MySQL逻辑架构、存储引擎和SQL预热 --【MySQL高级篇1】
文章目录
- 1、MySQL逻辑架构简介
- 2、存储引擎简介
- 3、SQL预热
-
- 3.1、性能下降SQL慢
- 3.2、SQL执行顺序
- 3.3、七种JOIN理论
- 3.4、七种JOIN的编写
1、MySQL逻辑架构简介
和其他数据库相比,MySQL有点与众不同,它的架构可以在多种不同的场景中应用并发挥良好的作用,主要体现在存储引擎的架构上。插件式的存储引擎架构将查询处理和其他的系统任务以及数据的存储提取相分离。这种架构可以根据业务的需求和实际需要选择合适的存储引擎。

- 连接层:
最上层是一些客户端和连接服务,包含本地sock通信和大多数基于客户端/服务端工具实现的类似tcp/ip的通信。 - 服务层:
第二层架构主要完成大多数的核心服务,如SQL接口,并完成缓存的查询,SQL的分析进而优化及部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如过程、函数等。在该层,服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化如确定表的顺序,是否利用索引等,最后生成相应的执行操作。如果是select语句,服务器还会查询内部的缓存。如果缓存空间足够大,这样在解决大量读的操作的环境下能够很好的提升系统的性能。 - 引擎层:
存储引擎层,存储引擎真正的负责了MySQL中的数据的存储和提取,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取。 - 存储层:
数据存储层,主要是将数据存储在运行于裸机设备的文件系统之上,并完成与存储引擎的交互。
2、存储引擎简介
| 对比项 | MsISAM | InnoDB |
|---|---|---|
| 主外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 行表锁 | 表锁,即使操作一条记录也会锁住整个表,不适合高并发的操作 |
行锁,操作时只锁住某一行,不对其他行有影响,适合高并发的操作 |
| 缓存 | 只缓存索引,不缓存真实数据 | 不仅缓存索引还要缓存真实数据,对内存要求较高,而且内存大小对性能有决定性的影响 |
| 表空间 | 小 | 大 |
| 关注点 | 性能 | 事务 |
| 默认安装 | Y | Y |
- 阿里巴巴大部分mysql数据库其实使用的percona的原型加以修改。
AliSql + AliRedis
3、SQL预热
3.1、性能下降SQL慢
1. 表现
- 执行时间长
- 等待时间长
2. 原因
- 查询语句写的烂。
- 索引失效。有单值索引和复合索引
- 关联查询太多join(设计缺陷或不得已的需求)
- 服务器调优及各个参数设置不合理(缓冲、线程数等)
3.2、SQL执行顺序
1. 手写
SELECT DISTINCT
< select list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition>
LIMIT < limit_number >
2. 机读
1 FROM < left_table >
2 ON < join_condition >
3 < join_type > JOIN < right_table >
4 WHERE < where_condition >
5 GROUP BY < group_by_list >
6 HAVING < having_condition >
7 SELECT
8 DISTINCT < select list >
9 ORDER BY < order_by_condition>
10 LIMIT < limit_number >
3. 总结

3.3、七种JOIN理论
1. LEFT JOIN
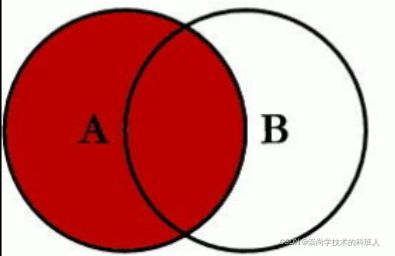
SQL语句
SELECT <select_list> FROM TableA A LEFT JOIN TableB B ON A.key=B.Key
2. RIGHT JOIN

SQL语句
SELECT <select_list> FROM TableA A RIGHT JOIN TableB B ON A.key=B.Key
3. INNER JOIN

SQL语句
SELECT <select_list> FROM TableA A INNER JOIN TableB B ON A.key=B.Key
4. LEFT JOIN + WHERE B.Key Is NULL
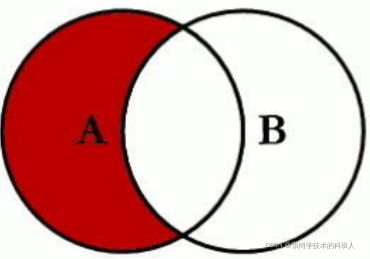
SQL语句
SELECT <select_list> FROM TableA A LEFT JOIN TableB B ON A.key=B.Key WHERE B.Key Is NULL
5. RIGHT JOIN + WHERE A.Key Is NULL

SQL语句
SELECT <select_list> FROM TableA A RIGHT JOIN TableB B ON A.key=B.Key WHERE A.Key Is NULL
6. FULL OUTER

SQL语句
SELECT <select_list> FROM TableA A FULL OUTER JOIN TableB B ON A.key=B.Key
7. FULL OUTER JOIN + WHERE A.Key Is NULL OR B.Key Is NULL

SQL语句
SELECT <select_list> FROM TableA A FULL OUTER JOIN TableB B ON A.key=B.Key WHERE A.Key Is NULL OR B.Key Is NULL
3.4、七种JOIN的编写
建表和插入数据的SQL语句
CREATE TABLE `tbl_emp` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) DEFAULT NULL,
`deptId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`) ,
KEY `fk_dept_id`(`deptId`)
)ENGINE = INNODB AUTO_INCREMENT = 1 CHARACTER SET = utf8;
CREATE TABLE `tbl_dept` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`deptName` VARCHAR(30) DEFAULT NULL,
`locAdd` VARCHAR(40) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE = INNODB AUTO_INCREMENT = 1 CHARACTER SET = utf8;
INSERT INTO tbl_dept VALUES(NULL,'RD',1);
INSERT INTO tbl_dept VALUES(NULL,'HR',12);
INSERT INTO tbl_dept VALUES(NULL,'MK',13);
INSERT INTO tbl_dept VALUES(NULL,'MIS',14);
INSERT INTO tbl_dept VALUES(NULL,'FD',15);
INSERT INTO tbl_emp VALUES(NULL,'z3',1);
INSERT INTO tbl_emp VALUES(NULL,'z4',1);
INSERT INTO tbl_emp VALUES(NULL,'z5',1);
INSERT INTO tbl_emp VALUES(NULL,'w5',2);
INSERT INTO tbl_emp VALUES(NULL,'w6',2);
INSERT INTO tbl_emp VALUES(NULL,'s7',3);
INSERT INTO tbl_emp VALUES(NULL,'s8',4);
INSERT INTO tbl_emp VALUES(NULL,'s9',51);
1. LEFT JOIN
SELECT * FROM tbl_emp a LEFT JOIN tbl_dept b ON a.deptId=b.id

说明
就是左边表有的但没有和右边表共有,那么
右边表的相应数据补NULL。
2. RIGHT JOIN
SELECT * FROM tbl_emp a RIGHT JOIN tbl_dept b ON a.deptId=b.id

说明
就是右边表有的但没有和左边表共有,那么
左边表的相应数据补NULL。
3. INNER JOIN
SELECT * FROM tbl_emp a INNER JOIN tbl_dept b ON a.deptId=b.id

4. LEFT JOIN + WHERE B.Key Is NULL
SELECT * FROM tbl_emp a LEFT JOIN tbl_dept b ON a.deptId=b.id WHERE b.id IS NULL
![]()
说明
左边表有的但右边表没有的
5. RIGHT JOIN + WHERE A.Key Is NULL
SELECT * FROM tbl_emp a RIGHT JOIN tbl_dept b ON a.deptId=b.id WHERE a.deptId IS NULL

说明
右边表有的但左边表没有的
6. FULL OUTER
SELECT * FROM tbl_emp a RIGHT JOIN tbl_dept b ON a.deptId=b.id
UNION
SELECT * FROM tbl_emp a LEFT JOIN tbl_dept b ON a.deptId=b.id

7. FULL OUTER JOIN + WHERE A.Key Is NULL OR B.Key Is NULL
SELECT * FROM tbl_emp a RIGHT JOIN tbl_dept b ON a.deptId=b.id WHERE a.deptId IS NULL
UNION
SELECT * FROM tbl_emp a LEFT JOIN tbl_dept b ON a.deptId=b.id WHERE b.id IS NULL
