作者:冰茹
小T导读: 和利时始创于1993年,业务集中在工业自动化、交通自动化和医疗大健康三大领域,结合自动化与信息化两方面的技术优势,提出了“智能控制、智慧管理、自主可控、安全可信”的战略指导方针。围绕集团三大业务,公司对工业互联网、大数据、5G、信息安全等新兴技术开展更深入的研究和应用示范,打造面向各领域应用的工业互联网平台,进一步促进智能制造解决方案的落地应用。

在物联网场景下,面对庞大的时序数据处理需求,Oracle、PostgreSQL等传统关系型数据库越来越吃力。基于此,目前国内外主流工业互联网平台几乎都已经采用时序数据库,来承接海量涌入的工业数据。
究其原因,可以从数据的三个核心需求来解释。我们都知道,企业在选择数据库、文件系统等产品时,最终目的都是为了以最佳性价比来满足数据的三个核心需求:数据写入、数据读取、数据存储。时序数据库完全是按照时序数据的三个需求特征进行设计和开发的,在数据处理上更加具有针对性:
- 在数据写入上,如果将时间看作一个主坐标轴,时序数据通常是按照时间顺序抵达,抵达的数据几乎总是作为新条目被记录,在数据处理操作上95%-99%都是写入操作;
- 在数据读取上,随机位置的单个测量读取、删除操作几乎没有,读取和删除都是批量的,从某时间点开始的一段时间内读取的数据可能非常巨大;
- 在数据存储上,时序数据结构简单,价值随时间推移迅速降低,通常都是通过压缩、移动、删除等手段来降低存储成本。
而关系型数据库主要应对的数据特点却大相径庭:
- 数据写入:大多数操作都是DML操作,插入、更新、删除等
- 数据读取:读取逻辑一般都比较复杂
- 数据存储:很少压缩,一般也不设置数据生命周期管理
因此,从数据本质的角度而言,时序数据库(不变性、唯一性以及可排序性)和关系型数据库的服务需求完全不同。这也是我们一开始就锁定时序数据库来满足工业互联网场景的核心原因。
一、时序数据库选型
我们对包括InfluxDB、OpenTSDB、HolliTSDB(和利时自研时序数据库)、TDengine在内的四款时序数据库进行了选型调研及相关测试。 测试数据的频率为1秒钟,数据集包含10000台设备,每台设备有10000条记录,每条数据采集记录包含3个标签字段、2个数据字段、1个时间戳字段。测试对比项包括占用磁盘空间、百万条数据遍历查询、聚合查询(COUNT、AVG、SUM、MAX、MIN)。测试结果如下所示:
- 占用磁盘空间

- 百万条数据遍历查询
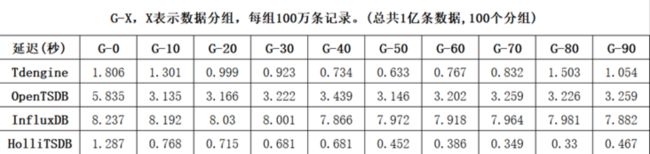
- 聚合查询COUNT

- 聚合查询AVG

- 聚合查询SUM

- 聚合查询MAX
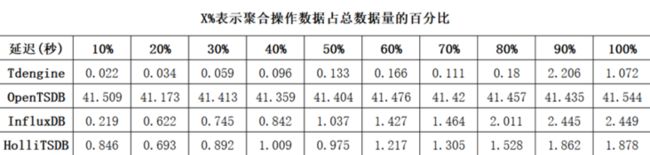
- 聚合查询MIN
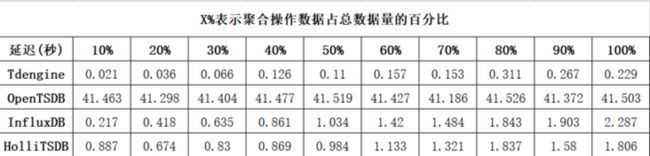
同等条件下,TDengine的压缩率最高,数据占用的存储空间最小;在原始数据查询上,OpenTSDB最慢,TDengine与HolliTSDB在伯仲之间;在聚合查询操作上,TDengine最快,HolliTSDB的速度和InfluxDB相当,OpenTSDB最慢。同时,InfluxDB只能单机部署,集群版本并未开源,且查询性能存在瓶颈,其QPS约为30-50。
从性能测试结果来看,我们选择TDengine的原因主要源于以下几点:
- TDengine在查询性能维度上的表现非常优异,满足了我们的业务查询需求
- 集群功能开源,方便横向扩展,更弹性
- 在开源热潮之下,支持如TDengine一般的国产开源数据库、操作系统、中间件等也是企业的必修课
最终我们决定接入TDengine,以享受更多元的本地化支持和响应。
二、技术架构与实现
目前TDengine作为边缘版时序数据库在搭建使用,具体的技术架构如下图所示:

基于TDengine进行建库建表思路如下:
CREATE STABLE IF NOT EXISTS ts_super
(time TIMESTAMP, s BIGINT, vl BIGINT,vf DOUBLE,vb BOOL,vs BINARY(16349))
TAGS
(innerId BIGINT, namespace BINARY(256), id BINARY(256), type BINARY(1), seq int);在构建列时,包含元素为time(时间,主键)、s(数据质量)、vl(整形类型数据L)、vf(浮点型数据F)、vb(布尔型数据B)、vs(字符串数据S),其中time、s是必填的列,剩余列则要根据测点类型填写,比如测点上报的是整形数据,就只需要设置time、s、vl这三列,vf、vb、vs这三列为null。
在构建tag时,要包括innerId(测点内部编码)、id(测点id)、type(测点类型,L/F/B/S)、seq (序号,L/F/B类型数据设置为0,S类型测点的seq可能为0,1,2,3...)
同时,在建库建表的操作中我们也碰到了一些小问题,放在这里给大家做下参考:
- 因为表名不支持特殊字符,所以需要再生成一个唯一编码作为表名;
- 查询语句会被填充,导致查询过程性能变慢,网卡被打满。这种情况下只需要将查询请求手动压缩,就能有效降低带宽占用率;
- TDengine字符串最长可以有16374字节 ,超过的话需要从逻辑上处理。我们采用的方案是如果长度超过16374 ,截取该字符串,同一个测点再建新的表,通过tag关联。
三、实际效果展示
1. 数据库配置
TDengine集群5个节点,副本数设置为3。修改配置为:
- minTablesPerVnode 10
- tableIncStepPerVnode 10
- compressMsgSize 1024
- rpcForceTcp 1
- httpMaxThreads 16
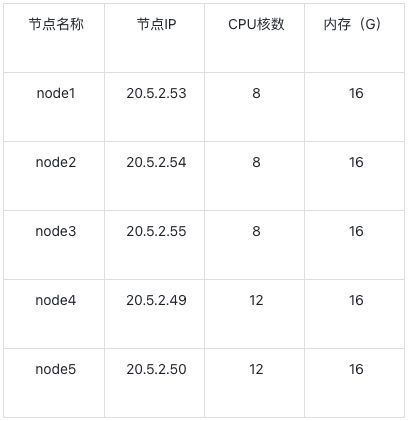
各节点机器配置如下:
2. 查询客户端配置
客户端共有三台主机,每台主机上分别运行时序查询及其对应的AB,各主机上的时序查询独立运行,分别启动一/二/三个时序查询及其对应的AB进行性能测试。

3. 数据说明
共1000个测点,80000万条数据,数据频率为每秒钟1条。存储分布如下所示,存储压缩率不超过1/10。

4. 查询结果

在我们的业务查询当中,增加QPS的主要方式是增加查询的并发数。AB从1到2,QPS增加了45%,平均响应时间不超过1000ms,很好满足了客户需求
5. 资源消耗(统计3个查询服务的实例)
- TDengine node节点资源消耗

在查询过程中,数据是相对均匀的分布,但是不同节点的CPU消耗仍然有较大的方差。这是由于TDengine的RESTful的底层是在服务端通过单独的代理线程作为客户端查询,所以会受到请求均匀度的影响。如果TDengine在后续可以做代理层面的负载均衡,相信能够缩小这个偏差。
6. 查询服务资源消耗

在查询段的节点资源消耗还是相当大的,因为需要对查询请求和结果进行处理。在具体业务中,可以考虑使用RPC接口来降低查询服务的CPU消耗。
四、写在最后
TDengine在本项目中展现出的性能效果非常显著,推动本次项目快速且高质量落地,实现降本增效的目标。接下来,希望TDengine能够在以下两个方向上有更大的进步,也祝愿我们的合作能够越来越紧密:
- 希望可以通过触发器或协处理器等方式,在服务端做数据过滤再返回,解决网络压力过大的问题
- 希望能够进一步改善长度限制的问题
⬇️点击下方图片查看活动详情,iPhone 13 Pro 等你带回家!