Flink算子和入门案例(wordcount)
文章目录
-
-
- 入门案例:
-
- 1.Flink入门案例wordcount
- 自定义source
-
- 2.基于本地构建DataStream,基于文件构建DataStream,基于socket构建DataStream,自定义source
- 3.使用自定义source去读取MySQL数据库数据
- 算子
-
- 4.map
- 5.flatMap
- 6.filter
- 7.KeyBy
- 8.Reduce
- 9.Agg
- 10.Window
- 11.union
- 12.SideOutput
- 自定义sink
-
- 13.自定义sink
- 14.自定义sink写数据到mysql
-
入门案例:
1.Flink入门案例wordcount
先导入pom依赖
.compiler.source>8</maven.compiler.source>
.compiler.target>8</maven.compiler.target>
.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
.version>1.11.2</flink.version>
.binary.version>2.11</scala.binary.version>
.version>2.11.12</scala.version>
.version>2.12.1</log4j.version>
</properties>
org.apache.flink</groupId>
flink-walkthrough-common_${
scala.binary.version}</artifactId>
${
flink.version}</version>
</dependency>
org.apache.flink</groupId>
flink-streaming-scala_${
scala.binary.version}</artifactId>
${
flink.version}</version>
</dependency>
org.apache.flink</groupId>
flink-clients_${
scala.binary.version}</artifactId>
${
flink.version}</version>
</dependency>
org.apache.logging.log4j</groupId>
log4j-slf4j-impl</artifactId>
${
log4j.version}</version>
</dependency>
org.apache.logging.log4j</groupId>
log4j-api</artifactId>
${
log4j.version}</version>
</dependency>
org.apache.logging.log4j</groupId>
log4j-core</artifactId>
${
log4j.version}</version>
</dependency>
mysql</groupId>
mysql-connector-java</artifactId>
5.1.36</version>
</dependency>
</dependencies>
<!-- Java Compiler -->
org.apache.maven.plugins</groupId>
maven-compiler-plugin</artifactId>
3.1</version>
1.8</source>
1.8</target>
</configuration>
</plugin>
<!-- Scala Compiler -->
net.alchim31.maven</groupId>
scala-maven-plugin</artifactId>
3.2.2</version>
compile</goal>
testCompile</goal>
</goals>
</execution>
</executions>
-nobootcp</arg>
</args>
</configuration>
</plugin>
</plugins>
</build>
package com.liu.core
import org.apache.flink.streaming.api.scala._
/**
* @ Author : ld
* @ Description : 实时统计word个数
* @ Date : 2021/11/23 18:57
* @ Version : 1.0
*/
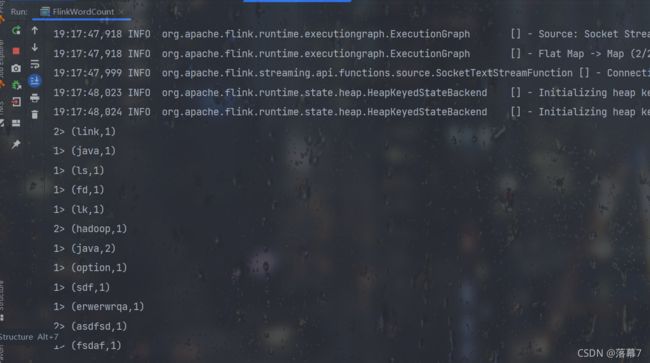
object FlinkWordCount {
def main(args: Array[String]): Unit = {
//创建flink的环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度
env.setParallelism(2)
//读取socket数据
//启动master开启nc,没有的执行yum -install nc安装
//nc -lk 8888
env.socketTextStream("master",8888)
//把单词拆分
.flatMap(_.split(","))
//转换成kv格式
.map((_,1))
//按单词分组
.keyBy(_._1)
//统计单词数量
.sum(1)
//打印结果
.print()
//启动flink
env.execute()
}
}

自定义source
2.基于本地构建DataStream,基于文件构建DataStream,基于socket构建DataStream,自定义source
package com.liu.source
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.scala._
/**
* @ Author : ld
* @ Description :
* @ Date : 2021/11/23 19:26
* @ Version : 1.0
*/
object Demo1Source {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
/**
* 基于本地构建DataStream -- 有界流
*/
val lisrDS: DataStream[Int] = env.fromCollection(List(1, 2, 3, 4, 5, 6, 7, 8, 9))
lisrDS.print()
/**
* 基于文件构建DataStream --有界流
*/
val studentDS: DataStream[String] = env.readTextFile("Flink/data/student.txt")
studentDS
.map(stu=>(stu.split(",")(4),1))
.keyBy(_._1)
.sum(1)
.print()
/**
* 基于socket构建DataStream-- 无界流
*/
// env.socketTextStream("master11",8888)
// .print()
/**
* 自定义socket,实现SourceFunction接口
*/
env.addSource(new MySource).print()
env.execute()
}
}
/**
* 自定义source,实现SourceFunction接口
* 实现run方法
*/
class MySource extends SourceFunction[Int]{
/**
* run方法只执行一次
* @ param ctx:用于发送数据到下游task
*/
override def run(ctx: SourceFunction.SourceContext[Int]): Unit = {
var i=0
while(true){
//死循环,看完发送到下游结果就关闭吧
//把数据发送到下游
ctx.collect(i)
//休眠50毫秒
Thread.sleep(50)
i+=1
}
}
/**
* cancel()方法再任务取消时执行用于回收资源
*/
override def cancel(): Unit = {
}
}
3.使用自定义source去读取MySQL数据库数据
package com.liu.source
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.source.{
RichSourceFunction, SourceFunction}
import org.apache.flink.streaming.api.scala._
import java.sql.{
Connection, DriverManager, ResultSet}
/**
* @ Author : ld
* @ Description :
* @ Date : 2021/11/23 20:05
* @ Version : 1.0
*/
object Demo2MysqlSource {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(2)
//使用自定义source
val mysqlDS: DataStream[(Int, String, Int, String, String)] = env.addSource(new MysqlSource)
mysqlDS.print()
env.execute()
}
}
/**
* 自定义读取mysql---有界流
* SourceFunction -- 单一source,run方法只会执行一次
* ParallelSourceFunction-- 并行的source,并行度决定source个数
* RichSourceFunction -- 比sourceFunction多了open和close方法
* RichParallelSourceFunction --结合上面两个方法
*/
class MysqlSource extends RichSourceFunction[(Int, String, Int, String, String)] {
/**
* open方法会在run方法之前执行
* @ param ctx
*/
var conn: Connection = _
override def open(parameters: Configuration): Unit = {
//加载驱动
Class.forName("com.mysql.jdbc.Driver")
//建立连接
conn = DriverManager.getConnection("jdbc:mysql://master:3306/test", "root", "123456")
}
/**
* 在run方法后执行
*/
override def close(): Unit = {
//关闭连接
conn.close()
}
override def run(ctx: SourceFunction.SourceContext[(Int, String, Int, String, String)]): Unit = {
//查看数据
val stat = conn.prepareStatement("select * from student")
val res: ResultSet = stat.executeQuery()
//解析数据
while (res.next()) {
val id: Int = res.getInt("id")
val name: String = res.getString("name")
val age: Int = res.getInt("age")
val gender: String = res.getString("gender")
val clazz: String = res.getString("clazz")
//数据发送到下游
ctx.collect((id, name, age, gender, clazz))
}
}
override def cancel(): Unit = {
}
}
算子
4.map
package com.liu.transformation
import org.apache.flink.api.common.functions.MapFunction
import org.apache.flink.streaming.api.scala._
/**
* @ Author : ld
* @ Description :
* @ Date : 2021/11/23 20:54
* @ Version : 1.0
*/
object Demo1Map {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val lineDS: DataStream[String] = env.socketTextStream("master11", 8888)
/**
* map函数
* 传入一个函数
* 传入一个接口的实现类 --MapFunction
*/
lineDS.map(new MapFunction[String,String]{
override def map(t: String): String = {
t +"ok"
}
}).print()
env.execute()
}
}

5.flatMap
package com.liu.transformation
import org.apache.flink.api.common.functions.{
FlatMapFunction, RichFlatMapFunction}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
/**
* @ Author : ld
* @ Description :
* @ Date : 2021/11/23 21:03
* @ Version : 1.0
*/
object Demo2FlatMap {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(4)//设置并行度为4
val linesDS: DataStream[String] = env.socketTextStream("master", 8888)
/**
* FlatMapFunction
* RichSourceFunction--多了open和close方法,可以做初始化操作
*/
val flatMapDS: DataStream[String] = linesDS.flatMap(new RichFlatMapFunction[String, String] {
override def flatMap(line: String, out: Collector[String]): Unit = {
/**
* flatMap函数,每一条数据执行一次
*
* @ param line : 一行数据
* @ param out ; 用于将数据发送到下游
*/
line
.split(",")
.foreach(out.collect) //下面释内容简写
// .foreach(word=>{
// //发送数据
// out.collect(word)
// })
}
})
flatMapDS.print()
env.execute()
}
}

6.filter
package com.liu.transformation
import org.apache.flink.api.common.functions.FilterFunction
import org.apache.flink.streaming.api.scala._
/**
* @ Author : ld
* @ Description :
* @ Date : 2021/11/23 21:17
* @ Version : 1.0
*/
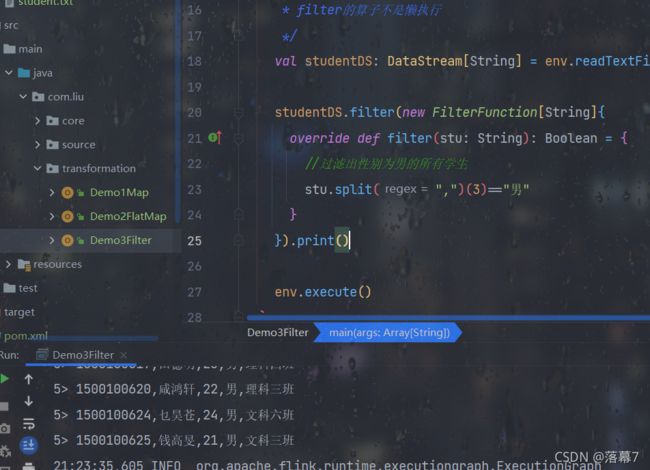
object Demo3Filter {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
/**
* filter的算子不是懒执行
*/
val studentDS: DataStream[String] = env.readTextFile("Flink/data/student.txt")
studentDS.filter(new FilterFunction[String]{
override def filter(stu: String): Boolean = {
//过滤出性别为男的所有学生
stu.split(",")(3)=="男"
}
}).print()
env.execute()
}
}
7.KeyBy
package com.liu.transformation
import org.apache.flink.api.java.functions.KeySelector
import org.apache.flink.streaming.api.scala._
/**
* @ Author : ld
* @ Description :
* @ Date : 2021/11/23 21:25
* @ Version : 1.0
*/
object Demo4KeyBy {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(3)
val linesDS: DataStream[String] = env.socketTextStream("master", 8888)
/**
* keyBy把相同的key发送到同一个task中
*/
linesDS.keyBy(new KeySelector[String,String] {
override def getKey(line: String): String ={
line
}
}).print()
env.execute()
}
}

8.Reduce
package com.liu.transformation
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.streaming.api.scala._
/**
* @ Author : ld
* @ Description :
* @ Date : 2021/11/23 22:01
* @ Version : 1.0
*/
object Demo5Reduce {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val lineDS: DataStream[String] = env.socketTextStream("master11", 8888)
val keyByDS: KeyedStream[(String, Int), String] = lineDS
.flatMap(_.split(","))
.map((_, 1))
.keyBy(_._1)
/**
* reduce:在keyBy之后进行聚合
*/
keyByDS.reduce(new ReduceFunction[(String,Int)]{
override def reduce(t: (String,Int), t1: (String,Int)): (String,Int) = {
(t._1,t1._2+t1._2)
}
}).print()
env.execute()
}
}
9.Agg
package com.liu.transformation
import org.apache.flink.streaming.api.scala._
/**
* @ Author : ld
* @ Description :
* @ Date : 2021/11/23 22:09
* @ Version : 1.0
*/
object Demo6Agg {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val studentDS: DataStream[String] = env.readTextFile("Flink/data/student.txt")
var stuDS: DataStream[Student] = studentDS.map(line => {
val split = line.split(",")
Student(split(0), split(1), split(2).toInt, split(3), split(4))
})
stuDS.keyBy(_.clazz)
.sum("age")
.print()
/**
* max 和 maxBy 之间的区别在于 max 返回流中的最大值,但 maxBy 返回具有最大值的键,
*/
stuDS.keyBy(_.clazz)
.maxBy("age")
.print()
env.execute()
}
case class Student(id:String,name:String,age:Int,gender:String,clazz:String)
}
10.Window
package com.liu.transformation
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
/**
* @ Author : ld
* @ Description :
* @ Date : 2021/11/23 21:52
* @ Version : 1.0
*/
object Demo7Window {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val linesDS: DataStream[String] = env.socketTextStream("master11", 8888)
/**
* 每5秒统计一次单词数量
*/
linesDS
.flatMap(_.split(","))
.map((_,1))
.keyBy(_._1)
.timeWindow(Time.seconds(5))
.sum(1)
.print()
env.execute()
}
}
11.union
package com.liu.transformation
/**
* @ Author : ld
* @ Description :
* @ Date : 2021/11/23 22:27
* @ Version : 1.0
*/
import org.apache.flink.streaming.api.scala._
object Demo8Union {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val ds1: DataStream[Int] = env.fromCollection(List(1,2,3,4,5,6))
val ds2: DataStream[Int] = env.fromCollection(List(4,5,6,7,8,9))
/**
* 合并DataStream 类型要一致
*
*/
val unionDS: DataStream[Int] = ds1.union(ds2)
unionDS.print()
env.execute()
}
}
12.SideOutput
package com.liu.transformation
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
/**
* @ Author : ld
* @ Description :
* @ Date : 2021/11/23 22:31
* @ Version : 1.0
*/
object Demo9SideOutput {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val studentDS = env.readTextFile("Flink/data/student.txt")
/**
* 将性别为男和性别为女学生单独拿出来
*/
val man = OutputTag[String]("男")
val women = OutputTag[String]("女")
val processDS = studentDS.process(new ProcessFunction[String, String] {
override def processElement(line: String, ctx: ProcessFunction[String, String]#Context, collector: Collector[String]): Unit = {
val gender: String = line.split(",")(3)
gender match {
//旁路输出
case "男" => ctx.output(man, line)
case "女" => ctx.output(women, line)
}
}
})
//获取旁路输出的DataStream
// processDS.getSideOutput(man).print()
processDS.getSideOutput(women).print()
env.execute()
}
}
自定义sink
13.自定义sink
package com.liu.sink
import org.apache.flink.streaming.api.functions.sink.SinkFunction
import org.apache.flink.streaming.api.scala._
/**
* @ Author : ld
* @ Description :
* @ Date : 2021/11/23 22:47
* @ Version : 1.0
*/
object Demo1Sink {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val studentDS = env.readTextFile("Flink/data/student.txt")
//自定义sink
studentDS.addSink(new MySink)
env.execute()
}
}
class MySink extends SinkFunction[String]{
/**
* invoke : 每一条数据都会执行一次
*
* @ param line 数据
* @ param context 上下文对象
*/
override def invoke(value: String, context: SinkFunction.Context[_]): Unit = {
print(value)
}
}
14.自定义sink写数据到mysql
package com.liu.sink
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{
RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala._
import java.sql.{
Connection, DriverManager}
/**
* @ Author : ld
* @ Description :
* @ Date : 2021/11/23 22:56
* @ Version : 1.0
*/
object Demo2MysqlSink {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val studentDS: DataStream[String] = env.readTextFile("Flink/data/student.txt")
studentDS.addSink(new MysqlSink)
env.execute()
}
}
class MysqlSink extends RichSinkFunction[String]{
/**
* 在invoke 之前执行,每一个task中只只一次
*/
var conn:Connection = _
override def open(parameters: Configuration): Unit = {
//加载驱动
Class.forName("com.mysql.jdbc.Driver")
//建立连接
conn = DriverManager.getConnection("jdbc:mysql://master:3306/test", "root", "123456")
}
/**
* 在run方法后执行
*/
override def close(): Unit = {
//关闭连接
conn.close()
}
//每条数据都会执行一次
override def invoke(value: String, context: SinkFunction.Context[_]): Unit ={
val split = value.split(",")
val stat = conn.prepareStatement("insert into student(id,name,age,gender,clazz) values(?,?,?,?,?)")
stat.setString(1,split(0))
stat.setString(2,split(1))
stat.setInt(3,split(2).toInt)
stat.setString(4,split(3))
stat.setString(5,split(4))
stat.execute()
}
}