学习笔记 | Ch05 Pandas数据清洗 —— 缺失值、重复值、异常值
第5章 数据清洗与整理
- pandas数据清洗:学会常见的数据清洗方法。
- 数据合并:学会多源数据的合并和连接。
- 数据重塑:针对层次化索引,学会
stack和unstack的使用。 - 字符串处理:学会
DataFrame中字符串函数的使用。
5.1 数据清洗:处理缺失值、重复数据及如何替代值
5.1.1 处理缺失值
1. 侦查缺失值
- 通过
isnull和notnull方法,可以返回布尔值的对象。 - 这时通过求和可以获取每列的缺失值数量,再通过求和就可以获取整个
DataFrame的缺失值数量。
2. 删除缺失值
- 通过
dropna方法可以删除具有缺失值的行。传入how='all',则只会删除全为NaN的那些行。 - 如果需要删除列,则指定轴方向即可。

3. 填充缺失值
替换法

- 通过
fillna方法可以将缺失值替换为常数值。 - 在
fillna中传入字典结构数据,可以针对不同列填充不同的值,fillna返回的是新对象,不会对原数据进行修改,可通过inplace就地进行修改。 - 对重新索引中填充缺失值的方法同样适用于
fillna中。 - 对于
fillna的参数,可以通过“?”进行帮助查询。
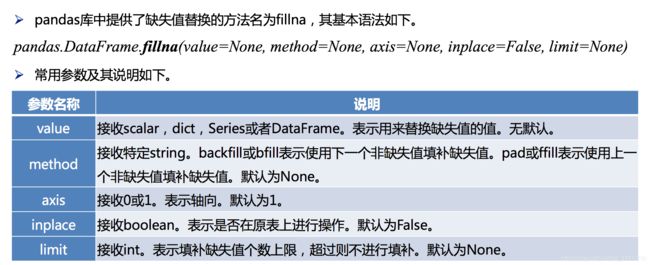


from pandas import Series,DataFrame
import pandas as pd
import numpy as np
df1 = DataFrame([[3,5,3],[1,6,np.nan],['lili',np.nan,'pop'],[np.nan,'a','b']])
df1
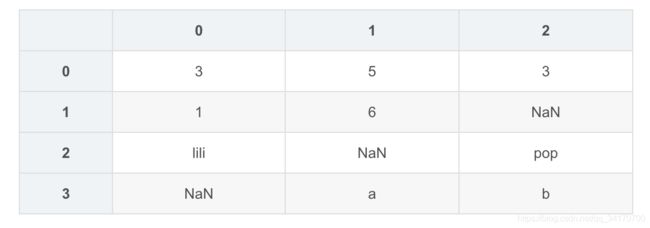
df1.isnull()
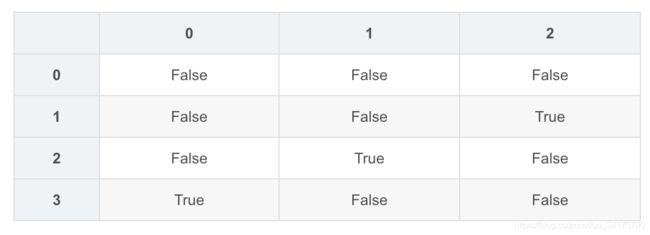
df1.notnull()
df1.isnull().sum()
0 1
1 1
2 1
dtype: int64
df1.isnull().sum().sum()
3
df1.info()
RangeIndex: 4 entries, 0 to 3
Data columns (total 3 columns):
0 3 non-null object
1 3 non-null object
2 3 non-null object
dtypes: object(3)
memory usage: 176.0+ bytes
df1.dropna()

df2 = DataFrame(np.arange(12).reshape(3,4))
df2
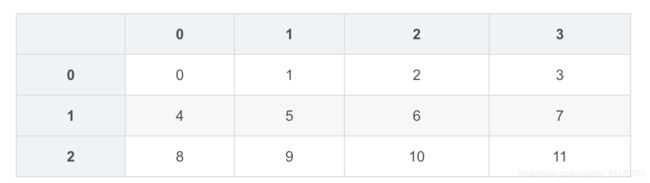
df2.ix[2,:]=np.nan
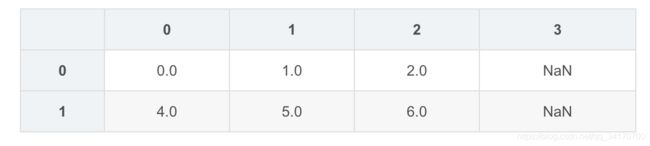
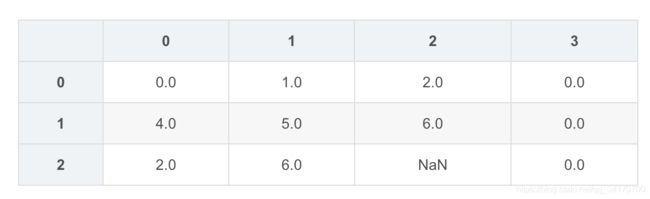
df2[3]=np.nan
df2

df2.dropna(how='all')
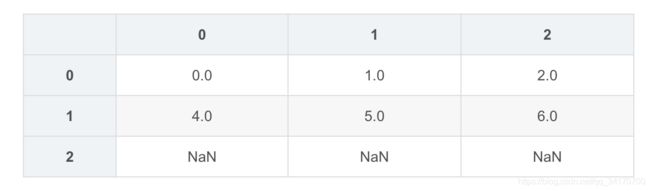
df2.dropna(how='all',axis=1)
df2
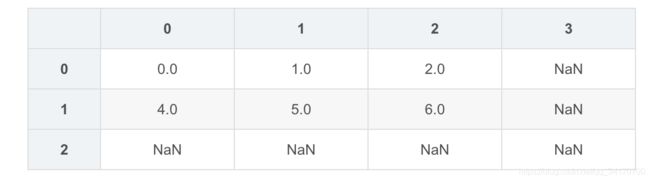
df2.fillna(0)

df2.fillna({1:6,3:0})

df2
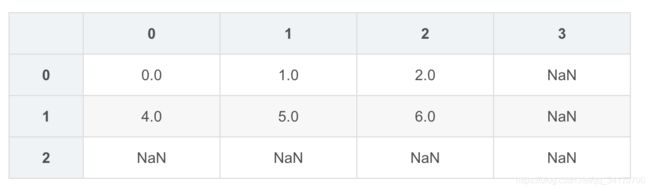
df2.fillna({1:6,3:0},inplace=True)
df2
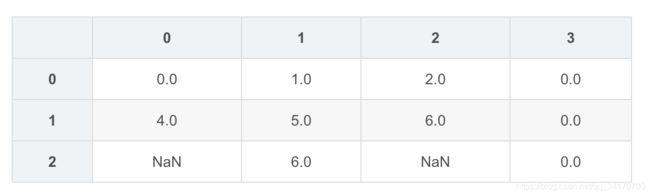
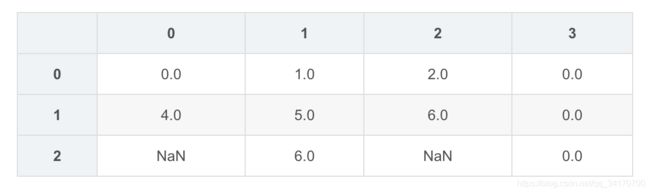
df2.fillna(method='ffill')
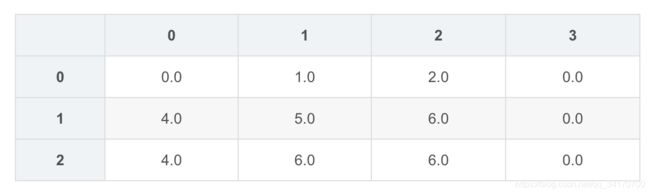
df2
df2[0]=df2[0].fillna(df2[0].mean())
df2
5.1.2 移除重复数据
- 在
DataFrame中,通过duplicated方法判断各行是否有重复数据。 - 通过
drop_duplicates方法,可以删除多余的重复项。在这种情况下,当每行的每个字段都相同时才会判断为重复项。

- 也可以通过指定部分列作为判断重复项的依据。
- 默认,保留的数据为第一个出现的组合。传入
keep='last'可以保留最后一个出现的组合。

5.1.3 替换值
- 替换值类似于
Excel中的替换功能,是对查询到的数据替换为相应的数据。在pandas中,通过pandas中,通过replace可完成替换值的功能。 - 也可以同时针对不同值进行多值替换,参数传入方式可以是列表也可以是字典格式。
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
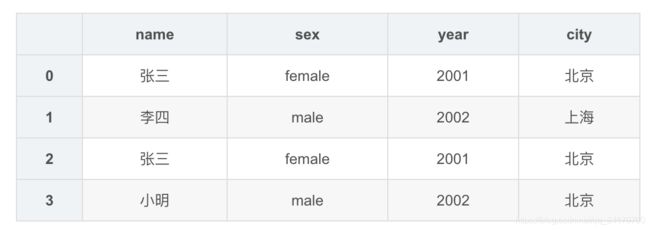
data = {
'name':['张三','李四','张三','小明'],
'sex':['female','male','female','male'],
'year':[2001,2002,2001,2002],
'city':['北京','上海','北京','北京']
}
df1 = DataFrame(data)
df1
df1.duplicated()
0 False
1 False
2 True
3 False
dtype: bool
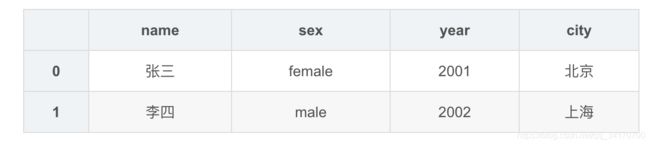
df1.drop_duplicates()
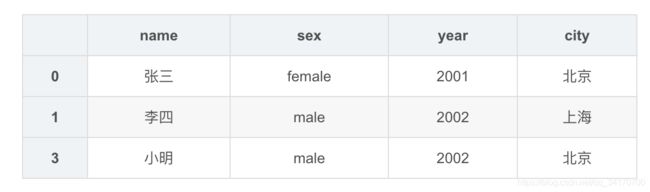
df1.drop_duplicates(['sex','year'])
df1
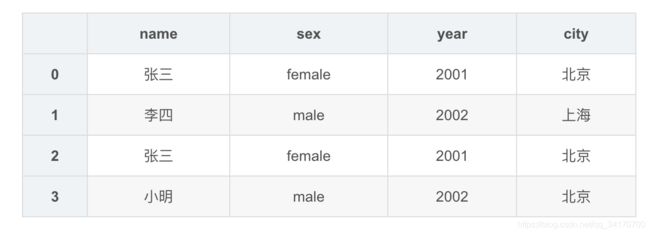
df1.drop_duplicates(['sex','year'],keep='last')

data = {
'name':['张三','李四','张三','小明'],
'sex':['female','male','','male'],
'year':[2001,2002,2001,2002],
'city':['北京','上海','','北京']
}
df1 = DataFrame(data)
df1
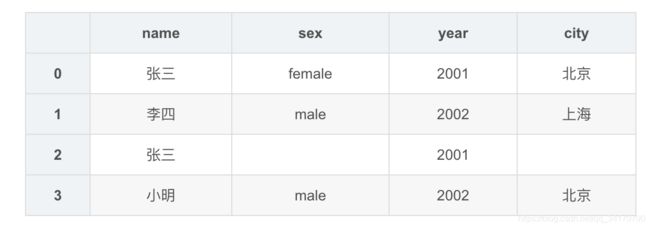
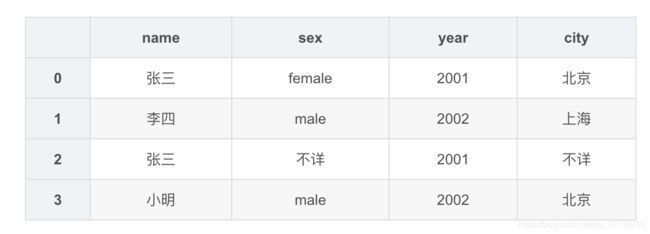
df1.replace('','不详')
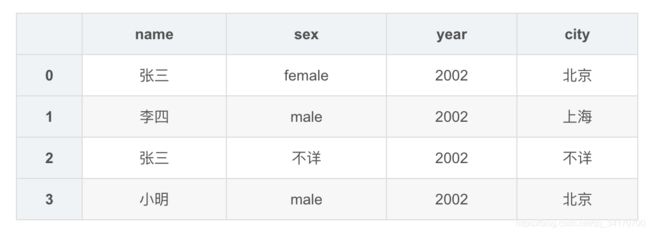
df1.replace(['',2001],['不详',2002])

df1.replace({'':'不详',2001:2002})
5.1.4 利用函数或映射进行数据转换
map方法- 注意:对于一列数据的转换,也可以通过
apply函数来实现。
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
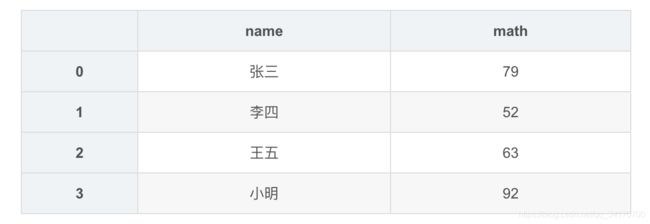
data = {
'name':['张三','李四','王五','小明'],
'math':[79,52,63,92]
}
df2 = DataFrame(data)
df2
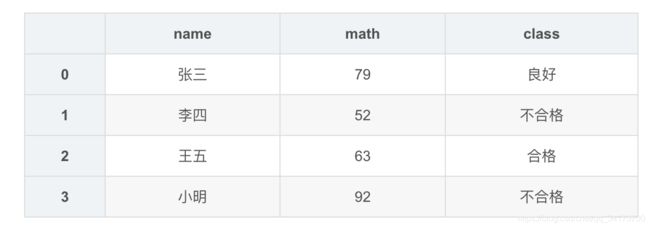
def f(x):
if x>=100:
return '优秀'
elif 70<=x<90:
return '良好'
elif 60<=x<70:
return '合格'
else:
return '不合格'
df2['class']=df2['math'].map(f)
df2
5.1.5 检测异常值



import pandas as pd
from pandas import Series,DataFrame
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
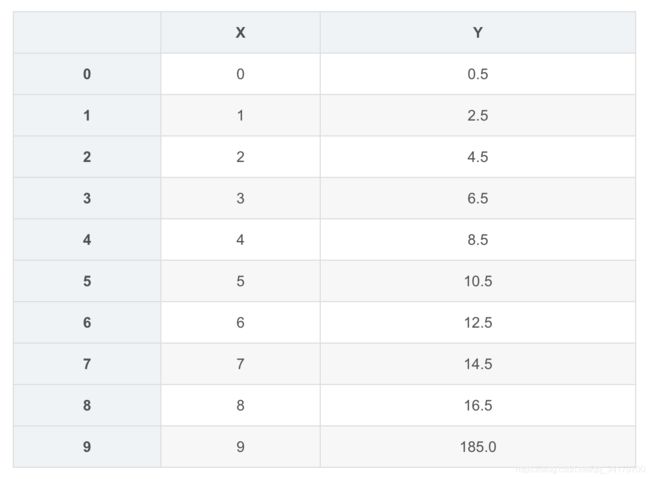
df3 = DataFrame(np.arange(10),columns=['X'])
df3['Y'] = 2*df3['X']+0.5
df3.iloc[9,1] = 185
df3
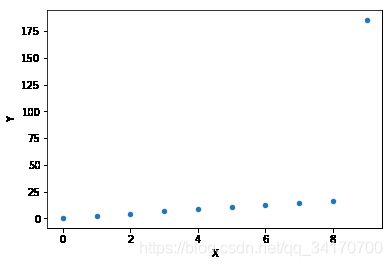
df3.plot(kind='scatter',x='X',y='Y')
5.1.6 虚拟变量
- 在数学建模和机器学习中,只有数值型数据才能供算法使用,对于一些分类变量则需要将其转换为虚拟变量,通过
get_dumnies函数可实现该功能。 - 对于多类别的数据而言,需要通过apply函数来实现。
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
df = DataFrame({
'朝向':['东','南','东','西','北'],
'价格':[1200,2100,2300,2900,1400]
})
df
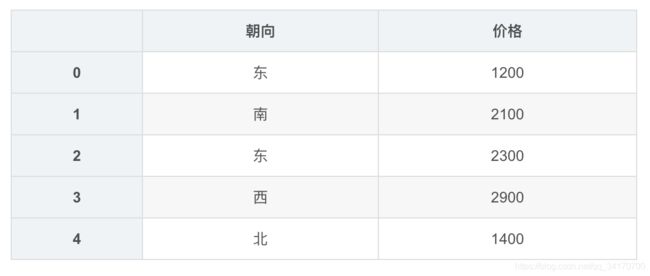
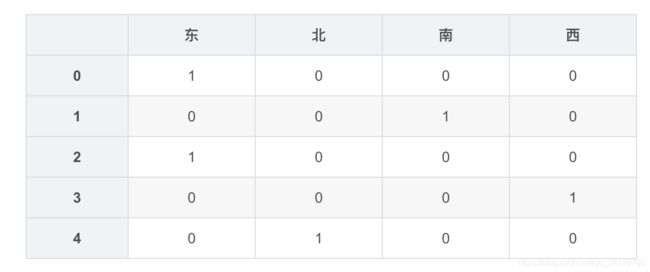
pd.get_dummies(df['朝向'])
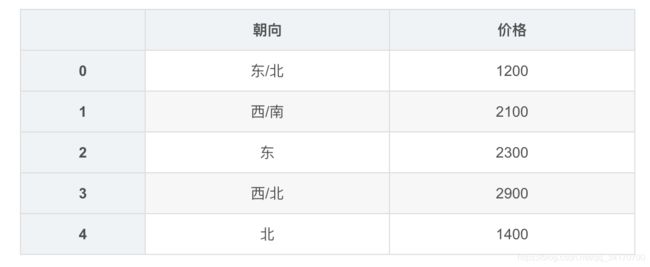
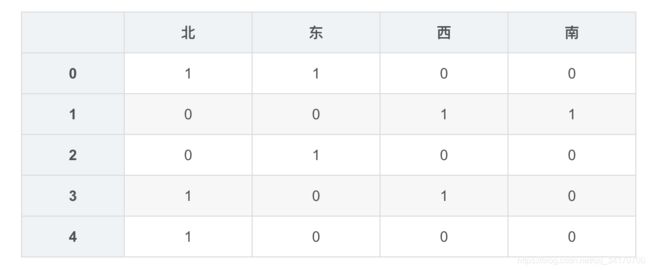
df2 = DataFrame({
'朝向':['东/北','西/南','东','西/北','北'],
'价格':[1200,2100,2300,2900,1400]
})
df2
dummies = df2['朝向'].apply(lambda x:Series(x.split('/')).value_counts())
dummies
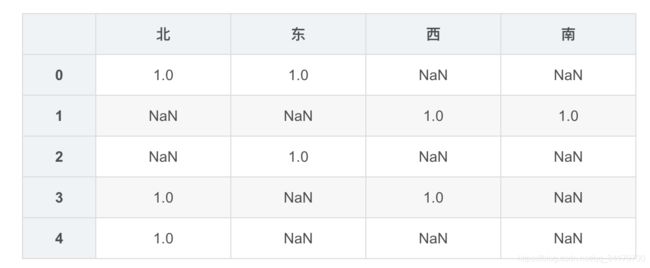
dummies = dummies.fillna(0).astype(int)
dummies
参考资料
- 《从零开始学python数据分析》