I recently started a new newsletter focus on AI education. TheSequence is a no-BS( meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:
我最近开始了一份有关AI教育的新时事通讯。 TheSequence是无BS(意味着没有炒作,没有新闻等),它是专注于AI的新闻通讯,需要5分钟的阅读时间。 目标是让您了解机器学习项目,研究论文和概念的最新动态。 请通过以下订阅尝试一下:
20 years ago, Christopher Nolan produced one of his first most influential movies in the history of cinematography. Memento broke many of the traditional paradigms in the film industry by structuring two parallel narratives, one chronologically going backwards and one going forward. The novel form narrative implemented in Memento forces the audience to constantly reevaluate their knowledge of the plot and they keep learning small details every few minutes of the film. It turns out that replaying a knowledge sequence backwards for small time intervals is an incredibly captivating method of learning and also a marvel of human cognition. How would a similar skill look in artificial intelligence(AI) systems. I was having a recent conversation about this topic and pointed out to OpenAI’s work creating an agent that learned to play Montezuma’s Revenge using a single demonstration.
20年前,克里斯托弗·诺兰(Christopher Nolan)制作了他在电影史上最有影响力的电影之一。 Memento通过构造两个平行的叙述,打破了电影界的许多传统范式,一个叙述按时间顺序向后倒推,而另一个则按顺序进行。 在《回忆》中采用的新颖形式叙事迫使观众不断重新评估他们对情节的了解,并且每隔几分钟就不断学习小细节。 事实证明,在很小的时间间隔内向后重播知识序列是令人难以置信的迷人学习方法,也是人类认知的奇迹。 在人工智能(AI)系统中,类似技能的外观如何? 我最近在谈论这个话题,并指出了OpenAI的工作,即创建了一个代理,该代理通过一个演示就学会了扮演Montezuma的复仇 。
Montezuma’s Revenge is a game often used in reinforcement learning demonstrations as it requires a player to take complex sequence of actions before producing any meaningful results. Typically, most approaches to solve Montezuma’s Revenge used complex forms of reinforcement learning such as Deep Q-Learning that require large collections of videos to train agents on the different game strategies. Those large datasets are incredibly hard to acquire and curate. To address that challenge, the team at OpenAI used a relatively new discipline in reinforcement learning known as one-shot learning.
蒙特祖玛的复仇是一款经常用于强化学习演示的游戏,因为它要求玩家在产生任何有意义的结果之前先采取一系列复杂的动作。 通常,大多数解决“蒙特祖玛的复仇”的方法都是使用复杂形式的强化学习,例如“深度Q学习”,需要大量视频集来对坐席进行不同游戏策略的培训。 那些庞大的数据集很难获得和管理。 为了应对这一挑战,OpenAI的团队在强化学习中使用了一种相对较新的学科,即一发式学习。
一站式强化学习 (One-Shot Reinforcement Learning)
Conceptually, one-shot or few-shot learning is a form of reinforcement learning in which agents learn a policy with a relatively few iterations of experience. One-shot learning looks to resemble some of the characteristics of human cognitions that allow us to master a new task with a relatively small base knowledge. However, as appealing as one-shot learning sounds, it results incredibly difficult to implement as its very vulnerable to the famous exploration-exploitation reinforcement learning dilemma.
从概念上讲,一次或几次学习是强化学习的一种形式,在这种学习中,主体通过相对较少的经验迭代来学习策略。 一次性学习看起来很像人类认知的某些特征,这些特征使我们能够以相对较小的基础知识来完成一项新任务。 但是,尽管听起来很吸引人,但由于难以克服著名的勘探开发强化学习难题,因此难以实施。
The traditional reinforcement learning theory is based on two fundamental methods: model-based and model-free. Model-based methods focused on learning as much as possible about a given environment and creating a model to represent it. From that perspective, model-based methods typically rely on other trained methods to better understand the correct actions to take on any given state of the environment. Model-free methods don’t ignore the characteristics of the environment and instead focused on learning a policy that produces the best outcome.
传统的强化学习理论基于两种基本方法:基于模型的方法和无模型的方法。 基于模型的方法着重于尽可能多地了解给定的环境并创建一个表示它的模型。 从这个角度来看,基于模型的方法通常依赖于其他训练有素的方法来更好地理解在任何给定的环境状态下采取的正确操作。 无模型方法不会忽略环境的特征,而是专注于学习产生最佳结果的策略。
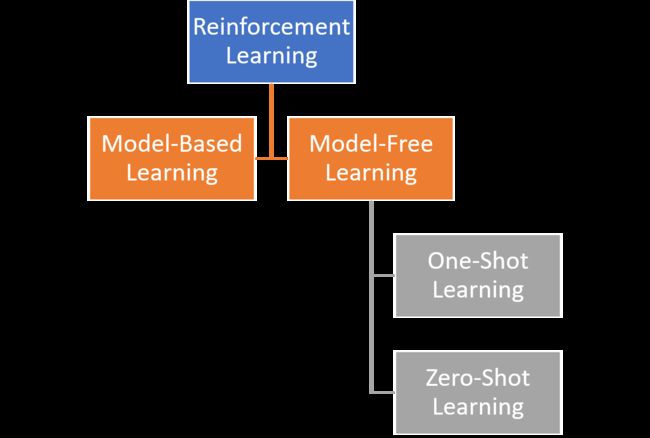
Most of the best-know model-free methods such as Policy-Gradients or Q-Learning take random actions in an environment and reinforce those actions that lead to a positive outcome. While this idea seems relatively trivial, it only works is the set of rewards is dense enough that any random action can be mapped to a reward. However, what happens when an agents needs to take a large sequence of actions without experiencing any specific reward? In reinforcement learning theory, this is known as the exploration-exploitation dilemma in which an agent needs to constantly balance short-term rewards vs. further exploration that can lead to bigger rewards. In the case of one-shot learning, using a small training set requires the agents to master exploration in order to produce a meaningful outcome.
大多数最知名的无模型方法(例如“策略梯度”或Q-Learning)都会在环境中采取随机行动,并加强那些能够带来积极成果的行动。 尽管这个想法似乎比较琐碎,但只有在奖励集足够密集以至于任何随机动作都可以映射为奖励时,它才起作用。 但是,当代理商需要采取大量行动而又没有获得任何特定奖励时,会发生什么? 在强化学习理论中,这被称为探索与开发困境,在这种困境中,主体需要不断地平衡短期奖励与进一步的探索之间的平衡,以寻求更大的奖励。 在一次学习的情况下,使用少量训练集就需要代理商掌握探索知识,以产生有意义的结果。

Let’s put this challenge in context by looking at Montezuma’s Revenge. In the game, the player needs to execute a large number of actions without obtaining any meaningful outcome such as getting a key.
让我们通过查看蒙特祖玛的复仇来将这一挑战放在背景中。 在游戏中,玩家需要执行大量动作,而没有获得任何有意义的结果,例如获取钥匙。
For instance, in the previous video, the probability of obtaining the key can decomposed using the following formula:
例如,在上一个视频中,可以使用以下公式分解获得密钥的概率:
p(get key) = p(get down ladder 1) * p(get down rope) * p(get down ladder 2) * p(jump over skull) * p(get up ladder 3).
p(获取密钥)= p(获取梯子1)* p(获取绳子)* p(获取梯子2)* p(跳过头骨)* p(获取梯子3)。
That formula clearly illustrates the biggest challenge of one-shot learning models. The probability of obtaining a reward poses a complexity of exp(N) where N is the number of actions that takes to achieve any previous steps. Any model that shows this level of exponential complexity scaling is incredibly hard to implement in practical scenarios. How did OpenAI solves this challenge?
该公式清楚地说明了一次性学习模型的最大挑战。 获得奖励的可能性带来了exp(N)的复杂性,其中N是实现任何先前步骤所采取的操作数。 任何显示这种指数复杂度缩放级别的模型在实际情况下都难以实现。 OpenAI如何解决这一挑战?
通过向后演示创建纪念效果 (Creating a Memento Effect with Backward Demonstrations)
The greatest insight of OpenAI is that while model-free reinforcement learning models have challenges orchestrating large sequence of actions, they are incredibly effective with shorter sequences. OpenAI decomposed a single video of Montezuma’s Revenge into a group of videos each one representing a specific task the agent needed to learn. Cleverly, they did this by going backwards on time ?
OpenAI的最大见解是,尽管无模型的强化学习模型在协调大型动作序列方面遇到了挑战,但在较短的动作序列中却非常有效。 OpenAI将Montezuma的复仇的单个视频分解为一组视频,每个视频代表代理需要学习的特定任务。 巧妙地,他们是通过按时倒退来做到这一点的?
The OpenAI approach to one-shot learning starts by training the agent with an episode almost at the end of the demonstration. Once the agent can beat the demonstrator in the remaining part of the game, the training mechanism rolls the starting point of the episode back in time like the Memento black-and-white track The model keeps doing that until the agent is able to play from the start of the game.
OpenAI一次学习的方法始于在演示快要结束时用一集训练代理。 一旦特工在游戏的其余部分击败了演示者,训练机制便像Memento黑白轨迹一样将事件的起点回滚到时间模型会一直这样做,直到特工能够玩从游戏开始。
In the following sequence of images, the AI agent finds itself halfway up the ladder that leads to the key. Once it learns to climb the ladder from there, the model can have it start at the point where it needs to jump over the skull. After it learns to do that, the model can have it start on the rope leading to the floor of the room, etc. Eventually, the agent starts in the original starting state of the game and is able to reach the key completely by itself.
在以下图像序列中,AI代理发现自己位于通往钥匙的梯子的中间。 一旦学会了从那里爬上梯子,模型就可以使其从需要跳过头骨的点开始。 在学会了这一点之后,模型可以使它从通向房间地板等的绳索上开始。最终,座席在游戏的原始开始状态下开始,并且能够完全自己到达钥匙。

By creating sub-training episodes rolling the state of the demonstration back in time, the model is decomposing a large exploitation problem into small and easy to solve exploration problems. More importantly, this approach moves the complexity of the problem from exponential to linear. If a specific sequence of N actions is required to reach a reward, this sequence may now be learned in a time that is linear in N.
通过创建子训练集,可以使演示状态及时返回,该模型将大型开采问题分解为小型且易于解决的勘探问题。 更重要的是,这种方法使问题的复杂性从指数级变为线性级。 如果需要N个动作的特定序列才能获得奖励,则现在可以在N个线性时间内学习该序列。
The OpenAI one-shot learning approach to solve Montezuma’s Revenge is incredibly clever. The specific reinforcement learning algorithm OpenAI used to learn Montezuma’s Revenge is a variant of Proximal Policy Optimization which is the same method that was used in their famous OpenAI Five system. Initial tests have a model scoring 74,500 points using a single demonstration. The code and demos are available on Github.
解决蒙特祖玛的复仇的OpenAI一站式学习方法非常聪明。 用于学习蒙特祖玛的复仇的特定强化学习算法OpenAI是近端策略优化的一种变体,与他们著名的OpenAI Five系统中使用的方法相同。 最初的测试使用一次演示就获得了74,500分的模型。 该代码和演示可在Github上获得 。
翻译自: https://medium.com/swlh/the-memento-effect-how-ai-agents-learned-to-play-montezumas-revenge-by-going-backwards-b24720ec2ed