一、现状查看
1.某天晚上,监控报警某台线上机器的内存剩余量小于20%,查看近7天内存情况发现一直在逐步增长

2.登录线上机器 top

发现java进程的cpu和内存都比较高
3.jmap -heap pid

发现老年代已经用了83%的空间,应该是有对象一直未释放,没有被gc掉,且一直在增长空间。
4.查看线程情况
ps -mp pid -o THREAD,tid,time或者top -Hp pid

发现27847这个线程已经存活了5天多的时间了,进去看下~
printf "%x\n" 27847 转成16进制 结果6cc7
jstack pid |grep 6cc7 -A 30 如果需要root权限则 su - root

发现这个线程一直在这段代码停留,这段代码的业务功能是将监控埋点的数据(metrics)report到influxdb,report过程中一直在往这个TreeMap中put数据。
二、JVM分析
本次用了JMC分析工具,对运行时JVM的情况进行分析,具体分析步骤如下:
1.用jmc工具导入自定义的jfc文件
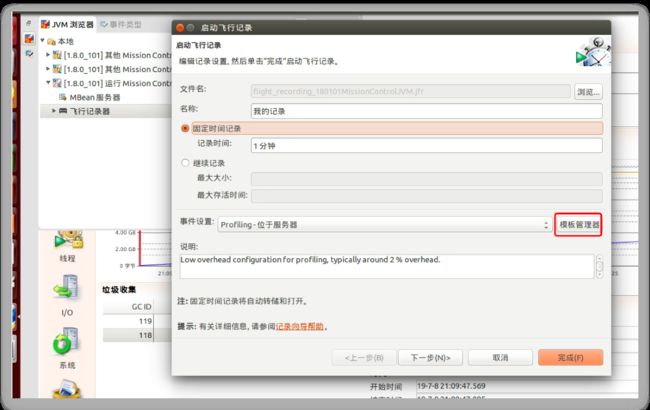
导入后进行编辑,勾选堆内存统计选项,然后重新导出文件
2.在需要分析的服务器上下载该jfc文件
3.进行信息采集:
jcmd $pid VM.unlock_commercial_features
jcmd $pid JFR.start name=myrec settings=tongdun delay=20s duration=2m filename=/tmp/$pid.jfr
其中,delay参数表示profile延迟启动时间,duration表示持续采集时间,这里设置为2分钟
settings表示使用哪种采集配置,这里用的就是第二步中放入的xxx.jfc配置,它默认有一个名为profile的配置,如果不想采集异常信息,也可以直接用它。
注意,采集数据生成后请执行下列命令移除这个采集
jcmd $pid JFR.stop name=myrec
4.文件写入完成后,打开jmc工具,直接打开该jfr文件,即可看到jvm的各种信息

5.查看内存情况:

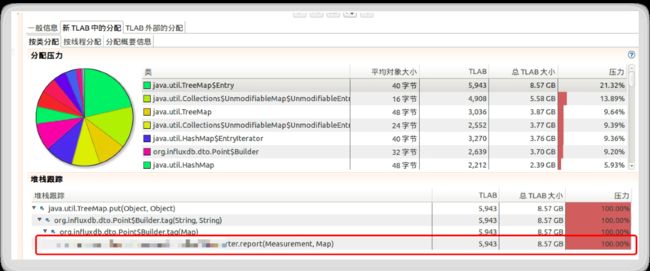

与在机器上通过异常线程查看到的情况一致
三、源码分析
分析该源码是使用公司的监控二方包进行监控数据埋点处的代码导致的异常,贴出部分代码。
//交易计数监控(成功率)
MetricsUtil.count(GateWayConstant.GATEWAY_COUNTER,
//次数是本次问题的罪魁祸首,流水号tag,每一次调用会生成一个流水号id
GateWayConstant.REQUEST_NUMBER,
StringUtil.defaultIfBlank(baseRequestResource.getRequestNumber(), GateWayConstant.BLANK_STRING),
GateWayConstant.EXTER_INTERFACE_ID,
externalInterface == null ? GateWayConstant.BLANK_STRING : externalInterface.getExterInterfaceId(),
GateWayConstant.EXTER_CHANNEL_ID,
externalInterface == null ? GateWayConstant.BLANK_STRING : externalInterface.getChannelId(),
MetricsUtil.RESULT, gwProcessFlag);
public static void count(String name, String... strs){
if(!formatParam(name, strs)){
return;
}
Measurement count = REGISTRY.getMeasurement(new MeasurementKey(name, strs));
List list = Arrays.asList(strs);
if(list.contains(RESULT)){
count.counter2(list.get(list.indexOf(RESULT)+1)).mark();
}
count.counter2(TOTAL).mark();
}
每次调用会new一个MeasurementKey对象,进去看看
public MeasurementKey(String name, String... tags) {
if (name == null || name.equals("")) {
logger.warn("measurement name is null or empty");
}
this.name = name;
this.tags = new HashMap<>();
for (int i = 0; i < tags.length / 2; i++) {
String tagName = tags[i * 2];
String tagValue = tags[i * 2 + 1];
if (tagName == null || tagName.equals("")) {
logger.warn(String.format("measurement: %s, tagName is null or empty", name));
}
if (tagValue == null || tagValue.equals("")) {
logger.warn(String.format("measurement: %s, tagName %s, tagValue is null or empty", name, tagName));
}
this.tags.put(tagName, tagValue);
}
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MeasurementKey key = (MeasurementKey) o;
return Objects.equal(getName(), key.getName()) && Objects.equal(getTags(), key.getTags());
}
@Override
public int hashCode() {
return Objects.hashCode(getName(), getTags());
}
如果是相同的tags,则生成的MeasurementKey将会是相同的,再看一下 REGISTRY.getMeasurement
private ConcurrentHashMap map = new ConcurrentHashMap<>();
public Measurement getMeasurement(final MeasurementKey key) {
Measurement measurement = map.get(key);
if (measurement == null) {
map.putIfAbsent(key, new Measurement(key));
measurement = map.get(key);
}
return measurement;
}
如果tag相同,则MeasurementKey相同,但由于监控中打了流水号tag,导致每一次的MeasurementKey都不一样,所以map会一直增长
再看一下上传influxdb的代码
public void init() {
if (!this.isEnable()) {
return;
}
this.executorService = new ScheduledThreadPoolExecutor(1);
executorService.scheduleAtFixedRate(new ReportTask(registry, reporters), reportIntervalMillis,
reportIntervalMillis, TimeUnit.MILLISECONDS);
}
注意这里用的scheduleAtFixedRate,周期性执行线程任务,本项目中设置的周期为5秒,但是如果5秒内没有执行完该任务,则队列中的任务会等待前一个任务完成后再继续执行,这也是为什么后面任务执行速度变慢后,线程一直没有被释放的原因,队列中一直有任务没有执行完。
再看一下线程任务代码:
@Override
public void run() {
try {
Collection measurements = registry.getMeasurements();
for (Measurement measurement : measurements) {
Map snapshot = measurement.snapshot();
for (Reporter reporter : reporters) {
try {
reporter.report(measurement, snapshot);
} catch (Throwable e) {
LOG.warn("reporter error:" + reporter.getClass().getName(), e);
}
}
measurement.clear();
}
} catch (Throwable t) {
LOG.error("report task error", t);
}
}
由于registry中的map会越来越大,所以获得的measuremets集合会越来越大,循环该集合进行report方法的,report会执行的越来越多,导致一个线程任务在5秒内执行不完,后续的任务就会堆积在队列中,也就造成了之前分析该线程的时候发现线程一直停留在report方法的原因。
四、总结
1.监控代码打点时使用不当,将流水号id作为tag,导致对象ConcurrentHashMap
2.该map对象每次上传完influxdb后没有清理整个对象,而是清理了Measurement中的fields对象,导致后续不停的需要循环该map进行上传。且上传的是空value数据。
3.修复方法,去掉监控打点处的流水号tag。