2004 - 字符拼接时代
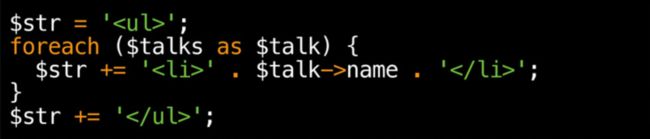
时光倒流,在 Facebook 的早期,马克·扎克伯格还在他的宿舍里,使用 PHP 构建网站的方式是使用字符串连接。事实证明这是一个非常好的建站方式,无论你是后端,前端,甚至没有编程完全没有经验,都可以建一个大网站

这种编程方式的唯一问题是它不安全。如果你使用这个精确的代码,攻击者可以执行任意 Javascript。这对 Facebook 尤其不利,因为此代码将在用户上下文中执行。这样你基本上可以接管用户帐户
如果你什么都不做,你就很脆弱。更糟糕的是,对于大多数输入,它实际上是将为开发该功能的开发人员呈现良好的效果。所以很少激励他/她添加适当的转义
而且,真正糟糕的特性是,您需要在数百名工程师编写的数百万行代码中包含每个调用站点,以确保安全。犯了一个错误?你的账户可能会被接管
避免这种不可能的情况的一个想法是,不管发生什么,都要避免一切。不幸的是,它不太管用,如果您对字符串进行双重转义,它将显示控制字符。如果您不小心转义标记,那么它将向用户显示 html!
2010 - XHP

我们在 Facebook 提出的解决方案是扩展 PHP 的语法以允许开发人员编写标记。在这种情况下
- 不再在字符串中

现在,标记的所有内容都是使用不同的语法编写的,因此我们知道在生成HTML时不要逃避它。其他所有内容都被视为不受信任的字符串并自动转义。我们可以在保证安全的同时保持开发的便利性

XHP 一经推出,不久人们就意识到他们可以创建自定义标签。事实证明,它们可以让您通过组合大量这些标记轻松构建非常大的应用程序。这是语义Web和Web组件概念的一个实现
我们开始在 Javascript 中做越来越多的事情以避免客户端和server之间的延迟, 我们尝试了很多技术,比如拥有一个跨浏览器的 DOM 库和一个数据绑定方法,但没有一个对我们真正有效
鉴于当前的世界状况,前端工程师 Jordan Wake 向他的经理提出了以下想法:将 XHP 移植到 Javascript。他以某种方式开始实践6个月,以便证明这个概念。
我第一次听说这个项目时,我想,绝对不可能实现,但在难得的机会中,这将是巨大的成功。当我终于开始使用它时,我立即开始传福音
2013 - JSX

第一个任务是编写支持这种奇怪的 XML 语法的 Javascript 扩展。我们 在Facebook使用 Javascript 转换实现了已有一段时间了。在这个例子中,我正在使用另一种方法编写下一个JavaScript标准ES6的函数。
实现 JSX 花了大约一周的时间,这并不是 React 最重要的部分,更有挑战性的是重现PHP的更新机制,真的很简单。
PHP -- 有什么变化吗?重新渲染一切。我们可以让它足够快吗?
每当有任何变化时,您都会转到一个新页面并获得一个完整的新页面。从开发人员的角度来看,这使得编写应用程序非常容易,因为您不必担心变化,也不必在UI发生变化时确保所有内容都同步
然而,每个人都会问的问题…它会非常慢
React -- 不仅速度够快,它通常比以前的实现更快
经过 2 年的生产使用,我可以自信地说,它比大多数产品快得多,我们替换它的代码。在本次演讲的其余部分,我将解释使之成为可能的重大优化
阿基姆·德梅尔 -- "You need to be right before being good"
我在学校的老师曾经说过,你需要先做对,然后才能做好。他的意思是如果您试图构建性能良好的东西,那么如果您首先构建一个简单但有效的实现并迭代性能,而不是从一开始就尝试以最佳方式构建它,那么您成功的几率会高得多
Naive
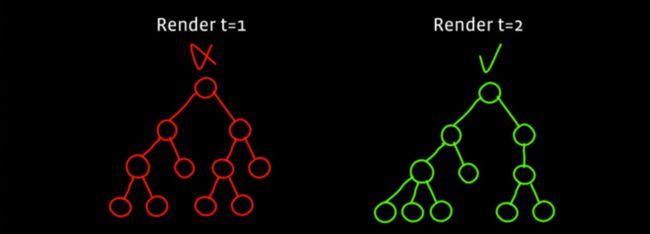
所以,让我们尝试应用他的建议。我们首先要实现最简单的版本。无论何时如果有任何变化,我们将构建一个全新的DOM并替换旧的DOM
DOM is Stateful

这是一种运行情况,但有很多边缘情况。如果你销毁DOM 将丢失当前聚焦的元素和光标,文本选择和滚动位置也是如此。这实际上意味着DOM节点实际上包含状态。
第一次尝试是试着恢复那些状态,我们会记住焦点输入,聚焦新元素,光标和滚动位置相同。不幸的是,这不足够
如果您使用的是 mac 并进行滚动,您将有惯性滑动。结果是没有用于读取或写入滚动惯性的 Javascript Apl。对于 iframe,如果它来自另一个 iframe,则情况更糟,安全策略实际上不允许您查看里面的内容,因此您不能恢复它。 DOM 不仅是有状态的,而且还包含隐藏状态
Reuse Nodes

为了解决这个问题,我们的想法不是销毁DOM并重新创建一个新的DOM,而是重用在两个渲染之间保持不变的DOM节点

我们将匹配节点,而不是删除以前的DOM树并将其替换为新的DOM树,如果它们没有更改,则丢弃新的DOM树并保留当前在屏幕上呈现的旧DOM树
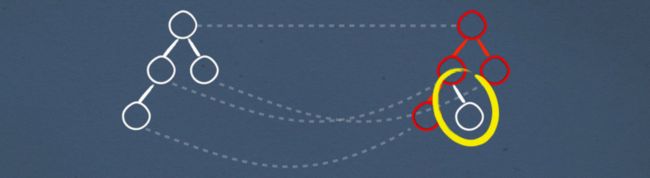

只要我们能够匹配节点,我们就会重复这个过程。但在某个时刻,我们将看到一个以前不存在的新节点。在本例中,我们将把新的dom树移动到旧的(当前在屏幕上呈现)dom树
AdonisSMU -- "I tend to think of React as Version Control for the DOM"
我们现在对React 的工作方式有了一个大致的了解,但没有具体的计划
这是我从帽子里拿出类比卡的那一刻

回到编程的黑暗时代,如果你想让别人尝试你的代码,你会创建一个 zip 并发送给他。如果您更改了任何内容,您将发送一个新的 zip 文件
版本控制出现了,它的工作方式是,它获取代码的快照并生成一个突变列表,如“删除那5行”、“添加3行”、“替换这个单词”…使用diff算法
这正是 React 所做的,但使用 DOM 作为输入而不是文本文件
Optimal Diff -- O(n^3)

因此,作为一名优秀的工程师,我们研究了树的diff算法,发现最优解在O(n)中
假设我们有一个包含 10,000 个 DOM 节点的页面。它很大但并非不可想象。为了得到一个数量级,我们假设我们可以在一个CPU周期内完成一个操作(不会发生),并且有一台1GHz的机器

计算差异需要17分钟!我们不能用那个。。。
但是,不要害怕,我们知道仍处于我们需要正确的阶段。那么我们研究它的工作方式

(1)对比新树中的每个节点,
(2) 将再次匹配旧树的每个节点
(3) 匹配操作对整个子树进行操作。在这里,我们得到了三个嵌套循环
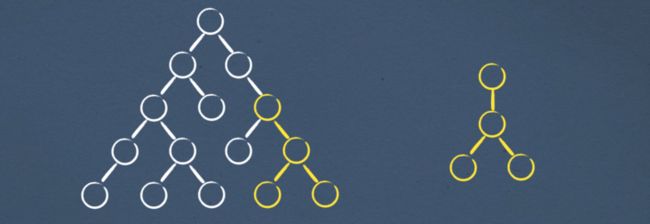


仔细想想,在web应用程序中,我们很少需要将元素移动到页面中的任何其他位置。我想到的唯一一个例子是拖放,但这并不常见。
移动元素的唯一时候是在子元素之间您经常添加/删除/移动列表中的元素
子元素嵌套

所以,我们可以通过子元素来计算差异。我们从其根开始并将其与其他根做匹配
并为所有匹配的子元素这样做。我们从一个可怕的大 O(n 变成很多O(m
我们尝试变得更好更快
事实证明,我们不能直接使用 Levenstein距离算法
Identity

为了了解原因,最好的方法是通过一个小例子。我们看到第一个渲染有三个输入,而下一个渲染只有两个输入。问题是如何匹配它们?

直观的反应是将前两个匹配在一起并删除第三个

但是,我们也可以删除第一个并将最后两个匹配在一起

一个不太明显但仍然完全有效的解决方案是删除所有以前的元素并创建两个新元素。所以在这一点上,我们没有足够的信息来正确地进行匹配,因为我们希望能够处理上述所有用例
一种想法是不仅使用标签名称而且使用属性。如果它们前后相等,那么我们进行匹配
![]()
事实证明这不适用于 value 属性。如果您尝试输入“oscon”,那么两者将是不同的输入焦点
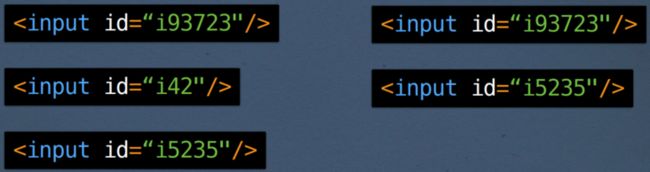
另一个更有希望的属性是 id 属性。在表单上下文中,它通常包含输入对应的模型的 id
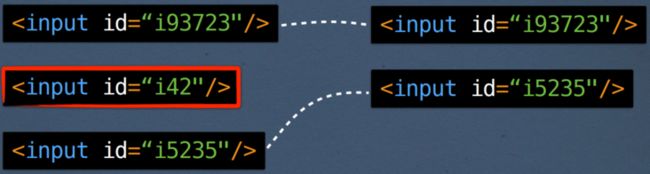
现在,我们能够成功匹配两个列表! (您是否注意到它与我之前展示的三个示例相比又一次匹配?)
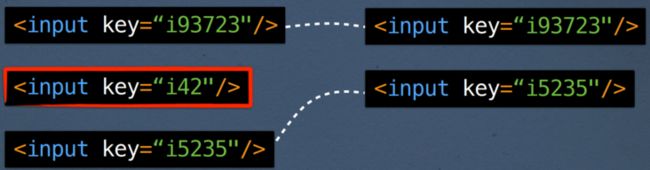
但是,如果您通过 AJAX 提交表单而不是让浏览器来提交,则不太可能将该 id 属性放入 DOM 中。
React引入key属性。它唯一的工作就是帮助diff算法进行匹配
子元素嵌套

事实证明,我们可以在O(n)中通过哈希表使用比 O(n 快得多的keys来实现匹配
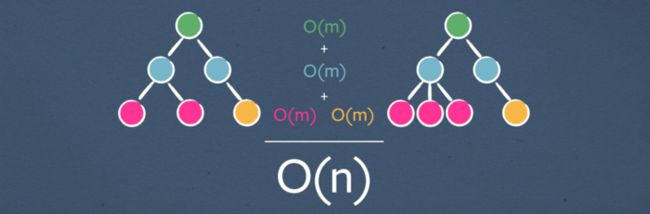
所以,如果我们把所有的部分O(m)相加,我们得到了O(n)的总复杂度。不可能有更好的复杂性
Let the goodness begin!
此时,我们已经有了一个正确的解决方案,我们现在可以开始实施所有很酷的优化以使其快速运行
如果你对 JS 应用做过任何优化,你可能听说 DOM 很慢。 Stack Exchange 上的 Rafal 做了一个很好的说明。如果你枚举一个空 div 的所有属性,你会看到很多!
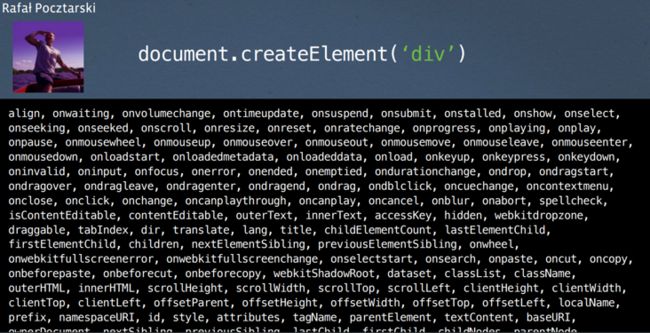
之所以有这么多属性,是因为浏览器渲染管道的很多步骤都使用了一个DOM节点。
浏览器首先查看 CSS 规则并找到与该节点匹配的规则,并在此过程中存储各种元数据以使其更快。例如,它维护一个 id 到 dom 节点的映射。
然后,它采用这些样式并计算布局,其中包含屏幕中的位置和定位。同样,大量的元数据。它将尽可能避免重新计算布局,并缓存以前计算的值。
然后,在某些时候,您实际上是 CPU 或 GPU 上的缓冲区。
所有这些步骤都需要起媒介作用表示并使用内存和 CPU。浏览器在优化整个管道方面做得非常好
Virtual DOM
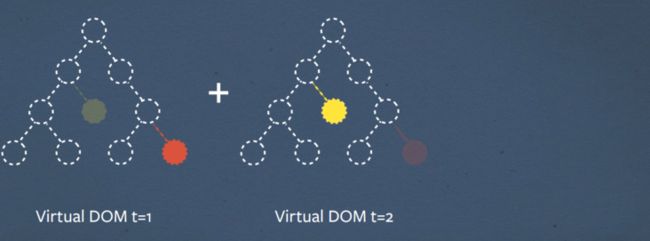
但是,如果您考虑一下 React 中发生的事情,我们只会在 diff 算法中使用那些 DOM 节点。所以我们可以使用一个更轻的 JavaScript 对象,它只包含标签名称和属性。我们称之为虚拟 DOM。

diff 算法生成一个 DOM 突变列表,与版本控制输出文本突变的方式相同

我们可以应用到真正的 DOM 上。然后我们让浏览器执行所有优化的管道。我们将昂贵但需要的 DOM 突变数量减少到最低限度
Batching

来自可汗学院的 Ben Alpert 通过批处理操作解决了这个问题。
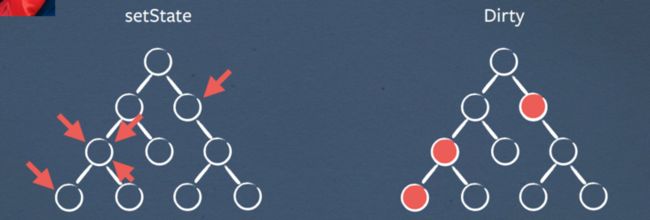
为了告诉 React 某些事情发生了变化,您可以在元素上调用 setState。 React 只会将元素标记为脏元素,但不会立即计算任何内容。如果你在同一个节点上多次调用 setState,它的性能也会一样
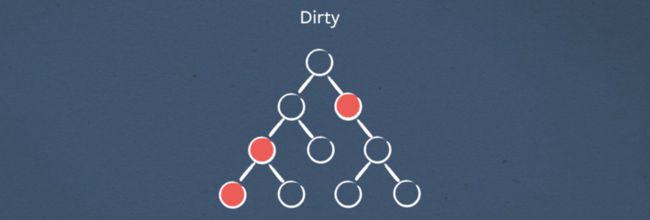
一旦初始事件完全传播……
我们可以从上到下重新渲染元素。这非常重要,因为它确保我们只渲染元素一次
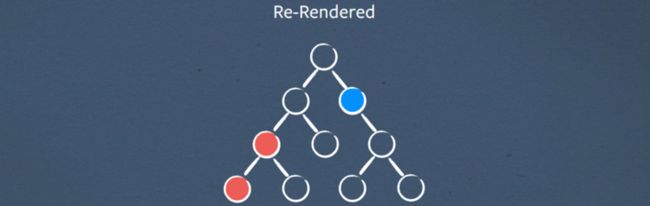

现在所有元素都已重新渲染到虚拟 DOM,我们将其提供给输出 DOM 突变的 diff 算法。在此过程中,我们无需从 DOM 中读取任何内容。 React 是只写
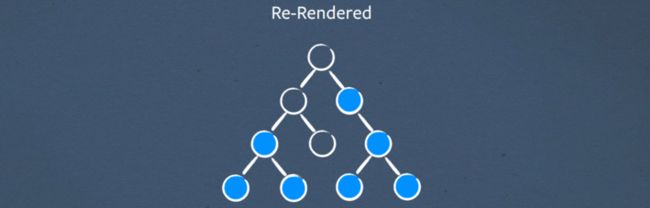
Subtree Re-rendering

一开始我说心智模型是“当任何事情发生变化时重新渲染一切”。这在实践中并不完全正确。我们只从已被 setState 标记的元素重新渲染子树。
当您开始将 React 集成到您的应用程序中时,通常的模式是在树内具有非常少的状态,因此 setState 代价非常低,因为它们只重新呈现 UI 的一小部分
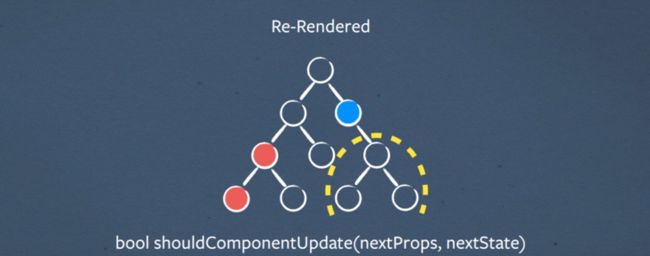
Pruning

当更多的应用程序被转换时,状态往往会上升,这意味着当发生任何变化时,您正在重新渲染应用程序的更大部分。

为了在性能方面减轻这种影响,您可以实现shouldComponentUpdate,它带有前一个和下一个state/props可以说:“你知道吗,什么都没有改变,让我们跳过重新渲染这个子树”
这使您可以精简大部分的树并重新获得性能

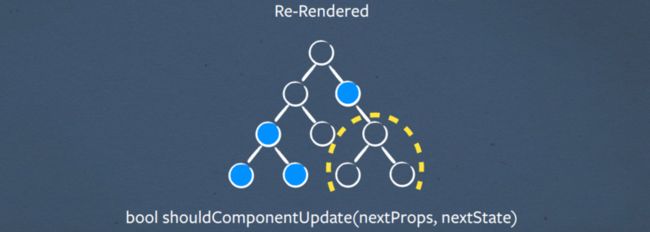
shouldComponentUpdate?
我们在开源版本中引入了 shouldComponentUpdate,但我们不太清楚如何正确实现它。
问题是在 JavaScript 中你经常使用对象来保存状态并直接改变它。这意味着状态的上一个和下一个版本是对对象的相同引用。因此,当您尝试将上一个版本与下一个版本进行比较时,即使发生了一些变化,它也会说前后状态一致。
纽约时报的大卫诺伦想出了一个很好的解决方案。在 ClojureScript 中,所有大多数值都是不可变的,这意味着当你更新一个时,你会得到一个新对象,而旧的则保持不变。这与 shouldComponentUpdate 配合得很好。
他在 ClojureScript 中在 React 之上编写了一个名为 Om 的库,该库使用不可变的数据结构来默认实现 shouldComponentUpdate
不幸的是,使用不变的数据结构需要一个巨大的思想飞跃,而每个人还没有做好准备。所以现在和可预见的未来 React 必须在没有它们的情况下工作,因此默认情况下无法实现 shouldComponentUpdate。
作为替代,我们刚刚发布了一个性能工具。您在应用程序中玩了一段时间,每次重新渲染组件时,如果diff没有输出任何DOM变化,那么它就会记住渲染所花的时间。最后,您会得到一个很好的表,它告诉您哪些组件将从shouldComponentUpdate中受益最大!

通过这种方式,您可以将其放在几个关键位置并获得最大性能优势
Conclusion
在本次演讲中,我们介绍了 React 正在做的四种优化:差异算法、虚拟 DOM、批处理和精简。我希望它能阐明它们存在的原因以及它们如何工作。
React 用于构建我们的桌面网站、移动网站和 Instagram 网站。它在 Facebook 非常成功,以至于基本上所有新的前端产品都是使用 React 编写的。这不是我们只是在内部工具或小功能中使用的项目,这是每个月有数亿人使用的Facebook主页使用的!
由于我们在开源会议上,我想以反思一下作为结束
我们在 2010 年开源了 XHP,但我们在这方面做得非常糟糕,我们在 4 年内只写了一篇博文。我们没有参加会议来解释它,编写文档……然而,在 Facebook 内部,我们非常喜欢它并在任何地方使用它。
去年我们开源 React 时,难度要大得多,因为我们必须同时解释 XHP 的好处以及我们必须做的所有疯狂优化才能使其在客户端上运行。
我们经常谈论开源的好处。这是一个很好的提醒,不开源您的核心技术会使其他项目的开源变得更加困难