无监督学习-kmeans聚类算法及手动实现
聚类
- K-means的应用场景
- sklearn实现K-means
-
- 使用鸢尾花数据进行聚类
- 聚类结果
- 查看三个中心点
- 使用K-means进行图片分割
-
- 显示原图像
- RGB分布
- 在RGB分布图中显示划分
- 图像划分结果
- 使用聚类进行预处理
-
- 加载数据集
- 一个简单的逻辑回归模型
- 使用K-means预处理的逻辑回归
- K-means算法手动实现
-
- 构建kmeans类
- 使用鸢尾花数据验证效果
- 源代码
K-means的应用场景
客户细分、数据分析、降维、半监督学习、搜索引擎、分割图像
sklearn实现K-means
使用鸢尾花数据进行聚类
from sklearn.cluster import KMeans
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris['data'][:, :2], iris['target']
k = 3
kmeans = KMeans(n_clusters=k)
y_pred = kmeans.fit_predict(X)
y_pred is kmeans.labels_
聚类结果
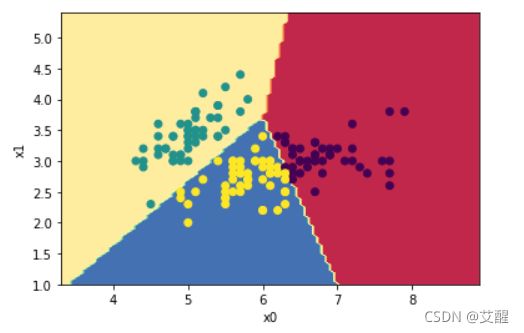
查看三个中心点
kmeans.cluster_centers_

使用K-means进行图片分割
显示原图像
import cv2
img = cv2.imread('pic.jpeg')
img=img[:,:,::-1]
plt.imshow(img)
plt.show()

可以看到原图像可以分为蓝色和白色
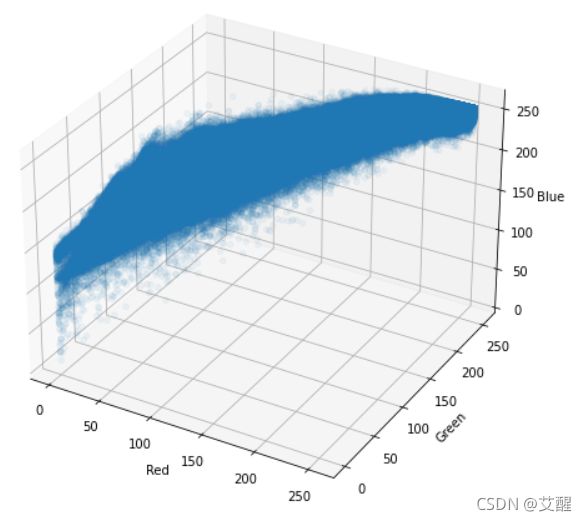
RGB分布
X=img.reshape(-1,3)
from sklearn.cluster import KMeans
km = KMeans(n_clusters=2)
km.fit(X)
y = km.labels_
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(6, 6))
ax = Axes3D(fig)
ax.scatter(X[:,0],X[:,1],X[:,2],alpha=0.05)
ax.set_xlabel('Red')
ax.set_ylabel('Green')
ax.set_zlabel('Blue')
plt.show()
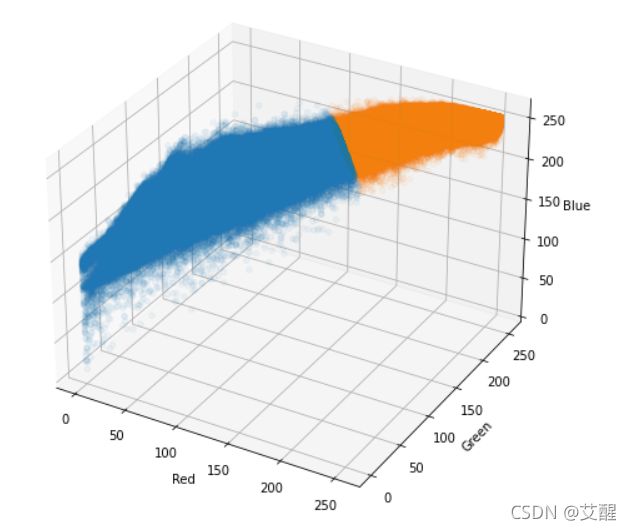
在RGB分布图中显示划分
fig = plt.figure(figsize=(6, 6))
ax = Axes3D(fig)
for i in range(3):
ax.scatter(X[y==i,0],X[y==i,1],X[y==i,2],alpha=0.05)
ax.set_xlabel('Red')
ax.set_ylabel('Green')
ax.set_zlabel('Blue')
plt.show()
图像划分结果
y=y.reshape(img.shape[:2])
plt.imshow(y)

使用聚类进行预处理
加载数据集
这里以手写数字为例
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
X_digits, y_digits = load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X_digits, y_digits)
一个简单的逻辑回归模型
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
log_reg.score(X_test, y_test)
运行结果
![]()
使用K-means预处理的逻辑回归
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
("kmeans", KMeans(n_clusters=50)),
("log_reg", LogisticRegression()),
])
pipeline.fit(X_train, y_train)
pipeline.score(X_test, y_test)
运行结果
![]()
可以看到使用聚类作为初始化可以有效提高模型的准确率
K-means算法手动实现
接下来我们手动实现一个kmeans算法
构建kmeans类
import numpy as np
class KMeans:
def __init__(self,n_clusters=5,max_iter=15):
self._n_clusters=n_clusters
self._X=None
self._y=None
self._center = None
self._max_iter=max_iter
def fit(self,X):
self._X=X
n=X.shape[0]
d=X.shape[1]
#随机生成中心点
print(X.min(axis=0))
print(X.max(axis=0))
self._center = np.array([[np.random.uniform(mi,mx) for mi,mx in zip(X.min(axis=0),X.max(axis=0))] for _ in range(self._n_clusters)])
print(self._center.shape)
step=0
#迭代
while step < self._max_iter:
#求样本点与每个中心点的距离
distances = np.array([np.sum((X-self._center[i,:])**2,axis=1) for i in range(self._n_clusters)])
#样本距离哪个最近中心点
self._y = np.argmin(distances.T,axis=1)
#对样本点加权平均计算新的中心点
self._center = np.array([np.mean(X[self._y==i,:],axis=0) for i in range(self._n_clusters)])
step+=1
#显示中间过程
plt.figure()
plt.scatter(X[self._y==0,0],X[self._y==0,1],marker='+')
plt.scatter(X[self._y==1,0],X[self._y==1,1],marker='+')
plt.scatter(X[self._y==2,0],X[self._y==2,1],marker='+')
plt.scatter(self._center[0,0],self._center[0,1])
plt.scatter(self._center[1,0],self._center[1,1])
plt.scatter(self._center[2,0],self._center[2,1])
plt.show()
return self
使用鸢尾花数据验证效果
from sklearn import datasets
import matplotlib.pyplot as plt
iris = datasets.load_iris()
X=iris.data[:,2:]
km1=KMeans(n_clusters=3)
km1.fit(X)
运行结果:

源代码
代码已经上传,等待审核过后即可查看
源代码
也可以参照百度网盘链接查看代码:
链接:https://pan.baidu.com/s/1K6pIwJC5kqASMckR05Saqg
提取码:isis