1.Mybatis 延迟加载策略
问题:在一对多中,当我们有一个用户,该用户有100个账户,
①在查询用户的时候,要不要把关联的账户查询出来?
②在查询账户的时候,要不要把关联的用户信息查询出来?
解决方案是:
①在查询用户的时候,用户下的账户信息应该是什么时候使用,什么时候查询。(延迟加载)
②在查询账户的时候,账户下的所属用户信息应该是随账户一起查询出来。(立即加载)
1.1什么为延迟加载:
延迟加载:就是在需要用到数据时才进行加载,不需要用到数据时就不加载数据。按需加载,延迟加载也称懒加载.
好处:先从单表查询,需要时再从关联表去关联查询,大大提高数据库性能,因为查询单表要比关联查询多张表速度要快。
缺点:因为只有当需要用到数据时,才会进行数据库查询,这样在大批量数据查询时,因为查询工作也要消耗
时间,所以可能造成用户等待时间变长,造成用户体验下降。
*注意:
一对一、多对一通常情况下采用立即加载
多对多、一对多通常情况下采用延迟加载
1.2用延迟加载实现需求:
需求:
查询账户(Account)信息并且关联查询用户(User)信息。如果先查询账户(Account)信息即可满足要求,当我们需要查询用户(User)信息时再查询用户(User)信息。把对用户(User)信息的按需去查询就是延迟加载。
mybatis第三天实现多表操作时,使用了resultMap来实现一对一,一对多,多对多关系的操作。主要是通过 association、collection 实现一对一及一对多映射。association、collection 具备延迟加载功能。
在全局的xml文件SqlMapConfig文件中配置:
①使用association完成延迟加载:
需求:
查询账户信息同时查询用户信息(在多对一即mybatis中的一对一的情况下完成延迟加载)。
IAccountDao接口中的方法:
public interface IAccountDao {
/*** 查询所有账户,同时获取账户的所属用户名称以及它的地址信息
* @return
*/
List
findAll( ); }
IAccoutDao.xml映射文件的配置:
select="com.itheima.dao.IUserDao.findById" column="uid">
select * from account
select : 填写我们要调用的 select 映射的 id,即在IUserDao接口中的findById的方法
column : 填写我们要传递给 select 映射的参数,传给findById方法的参数,在这里肯定为account表中的uid
IUserDao接口中的方法:
public interface IUserDao {
/**
* 根据 id 查询
* @param userId*
@return
*/
User findById(Integer id);
}
IUserDao.xml映射文件的配置:
select * from user where id = #{uid}
②使用collection完成延迟加载:
需求:
完成加载用户对象时,查询该用户所拥有的账户信息(在一对多的情况下完成延迟加载)。
IUserDao接口中的方法:
/**
*查询所有用户,同时获取出每个用户下的所有账户信息
* @return
*/
List
findAll( );
IUserDao.xml文件的配置:
select="com.itheima.dao.IAccountDao.findByUid" column="id">
select * from user
*注意:
主要用于加载关联的集合对象
select 属性 :
用于指定查询 account 列表的 sql 语句,所以填写的是该 sql 映射的 id
column 属性 :
用于指定 select 属性的 sql 语句的参数来源,上面的参数来自于 user 的 id 列,所以就写成 id 这一个字段名了
IAccountDao接口中的方法:
/**
* 根据用户 id 查询账户信息
* @param uid
* @return
*/
List
findByUid(Integer uid);
IAccountDao.xml配置文件:
select * from account where uid = #{uid}
2.Mybatis中的缓存机制
像大多数的持久化框架一样,Mybatis 也提供了缓存策略,通过缓存策略来减少数据库的查询次数,从而提
高性能。
Mybatis 中缓存分为一级缓存,二级缓存。
什么是缓存:存在于内存中的临时数据;
为什么使用缓存:减少和数据库交换的次数,提高执行效率;
适用于缓存的数据:经常查询的数据并且不经常改变,数据的正确与否对最终的结果影响不大的;
不适用于缓存的数据:经常改变的数据,数据的正确与否对最终的结果影响很大的;
2.1Mybatis中的一级缓存:
一级缓存是 SqlSession对象级别的缓存,只要 SqlSession对象没有 flush 或 close,它就存在。
原理:当我们执行查询之后,查询结果会存入到SqlSession对象为我们提供的一块区域中。该区域的结构是一个Map,当我们再次查询相同的数据时,mybatis会先去SqlSession中查询是否有,有的话直接拿出来使用。当SqlSession对象消失时,mybatis的一级缓存也就消失了。
一级缓存的分析:
一级缓存是 SqlSession 范围的缓存,当调用 SqlSession 的修改,添加,删除,commit( ),close( )等方法时,就会清空一级缓存。
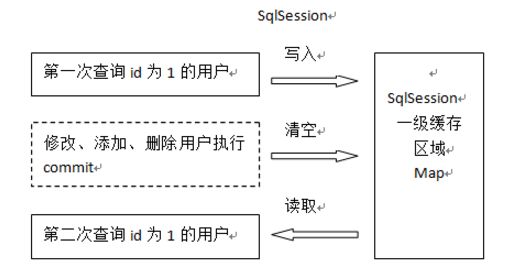
第一次发起查询用户 id 为 1 的用户信息,先去找缓存中是否有 id 为 1 的用户信息,如果没有,从数据库查
询用户信息。
得到用户信息,将用户信息存储到一级缓存中。
如果 sqlSession 去执行 commit 操作(执行插入、更新、删除),清空 SqlSession 中的一级缓存,这样
做的目的为了让缓存中存储的是最新的信息,避免脏读。
第二次发起查询用户 id 为 1 的用户信息,先去找缓存中是否有 id 为 1 的用户信息,缓存中有,直接从缓存
中获取用户信息。
2.2Mybatis中的二级缓存:
二级缓存:存放的内容是数据(JSON格式),而不是对象,会创建新对象,进行存改;
二级缓存是 mapper 映射级别的缓存,多个 SqlSession 去操作同一个 Mapper 映射的 sql 语句,多个SqlSession 可以共用二级缓存,二级缓存是跨 SqlSession 的。指的是mybatis中SqlSessionFactory对象的缓存。由同一个SqlSessionFactory对象创建的SqlSession共享其缓存。

首先开启 mybatis 的二级缓存。
sqlSession1 去查询用户信息,查询到用户信息会将查询数据存储到二级缓存中。
如果 SqlSession3 去执行相同 mapper 映射下 sql,执行 commit 提交,将会清空该 mapper 映射下的二级缓存区域的数据。
sqlSession2 去查询与 sqlSession1 相同的用户信息,首先会去缓存中找是否存在数据,如果存在直接从
缓存中取出数据。
使用步骤:
①让mybatis框架支持二级缓存,在全局配置文件中配置:
②让当前映射文件支持二级缓存,配置:
③让当前的操作支持二级缓存,在select标签中配置:
select * from user where id = #{uid}
将 UserDao.xml 映射文件中的
*注意:针对每次查询都需要最新的数据 sql,要设置成 useCache=false,禁用二级缓存。
二级缓存注意事项:当我们在使用二级缓存时,所缓存的类一定要实现 java.io.Serializable 接口,这种就可以使用序列化方式来保存对象。
3.Mybatis中的注解开发:
3.1 mybatis 的常用注解说明:
@Insert:实现新增
@Update:实现更新
@Delete:实现删除
@Select:实现查询
@Result:实现结果集封装
@Results:可以与@Result 一起使用,封装多个结果集
@ResultMap:实现引用@Results 定义的封装
@One:实现一对一结果集封装
@Many:实现一对多结果集封装
@SelectProvider: 实现动态 SQL 映射
@CacheNamespace:实现注解二级缓存的使用
注解开发测试使用的注意事项:
采用注解开发时,在全局配置文件中配置:
或者直接配置:
*注意:采用注解开发时,不能在同一个文件名称下dao进行xml开发,即使使用resource属性也不能。
如:dao接口在com.itheima.dao下,而对应接口的映射配置文件xml也在resources的com.itehima.dao目录下,此时就会报错,要么把xml移到别的目录,然后删除整个目录文件,要么直接删除文件和文件目录。
3.2使用注解实现复杂关系映射开发:
实现复杂关系映射之前我们可以在映射文件中通过配置
助@Results 注解,@Result 注解,@One 注解,@Many 注解。
复杂关系映射的注解说明:
@Results 注解 代替的是标签
@Resutl 注解 代替了
@Result 中 属性介绍:
id 是否是主键字段
column 数据库的列名
property 需要装配的属性名
one 需要使用的@One 注解(@Result(one=@One)()))
many 需要使用的@Many 注解(@Result(many=@many)()))
@one中的属性介绍:
@One 注解(一对一) 代替了
select 指定用来多表查询的 sqlmapper
fetchType 会覆盖全局的配置参数 FetchType.LAZY(延迟加载)或者FetchType.EAGER(立即加载)
例如:

*注意:
此时最后一个@Result注解中,column属性指定用来多表查询的sqlmapper的参数 ,
@Many 注解(多对一)
代替了
注意:聚集元素用来处理“一对多”的关系。需要指定映射的 Java 实体类的属性,属性的 javaType(一般为 ArrayList)但是注解中可以不定义;
例如:

3.3 mybatis 基于注解的二级缓存:
①.在全局配置文件SqlMapConfig.xml中配置开启二级缓存:
②. 在持久层接口中使用注解配置二级缓存:
@CacheNamespace(blocking=true)//mybatis 基于注解方式实现配置二级缓存
