SeriesFile 解析
SeriesFile是什么
- SeriesFile其实叫
SeriesKeyFile比较合适,里面存储了当前DB下的所有series key; - 其中的series key = (measurement + tag set)
SeriesFile的持久化
- 它对应于磁盘上的若干文件, 每个database都有自己的一组SeriesFile, 其目录为: [influxdb data path]/[database]/_series
- 我们来看下_series目录下的结构:
./_series/
├── 00
│ └── 0000
├── 01
│ └── 0000
├── 02
│ └── 0000
├── 03
│ └── 0000
├── 04
│ └── 0000
├── 05
│ └── 0000
├── 06
│ └── 0000
└── 07
└── 0000
-
每个DB下面的series文件分成至多8个partition, 每个partition下又分成多个Segment, 每个partition又对应一个内存索引
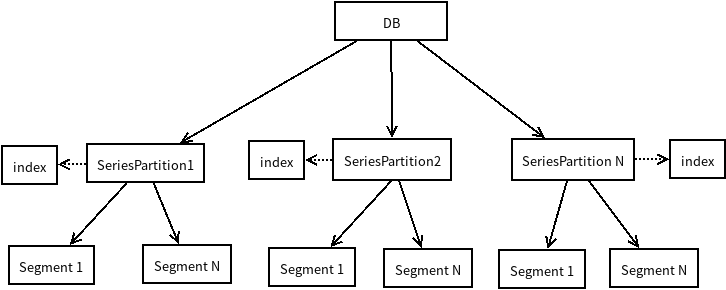 influxdb_series_file.png
influxdb_series_file.png
SeriesSegment
- 定义: 由seriese entries的log会组成磁盘文件, 这个类就负责读写这个磁盘文件
type SeriesSegment struct {
id uint16
path string
data []byte // mmap file
file *os.File // write file handle
w *bufio.Writer // bufferred file handle
size uint32 // current file size
}
-
SeriesSegment磁盘文件格式:
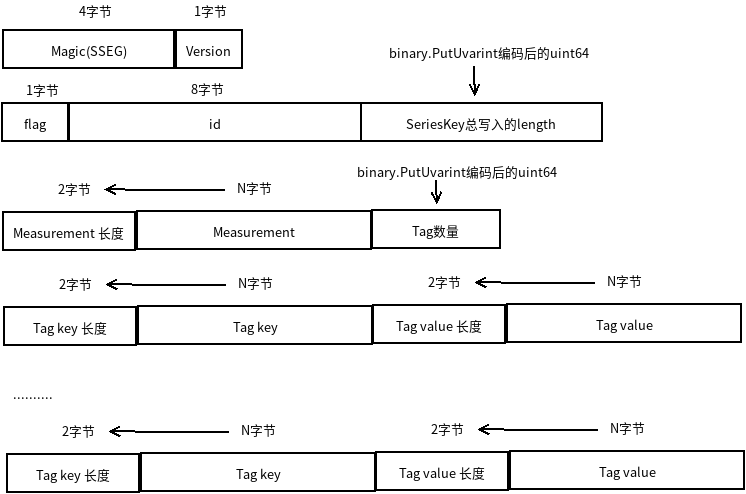 influxdb_series_file_format.png
influxdb_series_file_format.png
其中的flag有两个可能的值:
SeriesEntryInsertFlag:表示当前写入的SeriesKey是有效的;
SeriesEntryTombstoneFlag:墓碑标识。
- 创建SeriesSegment:
CreateSeriesSegment
func CreateSeriesSegment(id uint16, path string) (*SeriesSegment, error) {
// 先创建 .initializing结尾的临时文件
f, err := os.Create(path + ".initializing")
if err != nil {
return nil, err
}
defer f.Close()
// 先头部,包括Magic, Version
hdr := NewSeriesSegmentHeader()
if _, err := hdr.WriteTo(f); err != nil {
return nil, err
// 一个Segment文件需要预分配文件大小 ,最小4M, 最大256M
} else if err := f.Truncate(int64(SeriesSegmentSize(id))); err != nil {
return nil, err
} else if err := f.Close(); err != nil {
return nil, err
}
// Swap with target path.
if err := os.Rename(f.Name(), path); err != nil {
return nil, err
}
// Open segment at new location.
segment := NewSeriesSegment(id, path)
// 打开当前的Segment, 我们在下面单独介绍
if err := segment.Open(); err != nil {
return nil, err
}
return segment, nil
}
- 打开一个SeriesSegment, 使用内存映射读到内存:
Open
func (s *SeriesSegment) Open() error {
if err := func() (err error) {
// 内存映射读到内存中
if s.data, err = mmap.Map(s.path, int64(SeriesSegmentSize(s.id))); err != nil {
return err
}
// 读头部并且校验Version
hdr, err := ReadSeriesSegmentHeader(s.data)
if err != nil {
return err
} else if hdr.Version != SeriesSegmentVersion {
return ErrInvalidSeriesSegmentVersion
}
return nil
}(); err != nil {
s.Close()
return err
}
return nil
}
- 初始化写操作
InitForWrite:从头开始读取当前segment, 计算读到结尾时的size,在读的过程中作简单有效性校验,然后打开文件,文件写入的游标定位在文件结尾
func (s *SeriesSegment) InitForWrite() (err error) {
// Only calculcate segment data size if writing.
for s.size = uint32(SeriesSegmentHeaderSize); s.size < uint32(len(s.data)); {
flag, _, _, sz := ReadSeriesEntry(s.data[s.size:])
if !IsValidSeriesEntryFlag(flag) {
break
}
s.size += uint32(sz)
}
// Open file handler for writing & seek to end of data.
if s.file, err = os.OpenFile(s.path, os.O_WRONLY|os.O_CREATE, 0666); err != nil {
return err
} else if _, err := s.file.Seek(int64(s.size), io.SeekStart); err != nil {
return err
}
s.w = bufio.NewWriterSize(s.file, 32*1024)
return nil
}
- 写入log entry到segment文件
WriteLogEntry:
func (s *SeriesSegment) WriteLogEntry(data []byte) (offset int64, err error) {
if !s.CanWrite(data) {
return 0, ErrSeriesSegmentNotWritable
}
offset = JoinSeriesOffset(s.id, s.size)
if _, err := s.w.Write(data); err != nil {
return 0, err
}
s.size += uint32(len(data))
return offset, nil
}
这个方法返回的offset非常有用,它由segment id和 segment size组成:
func JoinSeriesOffset(segmentID uint16, pos uint32) int64 {
return (int64(segmentID) << 32) | int64(pos)
}
通过segment id可以知道写入了哪个segment文件,通过segment size可知道写了segment文件的什么位置
- Segment文件遍历操作
ForEachEntry:遍历读取每一条SeriesEntry, 然后回调传入的函数
func (s *SeriesSegment) ForEachEntry(fn func(flag uint8, id uint64, offset int64, key []byte) error) error {
for pos := uint32(SeriesSegmentHeaderSize); pos < uint32(len(s.data)); {
flag, id, key, sz := ReadSeriesEntry(s.data[pos:])
if !IsValidSeriesEntryFlag(flag) {
break
}
offset := JoinSeriesOffset(s.id, pos)
if err := fn(flag, id, offset, key); err != nil {
return err
}
pos += uint32(sz)
}
return nil
}
- 根据offset读取SeriesKey
ReadSeriesKeyFromSegments
func ReadSeriesKeyFromSegments(a []*SeriesSegment, offset int64) []byte {
// 从offset中分离出sigment id 和 pos
segmentID, pos := SplitSeriesOffset(offset)
segment := FindSegment(a, segmentID)
if segment == nil {
return nil
}
buf := segment.Slice(pos)
key, _ := ReadSeriesKey(buf)
return key
}
- 读取SeriesKey
ReadSeriesEntry, 按照Segment的format按字节读取flag, id, key
func ReadSeriesEntry(data []byte) (flag uint8, id uint64, key []byte, sz int64) {
// If flag byte is zero then no more entries exist.
flag, data = uint8(data[0]), data[1:]
if !IsValidSeriesEntryFlag(flag) {
return 0, 0, nil, 1
}
id, data = binary.BigEndian.Uint64(data), data[8:]
switch flag {
case SeriesEntryInsertFlag:
key, _ = ReadSeriesKey(data)
}
return flag, id, key, int64(SeriesEntryHeaderSize + len(key))
}
SeriesIndex
- 定义: SeriesIndex是对Partition下所有Segment file的内存索引,最主要的就是series key到 series id的map和series id到offset的map;
在内存中的Index数量超过阈值时,会在调用CreateSeriesListIfNoExists时被compact到磁盘文件;SeriesIndex对象在被初始化时会从磁盘文件中读取index, 在磁盘文件中的存储是按hash方式来定位写入的,使用的是mmap的方式;查找索引时先从内存查找才从磁盘文件查找
type SeriesIndex struct {
path string
count uint64
capacity int64
mask int64
maxSeriesID uint64
maxOffset int64
//以下这三项用来mmap磁盘index到内存
data []byte // mmap data
keyIDData []byte // key/id mmap data
idOffsetData []byte // id/offset mmap data
// In-memory data since rebuild.
keyIDMap *rhh.HashMap //series key到 series id的map
idOffsetMap map[uint64]int64 //series id到offset的map
tombstones map[uint64]struct{}
}
- 我们来看一下磁盘index的结构
- 先是Header:
SeriesIndexHeaderSize = 0 +
4 + 1 + // magic + version
8 + 8 + // max series + max offset
8 + 8 + // count + capacity
8 + 8 + // key/id map offset & size
8 + 8 + // id/offset map offset & size
- 具体的内容部分就是两个map(两个hash map), serieskey -> seriesid和 seriesid -> seriesoffset, 它们在文件中的起始位置和大小在header里都可以读到;
- 针对serieskey -> seriesid这个hash map, 存入时的key是series key, value是offset和id
- 针对seriesid -> seriesoffset这个hash map, 存入时的key是series id, value是id和offset
-
Open操作
func (idx *SeriesIndex) Open() (err error) {
// Map data file, if it exists.
if err := func() error {
if _, err := os.Stat(idx.path); err != nil && !os.IsNotExist(err) {
return err
} else if err == nil {
//将index磁盘文件内存映射到idx.data
if idx.data, err = mmap.Map(idx.path, 0); err != nil {
return err
}
// 读文件构造header
hdr, err := ReadSeriesIndexHeader(idx.data)
if err != nil {
return err
}
idx.count, idx.capacity, idx.mask = hdr.Count, hdr.Capacity, hdr.Capacity-1
idx.maxSeriesID, idx.maxOffset = hdr.MaxSeriesID, hdr.MaxOffset
// 通过header信息构造两个map的byte slice
idx.keyIDData = idx.data[hdr.KeyIDMap.Offset : hdr.KeyIDMap.Offset+hdr.KeyIDMap.Size]
idx.idOffsetData = idx.data[hdr.IDOffsetMap.Offset : hdr.IDOffsetMap.Offset+hdr.IDOffsetMap.Size]
}
return nil
}(); err != nil {
idx.Close()
return err
}
idx.keyIDMap = rhh.NewHashMap(rhh.DefaultOptions)
idx.idOffsetMap = make(map[uint64]int64)
idx.tombstones = make(map[uint64]struct{})
return nil
}
- 在内存中构建索引
Recover
func (idx *SeriesIndex) Recover(segments []*SeriesSegment) error {
// Allocate new in-memory maps.
idx.keyIDMap = rhh.NewHashMap(rhh.DefaultOptions)
idx.idOffsetMap = make(map[uint64]int64)
idx.tombstones = make(map[uint64]struct{})
// Process all entries since the maximum offset in the on-disk index.
minSegmentID, _ := SplitSeriesOffset(idx.maxOffset)
//遍历每一个Segment
for _, segment := range segments {
if segment.ID() < minSegmentID {
continue
}
//遍历Segment中的每一个SeriesEntry
if err := segment.ForEachEntry(func(flag uint8, id uint64, offset int64, key []byte) error {
if offset <= idx.maxOffset {
return nil
}
// 每个SeriesEntry都用idx.execEntry处理
idx.execEntry(flag, id, offset, key)
return nil
}); err != nil {
return err
}
}
return nil
}
- 操作一个Entry
func (idx *SeriesIndex) execEntry(flag uint8, id uint64, offset int64, key []byte) {
switch flag {
// 更新两个map
case SeriesEntryInsertFlag:
idx.keyIDMap.Put(key, id)
idx.idOffsetMap[id] = offset
if id > idx.maxSeriesID {
idx.maxSeriesID = id
}
if offset > idx.maxOffset {
idx.maxOffset = offset
}
case SeriesEntryTombstoneFlag:
idx.tombstones[id] = struct{}{}
default:
panic("unreachable")
}
}
- 各种查找方法, 先查内存中map, 再查从磁盘文件mmap后构建的map
func (idx *SeriesIndex) FindIDBySeriesKey(segments []*SeriesSegment, key []byte) uint64
func (idx *SeriesIndex) FindIDByNameTags(segments []*SeriesSegment, name []byte, tags models.Tags, buf []byte) uint64
func (idx *SeriesIndex) FindIDListByNameTags(segments []*SeriesSegment, names [][]byte, tagsSlice []models.Tags, buf []byte) (ids []uint64, ok bool)
func (idx *SeriesIndex) FindOffsetByID(id uint64) int64
SeriesPartition
- 管理旗下所有的SeriesPartition
-
Open方法:遍历目录下所有的segment file, 针对最新的一个segment作写入的初始化,构建内存index
func (p *SeriesPartition) Open() error {
// Create path if it doesn't exist.
if err := os.MkdirAll(filepath.Join(p.path), 0777); err != nil {
return err
}
// Open components.
if err := func() (err error) {
// 遍历所有的segment
if err := p.openSegments(); err != nil {
return err
}
// Init last segment for writes.
if err := p.activeSegment().InitForWrite(); err != nil {
return err
}
// 构建内存索引
p.index = NewSeriesIndex(p.IndexPath())
if err := p.index.Open(); err != nil {
return err
} else if p.index.Recover(p.segments); err != nil {
return err
}
return nil
}(); err != nil {
p.Close()
return err
}
return nil
}
- 给定一系列Series key, 返回对应的Series id,如果没有对应的id,则将series key插入到Partition(其实就是写入到对应的segment中)
func (p *SeriesPartition) CreateSeriesListIfNotExists(keys [][]byte, keyPartitionIDs []int, ids []uint64) error {
var writeRequired bool
p.mu.RLock()
//利用index作快速查找,同时确认是否没有包含的key
for i := range keys {
if keyPartitionIDs[i] != p.id {
continue
}
id := p.index.FindIDBySeriesKey(p.segments, keys[i])
if id == 0 {
writeRequired = true
continue
}
ids[i] = id
}
p.mu.RUnlock()
// Exit if all series for this partition already exist.
if !writeRequired {
return nil
}
type keyRange struct {
id uint64
offset int64
}
newKeyRanges := make([]keyRange, 0, len(keys))
// Obtain write lock to create new series.
p.mu.Lock()
defer p.mu.Unlock()
// Track offsets of duplicate series.
newIDs := make(map[string]uint64, len(ids))
for i := range keys {
// Skip series that don't belong to the partition or have already been created.
if keyPartitionIDs[i] != p.id || ids[i] != 0 {
continue
}
// Re-attempt lookup under write lock.
key := keys[i]
if ids[i] = newIDs[string(key)]; ids[i] != 0 {
continue
} else if ids[i] = p.index.FindIDBySeriesKey(p.segments, key); ids[i] != 0 {
continue
}
// Write to series log and save offset.
// 写入log entry
id, offset, err := p.insert(key)
if err != nil {
return err
}
// Append new key to be added to hash map after flush.
ids[i] = id
newIDs[string(key)] = id
newKeyRanges = append(newKeyRanges, keyRange{id, offset})
}
// Flush active segment writes so we can access data in mmap.
// 立即写入文件
if segment := p.activeSegment(); segment != nil {
if err := segment.Flush(); err != nil {
return err
}
}
// Add keys to hash map(s).
// 更新内存索引
for _, keyRange := range newKeyRanges {
p.index.Insert(p.seriesKeyByOffset(keyRange.offset), keyRange.id, keyRange.offset)
}
// compact 到磁盘文件,下面会详细讲解
return nil
}
- 根据id获取series key
func (p *SeriesPartition) SeriesKey(id uint64) []byte {
if id == 0 {
return nil
}
p.mu.RLock()
// 先用索引根据id获取到offset, 再用offset获取到key
key := p.seriesKeyByOffset(p.index.FindOffsetByID(id))
p.mu.RUnlock()
return key
}
- 根据series key获取id
func (p *SeriesPartition) FindIDBySeriesKey(key []byte) uint64 {
p.mu.RLock()
if p.closed {
p.mu.RUnlock()
return 0
}
id := p.index.FindIDBySeriesKey(p.segments, key)
p.mu.RUnlock()
return id
}
- 插入series key
func (p *SeriesPartition) insert(key []byte) (id uint64, offset int64, err error) {
// id为p.seq, 每插入一条,p.seq会递增SeriesFilePartitionN
id = p.seq
offset, err = p.writeLogEntry(AppendSeriesEntry(nil, SeriesEntryInsertFlag, id, key))
if err != nil {
return 0, 0, err
}
p.seq += SeriesFilePartitionN
return id, offset, nil
}
- compact index到磁盘
func (c *SeriesPartitionCompactor) compactIndexTo(index *SeriesIndex, seriesN uint64, segments []*SeriesSegment, path string) error {
hdr := NewSeriesIndexHeader()
hdr.Count = seriesN
hdr.Capacity = pow2((int64(hdr.Count) * 100) / SeriesIndexLoadFactor)
//分配两个hash map的内存空间,后面就是填充这两个map,然后写到磁盘
keyIDMap := make([]byte, (hdr.Capacity * SeriesIndexElemSize))
idOffsetMap := make([]byte, (hdr.Capacity * SeriesIndexElemSize))
// Reindex all partitions.
var entryN int
// 遍历所有的segment
for _, segment := range segments {
errDone := errors.New("done")
// 遍历segment内部的每一个Series Entry
if err := segment.ForEachEntry(func(flag uint8, id uint64, offset int64, key []byte) error {
// Make sure we don't go past the offset where the compaction began.
if offset > index.maxOffset {
return errDone
}
// Check for cancellation periodically.
// 每处理1000条entry,检查这个compact过程是否需要中断
if entryN++; entryN%1000 == 0 {
select {
case <-c.cancel:
return ErrSeriesPartitionCompactionCancelled
default:
}
}
// Only process insert entries.
switch flag {
case SeriesEntryInsertFlag: // fallthrough
case SeriesEntryTombstoneFlag: //遇到墓碑flag就跳过
return nil
default:
return fmt.Errorf("unexpected series partition log entry flag: %d", flag)
}
// Save max series identifier processed.
hdr.MaxSeriesID, hdr.MaxOffset = id, offset
// Ignore entry if tombstoned.
// 如果id已经被标识为删除,就跳过
if index.IsDeleted(id) {
return nil
}
// Insert into maps.
// 根据key定位到写入的内存map的位置后写入
c.insertIDOffsetMap(idOffsetMap, hdr.Capacity, id, offset)
return c.insertKeyIDMap(keyIDMap, hdr.Capacity, segments, key, offset, id)
}); err == errDone {
break
} else if err != nil {
return err
}
}
// Open file handler.
f, err := os.Create(path)
if err != nil {
return err
}
defer f.Close()
// Calculate map positions.
hdr.KeyIDMap.Offset, hdr.KeyIDMap.Size = SeriesIndexHeaderSize, int64(len(keyIDMap))
hdr.IDOffsetMap.Offset, hdr.IDOffsetMap.Size = hdr.KeyIDMap.Offset+hdr.KeyIDMap.Size, int64(len(idOffsetMap))
// Write header.
if _, err := hdr.WriteTo(f); err != nil {
return err
}
// Write maps.
if _, err := f.Write(keyIDMap); err != nil {
return err
} else if _, err := f.Write(idOffsetMap); err != nil {
return err
}
// Sync & close.
if err := f.Sync(); err != nil {
return err
} else if err := f.Close(); err != nil {
return err
}
return nil
}
SeriesFile
- 定义: 管理当前db下所有的SeriesePartition, 提供了操作Series的公共接口,对外屏蔽了SeriesPartition和SeriesSegment的存在;
- 我们在这里讲一下series id的产生规则
- Influxdb将paritition数量定死了为 8, 就是说所有的serieskey放在这8个桶里
- 如何确定放在哪个桶里呢?就是上面提到的计算SeriesKey的hash值然后取模parition个数
int(xxhash.Sum64(key) % SeriesFilePartitionN) - 所有这些partition的id是0 到 7, 每个partiton都有一个顺列号seq, 初始值为partition id + 1, 这个顺列号就是放入这个parition中的seriese key对应的id,每次增加 8, 比如对于1号partition, 第一个放入的series id就是2, 第二个就是10
- 有了上面的规则,从seriese id上就很容易得到它属于哪个 partition:
int((id - 1) % SeriesFilePartitionN)
- 将一系列的SeriesKey写入相应的Partiton, 写入哪个partition是计算SeriesKey的hash值然后取模parition个数
int(xxhash.Sum64(key) % SeriesFilePartitionN)
func (f *SeriesFile) CreateSeriesListIfNotExists(names [][]byte, tagsSlice []models.Tags) ([]uint64, error) {
//生成SeriesKey的slice
keys := GenerateSeriesKeys(names, tagsSlice)
//生成parition id的slice
keyPartitionIDs := f.SeriesKeysPartitionIDs(keys)
ids := make([]uint64, len(keys))
var g errgroup.Group
//使用goroutine并行写入
for i := range f.partitions {
p := f.partitions[i]
g.Go(func() error {
return p.CreateSeriesListIfNotExists(keys, keyPartitionIDs, ids)
})
}
if err := g.Wait(); err != nil {
return nil, err
}
return ids, nil
}
- 所有查询操作,基本上都是首先定位到Partition, 然后再由partition代劳,partition使用index和segment也来搞定, 这里不详述了
SeriesIDSet
- 用bitmap存储的Series ID, 这其实是个布隆过滤器的实现,如果布隆过滤器说一个id不存在于这个bitmap中那一定是不存在,但如果它说存在却不一定是真存在;
- 定义:
type SeriesIDSet struct {
sync.RWMutex
bitmap *roaring.Bitmap
}
- 这个bitmap使用roaring.Bitmap实现
- 我们来简单的看一下New方法的实现
func NewSeriesIDSet(a ...uint64) *SeriesIDSet {
ss := &SeriesIDSet{bitmap: roaring.NewBitmap()}
if len(a) > 0 {
a32 := make([]uint32, len(a))
for i := range a {
a32[i] = uint32(a[i])
}
ss.bitmap.AddMany(a32)
}
return ss
}
这里最关键的是参数里SeriesID是uinit64, 但存入bitmap时强转成了uinit32, 只取了SeriesID的低32位,也因此在查询id是否存在时,也只用低32位去查询,如果查到了有两种可能,存入的id就是这个uinit32值,存入的id的低32位是这个uint32值