log 文件中会自动生成一个随机的密码,我们需要先取得这个随机密码,以用于登录 MySQL 服务端:
grep "temporary password" /var/log/mysqld.log
mysql -uroot -p
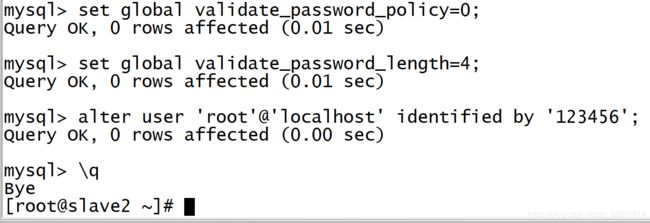
2.MySQL 密码安全策略:
设置密码强度为低级:
set global validate_password_policy=0;
设置密码长度最低为4:
set global validate_password_length=4;
修改本地密码:
alter user 'root'@'localhost' identified by '123456';
退出:\q
2.5远程登录
以新密码登陆 MySQL:
mysql -uroot -p123456
创建用户:
create user 'root'@'%' identified by '123456';
允许远程连接:
grant all privileges on *.* to 'root'@'%' with grant option;
刷新权限:
flush privileges;

3.Slave1 上安装 hive
首先我们需要创建工作路径,并将 hive 解压。环境中 master 作为客户端,slave1 作为服务器端,因此都需要使用到 hive。把hive安装包在master 中,因此我们先在 master 中对 hive 进行解压,然后将其复制到slave1 中。
把hive安装包传到master根目录中
1.建立工作路径
mkdir -p /usr/hive
2.解压缩
tar -zxvf apache-hive-2.1.1-bin.tar.gz -C /usr/hive/
![]()
再在slave1中建立工作路径,master远程拷贝至/usr/hive/
mkdir -p /usr/hive
scp -r /usr/hive/apache-hive-2.1.1-bin root@slave1:/usr/hive/

![]()
3.修改/etc/profile 文件设置 hive 环境变量。(master 和 slave1执行)
vi /etc/profile
添加以下内容
#set hive
export HIVE_HOME=/usr/hive/apache-hive-2.1.1-bin
export PATH=$PATH:$HIVE_HOME/bin
master上:

slave1上:

生效环境变量
source /etc/profile


4.因为服务端需要和 Mysql 通信,所以服务端需要 Mysql 的 lib 安装包到 Hive_Home/conf 目录下。
注意:mysql.jar 放在 slave2 中的目录下,需要将其远程复制到 slave1的 hive 的 lib 中。
将jar包传至slave2中,再执行
scp mysql-connector-java-5.1.47-bin.jar root@slave1:/usr/hive/apache-hive-2.1.1-bin/lib
需要手动输入密码是因为我们设置的ssh免密登录是指主节点可以免密登录从节点,而从节点没有设置ssh免密登录。
![]()
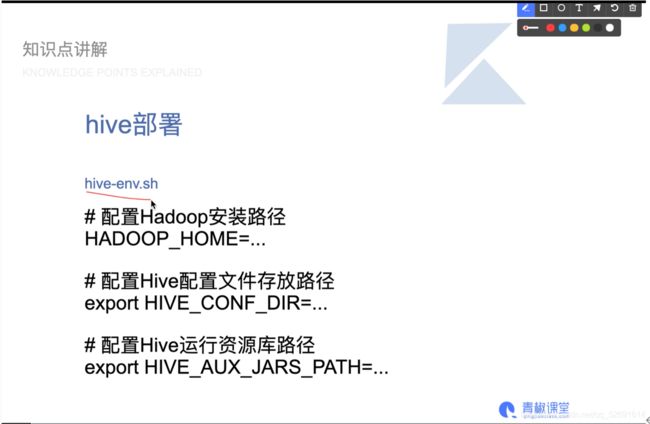
5.回到 slave1,修改 hive-env.sh 中 HADOOP_HOME 环境变量。
cd /usr/hive/apache-hive-2.1.1-bin/conf
cp -p hive-env.sh.template hive-env.sh
vi hive-env.sh

添加
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export HIVE_CONF_DIR=/usr/hive/apache-hive-2.1.1-bin/conf
export HIVE_AUX_JARS_PATH=/usr/hive/apache-hive-2.1.1-bin/lib
6.修改 hive-site.xml 文件(在slave1上)
vi hive-site.xml
添加以下内容
<!--Hive产生的元数据存放位置-->
hive.metastore.warehouse.dir</name>
/user/hive_remote/warehouse</value>
</property>
<!--数据库连接JDBC的URL地址-->
javax.jdo.option.ConnectionURL</name>
jdbc:mysql://slave2:3306/hive?createDatabaseIfNotExist=true&;characterEncoding=UTF-8&;useSSL=false</value>
JDBC connect string for a JDBC metastore</description>
</property>
<!--数据库连接driver,即MySQL驱动-->
javax.jdo.option.ConnectionDriverName</name>
com.mysql.jdbc.Driver</value>
</property>
<!--MySQL数据库用户名-->
javax.jdo.option.ConnectionUserName</name>
root</value>
</property>
<!--MySQL数据库密码-->
javax.jdo.option.ConnectionPassword</name>
123456</value>
</property>
hive.metastore.schema.verification</name>
false</value>
</property>
datanucleus.schema.autoCreateALL</name>
true</value>
</property>
</configuration>
4.master作为客户端
1.解决版本冲突和 jar 包依赖问题
hadoop和hive的jar包版本不同,保留一个高版本的jar包,删掉低版本的jar包。
slave1和master上执行
cp /usr/hive/apache-hive-2.1.1-bin/lib/jline-2.12.jar /usr/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/
![]()
rm -rf /usr/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/guava-11.0.2.jar
cp /usr/hive/apache-hive-2.1.1-bin/lib/guava-14.0.1.jar /usr/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/

2.修改 hive-env.sh
master上执行
cd /usr/hive/apache-hive-2.1.1-bin/conf
cp -p hive-env.sh.template hive-env.sh
vi hive-env.sh

添加
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export HIVE_CONF_DIR=/usr/hive/apache-hive-2.1.1-bin/conf
export HIVE_AUX_JARS_PATH=/usr/hive/apache-hive-2.1.1-bin/lib
3.修改 hive-site.xml(master上执行)
vi hive-site.xml
添加以下内容
<!--Hive产生的元数据存放位置-->
hive.metastore.warehouse.dir</name>
/user/hive_romote/warehouse</value>
</property>
<!---使用本地服务连接Hive,默认为true-->
hive.metastore.lodal</name>
false</value>
</property>
<!--连接服务器-->
hive.metastore.uris</name>
thrift://slave1:9083</value>
</property>
</configuration>
5.启动hive
每次启动hive前要先启动hadoop,不然会报错
1.启动hadoop(master上执行),很简单,就不截图了~~
cd /usr/hadoop/hadoop-2.7.3/
sbin/start-all.sh
2.初始化数据库(slave1上执行)
schematool -dbType mysql -initSchema
出现下图这个就是初始化成功了~

3.slave1上执行
cd /usr/hive/apache-hive-2.1.1-bin
bin/hive --service metastore
出现下图中这个就服务器启动成功~~

4.master上执行
cd /usr/hive/apache-hive-2.1.1-bin
bin/hive
出现hive>后执行show databases;进行测试
出现下面这个就成功~~
