YOLO v3论文笔记(一)
论文地址1: https://arxiv.org/pdf/1804.02767.pdf
论文地址2:https://pjreddie.com/media/files/papers/YOLOv3.pdf
论文题目:YOLOv3: An incremental improvement
keras 实现:https://github.com/qqwweee/keras-yolo3
YOLOv3检测一张320×320的图像只需要22.2毫秒,mAP为28.2。其与SSD一样准确,但速度快了三倍,
mAP是什么?参考下面博客:
https://blog.csdn.net/weixin_38145317/article/details/89215780
网络结构:

DBL: 网络,代码中的Darknetconv2d_BN_Leaky,是yolo_v3的基本组件,就是卷积+BN+Leaky relu。
resn: n代表数字,有res1,res2,...,res8等等,表示这个res_block里有多少个res_unit.
concat:张量拼接,将darknet中间层和后面的某一层的上采样进行拼接,拼接的操作和参差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
1.backbone: darknet-53
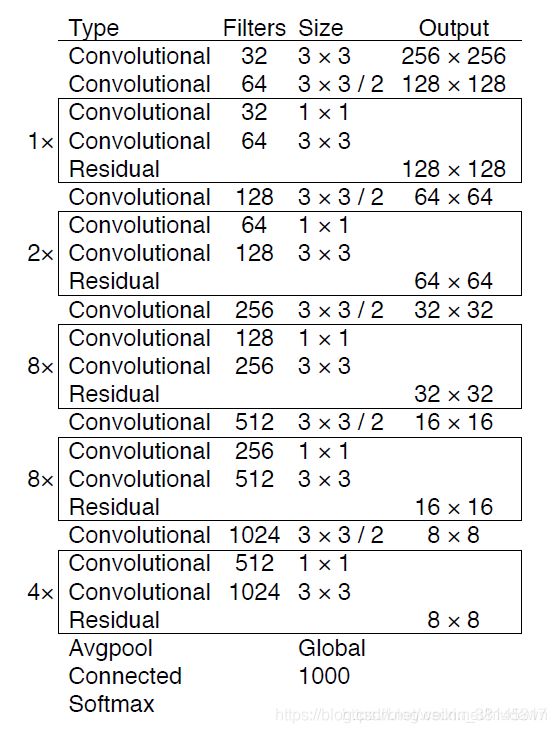
为了达到更好的分类效果,作者自己设计训练了darknet-53,作者在imagenet实验发现这个darknet-53,的确很强,相对于resnet-152和resnet-101,darknet-53不仅在分类精度上差不多,计算速度还比他们快多了,网络层数也比他们少。
不同于Darknet-19,yolo_v3使用了darknet-53的前面的52层(没有全连接层,除去最后一个FC),yolo_v3这个网络是一个全卷积网络,大量使用参差的跳层连接,并且为了降低池化带来的梯度负面效果,作者直接摒弃了pooling,用conv的stride来实现降采样。在这个网络结构中,使用的是步长为2的卷积来进行降采样。主干网络被分成3个stage,结构类似FPN,1-26层卷积为stage 1, 27-43层卷积为stage 2,44-52层卷积为stage 3, 低层卷积(26)感受视野较小,负责检测小目标,深层卷积(52)感受野大,容易检测出大目标,这个网络由残差单元叠加而成。根据作者的实验,在分类准确度上跟效率的平衡上,这个模型比ResNet-101、 ResNet-152和Darknet-19表现得更好。
为了加强算法对小目标检测度,yolov3中采用类似fpn的upsample和融合做法(最后融合了3个scale,其他两个scale的大小分别是26×26和52×52,在多个scale的feature map上做检测,
2. 网络输出,YOLO的CNN网络把图片分成S*S个网格(yolov3多尺度预测,输出3个:y1y2,y3,可以看成S*S个网格,分别为13*13, 26*26, 52*52),然后每个单元格负责去检测那些中心点落在该格子内的目标,如图所示,每个单元格需要预测3*(4+1+B)个值,如果将输入图片划分为S*S网格,那么每层最终预测值为S*S*3*(4+1+c)大小的张量,其中c为类别数(coco集为80类),即c=80,3代表一个grid会生成3个边界框,4,4表示对中心点(centx,centy)和宽高w,h这4个量的偏移值的预测,而每个边界框都有自己的位置补偿, 1代表置信度.
网络中作者进行了3次预测,分别是在32倍降采样,16倍降采样,8倍降采样时进行检测,这样在多尺度的feature map上检测跟ssd有点像。在网络中使用up-sample(上采样)的原因,网络越深的特征表达效果越好,比如在进行16倍降采样检测,如果直接使用第4次下采样的特征来检测,这样就使用了浅层特征,这样效果一般并不好,如果想使用32倍降采样后的特征,但深层特征的大小太小,因此yolo_v3使用了步长为2的up-sample上采样,将深层特征提取,其维度是与将要融合的特征层维度是相同的(channel不同),
备注:
1.对于tiny-yolo,2. 运行网络,YOLO的CNN网络把图片分成S*S个网格(yolov3多尺度预测,输出2层,每层S*S个网格,分别为13*13, 26*26).
2.作者在3条预测支路采用的也是全卷积的结构,其中最后一个卷积层的卷积核个数是255,是针对coco数据集的80类,3×(80+4+1)=255,3表示一个grid cell包含3个bounding box, 4表示4个坐标信息,1表示置信度。
3. 通过NMS,非极大值抑制,筛选出框boxes,输出框class_boxes和置信度class_box_scores,再生成类别信息classes,生成最终的检测数据框,并返回
3.多尺度预测
所谓的多尺度就是来自网络预测输出y1,y2,y3, grid分别为13*13, 26*26, 52*52.
注意:
1.原文有很多concatenate操作,有利于整合从不同层提取到的精细特征,使得物体预测小物体更加厉害,定位也有所提升.
2.使用k-means决定anchor boxes(yolov3统一改名为bouding box priors,预选框)的尺寸(宽高),
多尺度预测,13*13, 26*26, 52*52
小尺度:13*13的feature map,
网络接收一张(416*416)的图,经过5个步长为2的卷积来进行降采样(416/2^5=13).输出 (13*13)
中尺度:26*26的feature map,
从小尺度中的倒数第二层的卷积陈上采样(x2, up sampling)再与最后一个13x13大小的特征图相加,输出 (26*26)
大尺度:52*52的feature map,
操作同中尺度输出52*52
3. anchor box/bounding box
yolov3的bounding box 由yolov2改进而来, 两者都采用了对图像中的目标进行k-means聚类,feature map中的每个cell都会预测3个bounding box.
anchor box一共有9个,由k-means聚类得到,在COCO数据集上,9个聚类是:(10*13);(16*30);(33*23);(30*61);(62*45); (59*119); (116*90); (156*198); (373*326),这应该是按照输入图像的尺寸是416*416计算得到的,(个人觉得,我们训练的数据集中图片尺寸大小不一,应该先归一化,再来算尺寸,然后网络训练时,根据不同大小来调整anchor的实际宽高).
当输入为416*416时,实际总共有(52×52+26×26+13×13)×3=10647个proposal box.
bounding 与anchor box的区别
bounding box它输出的是框的位置(中心坐标与宽高),confidence,以及n个类别。
anchor box只是一个尺度,即只有宽高。
问题:
如果我这里anchor的尺寸是随意填写的,会对训练结果有什么影响吗?
不同尺寸特征图对应不同大小的先验框。
13*13feature map对应【(116*90),(156*198),(373*326)】
26*26feature map对应【(30*61),(62*45),(59*119)】
52*52feature map对应【(10*13),(16*30),(33*23)】
原因:特征图越大,感受野越小。对小目标越敏感,所以选用小的anchor box。
特征图越小,感受野越大。对大目标越敏感,所以选用大的anchor box。
备注:
yolov2 有5个尺寸预选框,yolov3有3个尺寸预选框,但是yolov3有3个输出检测层,所以yolov3的bouding box 比yolov2还要多,因为
(13*13+26*26+52*52)*3>13*13*5
2.4 特征提取
网络用了连续的3x3,1x1的卷积块,并采取了新流行的残差网络(resnet 的residual结构),并且添加了shortcut连接,因为一共包含了53层卷积层,所以又称为darknet-53
问题:为什么我按照论文的网络结构图片查出来只有1+1+2+1+2*2+1+2*8+1+2*8+1+2*4=52层,怎么作者说有53层呢?
答:darknet-53是因为除了52个卷积层之外,还有一个全连接层。在yolov3中,把最后的全连接层舍弃了,所以成了52
3.类别预测loss function
ylolov3重要改变之一:No more softmaxing the class.
对图像中检测到的目标执行多标签分类。
早期yolo,作者曾用softmax获取类别得分并用最大得分的标签来表示包含在边界框内的目标,在yolov3中,这种做法被修正。softmax来分类依赖于这样一个前提:即分类是相互独立的,换句话说,如果一个目标术语一种类别,那么它就不能属于另一种,但是,当我们的数据集中存在人或女人的标签时,上面所提到的前提就是失去了意义,这就是作者为什么不用softmax,而用logistic regression来预测每个类别得分并使用一个阈值来对目标进行多标签预测。比阈值高的类别就是这个边界框真正的类别。
用简单一点的语言来说,其实就是对每种类别使用二分类的logistic回归(或称为Sigmoid函数),即你要么是这种类别要么就不是,然后遍历所有类别,得到所有类别的得分,选取大于阈值的类别就好了。
ylolov3重要改变之二:舍弃平方误差,大都采用交叉熵
除了w,h的损失函数依然采用均方误差之外,其他部分的损失函数用的是二值交叉熵。
# K.binary_crossentropy is helpful to avoid exp overflow.
#x,y交叉熵损失,首先要置信度不为0
xy_loss = object_mask * box_loss_scale * K.binary_crossentropy(raw_true_xy, raw_pred[..., 0:2], from_logits=True)
#宽高损失为方差损失
wh_loss = object_mask * box_loss_scale * 0.5 * K.square(raw_true_wh-raw_pred[..., 2:4])
#置信度损失,交叉熵,这里没有物体的部分也要计算损失
confidence_loss = object_mask * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True)+ \
(1-object_mask) * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True) * ignore_mask
#分类损失
class_loss = object_mask * K.binary_crossentropy(true_class_probs, raw_pred[..., 5:], from_logits=True)
xy_loss = K.sum(xy_loss) / K.cast(batch_size, tf.float32)
wh_loss = K.sum(wh_loss) / K.cast(batch_size, tf.float32)
confidence_loss = K.sum(confidence_loss) / K.cast(batch_size, tf.float32)
class_loss = K.sum(class_loss) / K.cast(batch_size, tf.float32)
loss += xy_loss + wh_loss + confidence_loss + class_loss