非常抱歉,今天下午 16:30-17:15 期间,由于出现突发故障,造成园子无法正常访问,由此给您带来麻烦,请您谅解。
故障经过如下:
16:30 开始,Kubernetes 集群上博客站点的部分 pod 出现请求执行时间慢(5-10秒)的问题。
16:43 开始,请求执行时间慢的问题更加严重,开始出现执行时间超过10秒的请求。
16:50 开始,出现大量数据库连接超时的日志:
System.Data.SqlClient.SqlException (0x80131904): Timeout expired. The timeout period elapsed prior to completion of the operation or the server is not responding.
同时数据库服务器的 CPU 从正常时期的 30% 以下飙升至 45% 多。
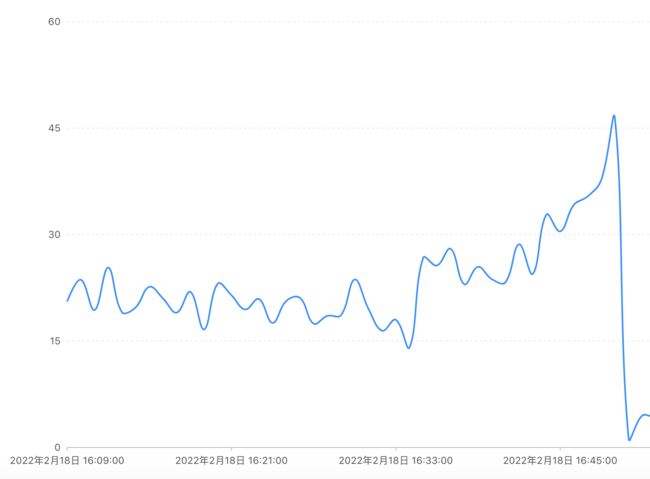
这时我们判断数据库服务器可能会超载,于是做了一个艰难的决定——按下“高速中换轮胎”的紧急按钮,启动了数据库的主备切换。

16:55 左右完成主备切换,但数据库的主备切换会造成 pod 因健康检查失败而重启,在访问高峰的高并发请求下,重启后的 pod 很容易出现不堪重负的无奈情况。
直到 17:10 左右才基本恢复。
最后剩下一款体质较差的 pod,重启后一接入负载总是不堪重负,落到它上面的请求就响应缓慢,拿它一点办法没有。
后来,急中生笨方法,既然体质弱的现实无法改变,那就接受这个现实,不让它干活就行,怎么让它不干活呢?在旧 pod 被删除之后与新 pod 启动完成健康检查之前,这个阶段 pod 是不干活的,只要让它一直处在这个阶段就行。于是盯着这款 pod,一等它完成健康检查有负载进来就删除它,用这个笨方法熬过访问高峰,体质弱的 pod 就能继续干活了。
(故障完)