2017年第八届蓝桥杯C/C++组省赛真题解析
目录
1. 购物单
2.等差素数列
3.承压计算
4.方格分割(待)
5.取数位
6.最大公共子串
7.日期问题(待)
8.包子凑数
9.分巧克力
10.k倍区间
1. 购物单
小明刚刚找到工作,老板人很好,只是老板夫人很爱购物。老板忙的时候经常让小明帮忙到商场代为购物。小明很厌烦,但又不好推辞。
这不,XX大促销又来了!老板夫人开出了长长的购物单,都是有打折优惠的。
小明也有个怪癖,不到万不得已,从不刷卡,直接现金搞定。
现在小明很心烦,请你帮他计算一下,需要从取款机上取多少现金,才能搞定这次购物。
取款机只能提供100元面额的纸币。小明想尽可能少取些现金,够用就行了。
你的任务是计算出,小明最少需要取多少现金。
以下是让人头疼的购物单,为了保护隐私,物品名称被隐藏了。
-----------------
**** 180.90 88折
**** 10.25 65折
**** 56.14 9折
**** 104.65 9折
**** 100.30 88折
**** 297.15 半价
**** 26.75 65折
**** 130.62 半价
**** 240.28 58折
**** 270.62 8折
**** 115.87 88折
**** 247.34 95折
**** 73.21 9折
**** 101.00 半价
**** 79.54 半价
**** 278.44 7折
**** 199.26 半价
**** 12.97 9折
**** 166.30 78折
**** 125.50 58折
**** 84.98 9折
**** 113.35 68折
**** 166.57 半价
**** 42.56 9折
**** 81.90 95折
**** 131.78 8折
**** 255.89 78折
**** 109.17 9折
**** 146.69 68折
**** 139.33 65折
**** 141.16 78折
**** 154.74 8折
**** 59.42 8折
**** 85.44 68折
**** 293.70 88折
**** 261.79 65折
**** 11.30 88折
**** 268.27 58折
**** 128.29 88折
**** 251.03 8折
**** 208.39 75折
**** 128.88 75折
**** 62.06 9折
**** 225.87 75折
**** 12.89 75折
**** 34.28 75折
**** 62.16 58折
**** 129.12 半价
**** 218.37 半价
**** 289.69 8折
--------------------
需要说明的是,88折指的是按标价的88%计算,而8折是按80%计算,余者类推。
特别地,半价是按50%计算。
请提交小明要从取款机上提取的金额,单位是元。
答案是一个整数,类似4300的样子,结尾必然是00,不要填写任何多余的内容。
特别提醒:不许携带计算器入场,也不能打开手机。
1.题是什么?
计算那一堆商品打折之后的价格总和,结果向上取整,以百为单位
2.思路
数据格式完整,直接将数据拷到txt中,使用记事本的替换功能将"****"全部去除,"半价"全部替换为"5折","折"全部去除,依次完成这三步之后数据清洗完成,运行如下代码完成计算,注意,链接生成的exe要与清洗出来的txt文件处于同一目录下才可读取到!
3.ac代码
答案:5200
#include
void solve(){
FILE *in=fopen("in.txt","r");
float ans=0;
float price,discount;
while(fscanf(in,"%f%f",&price,&discount)!=EOF){
if(discount<10) discount*=10;
ans+=price*discount/100;
}
printf("%f\n",ans);
}
int main(){
solve();
return 0;
} 2.等差素数列
2,3,5,7,11,13,....是素数序列。
类似:7,37,67,97,127,157 这样完全由素数组成的等差数列,叫等差素数数列。
上边的数列公差为30,长度为6。
2004年,格林与华人陶哲轩合作证明了:存在任意长度的素数等差数列。
这是数论领域一项惊人的成果!
有这一理论为基础,请你借助手中的计算机,满怀信心地搜索:
长度为10的等差素数列,其公差最小值是多少?
注意:需要提交的是一个整数,不要填写任何多余的内容和说明文字。
1.题是什么?
首先定义了一种等差素数列:完全由素数组成的等差数列,要求的就是长度为10的公差最小的等差素数列
2.思路
首先处理这个问题得了解素数处理,没了解过素数处理的朋友先移步我的博客 素数埃氏筛法.
我们知道素数的分布情况是越靠后分布越稀疏,故而满足条件的公差最小的情况必然会出现在数字偏小的区间,因而我们只需要将1e6以内的所有素数以埃氏筛法预处理出来,然后在其中寻找满足条件的最小公差,因是选择题不必太考虑因而我采取直接暴力搜寻,
至于为什么1e6以上的素数集合中不会出现更小公差的10长度等差素数列?我无法理论证明.
3.ac代码
答案:210
#include
const int maxn=1e6+5;
int prime[maxn],primenum;
int flag[maxn/32+1];//数组大小实际缩小8倍 ,对应位为0表示不是素数
//通过埃氏筛法获取t以内的所有素数,存于prime
void wei_prime(int t){
primenum=0;
flag[0]|=3;
for(int k=1;k<=t/32+1;k++) flag[k]=0;
for(int i=2;i<=t;i++){
if(!((flag[i/32]>>(i%32))&1)){
for(int j=i*2;j<=t;j+=i) flag[j/32]|=(1<<(j%32));
prime[primenum++]=i;
}
}
}
//通过flag数组判断数字t是否素数
bool isprime(int t){
if((flag[t/32]>>(t%32))&1) return false;
return true;
}
void solve(){
wei_prime(1e6);
int ans=0;
for(int i=1;i<=1e5;i++){
for(int k=0;prime[k]+9*i<1e6;k++){
int j=1;
while(j<10){
if(!isprime(prime[k]+i*j)) break;
j++;
}
if(j==10){
printf("%d\n",i);
return;
}
}
}
}
int main(){
solve();
return 0;
}
3.承压计算
X星球的高科技实验室中整齐地堆放着某批珍贵金属原料。
每块金属原料的外形、尺寸完全一致,但重量不同。
金属材料被严格地堆放成金字塔形。
7
5 8
7 8 8
9 2 7 2
8 1 4 9 1
8 1 8 8 4 1
7 9 6 1 4 5 4
5 6 5 5 6 9 5 6
5 5 4 7 9 3 5 5 1
7 5 7 9 7 4 7 3 3 1
4 6 4 5 5 8 8 3 2 4 3
1 1 3 3 1 6 6 5 5 4 4 2
9 9 9 2 1 9 1 9 2 9 5 7 9
4 3 3 7 7 9 3 6 1 3 8 8 3 7
3 6 8 1 5 3 9 5 8 3 8 1 8 3 3
8 3 2 3 3 5 5 8 5 4 2 8 6 7 6 9
8 1 8 1 8 4 6 2 2 1 7 9 4 2 3 3 4
2 8 4 2 2 9 9 2 8 3 4 9 6 3 9 4 6 9
7 9 7 4 9 7 6 6 2 8 9 4 1 8 1 7 2 1 6
9 2 8 6 4 2 7 9 5 4 1 2 5 1 7 3 9 8 3 3
5 2 1 6 7 9 3 2 8 9 5 5 6 6 6 2 1 8 7 9 9
6 7 1 8 8 7 5 3 6 5 4 7 3 4 6 7 8 1 3 2 7 4
2 2 6 3 5 3 4 9 2 4 5 7 6 6 3 2 7 2 4 8 5 5 4
7 4 4 5 8 3 3 8 1 8 6 3 2 1 6 2 6 4 6 3 8 2 9 6
1 2 4 1 3 3 5 3 4 9 6 3 8 6 5 9 1 5 3 2 6 8 8 5 3
2 2 7 9 3 3 2 8 6 9 8 4 4 9 5 8 2 6 3 4 8 4 9 3 8 8
7 7 7 9 7 5 2 7 9 2 5 1 9 2 6 5 3 9 3 5 7 3 5 4 2 8 9
7 7 6 6 8 7 5 5 8 2 4 7 7 4 7 2 6 9 2 1 8 2 9 8 5 7 3 6
5 9 4 5 5 7 5 5 6 3 5 3 9 5 8 9 5 4 1 2 6 1 4 3 5 3 2 4 1
X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X
其中的数字代表金属块的重量(计量单位较大)。
最下一层的X代表30台极高精度的电子秤。
假设每块原料的重量都十分精确地平均落在下方的两个金属块上,
最后,所有的金属块的重量都严格精确地平分落在最底层的电子秤上。
电子秤的计量单位很小,所以显示的数字很大。
工作人员发现,其中读数最小的电子秤的示数为:2086458231
请你推算出:读数最大的电子秤的示数为多少?
注意:需要提交的是一个整数,不要填写任何多余的内容。
1.题是什么?
按规则,每块原料的重量平均落在下方的两个原料上,已知电子秤显示存在某个比例的放大,最小的数字被放大为2086458231,你要输出最大的被显示为多少.
2.思路
核心就是每块原料的重量平均落在下方的两个原料上,以此对数据进行处理,最终获得最下方30个的受重,而受重和显示的数字之间是存在一个比例关系的,这个比例将受重放大了以加大精确度,故而我们需要得到最小和最大的受重,然后根据最小的受重和最小的显示数字得到这个比例,将之乘以最大的受重,即可知道最大的显示数字.
3.ac代码
答案:72665192664
#include
void solve(){
int sum[31];
sum[0]=0;
for(int i=1;i<=30;i++) sum[i]=i+sum[i-1];
double weight[sum[30]];
FILE *in=fopen("in.txt","r");
int now=0;
while(fscanf(in,"%lf",&weight[now])!=EOF) now++;
for(int i=0;i<30;i++) weight[sum[29]+i]=0;
for(int i=1;i<=29;i++){
for(int j=0;jweight[sum[29]+i]) minnum=weight[sum[29]+i];
}
printf("%lf",maxnum*2086458231/minnum);
}
int main(){
solve();
return 0;
}
4.方格分割
6x6的方格,沿着格子的边线剪开成两部分。
要求这两部分的形状完全相同。
如图:p1.png, p2.png, p3.png 就是可行的分割法。
试计算:
包括这3种分法在内,一共有多少种不同的分割方法。
注意:旋转对称的属于同一种分割法。
请提交该整数,不要填写任何多余的内容或说明文字。
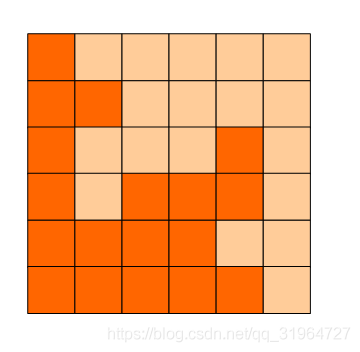
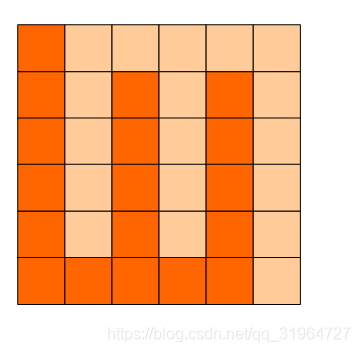
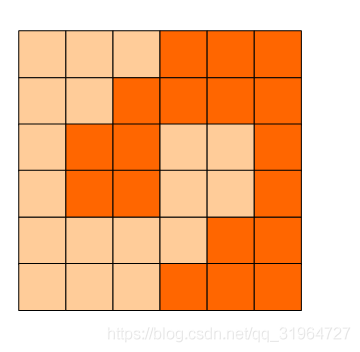
1.题是什么?
如图,求将6*6的方格分割为完全相同的两部分的方法数目(旋转对称的属于同一种分割法).
2.思路
我们先将6*6方格根据最左上方端点建立坐标系,x方向向右,y方向向下,故而他的左上方端点坐标为(0,0),6*6方格的中心点坐标为(3,3);
3.ac代码
5.取数位
求1个整数的第k位数字有很多种方法。
以下的方法就是一种。
// 求x用10进制表示时的数位长度
int len(int x){
if(x<10) return 1;
return len(x/10)+1;
}
// 取x的第k位数字
int f(int x, int k){
if(len(x)-k==0) return x%10;
return _____________________; //填空
}
int main()
{
int x = 23574;
printf("%d\n", f(x,3));
return 0;
}对于题目中的测试数据,应该打印5。
请仔细分析源码,并补充划线部分所缺少的代码。
注意:只提交缺失的代码,不要填写任何已有内容或说明性的文字。
1.题是什么?
代码补全
2.思路
首先len很明了,就是数字是几位数用的,而f明显是一个递归,已知逻辑就是当x的长度等于k时,返回x的个位数,其实这就是这个递归的终点,我们要填的代码就是要去逼近这个终点,f(x/10,k)就好了,相当于发现此时数位长了就缩一下就好,这道题的设计者明显没有思考过如果给的x的位数本就小于x的情况,故而我们也可以顺便额外做一个保护,当出现x的位数本就小于x的情况时返回-1表示输入错误
3.ac代码
答案:len(x)
#include
// 求x用10进制表示时的数位长度
int len(int x){
if(x<10) return 1;
return len(x/10)+1;
}
// 取x的第k位数字
int f(int x, int k){
if(len(x)-k==0) return x%10;
return len(x) 6.最大公共子串
最大公共子串长度问题就是:
求两个串的所有子串中能够匹配上的最大长度是多少。
比如:"abcdkkk" 和 "baabcdadabc",
可以找到的最长的公共子串是"abcd",所以最大公共子串长度为4。
下面的程序是采用矩阵法进行求解的,这对串的规模不大的情况还是比较有效的解法。
请分析该解法的思路,并补全划线部分缺失的代码。
#include
#include
#define N 256
int f(const char* s1, const char* s2)
{
int a[N][N];
int len1 = strlen(s1);
int len2 = strlen(s2);
int i,j;
memset(a,0,sizeof(int)*N*N);
int max = 0;
for(i=1; i<=len1; i++){
for(j=1; j<=len2; j++){
if(s1[i-1]==s2[j-1]) {
a[i][j] = __________________________; //填空
if(a[i][j] > max) max = a[i][j];
}
}
}
return max;
}
int main()
{
printf("%d\n", f("abcdkkk", "baabcdadabc"));
return 0;
} 注意:只提交缺少的代码,不要提交已有的代码和符号。也不要提交说明性文字。
1.题是什么?
代码补全
2.思路
题中代码是想使用类似与dp的思路,a[i][j]的含义是s1串中前i个字符所构成子串与s2串中前j个字符所构成子串的最长公共后缀长度,正因此,如果s1[i]==s2[j],我们便可以以a[i][j] = a[i-1][j-1]+1;求得a[i][j],这样便完成了数据的递推.最终a数组中最大的值便是最长公共子串长度.
你可能会有点迷糊,我们要求的是s1与s2的最长公共子串长度啊,关最长公共后缀长度什么事?其实只要我们求出所有m*n个情况下的最长公共后缀,取其最大值便是最长公共子串长度,就如abcdkkk与baabcdadabc,最长公共子串长度就是a[3][5]的值.
3.ac代码
答案:a[i-1][j-1]+1
#include
#include
#define N 256
int f(const char* s1, const char* s2)
{
int a[N][N];
int len1 = strlen(s1);
int len2 = strlen(s2);
int i,j;
memset(a,0,sizeof(int)*N*N);
int max = 0;
for(i=1; i<=len1; i++){
for(j=1; j<=len2; j++){
if(s1[i-1]==s2[j-1]) {
a[i][j] = a[i-1][j-1]+1; //填空
if(a[i][j] > max) max = a[i][j];
}
}
}
return max;
}
int main()
{
printf("%d\n", f("abcdkkk", "baabcdadabc"));
return 0;
}
7.日期问题
小明正在整理一批历史文献。这些历史文献中出现了很多日期。小明知道这些日期都在1960年1月1日至2059年12月31日。令小明头疼的是,这些日期采用的格式非常不统一,有采用年/月/日的,有采用月/日/年的,还有采用日/月/年的。更加麻烦的是,年份也都省略了前两位,使得文献上的一个日期,存在很多可能的日期与其对应。
比如02/03/04,可能是2002年03月04日、2004年02月03日或2004年03月02日。
给出一个文献上的日期,你能帮助小明判断有哪些可能的日期对其对应吗?
输入
----
一个日期,格式是"AA/BB/CC"。 (0 <= A, B, C <= 9)
输入
----
输出若干个不相同的日期,每个日期一行,格式是"yyyy-MM-dd"。多个日期按从早到晚排列。
样例输入
----
02/03/04
样例输出
----
2002-03-04
2004-02-03
2004-03-02
资源约定:
峰值内存消耗(含虚拟机) < 256M
CPU消耗 < 1000ms
请严格按要求输出,不要画蛇添足地打印类似:“请您输入...” 的多余内容。
注意:
main函数需要返回0;
只使用ANSI C/ANSI C++ 标准;
不要调用依赖于编译环境或操作系统的特殊函数。
所有依赖的函数必须明确地在源文件中 #include
不能通过工程设置而省略常用头文件。
提交程序时,注意选择所期望的语言类型和编译器类型。
1.题是什么?
2.思路
3.ac代码
8.包子凑数
小明几乎每天早晨都会在一家包子铺吃早餐。他发现这家包子铺有N种蒸笼,其中第i种蒸笼恰好能放Ai个包子。每种蒸笼都有非常多笼,可以认为是无限笼。
每当有顾客想买X个包子,卖包子的大叔就会迅速选出若干笼包子来,使得这若干笼中恰好一共有X个包子。比如一共有3种蒸笼,分别能放3、4和5个包子。当顾客想买11个包子时,大叔就会选2笼3个的再加1笼5个的(也可能选出1笼3个的再加2笼4个的)。
当然有时包子大叔无论如何也凑不出顾客想买的数量。比如一共有3种蒸笼,分别能放4、5和6个包子。而顾客想买7个包子时,大叔就凑不出来了。
小明想知道一共有多少种数目是包子大叔凑不出来的。
输入
----
第一行包含一个整数N。(1 <= N <= 100)
以下N行每行包含一个整数Ai。(1 <= Ai <= 100)
输出
----
一个整数代表答案。如果凑不出的数目有无限多个,输出INF。
例如,
输入:
2
4
5
程序应该输出:
6
再例如,
输入:
2
4
6
程序应该输出:
INF
1.题是什么?
给你n个数字,问你通过这n个数字凑不出来的数字有多少个,无穷个则输出INF
2.思路
首先判断这n笼包子是否存在某两个数互质,如果存在则直接输出INF,否则再通过完全背包dp求解具体个数,这是主体思路.
判断互质其实就是解其最大公约数看是否是1,求解两数最大公约数用gcd算法,不了解gcd算法的移步我的博客 gcd与扩展gcd
那为什么存在互质的情况下能凑出来的数目会是固定的呢?我们来想想通过n笼包子凑出目标数目target的过程,其实就相当于求解以下方程:a[0]*x1+a[1]*x2+...+a[n-1]*xn=target,找是否存在这么一组解x1,x2..xn使之成立,成立则能凑出来
而如果a[0]...a[n-1]这n笼包子中存在某两个数如a[0],a[3]是互质的,则大于a[0]*a[3]的所有数我都可以仅以a[0]和a[3]凑出来,而如果不存在互质,在无限大的数据下不能凑出的数字一定无穷多个..
因每笼包子最多100个,故只需要处理10000以内的即可,判断这些数字是否可由这n笼凑成其实就是一个标准的完全背包问题.
3.ac代码
#include
int gcd(int a,int b){
if(b==0) return a;
return gcd(b,a%b);
}
const int maxn=105;
int a[maxn];
void solve(){
int n;
scanf("%d",&n);
for(int i=0;i 9.分巧克力
儿童节那天有K位小朋友到小明家做客。小明拿出了珍藏的巧克力招待小朋友们。
小明一共有N块巧克力,其中第i块是Hi x Wi的方格组成的长方形。
为了公平起见,小明需要从这 N 块巧克力中切出K块巧克力分给小朋友们。切出的巧克力需要满足:
1. 形状是正方形,边长是整数
2. 大小相同
例如一块6x5的巧克力可以切出6块2x2的巧克力或者2块3x3的巧克力。
当然小朋友们都希望得到的巧克力尽可能大,你能帮小Hi计算出最大的边长是多少么?
输入
第一行包含两个整数N和K。(1 <= N, K <= 100000)
以下N行每行包含两个整数Hi和Wi。(1 <= Hi, Wi <= 100000)
输入保证每位小朋友至少能获得一块1x1的巧克力。
输出
输出切出的正方形巧克力最大可能的边长。
样例输入:
2 10
6 5
5 6
样例输出:
2
资源约定:
峰值内存消耗(含虚拟机) < 256M
CPU消耗 < 1000ms
请严格按要求输出,不要画蛇添足地打印类似:“请您输入...” 的多余内容。
注意:
main函数需要返回0;
只使用ANSI C/ANSI C++ 标准;
不要调用依赖于编译环境或操作系统的特殊函数。
所有依赖的函数必须明确地在源文件中 #include
不能通过工程设置而省略常用头文件。
提交程序时,注意选择所期望的语言类型和编译器类型。
1.题是什么?
要从已知大小的n块巧克力中切出k块正方形巧克力,问可取的最大大小是多少.
2.思路
一道最大化极小值的问题,使用二分查值确定这个最大大小,不了解二分查值的移步我的博客: 二分查值法
这里由于目标答案是整数需要做一些改动我的模版代码才能用,c函数做的就是判断在答案为mid时从n个蛋糕中切出的mid大小正方形巧克力够不够k个.
3.ac代码
#include
const int maxn=1e5+5;
const int maxhw=1e5;
int n,k;
int h[maxn],w[maxn];
bool c(int mid){
//判断答案为mid时是否满足条件,满足返回true,否则false
long long sum=0;
for(int i=0;i=k) return true;
return false;
}
void solve(){
scanf("%d%d",&n,&k);
for(int i=0;i1){
mid=(l+r)/2;
if(c(mid)) l=mid;
else r=mid;
}
printf("%d",l);
}
int main(){
solve();
return 0;
} 10.k倍区间
给定一个长度为N的数列,A1, A2, ... AN,如果其中一段连续的子序列Ai, Ai+1, ... Aj(i <= j)之和是K的倍数,我们就称这个区间[i, j]是K倍区间。
你能求出数列中总共有多少个K倍区间吗?
输入
-----
第一行包含两个整数N和K。(1 <= N, K <= 100000)
以下N行每行包含一个整数Ai。(1 <= Ai <= 100000)
输出
-----
输出一个整数,代表K倍区间的数目。
例如,
输入:
5 2
1
2
3
4
5
程序应该输出:
6
资源约定:
峰值内存消耗(含虚拟机) < 256M
CPU消耗 < 2000ms
请严格按要求输出,不要画蛇添足地打印类似:“请您输入...” 的多余内容。
注意:
main函数需要返回0;
只使用ANSI C/ANSI C++ 标准;
不要调用依赖于编译环境或操作系统的特殊函数。
所有依赖的函数必须明确地在源文件中 #include
不能通过工程设置而省略常用头文件。
提交程序时,注意选择所期望的语言类型和编译器类型。
1.题是什么?
题意明了,让你统计在所给长度1e5的数组中,区间和为k的倍数的子区间数目
2.思路
首先,最简单的思路,预处理前缀和,然后做二重循环对将近n*n个子区间一一求余判断这个子区间是否为0,这样的复杂度为O(n^2),会爆.
其次,我的思路,既然我只是要知道区间和为k倍数的子区间数目而不是到底有哪些子区间,那我岂不是只需要对这些子区间做一个记忆化,保留下对我后续计算有用的特征就好了吗,那么一个区间的什么特征对我后续判断其它区间区间和是否能被k整除有决定性作用呢?
tips:(记忆化是什么? 我的理解:记忆化就是以某种方式存储你计算过的数据,后面加以利用,优化计算效率)
自然是这个区间求余k后的结果!
现在,我们知道能通过这个特征去记忆化压缩数据之后,我们该怎么写进算法里并优化统计方法呢?
自然是做一个前缀和结果求余k的数组sum和一个记忆化数组num,记录之前出现过的所有前缀和求余k的结果的情况,这样的话之后当我们统计以a[i]结尾的区间有多少个满足题意时,num[sum[i]]即为答案!,为什么呢? 因为你想如果k=5,sum[i]=3,以a[i]为结尾满足题意的情况数目不就是前面的sum中为3的个数吗,我这一整个区间多了3,那我丢掉某个正好多了3的前缀不就不多了吗!
正好就是我们的num[3],为了维护num数组,每次要num[sum[i]]+=1,将本次情况更新进记忆化数组.
3.知识精炼
有没有注意到为什么num被叫做记忆化数组?因为他里面存的某个数字比如num[2]=3的含义是,前缀和求余结果为2的情况当前有3种,他是一种对于过去所有情况的记忆,仅仅根据最核心的特征进行记忆,这就是记忆化!你,get到feel了吗?
4.ac代码
#include
int maxn=1e5+5;
int maxk=1e5+5;
int main(){
int a[maxn];
int sum[maxn]; //前缀和求余k结果,sum[i]表示(a[0]+a[1]+...+a[i])%k
int num[maxk];//记忆化,num[i]=x表示在当前已出现x个和为i的前缀
int n,k,i;
scanf("%d%d",&n,&k);
for(i=0;i