自然语言处理(NLP)-知识图谱:知识表示学习(知识图嵌入)----> 知识推理【TransE系列模型】【第三方库:OpenKE(清华大学开源)】
一、知识表示学习简介
表示学习又称表征学习( Representation learning) , 主要是利用机器学习技术自动获取每个实体或者关系的向量化表达, 旨在将描述对象表示为低维稠密向量( 即分布式向量) 。
分布式表示的对象均被表示成一个低维的稠密、实值向量, 利用对象在空间的相对距离, 反映它们之间的语义关系。两个对象离得越近, 说明关系越紧密, 两个对象离得越远, 说明它们之间没有太强的关系。
将表示学习应用于知识表示中称之为知识表示学习或知识图嵌入。
知识表示学习是将知识库中的实体和关系嵌入到连续的向量空间中, 以便简化操作, 同时保持知识图谱的结构。
从形式上知识表示学习主要可以分成两类:
- 一种是基于结构的表示学习方法, 主要是从三元组的结构出发学习知识图谱中实体和关系的表示;
- 一种是基于语义的表示学习方法, 通过考虑文本语义来学习实体和关系的表示;
从发展来看, 目前知识表示学习的研究进程主要可以分成两个阶段, 以 2013 年 Borders 等人受Mikolov 发现的词向量空间中存在的平移不变性这一有趣现象的启发, 从而提出的 TransE 模型为分割。
- 在 TransE 之前主要包括结构表示、能量模型、矩阵分解模型等。
- 在 TransE 之后, 人们陆续提出了在其基础上加以改进的新Trans系列模型以及ConvE、ConvKB 和添加卷积的新模型
优势:生成知识表达时能够充分利用知识图谱已有的结构化信息
缺点:建模方法着眼于实体间的直接关联关系,难以引入并利用人类的先验知识实现逻辑推理
二、“知识表示学习”经典方法:TransE
1、TransE 简介
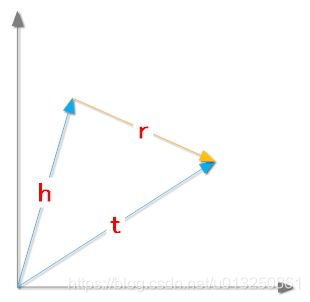
TransE 是知识表示翻译模型中非常经典的方法,Trans 系列方法是在 TransE 的基础上扩展的。 在 TransE 中,实体和关系被映射到向量空间,实体和关系的表示变成了向量之间的表示。 TransE 的主要思想是将三元组 ( h , r , t ) (h,r,t) (h,r,t) 中的关系等价于从头实体向量到尾实体向量的操作过程,这种操作过程称为翻译。

同时,TransE 还对三元组 ( h , r , t ) (h,r,t) (h,r,t) 中的实体和关系映射到向量空间作了一些假设,如上图 所示。 假设每一个三元组 ( h , r , t ) (h,r,t) (h,r,t) 都能表示为 ( h ⃗ , r ⃗ , t ⃗ ) (\vec{h},\vec{r},\vec{t}) (h,r,t) ,其中:
- h ⃗ \vec{h} h 是指头实体的向量表示;
- r ⃗ \vec{r} r 是指关系的向量表示;
- t ⃗ \vec{t} t 是指尾实体的向量表示;
其表示的含义是:在向量空间中,头实体向量 h ⃗ \vec{h} h 加上关系 r ⃗ \vec{r} r 应该等于尾实体向量 t ⃗ \vec{t} t。 如果在向量空间上述关系成立,就说明三元组 ( h , r , t ) (h,r,t) (h,r,t)在 KG 中是成立的。
2、TransE 模型的训练
TransE 在训练中根据三元组已经定义好的关系, 将实体和关系训练成分布式向量表示。作为给定的训练样本, 头实体的向量加上关系向量最接近尾实体向量: ( h ⃗ + r ⃗ ) = t ⃗ (\vec{h}+ \vec{r})=\vec{t} (h+r)=t
根据这种假设,TransE 模型的训练需要满足以下条件:
- 对正样本三元组: ( h ⃗ + r ⃗ ) ≈ t ⃗ (\vec{h}+ \vec{r})≈\vec{t} (h+r)≈t;
- 对负样本三元组: ( h ⃗ + r ⃗ ) ≠ t ⃗ (\vec{h}+ \vec{r})≠\vec{t} (h+r)=t;
其中, ( h ⃗ + r ⃗ ) (\vec{h}+ \vec{r}) (h+r) 与 t ⃗ \vec{t} t 的关系表示近似等价于向量相似度。 对于向量相似度,TransE 采用的方法是计算欧氏距离,得分函数为:
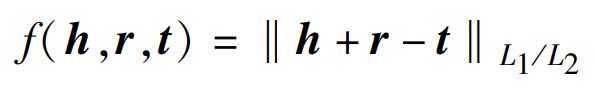
- 得分函数值越小,对正样本三元组越有利;
- 得分函数值越大,对负样本三元组越有利。
接着,TransE 通过损失函数测试表示学习的效果,设计的损失函数为:
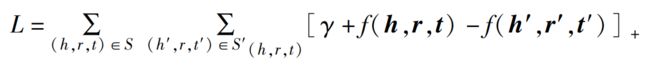
其中:
- S S S 指的是三元组 ( h , r , t ) (h,r,t) (h,r,t) 正样本集合;
- S h , r , t ′ S_{h,r,t}^{'} Sh,r,t′指的是三元组 ( h , r , t ) (h,r,t) (h,r,t) 的负样本集合。
- KG 中三元组 ( h , r , t ) (h,r,t) (h,r,t) 的负样本是通过随机替换头实体 h ⃗ \vec{h} h 或者尾实体 t ⃗ \vec{t} t 进行大量训练得到的。
- [ x ] + [x]_{+} [x]+ 指的是 m a x ( 0 , x ) max(0,x) max(0,x);
- γ γ γ 指的是损失函数中的间隔,这个参数需要满足大于零的条件;
在向量空间中, TransE 经过训练,不断调整 h ⃗ \vec{h} h、 r ⃗ \vec{r} r 和 t ⃗ \vec{t} t, 使 ( h ⃗ + r ⃗ ) (\vec{h}+ \vec{r}) (h+r) 尽可能等于 t ⃗ \vec{t} t, 最后使得损失函数 L L L 达到最小值:

3、TransE的局限性
TransE 的提出是为了解决多关系数据的处理问题,是一种简单、高效的 KG 表示学习方法,并且能够完成多种关系的链接预测任务。 TransE 的简单高效说明了 KG 表示学习方法能够自动且很好地捕捉推理特征,无须人工设计,很适合在大规模复杂的 KG 上推广,是一种有效的 KG 推理手段。
TransE的局限性:
- 尽管有效,TransE 依然存在着表达能力不足的问题,按照关系头尾实体个数比例划分,KG 中的关系可以分为一对一、一对多、多对一、多对多的四种关系。但是 TransE 无法有效处理一对多、多对一、多对多的关系以及自反关系。
- TransE 通过最小化所有关系路径共享的余量损失函数来确定实体、关系和多步关系路径,此设置无法考虑不同关系路径之间的差异。
- TransE模型还存在处理图像信息效果差、负例三元组的质量低、嵌入模型不能快速收敛、泛化能力差、边缘识别能力差等问题
4、TransE 的优化方案
TransE 主要用来学习实体之间存在 1-1 关系的数据, 在描述一对多和多对多关系时具有一定的局限性, 例如一个头实体能够同时映射到两个尾实体上的情况难以准确描述。为了解决 TransE 在处理复杂关系上存在的不足, 研究者在此基础上开发出许多扩展模型, 如用以解决 1-N 和 M-N 关系数据的 TransH, 解决跨空间的 M-N 关系数据的 TransR, 区别如下图所示:

5、TransE 的常用数据集
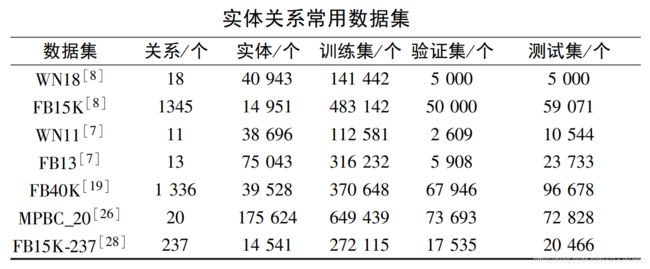
为了科学、一致地评价各类基于 TransE 的表示学习方法的性能, 需要使用标准 的 实 体 关 系 数 据 集 进 行 测 试 和 对比。 目前,常用的实体关系数据集如下表所示:
- WN18,是 WordNet 知识库的一个子集,有关系 18 个,实体40943个;
- FB15K,是 FreeBase 中一个相对稠密的子集,有关系 1345 个,实体 14951 个;
- WN11,是 WordNet 知识库的一个子集,有关系 11 个,实体 38696 个;
- FB13,是 FreeBase 中一个相对稠密的子集,有关系 13 个,实体 75043 个;
- FB40K,是 FreeBase 中一个相对稠密的子集,有关系 1336 个,实体39528个;
- MPBC_20, 有 关 系 20 个, 实 体 175624 个;
- FB15K-237,是 FreeBase 中一个子集,有关系 237 个,实体14541个。
6、基于 TransE 表示学习算法的评价指标
量化表示学习的指标分为:
- 正确实体的平均排名(衡量链接预测的效果)
- 正确实体排在前10名的概率(衡量链接预测的效果)
- 准确率的评价指标(衡量三元组分类的效果)
- 运行时间。 运行时间 t t t 主要比较不同方法的效率,此值越小越好
其中,正确实体的平均排名的评价指标、正确实体排在前10 名的概率评价指标主要是衡量链接预测的效果,准确率的评价指标主要衡量三元组分类的效果。
- 正确实体的平均排名。 正确实体的平均排序得分简称MeanRank,此值越小越好,这是衡量链接预测的重要指标。
- 正确实体排在前 10 名的概率。 正确实体排在前 10 名的概率简称 Hits@10,此值越大越好,这是衡量链接预测的重
要指标。
准确率。 三元组分类任务使用准确率作为评价指标,计算方法为
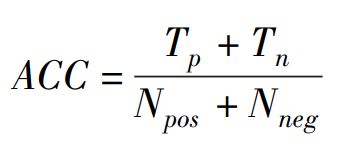
其中:- T p T_p Tp 表示预测正确的正例三元组个数;
- T n T_n Tn 表示预测正确的负例三元组个数;
- N p o s N_{pos} Npos和 N n e g N_{neg} Nneg分别表示训练集中的正例三元组和负例三元组的个数。
ACC 越高,表示模型在三元组分类这一任务上的效果越好
三、Trans系列的各种表示学习算法的分析与比较
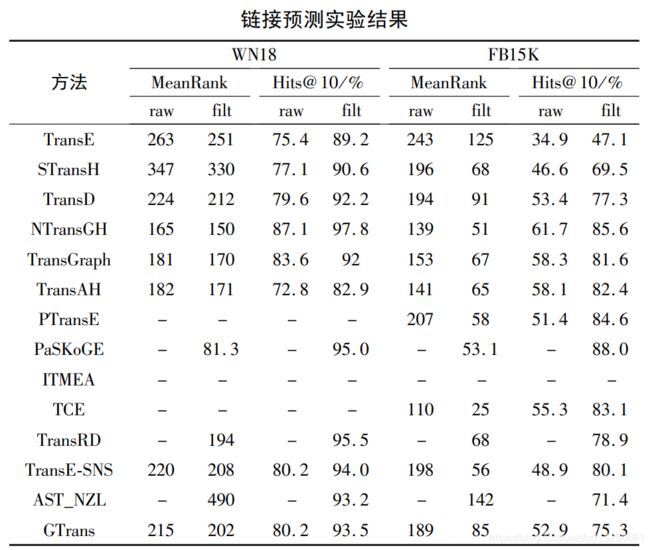
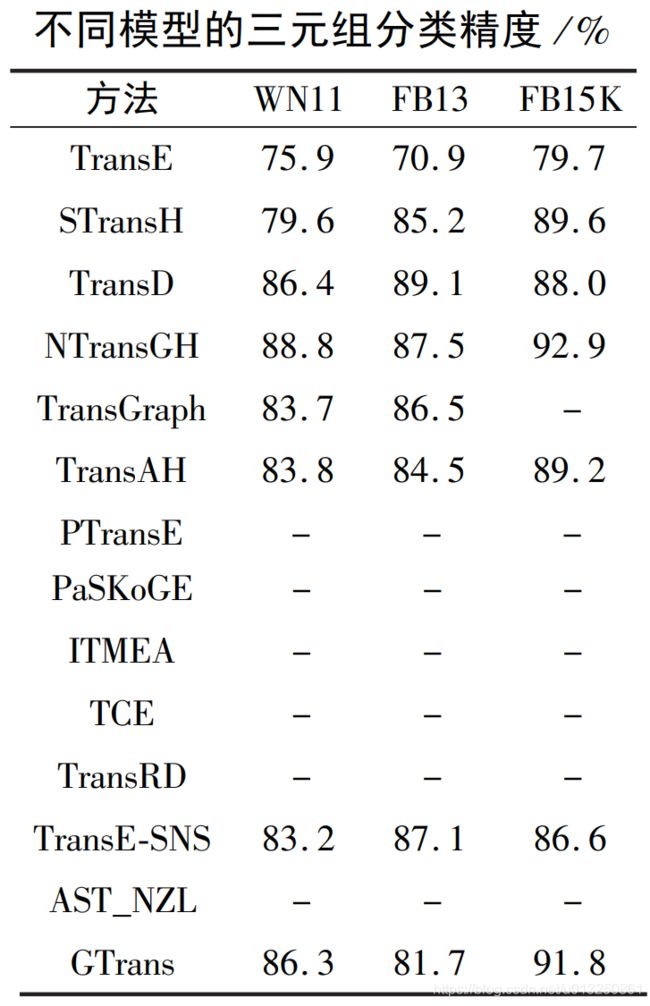
实验的参数设置为:
- 学习速率 α = { 0.002 , 0.005 , 0.01 } α =\{0. 002,0. 005,0. 01\} α={0.002,0.005,0.01},
- 差距 γ = { 0.25 , 0.5 , 1 , 2 } γ =\{0. 25,0. 5,1,2\} γ={0.25,0.5,1,2},
- 表示维度 κ = { 50 , 75 , 100 } κ =\{50,75,100\} κ={50,75,100},
- 权重 η = { 0.05 , 0.0625 , 0.25 , 1.0 } η =\{0. 05,0. 0625,0. 25,1. 0\} η={0.05,0.0625,0.25,1.0},
- 训练批次的大小 B = { 20 , 75 , 200 , 1200 , 4800 } B=\{20,75,200,1200,4800\} B={20,75,200,1200,4800}
四、TransE案例
transE知识图谱补全,FB15K-237数据集
- transE.py训练程序
- graph.py绘制损失函数折线
- test.py验证测试集
1、目的
知识图谱补全是从已知的知识图谱中提取出三元组(h,r,t),为实体和关系进行建模,通过训练出的模型进行链接预测,以达成知识图谱补全的目标。
本文实验采用了FB15K-237数据集,分为训练集和测试集。利用训练集进行transE建模,通过训练为每个实体和关系建立起向量映射,并在测试集中计算MeanRank和Hit10指标进行结果检验。
2、数据集
使用FB15K-237数据集,分为以下四个文件:
- entity2id.txt(实体和id对)
- relation2id.txt(关系和id对)

- train.txt(训练集三元组(实体,实体,关系))
- test.txt(测试集三元组(实体,实体,关系))
3、TransE模型构建
https://github.com/Cpaulyz/BigDataAnalysis/tree/master/Assignment8
3.1 原理
TransE将起始实体,关系,指向实体映射成同一空间的向量,如果(head,relation,tail)存在,那么h+r≈t

目标函数为:
![]()
3.2 算法

3.2.1 初始化
根据维度,为每个实体和关系初始化向量,并归一化
def emb_initialize(self):
relation_dict = {}
entity_dict = {}
for relation in self.relation:
r_emb_temp = np.random.uniform(-6 / math.sqrt(self.embedding_dim),
6 / math.sqrt(self.embedding_dim),
self.embedding_dim)
relation_dict[relation] = r_emb_temp / np.linalg.norm(r_emb_temp, ord=2)
for entity in self.entity:
e_emb_temp = np.random.uniform(-6 / math.sqrt(self.embedding_dim),
6 / math.sqrt(self.embedding_dim),
self.embedding_dim)
entity_dict[entity] = e_emb_temp / np.linalg.norm(e_emb_temp, ord=2)
3.2.2 选取batch
设置 nbatches 为batch数目,batch_size = len(self.triple_list) // nbatches
从训练集中随机选择batch_size个三元组,并随机构成一个错误的三元组S’,进行更新
def train(self, epochs):
nbatches = 400
batch_size = len(self.triple_list) // nbatches
print("batch size: ", batch_size)
for epoch in range(epochs):
start = time.time()
self.loss = 0
# Sbatch:list
Sbatch = random.sample(self.triple_list, batch_size)
Tbatch = []
for triple in Sbatch:
corrupted_triple = self.Corrupt(triple)
if (triple, corrupted_triple) not in Tbatch:
Tbatch.append((triple, corrupted_triple))
self.update_embeddings(Tbatch)
3.2.3 梯度下降
定义距离 d ( x , y ) d(x,y) d(x,y) 来表示两个向量之间的距离,一般情况下,我们会取L1,或者L2 normal。
在这里,我们需要定义一个距离,对于正确的三元组(h,r,t),距离d(h+r,t)越小越好;对于错误的三元组(h’,r,t’),距离d(h’+r,t’)越大越好。

之后,使用梯度下降进行更新
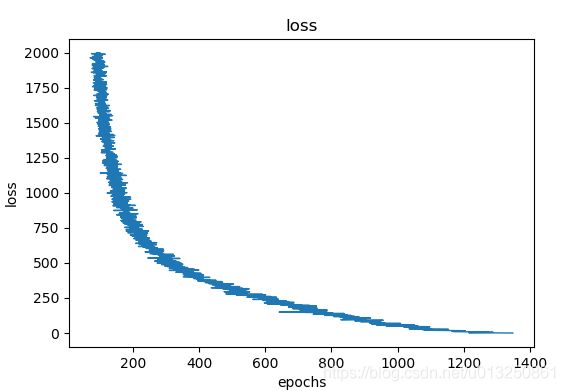
3.3 结果
选择迭代次数2000次,向量维度50,学习率0.01进行训练
损失函数变化如下
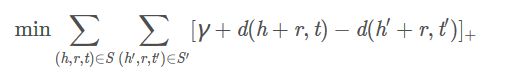
结果存储在entity_50dim 和 relation_50dim 中
4、TransE模型评价指标
4.1 Mean rank
对于测试集的每个三元组,以预测tail实体为例,我们将(h,r,t)中的t用知识图谱中的每个实体来代替,然后通过distance(h, r, t)函数来计算距离,这样我们可以得到一系列的距离,之后按照升序将这些分数排列。
distance(h, r, t)函数值是越小越好,那么在上个排列中,排的越前越好。
现在重点来了,我们去看每个三元组中正确答案也就是真实的t到底能在上述序列中排多少位,比如说t1排100,t2排200,t3排60…,之后对这些排名求平均,mean rank就得到了。
4.2 Hit@10
还是按照上述进行函数值排列,然后去看每个三元组正确答案是否排在序列的前十,如果在的话就计数+1
最终 排在前十的个数/总个数 就是Hit@10
4.3 代码实现
def distance(h, r, t):
h = np.array(h)
r = np.array(r)
t = np.array(t)
s = h + r - t
return np.linalg.norm(s)
def mean_rank(entity_set, triple_list):
triple_batch = random.sample(triple_list, 100)
mean = 0
hit10 = 0
hit3 = 0
for triple in triple_batch:
dlist = []
h = triple[0]
t = triple[1]
r = triple[2]
dlist.append((t, distance(entityId2vec[h], relationId2vec[r], entityId2vec[t])))
for t_ in entity_set:
if t_ != t:
dlist.append((t_, distance(entityId2vec[h], relationId2vec[r], entityId2vec[t_])))
dlist = sorted(dlist, key=lambda val: val[1])
for index in range(len(dlist)):
if dlist[index][0] == t:
mean += index + 1
if index < 3:
hit3 += 1
if index <10:
hit10 += 1
print(index)
break
print("mean rank:", mean / len(triple_batch))
print("hit@3:", hit3 / len(triple_batch))
print("hit@10:", hit10 / len(triple_batch))

4.4 测试结论
经过transE建模后,在测试集的13584个实体,961个关系的 59071个三元组中,测试结果如下:
- mean rank: 353.06935721419984
- hit@3: 0.12181950534103028
- hit@10: 0.2754989758087725
一方面可以看出训练后的结果是有效的,但不是十分优秀,可能与transE模型的局限性有关,transE只能处理一对一的关系,不适合一对多/多对一关系。
5、TransE模型完整代码
transE_L2.py
import codecs
import copy
import math
import random
import time
import numpy as np
entity2id = {} # 主体-id映射
relation2id = {} # 关系-id映射
loss_ls = []
# 生成序列化后得实体数组、关系数组、三元组【用id代表实体、关系】
def data_loader(file):
file_train = file + "train.txt"
file_entity2id = file + "entity2id.txt"
file_relation2id = file + "relation2id.txt"
# 将entity2id.txt转为【entity~id对】字典;将relation2id.txt转为【relation~id对】字典
with open(file_entity2id, 'r') as f1, open(file_relation2id, 'r') as f2:
lines1 = f1.readlines() # 每一行一个entity~id对
lines2 = f2.readlines() # 每一行一个relation~id对
for line in lines1:
line = line.strip().split('\t')
if len(line) != 2:
continue
entity2id[line[0]] = line[1] # 【entity~id对】字典
for line in lines2:
line = line.strip().split('\t')
if len(line) != 2:
continue
relation2id[line[0]] = line[1] # 【relation~id对】字典
entity_set = set()
relation_set = set()
triple_list = []
# 将train.txt训练集序列化【将entity、relation都转为id】
with codecs.open(file_train, 'r') as f:
content = f.readlines()
for line in content:
triple = line.strip().split("\t")
if len(triple) != 3:
continue
h_ = entity2id[triple[0]]
t_ = entity2id[triple[1]]
r_ = relation2id[triple[2]]
triple_list.append([h_, t_, r_])
entity_set.add(h_)
entity_set.add(t_)
relation_set.add(r_)
return entity_set, relation_set, triple_list
# L2范数
def distanceL2(h, r, t):
return np.sum(np.square(h + r - t)) # 为方便求梯度,去掉sqrt
class TransE:
def __init__(self, entity_set, relation_set, triple_list, embedding_dim=50, learning_rate=0.01, margin=1):
self.embedding_dim = embedding_dim
self.learning_rate = learning_rate
self.margin = margin
self.entity = entity_set # 实体的id数组
self.relation = relation_set # 关系的id数组
self.triple_list = triple_list # 实体-关系-实体的id三元组
self.loss = 0
# 将实体数组、关系数组中的id随机转为50维的embedding,然后所有(id~embedding)对组成字典【{id:embedding,...}】
def emb_initialize(self):
relation_dict = {}
entity_dict = {}
for relation in self.relation:
r_emb_temp = np.random.uniform(low=-6 / math.sqrt(self.embedding_dim), high=6 / math.sqrt(self.embedding_dim), size=self.embedding_dim) # 从一个均匀分布[low,high)中随机采样
r_emb_temp = r_emb_temp / np.linalg.norm(r_emb_temp, ord=2) # np.linalg.norm():求范数 【r_emb_temp.shape = (50,)】
# print("r_emb_temp.shape = {0}----r_emb_temp = \n{1}".format(r_emb_temp.shape, r_emb_temp))
relation_dict[relation] = r_emb_temp
for entity in self.entity:
e_emb_temp = np.random.uniform(-6 / math.sqrt(self.embedding_dim), 6 / math.sqrt(self.embedding_dim), self.embedding_dim) # 从一个均匀分布[low,high)中随机采样
e_emb_temp = e_emb_temp / np.linalg.norm(e_emb_temp, ord=2) # np.linalg.norm():求范数 【r_emb_temp.shape = (50,)】
entity_dict[entity] = e_emb_temp
self.relation = relation_dict
self.entity = entity_dict
def train(self, epochs):
print("=" * 50, "开始训练", "=" * 50)
nbatches = 400 # 设置总批次数量
batch_size = len(self.triple_list) // nbatches # 批次大小
print("len(self.triple_list) = {0}----nbatches = {1}----batch_size = {2}".format(len(self.triple_list), nbatches, batch_size))
for epoch in range(epochs):
print("-" * 50, "epoch = {0}".format(epoch), "-" * 50)
start = time.time()
self.loss = 0
Sbatch = random.sample(self.triple_list, batch_size) # 从triple_list三元组list中随机抽取batch_size个样本
print("本批次的所有正样本:len(Sbatch) = {0}----Sbatch[:3] = {1}".format(len(Sbatch), Sbatch[:3]))
Tbatch = [] # 保存本次batch的所有正负三元组样本对[(triple01, corrupted_triple01),(triple02, corrupted_triple02),...]
for triple in Sbatch:
corrupted_triple = self.Corrupt(triple)
if (triple, corrupted_triple) not in Tbatch:
Tbatch.append((triple, corrupted_triple))
self.update_embeddings(Tbatch)
print("本批次的所有正负三元组样本对:len(Tbatch) = {0}----Tbatch[:3] = {1}".format(len(Tbatch), Tbatch[:3]))
end = time.time()
print("epoch: ", epoch, "cost time: %s" % (round((end - start), 3)))
print("loss: ", self.loss)
loss_ls.append(self.loss)
# 保存临时结果
if epoch % 20 == 0:
with codecs.open("./saved_model/entity_temp", "w") as f_e:
for e in self.entity.keys():
f_e.write(e + "\t")
f_e.write(str(list(self.entity[e])))
f_e.write("\n")
with codecs.open("./saved_model/relation_temp", "w") as f_r:
for r in self.relation.keys():
f_r.write(r + "\t")
f_r.write(str(list(self.relation[r])))
f_r.write("\n")
print("写入文件...")
with codecs.open("./saved_model/entity_50dim", "w") as f1:
for e in self.entity.keys():
f1.write(e + "\t")
f1.write(str(list(self.entity[e])))
f1.write("\n")
with codecs.open("./saved_model/relation_50dim", "w") as f2:
for r in self.relation.keys():
f2.write(r + "\t")
f2.write(str(list(self.relation[r])))
f2.write("\n")
with codecs.open("./saved_model/loss", "w") as f3:
f3.write(str(loss_ls))
print("写入完成")
# 通过训练集的一个正样本三元组随机生成一个负样本三元组
def Corrupt(self, triple):
corrupted_triple = copy.deepcopy(triple)
seed = random.random()
if seed > 0.5: # 替换head
rand_head = triple[0]
while rand_head == triple[0]:
rand_head = random.sample(self.entity.keys(), 1)[0]
corrupted_triple[0] = rand_head
else: # 替换tail
rand_tail = triple[1]
while rand_tail == triple[1]:
rand_tail = random.sample(self.entity.keys(), 1)[0]
corrupted_triple[1] = rand_tail
return corrupted_triple
# 更新训练集本批次所有实体、关系的embedding表示。
def update_embeddings(self, Tbatch):
copy_entity = copy.deepcopy(self.entity)
copy_relation = copy.deepcopy(self.relation)
# triple:正样本三元组、corrupted_triple:负样本三元组---->【triple = ['5808', '8393', '802'];corrupted_triple=['7170', '8393', '802']】
for triple, corrupted_triple in Tbatch:
# 取copy里的vector累积更新【用于保存更新后得embedding】
h_correct_embedding_update = copy_entity[triple[0]] # 三元组正样本的头实体的embedding:h 【shape = (50,)】
t_correct_embedding_update = copy_entity[triple[1]] # 三元组正样本的尾实体的embedding:t 【shape = (50,)】
h_corrupt_embedding_update = copy_entity[corrupted_triple[0]] # 三元组负样本的头实体的embedding:h 【shape = (50,)】
t_corrupt_embedding_update = copy_entity[corrupted_triple[1]] # 三元组负样本的尾实体的embedding:h 【shape = (50,)】
relation_embedding_update = copy_relation[triple[2]] # 三元组样本的关系的embedding:r 【shape = (50,)】,正样本、负样本三元组的关系一致,没有变化。
# 取原始的embedding计算当前梯度
h_correct_embedding = self.entity[triple[0]] # 【shape = (50,)】
t_correct_embedding = self.entity[triple[1]] # 【shape = (50,)】
h_corrupt_embedding = self.entity[corrupted_triple[0]] # 【shape = (50,)】
t_corrupt_embedding = self.entity[corrupted_triple[1]] # 【shape = (50,)】
relation_embedding = self.relation[triple[2]] # 【shape = (50,)】
dist_correct = distanceL2(h_correct_embedding, relation_embedding, t_correct_embedding) # # 计算正样本三元组(h,t,r)的L2距离
dist_corrupt = distanceL2(h_corrupt_embedding, relation_embedding, t_corrupt_embedding) # 计算负样本三元组(h,t,r)的L2距离
err = self.hinge_loss(dist_correct, dist_corrupt) # 计算当前样本的err
# print("dist_correct = {0}----dist_corrupt = {1}----err = self.hinge_loss(dist_correct, dist_corrupt) = {2}".format(dist_correct, dist_corrupt, err))
if err > 0:
self.loss += err
# 计算正样本三元组(h,t,r)的梯度【y = (h + r - t)^2】
grad_pos = 2 * (h_correct_embedding + relation_embedding - t_correct_embedding) # 使用L2距离时:正样本的梯度【grad_pos.shape = (50,)】
# 计算负样本三元组(h,t,r)的梯度
grad_neg = 2 * (h_corrupt_embedding + relation_embedding - t_corrupt_embedding) # 使用L2距离时:负样本的梯度【grad_neg.shape = (50,)】
# 正样本三元组梯度下降
h_correct_embedding_update = h_correct_embedding_update - self.learning_rate * grad_pos # head系数为正,减梯度;
t_correct_embedding_update = t_correct_embedding_update - (-1) * self.learning_rate * grad_pos # tail系数为负,加梯度
# 负样本三元组梯度下降【corrupt项整体为负,因此符号与correct相反】
if triple[0] == corrupted_triple[0]: # 若替换的是尾实体,则头实体再次更新
h_correct_embedding_update -= (-1) * self.learning_rate * grad_neg
t_corrupt_embedding_update -= self.learning_rate * grad_neg
elif triple[1] == corrupted_triple[1]: # 若替换的是头实体,则尾实体再次更新
h_corrupt_embedding_update -= (-1) * self.learning_rate * grad_neg
t_correct_embedding_update -= self.learning_rate * grad_neg
# relation更新两次
relation_embedding_update -= self.learning_rate * grad_pos
relation_embedding_update -= (-1) * self.learning_rate * grad_neg
# batch norm
for i in copy_entity.keys():
copy_entity[i] /= np.linalg.norm(copy_entity[i])
for i in copy_relation.keys():
copy_relation[i] /= np.linalg.norm(copy_relation[i])
# 达到批量更新的目的
self.entity = copy_entity
self.relation = copy_relation
def hinge_loss(self, dist_correct, dist_corrupt):
return max(0, dist_correct - dist_corrupt + self.margin)
if __name__ == '__main__':
file1 = ".\\data\\"
entity_set, relation_set, triple_list = data_loader(file1)
print("load file...")
print("Complete load. entity : %d , relation : %d , triple : %d" % (
len(entity_set), len(relation_set), len(triple_list)))
transE = TransE(entity_set, relation_set, triple_list, embedding_dim=50, learning_rate=0.01, margin=1)
transE.emb_initialize()
transE.train(epochs=2000)
打印结果:
load file...
Complete load. entity : 14951 , relation : 1345 , triple : 483142
================================================== 开始训练 ==================================================
len(self.triple_list) = 483142----nbatches = 400----batch_size = 1207
-------------------------------------------------- epoch = 0 --------------------------------------------------
本批次的所有正样本:len(Sbatch) = 1207----Sbatch[:3] = [['3289', '12041', '589'], ['4253', '7891', '1286'], ['5903', '11747', '429']]
本批次的所有正负三元组样本对:len(Tbatch) = 1207----Tbatch[:3] = [(['3289', '12041', '589'], ['5546', '12041', '589']), (['4253', '7891', '1286'], ['4253', '157', '1286']), (['5903', '11747', '429'], ['5903', '4014', '429'])]
epoch: 0 cost time: 0.604
loss: 1220.1603333370822
-------------------------------------------------- epoch = 1 --------------------------------------------------
本批次的所有正样本:len(Sbatch) = 1207----Sbatch[:3] = [['10021', '3046', '877'], ['5411', '13447', '1053'], ['5030', '12084', '978']]
本批次的所有正负三元组样本对:len(Tbatch) = 1207----Tbatch[:3] = [(['10021', '3046', '877'], ['14950', '3046', '877']), (['5411', '13447', '1053'], ['7152', '13447', '1053']), (['5030', '12084', '978'], ['5418', '12084', '978'])]
epoch: 1 cost time: 0.587
loss: 1193.8297206555735
-------------------------------------------------- epoch = 2 --------------------------------------------------
本批次的所有正样本:len(Sbatch) = 1207----Sbatch[:3] = [['16', '7479', '619'], ['2565', '13857', '65'], ['9047', '932', '516']]
本批次的所有正负三元组样本对:len(Tbatch) = 1207----Tbatch[:3] = [(['16', '7479', '619'], ['13403', '7479', '619']), (['2565', '13857', '65'], ['689', '13857', '65']), (['9047', '932', '516'], ['9047', '11409', '516'])]
epoch: 2 cost time: 0.652
loss: 1183.5007631962042
-------------------------------------------------- epoch = 3 --------------------------------------------------
本批次的所有正样本:len(Sbatch) = 1207----Sbatch[:3] = [['1648', '9468', '93'], ['5617', '6358', '199'], ['6981', '6432', '193']]
本批次的所有正负三元组样本对:len(Tbatch) = 1207----Tbatch[:3] = [(['1648', '9468', '93'], ['1648', '10950', '93']), (['5617', '6358', '199'], ['5617', '10684', '199']), (['6981', '6432', '193'], ['6981', '7416', '193'])]
epoch: 3 cost time: 0.578
loss: 1223.3487675734252
-------------------------------------------------- epoch = 4 --------------------------------------------------
本批次的所有正样本:len(Sbatch) = 1207----Sbatch[:3] = [['4219', '10573', '597'], ['10525', '2094', '597'], ['13817', '8142', '805']]
本批次的所有正负三元组样本对:len(Tbatch) = 1207----Tbatch[:3] = [(['4219', '10573', '597'], ['14071', '10573', '597']), (['10525', '2094', '597'], ['10479', '2094', '597']), (['13817', '8142', '805'], ['3755', '8142', '805'])]
epoch: 4 cost time: 0.693
loss: 1184.1080661918454
-------------------------------------------------- epoch = 5 --------------------------------------------------
...
...
evaluate.py
import codecs
import random
import numpy as np
entity2id = {}
relation2id = {}
entityId2vec = {} # {5465:[0.12700147248907442,...,0.023727625960346894, -0.14198285344258], 6929: [0.1995235465355577,..., -0.0740944438429173, -0.06169414740012142],...}
relationId2vec = {}
# 生成序列化后得实体数组、关系数组、三元组【用id代表实体、关系】
def data_loader(file):
file_train = file + "train.txt"
file_entity2id = file + "entity2id.txt"
file_relation2id = file + "relation2id.txt"
# 将entity2id.txt转为【entity~id对】字典;将relation2id.txt转为【relation~id对】字典
with open(file_entity2id, 'r') as f1, open(file_relation2id, 'r') as f2:
lines1 = f1.readlines() # 每一行一个entity~id对
lines2 = f2.readlines() # 每一行一个relation~id对
for line in lines1:
line = line.strip().split('\t')
if len(line) != 2:
continue
entity2id[line[0]] = line[1] # 【entity~id对】字典
for line in lines2:
line = line.strip().split('\t')
if len(line) != 2:
continue
relation2id[line[0]] = line[1] # 【relation~id对】字典
entity_set = set()
relation_set = set()
triple_list = []
# 将train.txt训练集序列化【将entity、relation都转为id】
with codecs.open(file_train, 'r') as f:
content = f.readlines()
for line in content:
triple = line.strip().split("\t")
if len(triple) != 3:
continue
h_ = entity2id[triple[0]]
t_ = entity2id[triple[1]]
r_ = relation2id[triple[2]]
triple_list.append([h_, t_, r_])
entity_set.add(h_)
entity_set.add(t_)
relation_set.add(r_)
return entity_set, relation_set, triple_list
# 加载transE模型【即:加载优化到最优的id2vec的embedding】
def transE_loader(file):
file1 = file + "./saved_model/entity_50dim"
file2 = file + "./saved_model/relation_50dim"
# 加载实体id的embedding
with codecs.open(file1, 'r') as f:
content = f.readlines()
for line in content:
line = line.strip().split("\t")
entityId2vec[line[0]] = eval(line[1])
# 加载关系id的embedding
with codecs.open(file2, 'r') as f:
content = f.readlines()
for line in content:
line = line.strip().split("\t")
relationId2vec[line[0]] = eval(line[1])
def distance(h, r, t):
h = np.array(h)
r = np.array(r)
t = np.array(t)
s = h + r - t
return np.linalg.norm(s) # np.linalg.norm():求范数
def evaluate(entity_set, triple_list):
triple_batch = triple_list[:10]
mean = 0
hit10 = 0
hit3 = 0
for index, triple in enumerate(triple_batch):
print("-" * 20, "本batch的第{0}个三元组:{1}".format(index, triple), "-" * 20)
dlist = []
h = triple[0]
t = triple[1]
r = triple[2]
print("h = {0},t = {1},r = {2}".format(h, t, r))
h_embedding, t_embedding, r_embedding = entityId2vec[h], entityId2vec[t], relationId2vec[r]
distance_of_htr = distance(h_embedding, r_embedding, t_embedding)
print("使用本三元组target的t所计算的距离:distance_of_htr = {0}".format(distance_of_htr))
dlist.append((t, distance_of_htr))
print("dlist = {0}".format(dlist))
for t_ in entity_set:
if t_ != t:
t__embedding = entityId2vec[t_]
distance_of_ht_r = distance(h_embedding, r_embedding, t__embedding)
dlist.append((t_, distance_of_ht_r))
dlist = sorted(dlist, key=lambda val: val[1])
print("所有的t与本三元组中的h,r组成的三元组所计算的距离:len(dlist) = {0}----dlist[:5] = {1}".format(len(dlist), dlist[:5]))
for index in range(len(dlist)):
if dlist[index][0] == t:
mean += index + 1
if index < 3:
hit3 += 1
if index < 10:
hit10 += 1
print("本三元组计算的rank = {0}".format(index))
break
print("mean rank:", mean / len(triple_batch))
print("hit@3:", hit3 / len(triple_batch))
print("hit@10:", hit10 / len(triple_batch))
if __name__ == '__main__':
file1 = ".\\data\\"
print("load file...")
entity_set, relation_set, triple_list = data_loader(file1)
print("Complete load. entity : %d , relation : %d , triple : %d" % (len(entity_set), len(relation_set), len(triple_list)))
print("load transE vec...")
transE_loader(".\\")
print("Complete load.")
evaluate(entity_set, triple_list)
打印结果:
load file...
Complete load. entity : 14951 , relation : 1345 , triple : 483142
load transE vec...
Complete load.
-------------------- 本batch的第0个三元组:['9447', '5030', '352'] --------------------
h = 9447,t = 5030,r = 352
使用本三元组target的t所计算的距离:distance_of_htr = 1.083757906019471
dlist = [('5030', 1.083757906019471)]
所有的t与本三元组中的h,r组成的三元组所计算的距离:len(dlist) = 14951----dlist[:5] = [('13812', 0.8776503392958249), ('756', 0.9273324034757694), ('9700', 0.9779209910384178), ('9447', 1.0), ('626', 1.0605778520764824)]
本三元组计算的rank = 6
-------------------- 本batch的第1个三元组:['4886', '13680', '319'] --------------------
h = 4886,t = 13680,r = 319
使用本三元组target的t所计算的距离:distance_of_htr = 1.3356357584885041
dlist = [('13680', 1.3356357584885041)]
所有的t与本三元组中的h,r组成的三元组所计算的距离:len(dlist) = 14951----dlist[:5] = [('4886', 1.0), ('11505', 1.0527638308342866), ('5197', 1.0962477302665679), ('5371', 1.0982378830548576), ('12587', 1.1263095461543984)]
本三元组计算的rank = 594
-------------------- 本batch的第2个三元组:['7374', '13062', '648'] --------------------
h = 7374,t = 13062,r = 648
使用本三元组target的t所计算的距离:distance_of_htr = 1.0974804677802559
dlist = [('13062', 1.0974804677802559)]
所有的t与本三元组中的h,r组成的三元组所计算的距离:len(dlist) = 14951----dlist[:5] = [('1732', 0.7365846221743828), ('2485', 0.7628052954201915), ('12983', 0.7656225929103128), ('2643', 0.768594305567245), ('10091', 0.7824812670680343)]
本三元组计算的rank = 920
-------------------- 本batch的第3个三元组:['11436', '7445', '143'] --------------------
h = 11436,t = 7445,r = 143
使用本三元组target的t所计算的距离:distance_of_htr = 1.363459376056827
dlist = [('7445', 1.363459376056827)]
所有的t与本三元组中的h,r组成的三元组所计算的距离:len(dlist) = 14951----dlist[:5] = [('11436', 0.9999999999999999), ('14587', 1.1515232675210472), ('11945', 1.159920939147419), ('7894', 1.1654918854597758), ('11124', 1.174576429168093)]
本三元组计算的rank = 133
-------------------- 本batch的第4个三元组:['12510', '4746', '381'] --------------------
h = 12510,t = 4746,r = 381
使用本三元组target的t所计算的距离:distance_of_htr = 1.0565318480240966
dlist = [('4746', 1.0565318480240966)]
所有的t与本三元组中的h,r组成的三元组所计算的距离:len(dlist) = 14951----dlist[:5] = [('2119', 0.9221769627137015), ('7555', 0.9973020208909482), ('12510', 1.0), ('6547', 1.0038303141576388), ('4746', 1.0565318480240966)]
本三元组计算的rank = 4
-------------------- 本batch的第5个三元组:['6547', '4439', '246'] --------------------
h = 6547,t = 4439,r = 246
使用本三元组target的t所计算的距离:distance_of_htr = 1.0342768486038687
dlist = [('4439', 1.0342768486038687)]
所有的t与本三元组中的h,r组成的三元组所计算的距离:len(dlist) = 14951----dlist[:5] = [('6155', 0.8932934458889678), ('3199', 0.8963800093990113), ('744', 0.9090436176492527), ('11441', 0.9392155058572145), ('3241', 0.9421447562333829)]
本三元组计算的rank = 70
-------------------- 本batch的第6个三元组:['5281', '10596', '579'] --------------------
h = 5281,t = 10596,r = 579
使用本三元组target的t所计算的距离:distance_of_htr = 1.0916200834931573
dlist = [('10596', 1.0916200834931573)]
所有的t与本三元组中的h,r组成的三元组所计算的距离:len(dlist) = 14951----dlist[:5] = [('5281', 0.9999999999999999), ('12618', 1.089365452545339), ('10596', 1.0916200834931573), ('12432', 1.1043604068434179), ('1748', 1.1224552475584666)]
本三元组计算的rank = 2
-------------------- 本batch的第7个三元组:['11562', '6580', '751'] --------------------
h = 11562,t = 6580,r = 751
使用本三元组target的t所计算的距离:distance_of_htr = 1.1937596560209756
dlist = [('6580', 1.1937596560209756)]
所有的t与本三元组中的h,r组成的三元组所计算的距离:len(dlist) = 14951----dlist[:5] = [('5592', 0.8474301826832381), ('14361', 0.8782211329111241), ('2547', 0.8815793060566249), ('2768', 0.8931195478639203), ('10247', 0.9230403606248357)]
本三元组计算的rank = 992
-------------------- 本batch的第8个三元组:['3015', '2119', '387'] --------------------
h = 3015,t = 2119,r = 387
使用本三元组target的t所计算的距离:distance_of_htr = 1.1937675706017288
dlist = [('2119', 1.1937675706017288)]
所有的t与本三元组中的h,r组成的三元组所计算的距离:len(dlist) = 14951----dlist[:5] = [('3015', 1.0), ('2796', 1.0716400156542993), ('9515', 1.0810341006943935), ('7555', 1.0986414894068919), ('10715', 1.1188156203580466)]
本三元组计算的rank = 17
-------------------- 本batch的第9个三元组:['8641', '6183', '1226'] --------------------
h = 8641,t = 6183,r = 1226
使用本三元组target的t所计算的距离:distance_of_htr = 1.302097665688129
dlist = [('6183', 1.302097665688129)]
所有的t与本三元组中的h,r组成的三元组所计算的距离:len(dlist) = 14951----dlist[:5] = [('12967', 0.8481174438791005), ('14303', 0.9177587968031853), ('5650', 0.9407730352234447), ('5262', 0.9407944480976681), ('9267', 0.9507680095882802)]
本三元组计算的rank = 1223
mean rank: 397.1
hit@3: 0.1
hit@10: 0.3
五、第三方库
清华大学开源知识图谱库:OpenKE:http://139.129.163.161/home
使用说明:[OpenKE] Knowledge Embedding PyTorch版本
参考资料:
清华大学知识表示学习开源项目:An Open-source Framework for Knowledge Embedding
知识图谱中的关系推理
Translating Embeddings for Modeling Multi-relational Data
知识表示学习Trans系列梳理(论文+代码)
[OpenKE] Knowledge Embedding PyTorch版本
transE知识图谱补全,FB15K-237数据集(python实现)
论文笔记(一):TransE论文详解及代码复现