Yolov3开源代码解析-Tensoflow1.x
本文解读的Yolov3源码链接如下:
YunYang1994/tensorflow-yolov3
用Tensorflow1.x实现的
放个代码作者的博客https://yunyang1994.gitee.io/2018/12/28/YOLOv3-算法的一点理解/
Yolov3论文地址:https://arxiv.org/abs/1804.02767
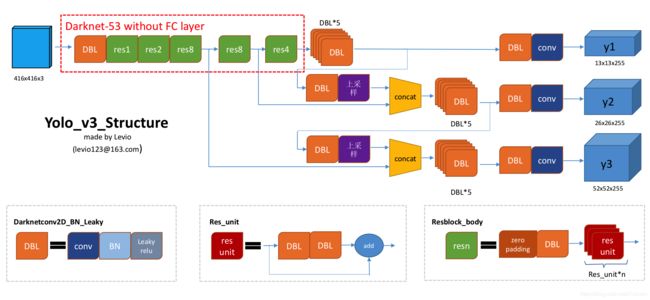
YoloV3速览
Yolov3还是遵循老传统,将图片划分为网格每个网格负责预测中心点落在该网格的物体。和Yolov2的不同之处主要有以下几个方面:
- 特征提取网络换成了Darknet53(使用残差块构建的)
- 使用多尺度输出,现在输出大中小三个网格的结果
- 重新使用anchors(k-means尺度聚类出来的)
Yolov3的总体结构图(代码作者博客中的,侵删)
代码结构
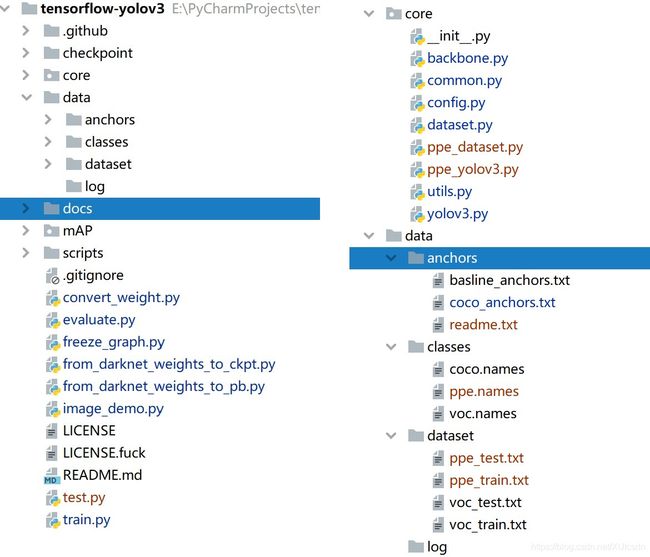
这里面红色的是我自己改了一点的代码直接忽略就行了。另外docs、mAP、script在本文里就直接忽略了,要计算mAP可以使用github上的另一个开源项目rafaelpadilla/Object-Detection-Metrics
checkpoint文件是存放Tensoflow的Saver保存的模型数据的。core就是整个Yolov3的网络和损失函数的实现,训练脚本是在根目录下的train.py里实现的。data文件夹里存放有保存了anchors文本文件、classes保存要预测的所有类别其实就是一个保存了所有类别名字的文本文件,dataset保存了包含图片路径和标注框信息的文本文件。更详细的内容之后会介绍。
YoloV3网络结构和损失函数的实现
core下面的内容实现了整个Yolov3,文件清单如下:
- dataset.py 从data/dataset读取数据集信息,生成batch
- common.py 封装Tensorflow的API,主要是卷积和残差块的封装
- backbone.py 构建的Darknet53网络
- yolov3.py 使用Darknet53构建的Yolov3网络,以及损失函数
- config.py 训练使用的各种超参数和Yolov3网络的一些参数配置
- utils.py 工具
现在来一个一个文件的说说作者是怎么实现的,首先来把主要的Yolov3网络和损失函数的实现理一理。要实现Yolov3首先就得先实现它的主干网Darknet53,要实现这个主干网就要使用残差块和一些卷积操作。由于原生的Tensorflow的卷积操作还需要先定义变量,batch normal也没有指数加权移动平均等等一些列的麻烦事,所以先封装一下这些操作。
TF1.x这些原生的的操作的确是麻烦了一点,但如果要使用Tensorboard监控变量或者中间值的话的确也很方便。不过TF1.x的静态图确实不好调试,不得不说一句TF提供的调试控制台难用的一逼。
common.py里面就封装了这些操作,这里主要看看作者对卷积操作和残差块的封装,上采样和一个route实在太简单就不说了。
def convolutional(input_data, filters_shape, trainable, name, downsample=False, activate=True, bn=True):
with tf.variable_scope(name):
if downsample:
pad_h, pad_w = (filters_shape[0] - 2) // 2 + 1, (filters_shape[1] - 2) // 2 + 1
paddings = tf.constant([[0, 0], [pad_h, pad_h], [pad_w, pad_w], [0, 0]])
input_data = tf.pad(input_data, paddings, 'CONSTANT')
strides = (1, 2, 2, 1)
padding = 'VALID'
else:
strides = (1, 1, 1, 1)
padding = "SAME"
weight = tf.get_variable(name='weight', dtype=tf.float32, trainable=True,
shape=filters_shape, initializer=tf.random_normal_initializer(stddev=0.01))
conv = tf.nn.conv2d(input=input_data, filter=weight, strides=strides, padding=padding)
if bn:
conv = tf.layers.batch_normalization(conv, beta_initializer=tf.zeros_initializer(),
gamma_initializer=tf.ones_initializer(),
moving_mean_initializer=tf.zeros_initializer(),
moving_variance_initializer=tf.ones_initializer(), training=trainable)
else:
bias = tf.get_variable(name='bias', shape=filters_shape[-1], trainable=True,
dtype=tf.float32, initializer=tf.constant_initializer(0.0))
conv = tf.nn.bias_add(conv, bias)
if activate: conv = tf.nn.leaky_relu(conv, alpha=0.1)
return conv
def residual_block(input_data, input_channel, filter_num1, filter_num2, trainable, name):
short_cut = input_data
with tf.variable_scope(name):
input_data = convolutional(input_data, filters_shape=(1, 1, input_channel, filter_num1),
trainable=trainable, name='conv1')
input_data = convolutional(input_data, filters_shape=(3, 3, filter_num1, filter_num2),
trainable=trainable, name='conv2')
residual_output = input_data + short_cut
return residual_output
先来看卷积操作,没什么好说的定义卷积核变量然后执行conv2d,然后有几个参数来控制激活函数和batch norm。唯一值得说的是strides不为1时进行了固定的填充,这个填充是为了使不同尺寸的输入具有相同的填充,避免使用SAME填充可能造成的这种像素级误差。
说到batch normal,这里使用的其实keras封装过了的,里面自带了对每个batch计算得到的均值和方差的指数加权移动平均的变量。关于这两个变量加权的衰减率设置其实还和batch的大小有关系,有时这个衰减率设置的有问题会导致网络在推理时的性能很差,特别是在循环神经网络这种非常长的网络里面,具体的关系说实话我也不太清楚,只是遇到过这个坑。