Unsupervised Question Answering by Cloze Translation 通过完形填空翻译的无监督的问答
Unsupervised Question Answering by Cloze Translation 通过完形填空翻译的无监督的问答
文章目录
- Unsupervised Question Answering by Cloze Translation 通过完形填空翻译的无监督的问答
- 0、Abstract
-
- 0.1、背景
- 0.2、Paper做的
-
- c-1)为了产生上面的三元组:
- 0.3、其它
- 1、Introduction
-
- 1.1 现有背景
- 1.2 作者方法
- 1.3 cloze to natural
- 1.4 少样本学习
- 1.5 To Summarize 总结
- 2、Unsupervised Extractive QA 无监督EQA
-
- 2.1、Context and Answer Generation 上下文和答案生成
- 2.2、Question Generation 问题生成
- 2.3、Question Answering 问题回答
- 2.4、Unsupervised Cloze Translation 无监督完形填空翻译
- 3、Experiments 实验
-
- 3.1、Unsupervised QA Experiments 无监督QA实验
- 3.2、Ablation Studies and Analysis消融实验和分析
- 3.3、Error Analysis 错误分析
- 3.4、UNMT-generated Question Analysis UNMT生成问题分析
- 3.5、Few-Shot Question Answering 少样本问题回答
- 4、Related Work相关工作
- 5、Discussion 讨论
- 6、Conclusion 结论
作者是三个Facebook的AI研究员
0、Abstract
0.1、背景
获取QA的训练数据是一个耗时、耗资源的问题,现有的QA数据集仅仅只是某个特定领域或语言的。
0.2、Paper做的
a)对于EQA需要多大程度质量的训练数据
b)调查无监督EQA的可能性
c)通过无监督的方法产生context、question、answer三元组去自动合成EQA的训练数据,用于解决背景提出的问题
c-1)为了产生上面的三元组:
1、从一个大的语料库中随机抽取context paragraph 样本
2、从上面的样本中,随机抽取noun phrase OR named entity 作为答案
3、将上述抽取的答案转化为“fill-in-the-blank”在context中,既完形填空
4、最终将上面的完形填空翻译为自然语言问题
0.3、其它
文章提出并对比了几种无监督方法用于完形填空问题翻译为自然语言问题,包括使用nonaligned语料库中的自然语言问题和完形填空问题以及基于rule-base的方法训练一个无监督的NMT(Neural Machine Translation)模型。结果发现使用合成的训练数据集训练的modern QA模型能够很好的学会回答人类问题。还证实了不使用SQuAD的数据集的情况下,我们的方法(指的是使用合成的训练数据集)在SQuAD v1上可以实现56.4F1,当答案是Named entity时可以实现64.5F1,远超早期的监督模型。
1、Introduction
1.1 现有背景
a)EQA表示给定一个context document assumption情况下,答案在document里面,然后进行回答。
b)现有的EQA数据集SQuAD、SQuAD 2.0 都已经被模型给刷爆了,超过了人类的表现。
c)Natural Question也已经被模型给达到了人类的表现。
1.2 作者方法
生成EQA训练数据集,图一为示意图
1)在目标域中抽取一个段落,例如英语的维基百科
2)在上面抽取的段落中抽取一个candidate answer集,使用pretrained component(NER(Named Entity Recognition) or noun chunkers)去识别这些candidate answer。这些需要监督(?),但是不需要 aligned(question, answer) or (question, context) data。提供一个candidate answer 和 context我们可以提取出 “fill-the-blank”完形填空。
3)最后,我们使用无监督的完形填空-自然语言问题翻译器将完形填空问题转换为自然语言问题(最大的挑战)
1.3 cloze to natural
利用最近在无监督机器翻译的方法(Lample et al., 2018, 2017; Lample and Conneau, 2019; Artetxe et al., 2018).文章收集了大量的自然问题的语料库以及unaligned的完形填空语料库并且结合online back-translation 和 de-noising auto-encoding去训练seq2seq模型去映射natural和cloze问题领域。无监督seq2seq模型超过基于noise和rule-based。
1.4 少样本学习
1.2中作者的方法也能用于few-shot learning,例如使用32个标签数据可以获得59.3 F1超过不使用我们的方法40.0 F1(?)
1.5 To Summarize 总结
a)实现无监督QA的第一种方法就是使用无监督的机器翻译将问题减为无监督的完形填空翻译
b)大量的实验测试各种完形填空问题翻译算法和假设的效果
c)实验证明我们的方法可以用于EQA的few-shot learning(-本文用于合成数据集的模型和产生的数据集在:
https://github.com/facebookresearch/UnsupervisedQA)
2、Unsupervised Extractive QA 无监督EQA

图1:关于本文方法的示意图,右边虚线箭头代表传统EQA,我们介绍无监督的数据产生(左边,实心箭头)用于训练标准的EQA模型
在EQA里面给予一个问题 q 和一个context paragraph c 以及需要提供的答案 a = (b, e),b为c中的字符索引开始,e为结束。图1为该任务的示意图。
分2阶段解决无监督QA。(看不懂,那些生成器为什么要写成p(xx)的)
使用无监督开发一个生成模型 p(q, a, c),然后使用 p 作为数据生成器训练一个判别模型 pr(a |q, c)。这个生成器 p(q, a, c) = p© * p(a|c) * p(q|a, c)将生成数据在一个“相反的方向”,首先通过p©进行context抽样,然后获取答案通过p(a|c),最后获取问题通过p(q|a, c)。
2.1、Context and Answer Generation 上下文和答案生成
对任何文档平均抽取合适长度的段落c,加入先验经验通过p(a|c)生成好的答案spans,分为Noun Phrase 和 Named Entities 的p(a|c)。若答案只为Named Entity虽然减少了问题类型,但是实际很有效
2.2、Question Generation 问题生成
分两步生成完形填空q’ = cloze(a, c)以及翻译p(q|q’),通过选择答案周围的子句以提高问题的准确性同时减少完形填空的长度,现有4种方法将cloze翻译为natural。
1)Identity Mapping
采用启发式的wh单词替换mask token
2)Noisy Clozes
删除完形填空 q’ 的mask token,在q’前面加个wh,在句尾加个?,采用 Lample et al. (2018) 的noise function
3)Rule-Based
将嵌入在句子中的答案变成 (q, a) 对可以理解为具有 wh-movement 和 wh-word 的类型依赖选择的句法转换,使用 Heilman and Smith (2010)完成
4)Seq2Seq
3)需要大量的工程和先验知识,1)2)产生的问题距离真正的自然问题远远不够,本文采用无监督seq2seq模型来完成完形填空到自然语言问题
2.3、Question Answering 问题回答
2种方法
1)训练一个单独的QA系统,对于任何QA结构,都采用我们生成的数据训练
2)Using Posterior 计算最高的posterior p(a|c, q),即计算产生这个问题可能性最大的answer使用 Lewis and Fan (2019).
2.4、Unsupervised Cloze Translation 无监督完形填空翻译
采用nonparallel corpora 的源和目标语言句子,学习一个函数用于自然语言问题和完形填空问题的映射,这将需要大量的完形填空语料库和自然语言语料库
完形填空语料库:抛弃单词长度超过40的,如果答案是noun phrase就用“MASK”代替,如果答案是Named Entity,参考如下表格5,依据Named Entity的类型来进行替代,并且给问题标注上类型。5M个从维基百科。

问题语料库:从common crawl获取问题,选择开头为(“how much”,“how many”, “what”,“when”, “where” and “who”) ,以?结尾的,拒绝重复?或结尾为?!或长度大于20的。5M个。
根据Lample et al. (2018)训练cloze-to-natural模型,同样也有使用语言预训练模型同 Lample and Conneau (2019).类似。虽然使用pretraining会产生更多的好格式问题,但是对于QA的性能却并没有很大的提升,未来工作。采用无监督NMT进行cloze-to-natural。无监督NMT训练步骤如下:
使用Moses (Koehn et al., 2007),and use FastBPE (https://github.com/glample/fastBPE)进行单词和subword分割,结构上采用4层transformer进行编码和4层transformer进行解码,有一层是特定语言专用,其余共享。采用Lample el al.(2018)进行标准超参数设置,输入单词矩阵向量话使用FastText
Wh* 启发式,应用于输入的cloze问题,在训练时将答案类型映射为合适的wh*,在前面加上类型,然后进行合适的wh* 映射,规则见表格5,在训练前添加前置wh*在问题最前面,然后再添加答案类型在问题前面。如“PLACE Where is Mount Vesuvius ?”
3、Experiments 实验
1、探究不使用align的q,a数据,那么QA系统的表现性能会怎样
2、这样做对比监督学习以及其它不需要训练数据的方法(???)
3、探究解释关于不同的设计决策对我们的QA系统的性能影响
4、当只有少量可用样本时方法的可行性分析
5、评估无监督NMT对于问题生成是否有效
3.1、Unsupervised QA Experiments 无监督QA实验
采用微调BERT (Devlinet al., 2018) and BiDAF + Self Attention (Clark and Gardner, 2017) 使用合成的数据集进行训练,使用NMT模型进行问题评估,使用EM和F1进行标准评定。采用SQuAD开发数据集进行模型组件评估。
本文是第一个特意使用无监督QA在SQuAD数据集上的。同许多模型进行对比,实验结果见表一

表格1 本文最好的无监督模型对比各种baseline和监督模型,*代表结果是评估在SQuAD dev set,†表示结果是在一个不标准的测试集通过Dhingra el al.(2018)创建,‡表示我本文重新实现的。
3.2、Ablation Studies and Analysis消融实验和分析
所有的消融实验分析采用SQuAD development set。使用BERT-Base和BiDAF+SA进行消融,使用最佳的设置来进行微调BERT-Large模型,所有使用BERT-Base的实验都进行3 seeds进行重复,防止不稳定性。记录平均结果如表2

1)训练QA模型比Posterior Maximisation要好
2)答案类型是Named Entity比noun phrase要好
3)使用子句产生更短的问题,这样产生的问题分布更接近SQuAD问题分布,训练效果更好,能实现更高的F1。见图2不同问题生成器,生成问题的长度和最大相同子序列长度同SQuAD的对比图。

4)Noisy方法和UNMT翻译有助于提高训练模型的F1,其中noisy cloze能提高更多。
5)BERT-Base比BiDAF+SA要好,BERT-Large又比BERT-Base要好,对QA提升最多
6)NMT比Rule-based要好
3.3、Error Analysis 错误分析
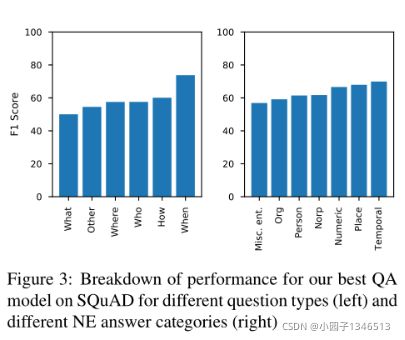
对于答案是Named Entity的SQuAD其F1能达到64.5,如果不是则只有47.9 F1,这得益于BERT的语言预训练归纳了NE在句子中的语义作业,而不是简单的模仿NER系统。图三展示了我们系统对于不同类型问题的表现。“when”问题表现最好,因为这种问题潜在的可能的答案最少“what”问题答案有很广的潜在答案所以表现最差,“TEMPORAL”同“when”一样。
3.4、UNMT-generated Question Analysis UNMT生成问题分析
完形填空和产生的问题字长是不对称的,翻译必须保存答案,而不是简单的风格转换。在不使用heuristic的情况下,UNMT将变得困难,如图4,特别是对于Person/Org/Norp和Numeric答案。

图4展示了对于NE答案无监督的UNMT产生的样例。

UNMT的输出很多都是复制的输入,产生的问题平均有context中9.1个连续的token长的子句,相较于4.7tokens的SQuAD,UNMT是保守的翻译。但是UNMT产生的问题里面也有单词的语义替换,比如“sold”换成“buy”,也有人称的替换,但是语义转义也是个问题。
使用BERT-Base采用的Faruquiand and Das(2018)里面的数据训练
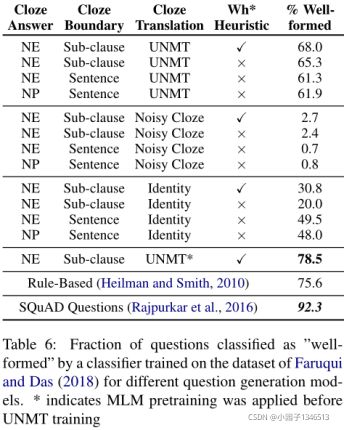
一个classifier用于问题质量评估,评估产生问题的质量,如下表格6。
可以发现UNMT可以产生68%的好格式问题,rule-based 可以产生75.6%的,同时SQuAD里面有92.3%的好问题,发现使用预训练模型的UNMT可以产生78.5%的好格式问题。
3.5、Few-Shot Question Answering 少样本问题回答
使用Section 3里面最好配置的BERT-large QA模型进行预训练(?),同时使用少量SQuAD训练数据进行调优,使用和Dhingra的BETR-Large模型进行对比,进行模型训练提早停止。如图5,我们的少样本问题回答是有用的,且同其它两种对比,我们的效果最好。

4、Related Work相关工作
Unsupervised Learning in NLP
Semi-supervised QA
Question Generation
5、Discussion 讨论
达到我们方法的最好表现需要1)NER系统2)用constituency parser 进行子句提取(trained on the Penn Treebank) 3)wh*的heuristic,这限制了我们的方法。但是我们的方法是无监督的不需要(question, answer)或(question,context)对,这对于大规模的QA训练数据来说是一个巨大的挑战。
我们还注意到“noisy cloze”系统虽然简单且缺乏问题的相关语法和句法,但是产生的效果却和我们最复杂的系统一样。同时它产生的问题格式也很差。但是这个有趣的结果表明自然问题可能对于SQuAD来说没有那么重要,然而强大的问题上下文单词匹配就足够了。
6、Conclusion 结论
对于EQA,不使用带标签的数据是可行的,且对于SQuAD达到56.4 F1,对于答案只是Named Entity达到64.5 F1,超过了很多简单的监督系统。但是虽然本文结果在相对简单的QA task上表现的鼓舞人心,但是进一步的工作需要去处理更具有挑战性的QA元素和减少对于语言资源和启发式的依赖