分析目的:
-
- 地区对数据分析师的薪酬的影响;
-
- 学历对数据分析师的薪酬的影响;
-
- 工作年限对数据分析师的薪酬的影响
数据获取:
链接:https://pan.baidu.com/s/1-fo019qb-FY3khIKdnzAUg
提取码:wnto
一、清洗数据:删除空值,去重复值
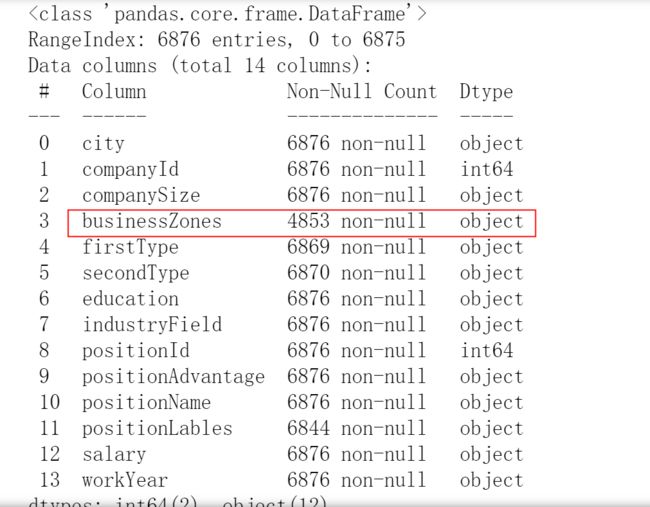
数据的缺失值在很大程度上会影响数据的分析结果,如果某一个字段缺失值超过一半的时候, 我们就可以将这个字段删除了,因为缺失过多就没有业务意义了。 所以这里我们通过data.info()拿到数据后发现businessZones列的数据缺失量比较大,所以需要将该列数据删除。
import pandas as pd
data = pd.read_csv('C:/Users/cherich/Desktop/data/analyse_spider.csv',encoding= 'GBK')
data.head()
data.tail()
data.info()
运行结果:
删除缺失值和重复数据:
# 删除businessZones列数据
data.drop(['businessZones'],axis=1, inplace=True)
# 删除含有NaN的数据
data.dropna(inplace=True)
print(len(data.duplicated()[data.duplicated()==True]))
# 删除重复数据
data.drop_duplicates(inplace=True)
data.info()
运行结果:

我们可以看到⼀共有1830条重复数据,可以直接使⽤data.drop_duplicates()删除。
二、整理数据和分析
所以我们根据当前案例得出了⼀个经验,数据的缺失值处理和重复值处理,是我们在分析之前 必须要考虑的事,因为会直接影响分析结果。 好了到了这⾥数据已经都是⼲净的了,接下来就可以整理数据和分析数据 根据⽬标明确完成第⼀个任务:
- 地区对数据分析师的薪酬的影响
已知数据:

看了已知数据重点来了,我们需要将salary薪资字段按照最高薪水和最低薪水拆成两列,并且 薪水的话如果用几K表示,直接用于计算。
配合图⽚更好理解:
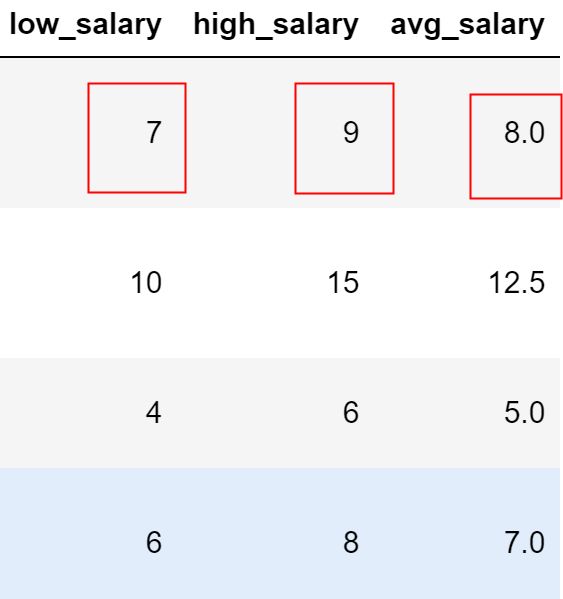
# 定义拆分的函数
def split_salary(salary,method):
# 获取'-'索引值
position = salary.upper().find('-')
if position != -1:
#salary值是15k-25k形式
low_salary = salary[:position-1]
high_salary= salary[position+1:len(salary)-1]
else:
#salary值是15k以上形式
low_salary = salary[:salary.upper().find('K')]
high_salary= low_salary
# 根据参数用以判断返回的值
if method == 'low':
return low_salary
elif method == 'high':
return high_salary
elif method == 'avg':
return (int(low_salary) + int(high_salary))/2
data['low_salary']=data.salary.apply(split_salary,method='low')
data['high_salary']=data.salary.apply(split_salary,method='high')
data['avg_salary']=data.salary.apply(split_salary,method='avg')
data
运行结果:
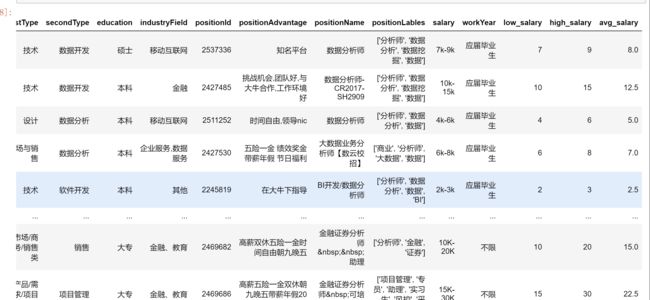
代码逻辑:
1.我们自定义了一个函数split_salary()函数,salary参数是使用apply函数必须要传的参数, 其实就是data.salary的值。
2.使用salary.upper().find('-')判断salary值是15k-25k的形式还是15k以上形式,如果结果 是-1,表示是15k以上形式,反之是15k-25k形式。为了避免k的大小写,我们用upper函数将 k都转换为K,然后以K作为截取。
3.在split_salary函数增加了新的参数用以判断返回low_salary还是high_salary或者是 avg_salary。
三、数据可视化
接下来就可以展示数据了
1、数据分析师的薪资分布
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style='darkgrid')
plt.hist(data.avg_salary)
plt.show()
运行结果:
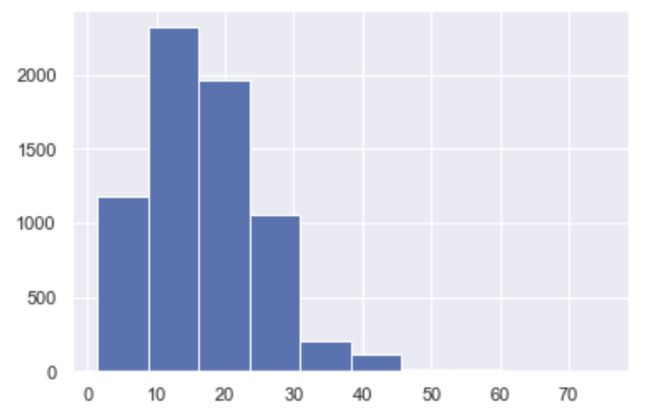
说明:以上我们可以看出大部分数据分析师工资分布在10到20K之间
2、城市对数据分析师工资的影响
from matplotlib import font_manager
my_font=font_manager.FontProperties(fname='C:/Users/cherich/Desktop/data/STSONG.TTF')
groups = data.groupby(by='city')
xticks = []
for group_name,group_df in groups:
xticks.append(group_name)
plt.bar(group_name,group_df.avg_salary.mean())
plt.xticks(xticks,fontproperties=my_font)
plt.show()
运行结果:
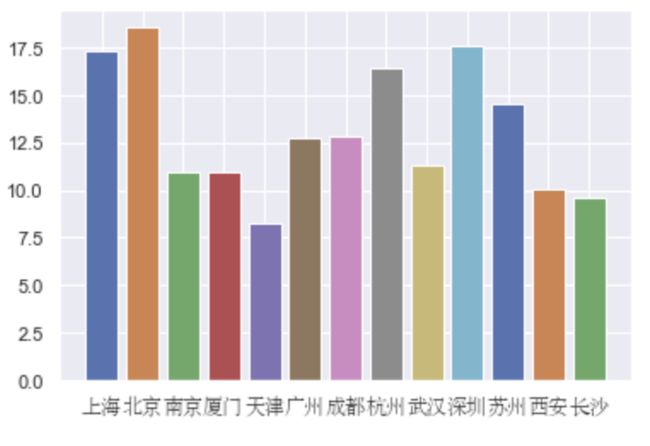
说明:以上可以看出北上深数据分析师工资水平最高
3、学历对数据分析师工资的影响
groups = data.groupby(by='education')
xticks = []
for group_name,group_df in groups:
xticks.append(group_name)
plt.bar(group_name,group_df.avg_salary.mean())
plt.xticks(xticks,fontproperties=my_font)
plt.show()
运行结果:
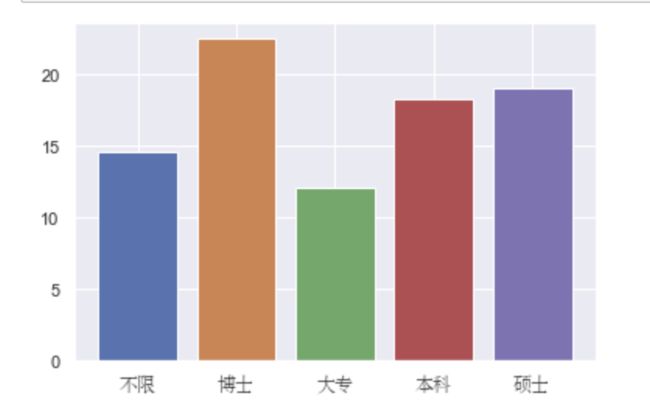
说明:以上可以看出博士学历数据分析师工资水平最高,本科和硕士差不多
4、工作年限对数据分析师的影响
groups = data.groupby(by='workYear')
xticks = []
for group_name,group_df in groups:
xticks.append(group_name)
plt.bar(group_name,group_df.avg_salary.mean())
plt.xticks(xticks,fontproperties=my_font)
plt.show()
运行结果:
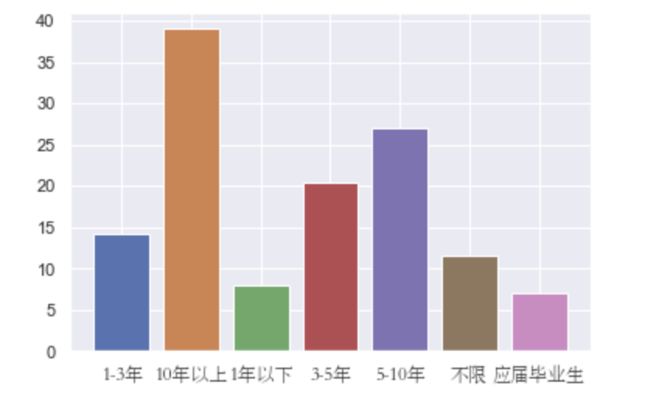
说明:以上可以看出年限越高数据分析师工资水平越高