❑ 任意两行都不具有相同的主键值;
❑ 每个行都必须具有一个主键值(主键列不允许NULL值)
在使用多列作为主键时,上述条件必须应用到构成主键的所有列,所有列值的组合必须是唯一的(但单个列的值可以不唯一)。
几乎所有重要的DBMS都支持SQL
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
建立索引会占用磁盘空间的索引文件。
MySQL Query Browser为一个图形交互客户机,用来编写和执行MySQL命令。
MySQL Administrator(MySQL管理器)是一个图形交互客户机,用来简化MySQL服务器的管理。http://dev.mysql.com/downloads/
必须先使用USE打开数据库,才能读取其中的数据。
SHOW DATABASES;返回可用数据库的一个列表。
SHOW TABLES;返回当前选择的数据库内可用表的列表。
show columns from auth_user;它对每个字段返回一行,行中包含字段名、数据类型、是否允许NULL、键信息、默认值以及其他信息
mysql> show columns from auth_user; = describe auth_user;
+--------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| password | varchar(128) | NO | | NULL | |
| last_login | datetime(6) | YES | | NULL | |
| is_superuser | tinyint(1) | NO | | NULL | |
| username | varchar(150) | NO | UNI | NULL | |
| first_name | varchar(30) | NO | | NULL | |
| last_name | varchar(150) | NO | | NULL | |
| email | varchar(254) | NO | | NULL | |
| is_staff | tinyint(1) | NO | | NULL | |
| is_active | tinyint(1) | NO | | NULL | |
| date_joined | datetime(6) | NO | | NULL | |
+--------------+--------------+------+-----+---------+----------------+
自动增量auto_increment: 某些表列需要唯一值。
如果需要它,则必须在用CREATE语句创建表时把它作为表定义的组成部分。
❑ SHOW STATUS,用于显示广泛的服务器状态信息;
| Innodb_buffer_pool_dump_status | Dumping of buffer pool not started |
| Innodb_buffer_pool_load_status | Buffer pool(s) load completed at 200923 8:09:34 |
| Innodb_buffer_pool_resize_status | |
| Innodb_buffer_pool_pages_data | 550 |
| Innodb_buffer_pool_bytes_data | 9011200 |
| Innodb_buffer_pool_pages_dirty | 0 |
| Innodb_buffer_pool_bytes_dirty | 0 |
| Innodb_buffer_pool_pages_flushed | 42 |
| Innodb_buffer_pool_pages_free | 7642 |
| Innodb_buffer_pool_pages_misc | 0 |
| Innodb_buffer_pool_pages_total | 8192 |
| Innodb_buffer_pool_read_ahead_rnd | 0 |
| Innodb_buffer_pool_read_ahead | 0 |
| Innodb_buffer_pool_read_ahead_evicted | 0 |
| Innodb_buffer_pool_read_requests | 18126 |
| Innodb_buffer_pool_reads | 516 |
| Innodb_buffer_pool_wait_free | 0 |
| Innodb_buffer_pool_write_requests | 365 |
| Innodb_data_fsyncs | 7 |
| Innodb_data_pending_fsyncs | 0 |
| Innodb_data_pending_reads | 0 |
| Innodb_data_pending_writes | 0 |
| Innodb_data_read | 8851968 |
| Innodb_data_reads | 705 |
| Innodb_data_writes | 59 |
| Innodb_data_written | 722944 |
| Innodb_dblwr_pages_written | 2 |
| Innodb_dblwr_writes | 1 |
| Innodb_log_waits | 0 |
| Innodb_log_write_requests | 0 |
❑ SHOW CREATE DATABASE和SHOW CREATE TABLE,分别用来显示创建特定数据库或表的MySQL语句;
❑ SHOW GRANTS,用来显示授予用户(所有用户或特定用户)的安全权限;
❑ SHOW ERRORS和SHOW WARNINGS,用来显示服务器错误或警告消息。
show variables like '%wait_timeout%';
使用set global slow_query_log=1开启了慢查询日志只对当前数据库生效,如果MySQL重启后则会失效。如果要永久生效,就必须修改配置文件my.cnf(其它系统变量也是如此)。
mysql> show variables like '%query_log%';
+------------------------------+--------------------------------------+
| Variable_name | Value |
+------------------------------+--------------------------------------+
| binlog_rows_query_log_events | OFF |
| slow_query_log | OFF |
| slow_query_log_file | /var/lib/mysql/9610e399939d-slow.log |
+------------------------------+--------------------------------------+
set global slow_query_log=1;
mysql> show variables like '%query_log%';
+------------------------------+--------------------------------------+
| Variable_name | Value |
+------------------------------+--------------------------------------+
| binlog_rows_query_log_events | OFF |
| slow_query_log | ON |
| slow_query_log_file | /var/lib/mysql/9610e399939d-slow.log |
+------------------------------+--------------------------------------+
- 检索数据
select id ,course_id,name from ss_c_lesson;展示字段
未排序数据 如果读者自己试验这个查询,可能会发现显示输出的数据顺序与这里的不同。出现这种情况很正常。如果没有明确排序查询结果(下一章介绍),则返回的数据的顺序没有特殊意义。返回数据的顺序可能是数据被添加到表中的顺序,也可能不是。只要返回相同数目的行,就是正常的。
SQL语句不区分大小写,在处理SQL语句时,其中所有空格都被忽略。
使用通配符 一般,除非你确实需要表中的每个列,否则最好别使用*通配符。虽然使用通配符可能会使你自己省事,不用明确列出所需列,但检索不需要的列通常会降低检索和应用程序的性能。
关键字指示MySQL只返回不同的值。,如果使用DISTINCT关键字,它必须直接放在列名的前面。select distinct delete_state from ss_c_lesson;
如果给出SELECT DISTINCT vend_id, prod_price,除非指定的两个列都不同,否则所有行都将被检索出来。
| 1 | 1851 |
| 1 | 1852 |
| 0 | 1853 |
| 1 | 1853 |
| 1 | 1854 |
| 0 | 1855 |
| 1 | 1855 |
| 1 | 1856 |
| 1 | 1857 |
| 1 | 1858 |
| 1 | 1859 |
| 1 | 1860 |
| 1 | 1861 |
| 1 | 1862 |
| 1 | 1863 |
| 1 | 1864 |
| 1 | 1865 |
| 1 | 1866 |
| 0 | 1867 |
| 1 | 1867 |
| 1 | 1868 |
| 1 | 1869 |
| 1 | 1870 |
| 1 | 1871 |
| 1 | 1872 |
| 1 | 1873 |
| 1 | 1874 |
mysql> select distinct delete_state from ss_c_lesson;
+--------------+
| delete_state |
+--------------+
| 1 |
| 0 |
+--------------+
LIMIT 5, 5指示MySQL返回从行5开始的5行。第一个数为开始位置,第二个数为要检索的行数。
行0 检索出来的第一行为行0而不是行1。因此,LIMIT 1, 1将检索出第二行而不是第一行。
在行数不够时 LIMIT中指定要检索的行数为检索的最大行数。
LIMIT 4 OFFSET 3意为从行3开始取4行,就像LIMIT 3, 4一样。
mysql> select distinct delete_state from ss_c_lesson;
+--------------+
| delete_state |
+--------------+
| 1 |
| 0 |
+--------------+
2 行于数据集 (0.05 秒)
mysql> select distinct delete_state from ss_c_lesson limit 1,1;
+--------------+
| delete_state |
+--------------+
| 0 |
+--------------+
1 行于数据集 (0.05 秒)
mysql> select distinct delete_state from ss_c_lesson limit 1,5;
+--------------+
| delete_state |
+--------------+
| 0 |
+--------------+
1 行于数据集 (0.05 秒)
mysql> select distinct delete_state from ss_c_lesson limit 5 offset 0;
+--------------+
| delete_state |
+--------------+
| 1 |
| 0 |
+--------------+
mysql> select distinct content_faculty.team_id from shuangshi.content_faculty;
+---------+
| team_id |
+---------+
| 1 |
| 2 |
+---------+
2 行于数据集 (0.03 秒)
- 排序检索数据
mysql> select half_size_pic_id from content_faculty order by half_size_pic_id;
+------------------+
| half_size_pic_id |
+------------------+
| 267 |
| 270 |
| 271 |
| 275 |
| 277 |
| 279 |
| 282 |
| 284 |
| 285 |
| 288 |
| 289 |
| 292 |
| 294 |
| 296 |
| 297 |
| 300 |
| 301 |
+------------------+
按多个列排序时,排序完全按所规定的顺序进行。换句话说,对于上述例子中的输出,仅在多个行具有相同的prod_price值时才对产品按prod_name进行排序。如果prod_price列中所有的值都是唯一的,则不会按prod_name排序。
与DESC相反的关键字是ASC(ASCENDING),在升序排序时可以指定它。但实际上,ASC没有多大用处,因为升序是默认的
为了进行降序排序,必须指定DESC关键字。
-
过滤数据:数据也可以在应用层过滤,服务器不得不通过网络发送多余的数据,这将导致网络带宽的浪费。
select name from usystem_user_info where sex = 0 order by user_id; where必须位于order by的前面select name from usystem_user_info where user_id < 19 order by name DESC;
!= 和 <>都是不等于 BETWEEN关键字
MySQL在执行匹配时默认不区分大小写,所以fuses与Fuses匹配。
如果将值与串类型的列进行比较,则需要限定引号。用来与数值列进行比较的值不用引号。
校验空值select name from usystem_user_info where institution_id is null;
SQL(像多数语言一样)在处理OR操作符前,优先处理AND操作符
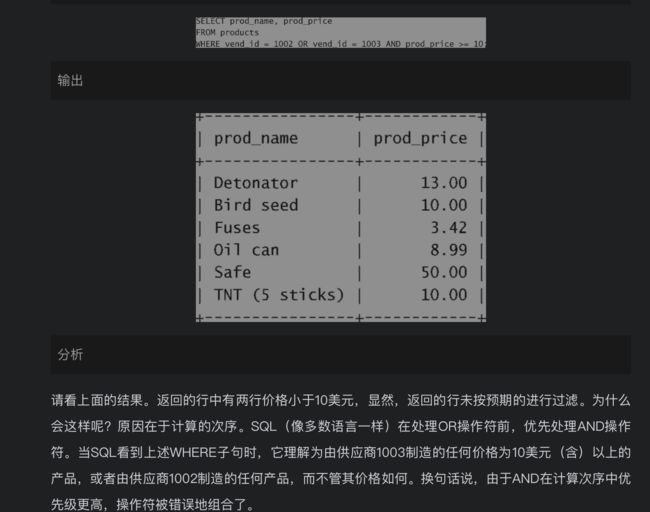 优先处理and
优先处理and
为什么要使用IN操作符?其优点具体如下。❑ 在使用长的合法选项清单时,IN操作符的语法更清楚且更直观。❑ 在使用IN时,计算的次序更容易管理(因为使用的操作符更少)。❑ IN操作符一般比OR操作符清单执行更快。❑ IN的最大优点是可以包含其他SELECT语句,使得能够更动态地建立WHERE子句。第14章将对此进行详细介绍。
WHERE子句中的NOT操作符有且只有一个功能,那就是否定它之后所跟的任何条件。
select * from food_subsidy where id not in (1002,1003) order by name; - 通配符过滤
区分大小写 根据MySQL的配置方式,搜索可以是区分大小写的。如果区分大小写,'jet%’与JetPack 1000将不匹配。
即使是WHEREprod_name LIKE '%’也不能匹配用值NULL作为产品名的行。
下划线的用途与%一样,但下划线只匹配单个字符而不是多个字符。与%能匹配0个字符不一样,_总是匹配一个字符,不能多也不能少,通配符搜索的处理一般要比前面讨论的其他搜索所花时间更长。
❑ 不要过度使用通配符。如果其他操作符能达到相同的目的,应该使用其他操作符。❑ 在确实需要使用通配符时,除非绝对有必要,否则不要把它们用在搜索模式的开始处。把通配符置于搜索模式的开始处,搜索起来是最慢的。❑ 仔细注意通配符的位置。如果放错地方,可能不会返回想要的数据。
select name from usystem_user_info where name REGEXP '蒙' ; 包含蒙的
like和REGEXP区别
mysql> select name from usystem_user_info where name REGEXP 'sakur' ;
+--------+
| name |
+--------+
| sakura |
| sakura |
+--------+
2 行于数据集 (0.02 秒)
mysql> select name from usystem_user_info where name like 'sakur' ;
空的数据集 (0.01 秒)
为区分大小写,可使用BINARY关键字,如WHERE prod_name REGEXPBINARY 'JetPack .000'。
两个以上的OR条件 可以给出两个以上的OR条件。例如,'1000 | 2000 | 3000’将匹配1000或2000或3000。
mysql> select name from usystem_user_info where name REGEXP 'sakur|蒙' ;
+-----------+
| name |
+-----------+
| 王蒙 |
| 李蒙 |
| 蒙彩结 |
| 王蒙 |
| 胡蒙 |
| sakura |
| sakura |
| 惠蒙蒙 |
+-----------+
8 行于数据集 (0.03 秒)
集合可用来定义要匹配的一个或多个字符。例如,下面的集合将匹配数字0到9:[0123456789]为简化这种类型的集合,可使用-来定义一个范围。下面的式子功能上等同于上述数字列表:[0-9]范围不限于完整的集合,[1-3]和[6-9]也是合法的范围。此外,范围不一定只是数值的,[a-z]匹配任意字母字符。
为了匹配特殊字符,必须用\为前导。\-表示查找-, \.表示查找.
\(sakura?[0-9]\) [[:digit:]]{3} ^[0-9\.]
LIKE和REGEXP的不同在于,LIKE匹配整个串而REGEXP匹配子串
- 创建计算字段
我们需要直接从数据库中检索出转换、计算或格式化过的数据;而不是检索出数据,然后再在客户机应用程序或报告程序中重新格式化。计算字段并不实际存在于数据库表中。计算字段是运行时在SELECT语句内创建的。
Concat()
mysql> select concat (name,'(',polyv_num,')') from usystem_user_info where id < 10 order by id;
+---------------------------------+
| concat (name,'(',polyv_num,')') |
+---------------------------------+
| 胡军() |
| 陈大千(557982) |
| 李明雪() |
| A组织员工() |
| B组织员工() |
| 唐博() |
| 邢华洋() |
| 张燕() |
+---------------------------------+
8 行于数据集 (0.01 秒)
Trim函数 MySQL除了支持RTrim()(正如刚才所见,它去掉串右边的空格),还支持LTrim()(去掉串左边的空格)以及Trim()(去掉串左右两边的空格)。
mysql> select concat (name,'(',Trim(polyv_num),')') from usystem_user_info where id < 10 order by id;
+---------------------------------------+
| concat (name,'(',Trim(polyv_num),')') |
+---------------------------------------+
| 胡军() |
| 陈大千(557982) |
| 李明雪() |
| A组织员工() |
| B组织员工() |
| 唐博() |
| 邢华洋() |
| 张燕() |
+---------------------------------------+
8 行于数据集 (0.01 秒)
AS
mysql> select concat (name,'(',Trim(polyv_num),')') as sakura from usystem_user_info where id < 10 order by id;
别名的其他用途 别名还有其他用途。常见的用途包括在实际的表列名包含不符合规定的字符(如空格)时重新命名它,在原来的名字含混或容易误解时扩充它,等等。
使用计算字段
mysql> select sakura from (select concat (name,'(',Trim(polyv_num),')') as sakura from usystem_user_info where id < 10 order by id)mm ;
+-------------------+
| sakura |
+-------------------+
| 胡军() |
| 陈大千(557982) |
| 李明雪() |
| A组织员工() |
| B组织员工() |
| 唐博() |
| 邢华洋() |
| 张燕() |
+-------------------+
8 行于数据集 (0.02 秒)
计算
mysql> select id,user_id*id as all_id from usystem_user_info where id<10;
+----+--------+
| id | all_id |
+----+--------+
| 2 | 4 |
| 3 | 9 |
| 4 | 16 |
| 5 | 25 |
| 6 | 30 |
| 7 | 42 |
| 8 | 56 |
| 9 | 72 |
+----+--------+
8 行于数据集 (0.07 秒)
时间
mysql> select NOW();
+---------------------+
| NOW() |
+---------------------+
| 2020-10-22 17:57:06 |
+---------------------+
1 行于数据集 (0.02 秒)
datetime这种类型存储日期及时间值,样例表中的值全都具有时间值00:00:00
select start_time,id,name from ss_c_lesson where Year(real_start_time)=2020 and month(real_start_time)=01;
- 汇总数据
只用于单个列 AVG()只能用来确定特定数值列的平均值,而且列名必须作为函数参数给出。为了获得多个列的平均值,必须使用多个AVG()函数。
计数
mysql> select count(*) from ss_c_lesson;
+----------+
| count(*) |
+----------+
| 48808 |
+----------+
1 行于数据集 (0.03 秒)
mysql> select count(real_start_time) from ss_c_lesson;
+------------------------+
| count(real_start_time) |
+------------------------+
| 20857 |
+------------------------+
1 行于数据集 (0.03 秒)
NULL值 如果指定列名,则指定列的值为空的行被COUNT()函数忽略,但如果COUNT()函数中用的是星号(*),则不忽略。
NULL值 AVG()函数忽略列值为NULL的行。
不重复行
mysql> select avg(distinct id) from ss_c_lesson;
+------------------+
| avg(distinct id) |
+------------------+
| 26770.8554 |
+------------------+
1 行于数据集 (0.06 秒)
聚集函数用来汇总数据。MySQL支持一系列聚集函数,可以用多种方法使用它们以返回所需的结果。这些函数是高效设计的,它们返回结果一般比你在自己的客户机应用程序中计算要快得多。
- 分组数据
mysql> select name, count(*) as num_prods from content_special_subject group by name;
+--------+-----------+
| name | num_prods |
+--------+-----------+
| | 1 |
| kkk | 1 |
| sakura | 4 |
+--------+-----------+
3 行于数据集 (0.08 秒)
GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。如果分组列中具有NULL值,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。
with rollup关键字会在所有记录的最后加上一条记录,该记录是上面所有记录的总和
mysql> select name,count(*) as ccount from content_special_subject group by name having count(*)>2;
+--------+--------+
| name | ccount |
+--------+--------+
| sakura | 4 |
+--------+--------+
1 行于数据集 (0.01 秒)
mysql> select name,count(*) as ccount from content_special_subject group by name having ccount>2;
+--------+--------+
| name | ccount |
+--------+--------+
| sakura | 4 |
+--------+--------+
1 行于数据集 (0.02 秒)
- 使用子查询
select name , course_id from ss_c_lesson where course_id in ( select id from ss_c_course where name like '%狄仁杰%');
SELECT name, course_id, ( select count(*) FROM ss_c_course WHERE ss_c_lesson.course_id = ss_c_course.id) AS sakura FROM ss_c_lesson;
子表里面查询需要table.name 始终需要from全所有引用到的表
使用子查询并不总是执行这种类型的数据检索的最有效的方法。更多的论述,请参阅第15章
- 联结表
外键为某个表中的一列,它包含另一个表的主键值,定义了两个表之间的关系。
完全限定列名 在引用的列可能出现二义性时,必须使用完全限定列名(用一个点分隔的表名和列名)。
mysql> select ss_c_lesson.name , count(*) from ss_c_lesson,ss_c_course where ss_c_lesson.course_id = ss_c_course.id;
+-----------+----------+
| name | count(*) |
+-----------+----------+
| 作文课 | 5354 |
+-----------+----------+
1 行于数据集 (0.13 秒)
mysql> select ss_c_lesson.name , count(*) from ss_c_lesson inner join ss_c_course on ss_c_lesson.course_id = ss_c_course.id;
+-----------+----------+
| name | count(*) |
+-----------+----------+
| 作文课 | 5354 |
+-----------+----------+
1 行于数据集 (0.05 秒)
交叉内联结果一致,联结的表越多,性能下降越厉害。
- 创建高级联结join
mysql> select p.id,name from content_special_subject_pic as p , content_special_subject_component as s where s.subject_id = p.subject_id;
+----+--------+
| id | name |
+----+--------+
| 1 | sdfds |
| 2 | sakura |
| 1 | sdfds |
| 2 | sakura |
+----+--------+
4 行于数据集 (0.17 秒)
mysql> select distinct p.id,name from content_special_subject_pic as p , content_special_subject_component as s where s.subject_id = p.subject_id;
+----+--------+
| id | name |
+----+--------+
| 1 | sdfds |
| 2 | sakura |
+----+--------+
2 行于数据集 (0.08 秒)
mysql> select name ,p.url from content_special_subject_pic as p left outer join content_special_subject_component as s on p.subject_id = s.subject_id;
+--------+-----+
| name | url |
+--------+-----+
| sdfds | ddd |
| sakura | |
| sdfds | ddd |
| sakura | |
| www | |
+--------+-----+
5 行于数据集 (0.02 秒)
mysql> select * from content_special_subject_pic as p , content_special_subject_component as s where s.subject_id = p.subject_id;
+----+--------+-----+--------+--------------+------------+-------+---------------+-------+------+---------------------------------------------+--------+-----------------+
| id | name | url | pic_id | delete_state | subject_id | id(2) | subject_id(2) | order | type | coordinate | url(2) | delete_state(2) |
+----+--------+-----+--------+--------------+------------+-------+---------------+-------+------+---------------------------------------------+--------+-----------------+
| 1 | sdfds | ddd | 193 | 0 | 2 | 2 | 2 | 0 | 2 | {"top":45,"left":80,"right":96,"below":87} | | 0 |
| 1 | sdfds | ddd | 193 | 0 | 2 | 3 | 2 | 0 | 2 | {"top":45,"left":80,"weight":96,"hight":87} | rrrr | 0 |
| 2 | sakura | | 194 | 0 | 2 | 2 | 2 | 0 | 2 | {"top":45,"left":80,"right":96,"below":87} | | 0 |
| 2 | sakura | | 194 | 0 | 2 | 3 | 2 | 0 | 2 | {"top":45,"left":80,"weight":96,"hight":87} | rrrr | 0 |
+----+--------+-----+--------+--------------+------------+-------+---------------+-------+------+---------------------------------------------+--------+-----------------+
4 行于数据集 (0.09 秒)
不确定是否重复数据还是语句有问题就select*全部打印出来
使用LEFT OUTER JOIN从FROM子句的左边表中选择所有行,外部联结的类型 存在两种基本的外部联结形式:左外部联结和右外部联结。它们之间的唯一差别是所关联的表的顺序不同。换句话说,左外部联结可通过颠倒FROM或WHERE子句中表的顺序转换为右外部联结。因此,两种类型的外部联结可互换使用,而究竟使用哪一种纯粹是根据方便而定。
- 联合查询union
UNION必须由两条或两条以上的SELECT语句组成,语句之间用关键字UNION分隔(因此,如果组合4条SELECT语句,将要使用3个UNION关键字)
union会去重 union all不会
mysql> select * from content_special_subject_pic group by subject_id UNION select * from content_special_subject_pic where subject_id = 2;
+----+--------+-----+--------+--------------+------------+
| id | name | url | pic_id | delete_state | subject_id |
+----+--------+-----+--------+--------------+------------+
| 1 | sdfds | ddd | 193 | 0 | 2 |
| 3 | www | | 0 | 0 | 30 |
| 2 | sakura | | 194 | 0 | 2 |
+----+--------+-----+--------+--------------+------------+
3 行于数据集 (0.12 秒)
mysql> select * from content_special_subject_pic group by subject_id UNION all select * from content_special_subject_pic where subject_id = 2;
+----+--------+-----+--------+--------------+------------+
| id | name | url | pic_id | delete_state | subject_id |
+----+--------+-----+--------+--------------+------------+
| 1 | sdfds | ddd | 193 | 0 | 2 |
| 3 | www | | 0 | 0 | 30 |
| 1 | sdfds | ddd | 193 | 0 | 2 |
| 2 | sakura | | 194 | 0 | 2 |
+----+--------+-----+--------+--------------+------------+
4 行于数据集 (0.11 秒)
-
全文本搜索
两个最常使用的引擎为MyISAM和InnoDB,前者支持全文本搜索,而后者不支持。PRI主键约束;UNI唯一约束;MUL可以重复。
两个行都包含词rabbit,但包含词rabbit作为第3个词的行的等级比作为第20个词的行高。这很重要。全文本搜索的一个重要部分就是对结果排序。具有较高等级的行先返回(因为这些行很可能是你真正想要的行)。
全文本搜索提供了简单LIKE搜索不能提供的功能。而且,由于数据是索引的,全文本搜索还相当快。
in boolean mode >>使用-ropes 不包含ropes
 boolean操作符
boolean操作符
仅在MyISAM数据库引擎中支持全文本搜索
mysql> create table sakuranew (
note_id int not null auto_increment,
prod_id char(10) not null ,
note_date datetime not null,
note_text text null,
primary key(note_id),
fulltext(note_text)
)engine=myisam;
Query OK, 0 rows affected (0.08 秒)
- 插入操作
省略的列必须满足以下某个条件。
❑ 该列定义为允许NULL值(无值或空值)
❑ 在表定义中给出默认值,这表示如果不给出值,将使用默认值。
如果数据检索是最重要的(通常是这样),则你可以通过在INSERT和INTO之间添加关键字LOW_PRIORITY,指示MySQL降低INSERT语句的优先级。
其中单条INSERT语句有多组值,每组值用一对圆括号括起来,用逗号分隔。
INSERT LOW_PRIORITY INTO sakuranew (note_id,prod_id,note_date,note_text) SELECT note_id,prod_id,note_date,note_text FROM sakura;
INSERT SELECT中SELECT语句可包含WHERE子句以过滤插入的数据。
- 更删操作
IGNORE关键字 如果用UPDATE语句更新多行,并且在更新这些行中的一行或多行时出现一个错误,则整个UPDATE操作被取消(错误发生前更新的所有行被恢复到它们原来的值)。即使是发生错误,也继续进行更新,可使用IGNORE关键字,如下所示:UPDATE IGNORE customers…
DELETE不需要列名或通配符。DELETE删除整行而不是删除列。为了删除指定的列,请使用UPDATE语句。 update set null
删除表的内容而不是表 DELETE语句从表中删除行,甚至是删除表中所有行。但是,DELETE不删除表本身。[插图]更快的删除 如果想从表中删除所有行,不要使用DELETE。可使用TRUNCATE TABLE语句,它完成相同的工作,但速度更快(TRUNCATE实际是删除原来的表并重新创建一个表,而不是逐行删除表中的数据)。DROP不保留表结构
如果省略了WHERE子句,则UPDATE或DELETE将被应用到表中所有的行。
where尽量使用主键 - 创建操纵表
如果你仅想在一个表不存在时创建它,应该在表名后给出IF NOT EXISTS。这样做不检查已有表的模式是否与你打算创建的表模式相匹配。它只是查看表名是否存在,并且仅在表名不存在时创建它。
允许NULL值的列不能作为唯一标识。表中的每个行必须具有唯一的主键值。如果主键使用单个列,则它的值必须唯一。如果使用多个列,则这些列的组合值必须唯一。
每个表只允许一个AUTO_INCREMENT列,而且它必须被索引(如,通过使它成为主键。你可以简单地在INSERT语句中指定一个值,只要它是唯一的(至今尚未使用过)即可,该值将被用来替代自动生成的值。后续的增量将开始使用该手工插入的值。
如何在使用AUTO_INCREMENT列时获得这个值呢?可使用last_insert_id()函数获得这个值,如下所示:SELECT_last_insert_id()
默认值用CREATE TABLE语句的列定义中的DEFAULT关键字指定。
但MySQL与其他DBMS不一样,它具有多种引擎。它打包多个引擎,这些引擎都隐藏在MySQL服务器内,全都能执行CREATE TABLE和SELECT等命令。
❑ InnoDB是一个可靠的事务处理引擎,它不支持全文本搜索;
❑ MEMORY在功能等同于MyISAM,但由于数据存储在内存(不是磁盘)中,速度很快(特别适合于临时表);
❑ MyISAM是一个性能极高的引擎,它支持全文本搜索,但不支持事务处理。
RENAME TABLE所做的仅是重命名一个表。
操作列 alter table sakura drop/add
constraint 外键名 foreign key 外键字段 references 主表名(关联字段)
保持数据一致性,完整性,主要目的是控制存储在外键表中的数据。 使两张表形成关联,外键只能引用外表中的列的值!建立外键的前提: 本表的列必须与外键类型相同(外键必须是外表主键)。事件触发限制: on delete和on update , 可设参数cascade(跟随外键改动), restrict(限制外表中的外键改动),set Null(设空值),set Default(设默认值),[默认]no action
创建含有外键的表:
create table temp(
id int,
name char(20),
foreign key(id) references outTable(id) on delete cascade on update cascade);
说明:把id列 设为MySQL外键 参照外表outTable的id列 当外键的值删除 本表中对应的列筛除 当外键的值改变 本表中对应的列值改变。
- 视图
在视图创建之后,可以用与表基本相同的方式利用它们。可以对视图执行SELECT操作,过滤和排序数据,将视图联结到其他视图或表,甚至能添加和更新数据(添加和更新数据存在某些限制。关于这个内容稍后还要做进一步的介绍)。重要的是知道视图仅仅是用来查看存储在别处的数据的一种设施。视图本身不包含数据,因此它们返回的数据是从其他表中检索出来的。在添加或更改这些表中的数据时,视图将返回改变过的数据。[插图]性能问题 因为视图不包含数据,所以每次使用视图时,都必须处理查询执行时所需的任一个检索。如果你用多个联结和过滤创建了复杂的视图或者嵌套了视图,可能会发现性能下降得很厉害。因此,在部署使用了大量视图的应用前,应该进行测试。
如果视图定义中有以下操作,则不能进行视图的更新:❑ 分组(使用GROUP BY和HAVING);❑ 联结;❑ 子查询;❑ 并;❑ 聚集函数(Min()、Count()、Sum()等);❑ DISTINCT;❑ 导出(计算)列。
CREATE VIEW sakuraview as SELECT note_text from sakura where note_id = 1;
mysql> select * from sakuraview;
+------------------------------------------+
| note_text |
+------------------------------------------+
| rabbit is a cute animal,do you think so? |
+------------------------------------------+
- 存储过程
提高性能。因为使用存储过程比使用单独的SQL语句要快;通过把处理封装在容易使用的单元中,简化复杂的操作;由于不要求反复建立一系列处理步骤,这保证了数据的完整性;如果表名、列名或业务逻辑(或别的内容)有变化,只需要更改存储过程的代码
DELIMITER //告诉命令行实用程序使用//作为新的语句结束分隔符,可以看到标志存储过程结束的END定义为END//而不是END;。这样,存储过程体内的;仍然保持不动,并且正确地传递给数据库引擎。最后,为恢复为原来的语句分隔符,可使用DELIMITER ;。除\符号外,任何字符都可以用作语句分隔符
mysql> CREATE PROCEDURE sakura()
BEGIN
SELECT max(note_id) as maxsakura
from sakura;
END;
Query OK, 0 rows affected (0.01 秒)
mysql> call sakura();
+-----------+
| maxsakura |
+-----------+
| 3 |
+-----------+
1 行于数据集 (0.01 秒)
Query OK, 0 rows affected (0.02 秒)
mysql> drop procedure sakura;
Query OK, 0 rows affected (0.09 秒)
这条语句删除刚创建的存储过程。请注意没有使用后面的(),只给出存储过程名
decimal(8,2) 整数和小数加起来一共8位,保留两位小数
存储过程的结束标点一定要修改
delimiter ??
CREATE PROCEDURE sakura(
OUT pl DECIMAL(8,2),
OUT pa DECIMAL(8,1),
OUT ph DECIMAL(8,3))
BEGIN
SELECT MIN(note_id) INTO pl FROM sakura;
SELECT MAX(note_id) INTO pa FROM sakura;
SELECT AVG(note_id) INTO ph FROM sakura;
END??
delimiter ;
所有MySQL变量都必须以@开始
mysql> select @pa;
+------+
| @pa |
+------+
| 3.0 |
+------+
1 行于数据集 (0.01 秒)
mysql> select @pa1;
+------+
| @pa1 |
+------+
| NULL |
+------+
1 行于数据集 (0.02 秒)
mysql> CALL sakura234(@pl1,@pa1,@ph1);
Query OK, 1 rows affected (0.01 秒)
mysql> select @pa1;
+------+
| @pa1 |
+------+
| 3.0 |
+------+
1 行于数据集 (0.02 秒)
调用call之后才能使用变量
传入值到存储过程
delimiter ??
CREATE PROCEDURE sakura(
IN pronum CHAR,
OUT ototal DECIMAL(8,2))
BEGIN
SELECT SUM(note_id*note_id) FROM sakura WHERE prod_id = pronum INTO ototal;
END??
delimiter ;
mysql> call sakura(33,@total123);
Query OK, 1 rows affected (0.02 秒)
mysql> select @total1123;
触发器仅create update delete 只支持表不支持view或临时表 一个表最多六个触发器
- 事务
事务(transaction)指一组SQL语句;
❑ 回退(rollback)指撤销指定SQL语句的过程;
❑ 提交(commit)指将未存储的SQL语句结果写入数据库表;
❑ 保留点(savepoint)指事务处理中设置的临时占位符(place-holder),你可以对它发布回退(与回退整个事务处理不同)。事务处理(transaction processing)可以用来维护数据库的完整性,它保证成批的MySQL操作要么完全执行,要么完全不执行。ROLLBACK和COMMIT
START TRANSACTION;ROLLBACK
事务处理用来管理INSERT、UPDATE和DELETE语句。你不能回退SELECT语句。(这样做也没有什么意义。)你不能回退CREATE或DROP操作。事务处理块中可以使用这两条语句,但如果你执行回退,它们不会被撤销。
一般的MySQL语句都是直接针对数据库表执行和编写的。这就是所谓的隐含提交(implicit commit),即提交(写或保存)操作是自动进行的。
但是,在事务处理块中,提交不会隐含地进行。为进行明确的提交,使用COMMIT语句 - 安全
不应该在日常的MySQL操作中使用root
在创建用户账号后,必须接着分配访问权限。新创建的用户账号没有访问权限。它们能登录MySQL,但不能看到数据,不能执行任何数据库操作
grant/revoke select on ss_c_lesson.* from sakura;
show grants for sakura;
set password = password('n3w 'P@$$w0rd")
19. 维护
❑ 使用命令行实用程序mysqldump转储所有数据库内容到某个外部文件。在进行常规备份前这个实用程序应该正常运行,以便能正确地备份转储文件。❑ 可用命令行实用程序mysqlhotcopy从一个数据库复制所有数据(并非所有数据库引擎都支持这个实用程序)。❑ 可以使用MySQL的BACKUP TABLE或SELECT INTO OUTFILE转储所有数据到某个外部文件。这两条语句都接受将要创建的系统文件名,此系统文件必须不存在,否则会出错。数据可以用RESTORE TABLE来复原。首先刷新未写数据 为了保证所有数据被写到磁盘(包括索引数据),可能需要在进行备份前使用FLUSH TABLES语句。
检查表键是否正常
mysql> analyze table ss_c_lesson;
+-----------------------+---------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+-----------------------+---------+----------+----------+
| shuangshi.ss_c_lesson | analyze | status | OK |
+-----------------------+---------+----------+----------+
如果从一个表中删除大量数据,应该使用OPTIMIZE TABLE来收回所用的空间,从而优化表的性能。
20.性能
硬件/专用服务器/一段时间需要调整内存分配、缓冲区大小等/它经常同时执行多个任务。如果这些任务中的某一个执行缓慢,则所有请求都会执行缓慢。如果你遇到显著的性能不良,可使用SHOWPROCESSLIST显示所有活动进程(以及它们的线程ID和执行时间)/ select编写方式/ explain解释如何运行select/存储过程执行得比一条一条地执行其中的各条MySQL语句快/总是使用正确的数据类型/不使用select*/最好是使用FULLTEXT而不是LIKE/索引可根据需要添加和删除/你的SELECT语句中有一系列复杂的OR条件吗?通过使用多条SELECT语句和连接它们的UNION语句,你能看到极大的性能改进/在导入数据时,应该关闭自动提交/有的操作(包括INSERT)支持一个可选的DELAYED关键字,如果使用它,将把控制立即返回给调用程序,并且一旦有可能就实际执行该操作
mysql> explain select user from user;
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | user | index | NULL | PRIMARY | 228 | NULL | 8 | Using index |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
1 行于数据集 (0.04 秒)
21. 数据类型
串数据类型:CHAR属于定长串类型/TEXT属于变长串类型(MySQL处理定长列远比处理变长列快得多。此外,MySQL不允许对变长列(或一个列的可变部分)进行索引。这也会极大地影响性能。)

数值数据类型:有数值数据类型(除BIT和BOOLEAN外)都可以有符号或无符号;但如果你知道自己不需要存储负值,可以使用UNSIGNED关键字,这样做将允许你存储两倍大小的值。存储货币数据类型 MySQL中没有专门存储货币的数据类型,一般情况下使用DECIMAL(8, 2)。

日期类型:

二进制类型:

查看表大小
use information_schema;
select concat(round(sum(DATA_LENGTH/1024/1024),2),'MB') as data from TABLES where table_schema='tengyue_shuangshi';
select concat(round(sum(DATA_LENGTH/1024/1024),2),'MB') as data from TABLES;
查看连接数
mysql> show status like 'Threads%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_cached | 12 |
| Threads_connected | 15 |
| Threads_created | 51696 |
| Threads_running | 1 |
+-------------------+-------+
mysql> show variables like '%max_connections%';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 1000 |
+-----------------+-------+
1 行于数据集 (0.03 秒)
mysql> show global status like '%max_used_connections%';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| Max_used_connections | 1001 |
+----------------------+-------+
1 行于数据集 (0.31 秒)
+1为管理员账号