教师学生模型、伪标签、半监督学习和图像分类
使用 Noisy Student 进行自训练改进 ImageNet 分类是一篇由 Google Research、Brain Team 和Carnegie Mellon大学发表在2020 CVPR的论文
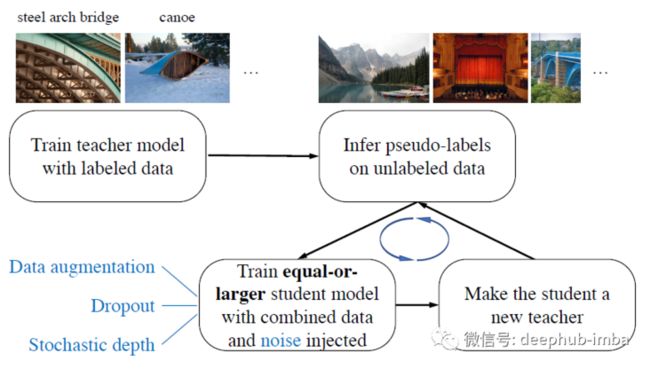
Noisy Student在训练时使用相等或更大的学生模型和在学习期间添加噪声(Dropout, Stochastic Depth,和数据增强)扩展了自训练和蒸馏方法。
- 一个 EfficientNet 模型首先作为教师模型在标记图像上进行训练,为 300M 未标记图像生成伪标签。
- 然后将更大的 EfficientNet 作为学生模型并结合标记图像和伪标签图像进行训练。
- 学生网络训练完成后变为教师再次训练下一个学生网络,并迭代重复此过程。
Noisy Student的训练过程
标记图像 {(x1, y1), (x2, y2), ..., (xn, yn)},未标记的图像 {~x1; ~x2, ..., ~xm} 第 1 步:学习教师模型 θ t*,它可以最大限度地减少标记图像上的交叉熵损失:
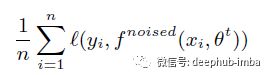
第 2 步:使用正常(即无噪声)教师模型为干净(即无失真)未标记图像生成伪标签:
![]()
经过测试软伪标签(每个类的概率而不是具体分类)效果更好。
第 3 步:学习一个相等或更大的学生模型 θ s*,它可以最大限度地减少标记图像和未标记图像上的交叉熵损失,并将噪声添加到学生模型中:
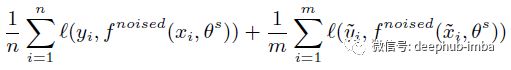
步骤 4:学生网络作为老师,从第2步开始进行迭代训练。
噪声
噪声由两种类型:输入噪声和模型噪声。
- 对于输入噪声,使用 RandAugment [18] 进行数据增强。简而言之,RandAugment 包括增强:亮度、对比度和清晰度。
- 对于模型噪声,使用 Dropout [76] 和 Stochastic Depth [37]。
噪声具有在标记和未标记数据的决策函数中强制执行不变性的重要好处。
数据增强是Noisy Student训练中的一种重要方法,因为它迫使学生确保图像增强版本之间的预测一致性。
教师模型通过干净的图像来生成高质量的伪标签,而学生则需要使用增强图像作为输入来重现这些标签。
当 Dropout 和 Stochastic Depth 函数用作噪声时,教师模型在推理时表现得像一个集成(当它生成伪标签时),而学生模型表现得像一个单一的模型。换句话说,学生被迫模仿更强大的集成模型。
其他一些信息
Noisy Student在训练还通过一个额外的技巧更好地工作:数据过滤和平衡。教师模型具有低置信度( < 0.3)的图像会被过滤,因为它们通常是域外图像。每个类的未标记图像的数量需要进行平衡,因为 ImageNet 中的所有类都具有相似数量的标记图像。为此,复制没有足够图像的类中的图像。对于图像过多的类,会使用置信度最高的图像(最多 130K)。
一些训练的细节如下
- 使用了 EfficientNet-L2,它比 EfficientNet-B7 更宽更深,但使用了较低的分辨率。
- 使用了 FixRes。
- JFT 用作未标记的数据集。用于训练学生模型的图像总数为 130M(包含一些重复图像)。因为重复所以这 130M 图像中只有 81M 独特图像。
- 最大的模型 EfficientNet-L2 需要在 Cloud TPU v3 Pod 上训练 6 天,该 Pod 有 2048 个内核。
实验结果
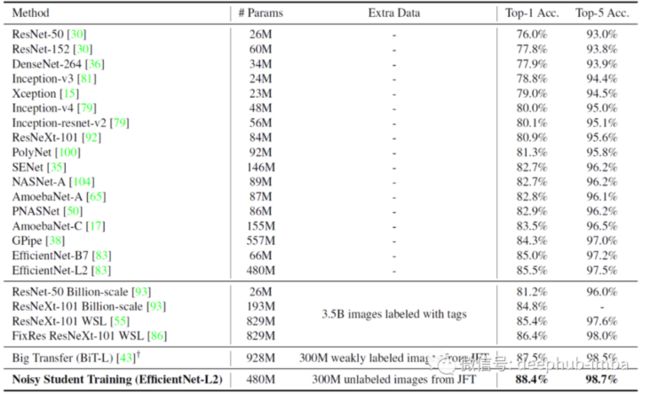
EfficientNet-L2 with Noisy Student 在训练时达到了 88.4% 的 top-1 准确率,明显优于 EfficientNet 上报告的 85.0% 的最佳准确率。3.4% 的总收益来自两个来源:通过使模型更大(+0.5%)和Noisy Student(+2.9%)。
换句话说,Noisy Student 训练对准确性的影响比改变架构要大得多。
Noisy Student 训练超过了需要 35 亿张带有标签的 Instagram 图像的 FixRes ResNeXt-101 WSL [55, 86] 86.4% 的最新准确率, 作为比较,Noisy Student Training 只需要 300M 未标记的图像,这可能更容易收集。并且与 FixRes ResNeXt-101 WSL 相比,所提出的模型的参数数量也大约少了两倍。如果仅使用大约一半的模型大小,Noisy Student训练也优于 BiT-L。
不进行迭代训练的Noisy Student
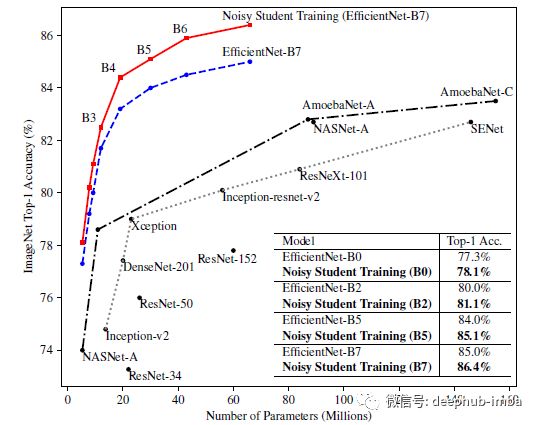
Noisy Student 训练导致所有模型大小的持续提高率为 0.8%。具有Noisy Student 的 EfficientNets 在模型大小和准确性之间提供了更好的权衡。
稳健性基准测试

ImageNet-C 和 P 测试集 [31] 包括具有常见损坏和扰动的图像,例如模糊、雾化、旋转和缩放。ImageNet-A 测试集 [32] 由难度较大的图像组成,这些图像会导致最先进模型的准确性显著下降。
标准模型的预测是不正确的,而 Noisy Student Training 模型的预测是正确的。

在ImageNet-A上,它将前一名的准确率从61.0%提高到83.7%。在ImageNet-C上,它将 mean corruption error(mCE)从45.7减少到28.3。在ImageNet-P上,如果使用224×224(直接比较)的分辨率,它会导致mean flip rate (mFR)为14.2,如果使用299×299的分辨率,则会降低至12.2。
对抗性鲁棒性结果
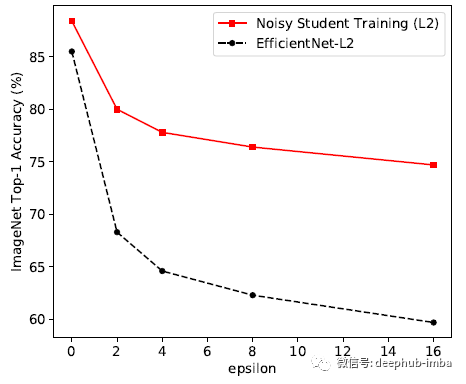
FGSM 攻击在输入图像 [25] 上执行一个梯度下降步骤,每个像素的更新设置为 ε。
Noisy Student训练将 EfficientNet-L2 的准确率从 1.1% 提高到 4.4%,尽管该模型并未针对对抗鲁棒性进行优化。
消融研究
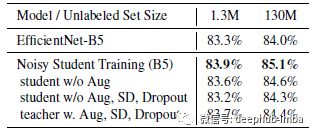
Stochastic Depth, Dropout 和数据增强等噪声在使学生模型比教师模型表现更好方面发挥着重要作用。随着噪声功能的移除,性能持续下降。发现向生成伪标签的教师模型添加噪声会导致准确性降低,这表明拥有强大的无噪声教师模型是非常重要的。
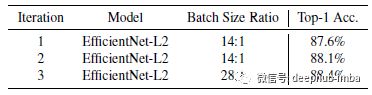
模型性能在第一次迭代中提高到 87.6%,然后在第二次迭代中提高到 88.1%。对于最后一次迭代,未标记的批量大小和标记的批量大小之间的比率更大,用于将最终性能提高到 88.4%。(更多消融在论文的附录中介绍。如果有兴趣,请仔细阅读。)
总结
- 使用性能更好的大型教师模型会带来更好的结果。
- 为了获得更好的性能,需要大量未标记的数据。
- 在某些情况下,对于域外数据,软伪标签比硬伪标签更有效。
- 大型学生模型对于让学生变为更强大的模型很重要。
- 数据平衡对于小型模型很有用。
- 标记数据和未标记数据的联合训练优于首先使用未标记数据进行预训练然后对标记数据进行微调。
- 在未标记的批次大小和标记的批次大小之间使用较大的比率可以使模型在未标记数据上训练更长时间,以实现更高的准确性。
- 从头开始训练学生有时比用老师初始化学生要好,而用老师初始化的学生仍然需要大量的训练 epoch 才能表现良好。
论文地址:
https://www.overfit.cn/post/894964adab5c4c14b5cba4564f12a93f
[2020 CVPR] [Noisy Student]Self-training with Noisy Student improves ImageNet classification arxiv 1911.04252
本文作者:Sik-Ho Tsang