建议阅读方式
可前往语雀阅读,体验更好:微服务基础设施搭建必做的 4 件事
背景介绍
随着流量与业务复杂度的日益增加,包括敏捷研发理论的普及,大型网站往往采用分治的方式,将整个系统划分为若干个内部相对自治的子模块
比如电商系统可以划分为订单、物流、商家、用户等业务模块,各模块交织形成整个业务体系,各个模块也独立的开发、运维:
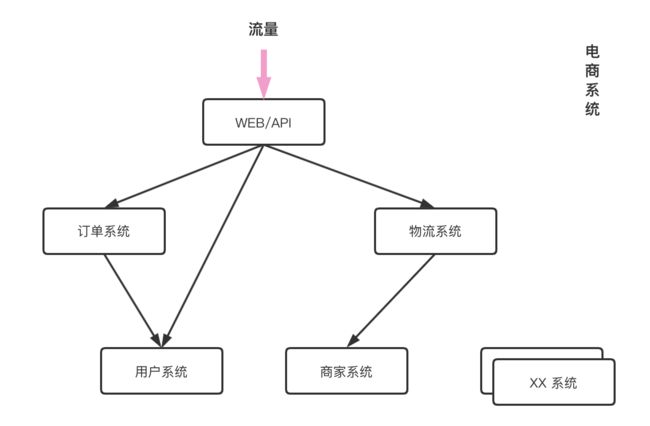
改造后无状态服务层的通信与运营,需要一系列的新组件的支撑才可以实现,这是微服务改造的基础,也是决定成败的一步
对有状态的存储层而言,往往采用独立命名空间,可以是集群、机器、数据表等,也就可以先根据命名空间隔离过渡并逐渐改造
本文主要分享的是服务层改造微服务基础设施的要点,整体也可以总结为如下 4 个问题:
1. 分布式系统中进程间如何通信
微服务改造后,业务进程部署在不同节点上,单体应用中进程内通过函数调用实现的业务逻辑,会转化为跨网络的调用
这个问题的解决方案是提供对业务透明的分布式通信的能力,也就是 Remote Procedure Call,简称为 RPC;同时约束服务像“类”一样定义接口,在 RPC 通信框架的助力下,可以像调用本地方法一样方便地进行远程服务调用
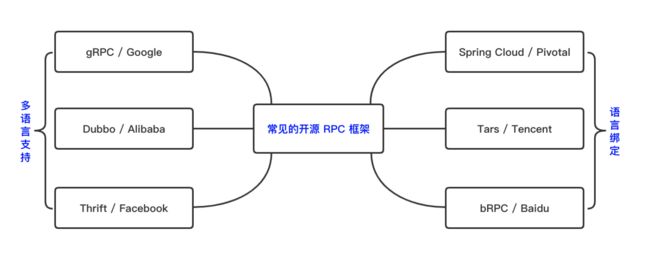
但从零开发可应用于生产环境的 RPC 框架的成本较高,对中小团队而言,建议选择开源的 RPC 框架,逐渐根据特定需求进行定制迭代
RPC 框架选型
在做选型时,除社区活跃度、文档丰富度外,建议重点关注以下几个方面:
- 公司的多语言诉求
完成微服务改造后的各团队往往独立演进,自治和自主往往引发不同语言的技术多样性的问题,如果对跨语言服务通信有强诉求,尽量要避开语言绑定的 RPC 框架,像 gRPC、Thrift、Dubbo 都支持国内最主流的语言
如果限定于一种语言,也可以选择特定语言的 RPC 框架,如 Spring Cloud、bRPC、Tars 等
- 性能方面的考虑
RPC 框架性能差异往往体现在序列化协议方面,同一个框架采用不同的序列化算法时,吞吐极限差异可达数倍
如 HTTP、Hessian 等序列化性能不突出的协议,对应用的负载会成为瓶颈点,建议规避或趁早替换,像 Spring Cloud、Dubbo 都提供了替换序列化算法的能力
- 业务长期演进中通信框架替换成本
尤其要结合公有云的使用情况以及未来的迁移计划来考虑
- 考虑通信框架背后的微服务组件生态是否完整
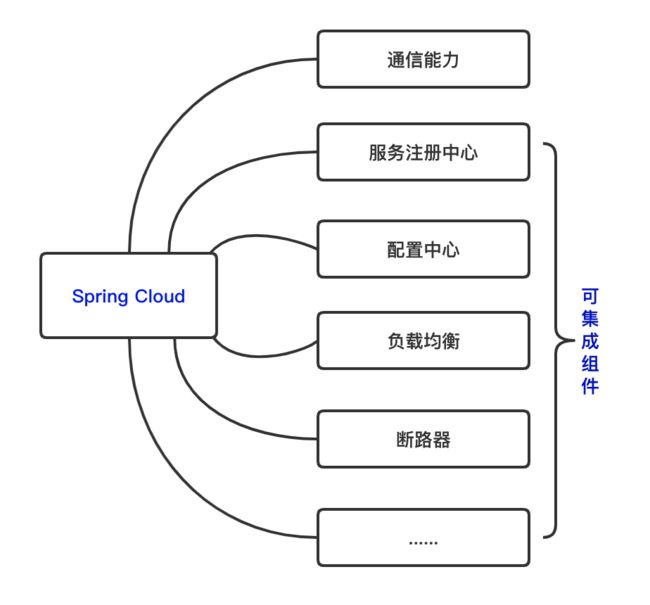
微服务基础设施中,有配置管理、服务注册发现、断路器等众多子系统,追求快速上手还是建议采用满足构建微服务所需的解决方案的产品
对于初创产品而言,复杂的架构维护成本还是非常高的,比如 Spring Cloud 除通信功能外,也打通了服务注册中心、配置中心、负载均衡、断路器等可集成组件
此外,RESTful API 也是较为流行的技术,但它的语义模型限制较多,在内网复杂业务交互方面存在局限,包括在高性能场景下异步的处理也非常复杂,个人建议如果不作为对外服务,要慎重选择
Service Mesh 也是微服务最火的方向之一,但目前依然不够成熟,除了在公有云做一些探索和尝试或团队技术积累较多的情况下,个人不建议直接引入到生产环境
RPC 通信框架 4 个实践经验
介绍完技术选型后,再介绍下 RPC 通信框架的 4 个实践经验:
- 公司作战需要规范
大到微服务治理体系,小到通讯框架的内部协议,极其建议大家趁早做标准化与规范化
标准化具备业务持续快速演进与融合的长远意义,规避未来的异构子系统交互复杂性引入的高额成本
- 具备服务保护机制
主要体现在不因上下游异常而拖垮自己:
- 一是要具备过载保护的能力,比如说我们可以针对节点、接口、各调用端做限流
- 二是要对依赖方的异常做故障压制,比如说我们要弱化依赖,降级时采用默认值、降级异常、mock 对象等
- 健壮的集群间容错策略
要建设健壮的集群间容错策略,以应对不同的场景,主要体现在两个方面:
- 流量容错策略,如 failfast、failover、backup request 等
- 调用端对服务端节点状态的感知,除了依赖注册中心的节点存活判定结果,也要具备框架视角端到端的心跳探活检测能力,以保证注册中心异常时服务依然可用
- 多样的调用方式支持多样的业务场景
如异步调用、Oneway 调用、泛化调用等
2. 服务集群中节点和流量如何管理
在微服务架构当中,节点管理与流量管理一般是通信框架与注册中心协同实现的
注册中心相关机制
注册中心是服务端节点的“地址服务”,它会实时管理每个服务名与其节点的映射关系,它具体解决的内容可以从 3 个问题、3 种场景谈起:
- 问题 1:单体应用中函数调用是基于内存中函数地址寻址,服务化后调用端如何找到对端节点?
- 问题 2:服务端扩容后,调用端如何自动发现新的节点并进行负载均衡?
- 问题 3:服务端个别节点宕机,如何自动使其失效避免调用端继续调用报错?
- 场景 1:单节点业务异常时,需要快速禁用异常节点
- 场景 2:对于服务发布时灰度的节点,期望降低其流量比例
- 场景 3:业务在多地部署时,期望支持同地域优先等个性化的路由策略
具体机制可以用 4 张图来说明:
服务注册中心原理
第一张图是注册中心的基本原理,它对应的是问题 1
问题 1:单体应用中函数调用是基于内存中函数地址寻址,服务化后调用端如何找到对端节点?
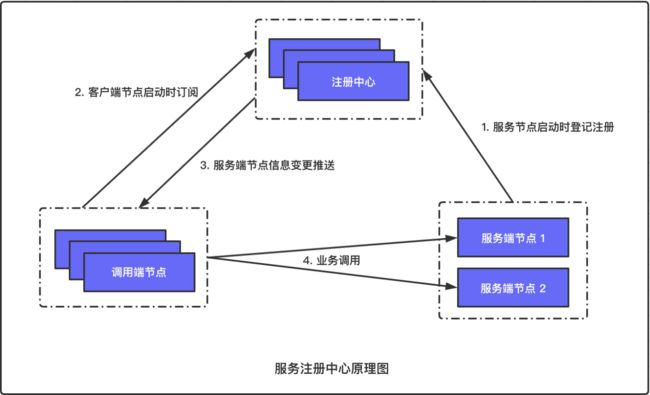
这里有 4 个环节
- 第一个环节,提供服务的各节点启动时向注册中心系统登记,一般是 Service Name、IP、port 等信息
注册中心管理 Service Name 与对应的若干个 IP、port 的关系
- 第二个环节,调用端各节点启动时向注册中心询问自身依赖 Service Name 的信息,注册中心会将对应的 IP、port 下发
- 第三个环节,注册中心需要记录每个调用端所关注的 Service Name,当关注的 ServiceName 下节点变更时也会主动通知订阅的调用端进行更新
- 第四个环节,调用端根据注册中心提供的对端节点信息,建立连接并进行业务通信
服务端节点扩容原理
第二张图,讲的是服务端扩容原理,它对应的是问题 2
问题 2:服务端扩容后,调用端如何自动发现新的节点并进行负载均衡?
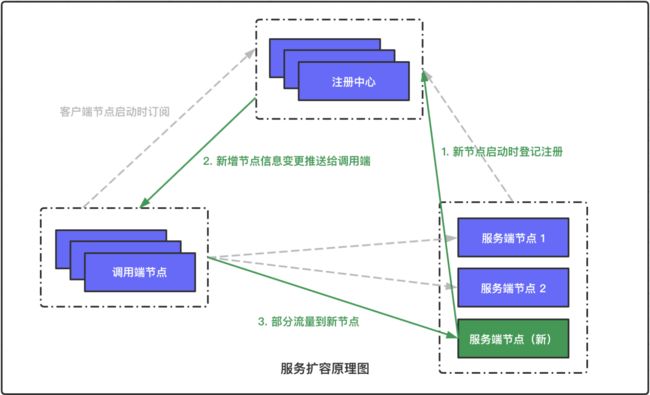
每次新节点启动登记时,注册中心根据登记节点的 Service Name,筛选出所有关注该 Service Name 的所有调用端节点,并将新增的节点信息也下发下去,感知到变更信息的节点即时建立连接,并分配部分流量到新节点
异常节点摘除原理
第三张图,讲的是异常节点摘除的原理,它对应的是问题 3 和场景 1
问题 3:服务端个别节点宕机,如何自动使其失效避免调用端继续调用报错?
场景 1:单节点业务异常时,需要快速禁用异常节点
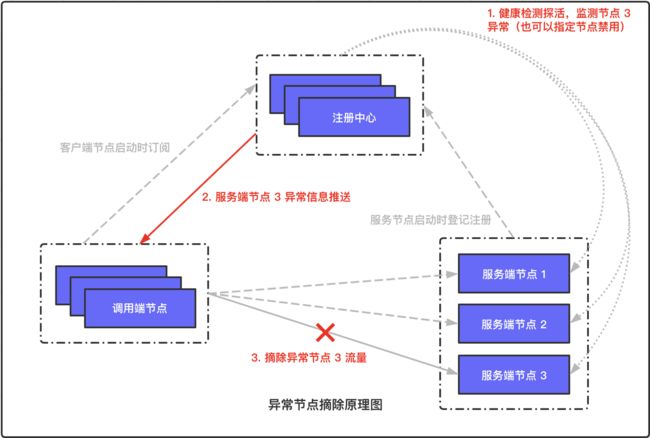
注册中心对已注册的所有服务端节点做周期性健康监测,当检测到节点异常时,如端口不响应,会通知已订阅异常节点所属 Service Name 的所有调用端节点,感知到变更信息的调用端节点摘除异常节点对应的流量
路由策略原理
最后一张图,是路由策略原理图:
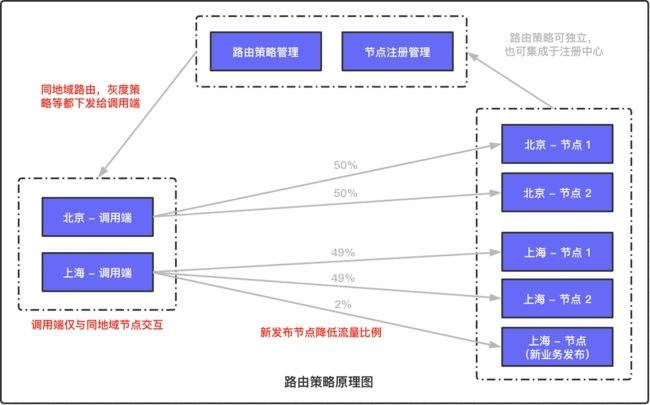
服务端新节点注册时,可以指定新节点接收的流量比例,将负载均衡策略同步给调用端,以应对新发布代码的灰度场景,此外,也可以将同地域优先等路由策略下发给调用端应用;负载均衡策略、路由策略一般是服务端指定,但真正执行是在调用端
注册中心技术选型
以上是注册中心相关原理,再来说下注册中心的技术选型,注册中心也有较为成熟的开源方案,如 Eureka、Consul、Nacos 等,也可以基于 Zookeeper、Etcd 等分布式协调系统建设,一般来说,节点规模在千级别内都能支撑
选型时,重点关注两个方面:
- 一是与通信框架、业务开发框架的匹配度,减少适配所带来的成本
- 二是依然要考虑公有云部署情况,尽量贴近已选择或未来会选择的云厂商
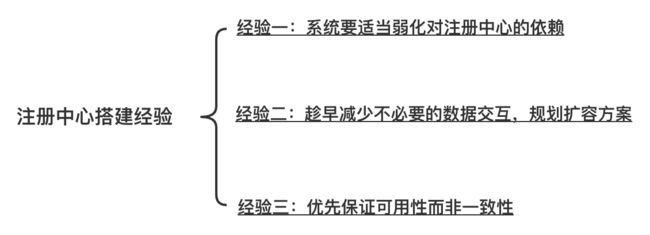
注册中心 3 个实践经验
这里介绍 3 个注册中心的实践经验
- 第一个经验,系统要适当弱化对注册中心的依赖
系统要适当弱化对注册中心的依赖,当注册中心完全不可用时,也要能在一定程度维持业务可用,比如:
- 应用进程所在节点定时缓存服务端节点列表,当注册中心异常时,使用缓存数据继续调用
- 调用端不仅依赖注册中心的决策,也要根据自身的心跳探活决定流量管理动作
- 当注册中心主动封禁大量节点时,很可能是误判,要考虑对禁用指令进行熔断
- 第二个经验,趁早减少不必要的数据交互,规划扩容方案
注册中心的负载与系统节点数呈现的并不是简单的线性关系,它比较难划分为多份完全无关的数据,因为注册中心对应的是服务间的二维关系,调用关系可能随业务迭代经常变化,所以趁早减少不必要的数据交互,以及规划扩容方案是十分必要的,比如按需订阅、读写分离来降低集群的压力都是常见方案
- 第三个经验,优先保证可用性而非一致性
一致性与可用性方面的选择,注册中心更适宜定位为 AP 系统而非 CP 系统,优先保证可用性而非一致性也是业界的主流观点,此外,多地域部署的注册中心,也能在网络分区时从容应对,比如健康检查可以采用同地域检测或仲裁的模式,可以避免脑裂引入的不一致状态
3. 系统复杂化后如何快速发现和定位异常
系统故障是无处不在的,随着业务复杂度的持续增加,系统的整体复杂度会呈现指数级膨胀,这会引入极大的运维成本,比如说单体应用的业务异常或性能问题集中在进程内,在确定节点上定位问题相对简单,但在微服务化系统演化出的复杂链路拓扑上,就较难定位分布式拓扑中哪个环节出现了问题
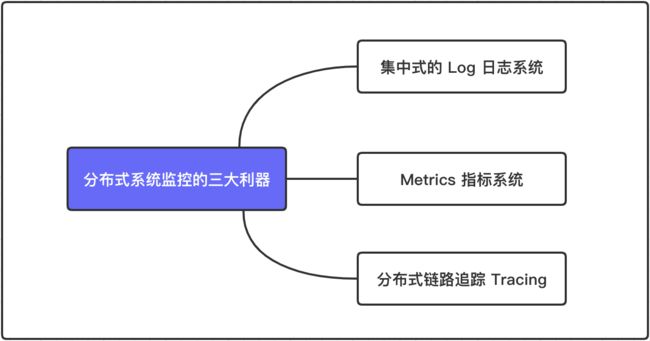
如果没有一套设施来提升观测效率,运维的成本会被持续放大,针对这个问题,我们可以围绕分布式系统监控的三大利器来建设解决:
- 第一个,集中式的 Log 日志系统
日志是原始的文本信息,微服务改造之后,日志文件呈现分散的特征,包括一个服务的日志可能也会分散到数百个节点上,将日志进行集中化有助于解放“日志文件寻址”的成本,另外将文本进行联动分析也对提效大有裨益
- 第二个,Metrics 指标系统
Metrics 比日志的抽象层次更高,它将各服务的流量指标进行多维度的统计,包含但不限于服务的依赖方、被依赖方,服务各接口各主机的 QPS、成功率、分位数延时等指标,依托 Metric 可以对服务性能、稳定性进行全局指标化的运营,整体的把控服务运行状况
- 第三个,分布式链路追踪 Tracing 系统
Tracing 也具备较高的抽象层次,通过将一次调用过程中涉及的整个链路拓扑上各环节的耗时、异常信息等状态串联起来,可以非常有效的帮助分析系统间的联动关系与行为,定位系统内的调用瓶颈
三者之间的区别与联系,强烈建议阅读 Peter Bourgon 的这篇文章:Metrics, tracing, and logging,讲解得非常得清晰透彻,虽然是 17 年的内容,不过直至今日也有非常大的参考意义
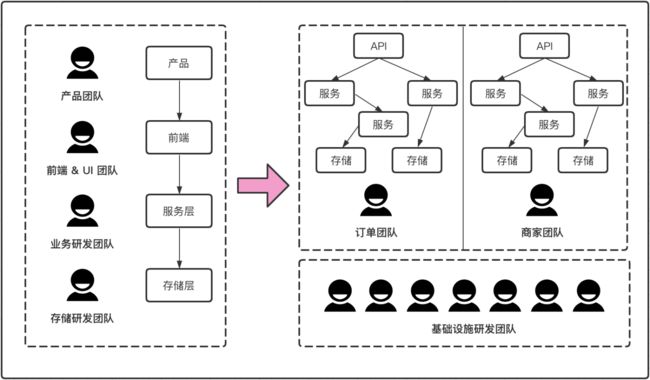
4. 微服务拆分后团队组织如何变化
单体服务往往采用按技术能力组织,相比之下,微服务改造后,各业务方向团队更适合按业务职能组织
每个组织内部有产品、设计、前端、后端、运维等,这也遵循康威定律,此外,规模较大的公司往往有独立的基础技术部门,这非常有助于技术栈的统一,更深远的意义是持续提升业务研发与运营效率,保障系统的整体可用性
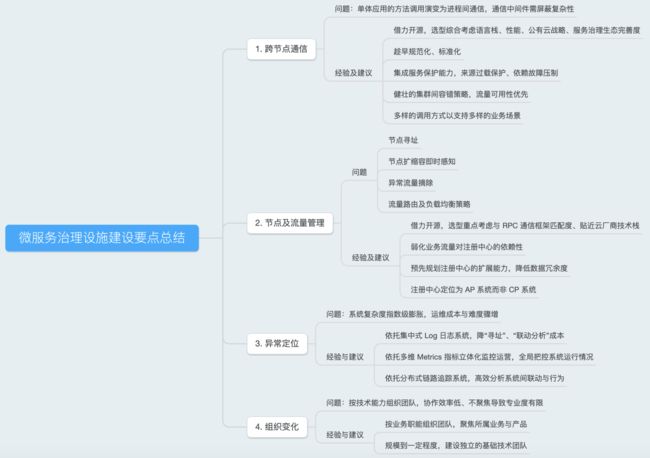
微服务治理设施建设要点总结
详情可参见幕布文档:微服务治理设施建设要点总结
资料来源
本篇笔记,来源于《极客时间》每日一课,郭继东的《微服务基础设施搭建必做的 4 件事》,郭老师的讲述非常凝练,对搭建微服务基础设施形成系统的方法论,大有裨益