去除马赛克,有办法了 附运行教程
消除马赛克秒变高清人像,将模糊的照片秒变清晰。
ai技术是越来越强悍了。
但现在的ai技术,真的可以完全消除马赛克,百分百还原照片吗?
其实,消除马赛克的算法 PULSE,在2年前就已经发布了。
通过算法脑补出打码的地方,帮助我们还原照片。
甚至脸上的毛孔、头发都能复原。
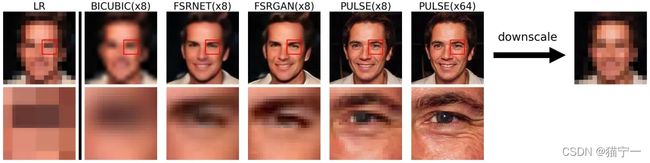
发展到现在,消除马赛克的技术已经趋于成熟了,这不前两周,又开源了一个新的算法MAE。
这个更厉害,即使画面遮挡超过90%,ai也会想办法帮我们复原。
我运行试了一下,用的是下面这张图片。
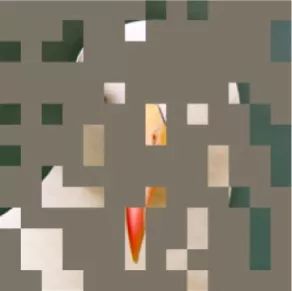
遮挡后,我们能大体看出这是什么,但是眼睛长什么样子还不知道。
运行了一下,算法模拟出来的效果是下面这样的:

而原图是这样的:

基本上是还原了。
我们来看看这些算法的原理吧。
马赛克其实就是一张低像素的图像。
一张清晰的图片,只是眼睛这一个区域,可能就有100个像素,而转换成马赛克,这一区域可能就只有3个像素。
这样图片就会模糊不清,看不清楚原图片是个啥。
那想要复原照片呢,就需要根据这3个像素,脑补出一些的特征,重新补足为100个像素。
这个就是算法做的事情,自动脑补一些不存在的特征,比如皱纹、毛发等。
那这些算法真的能帮我们百分百复原照片吗?
我拿我自己的证件照试了一下。
第一张是原图,最后一张是最后复原的效果。

那个——
虽然也是有鼻子有眼的。
但是跟原照片相比,只能说是毫不相关。
最后生成的照片只是算法脑补出来的,可能只是一张看上去真实的面孔。
但想要通过马赛克去重建还原人像,目前看来,这是不可能的。
但复原一些个体特性不太明显的事物,比如家具、动物等,准确率就比较高了。
比如下面这个小狐狸,MAE算法复原的就很成功。

那怎么运行这些算法呢?
我们以第一个算法PULSE举例。
第一步:下载代码
项目地址:
https://github.com/adamian98/pulse
第二步:搭建环境
在代码文件的根目录下面,有一个pulse.yml文件,环境配置信息都在这里面了。
我们可以直接运行下面代码创建虚拟环境,并根据pulse.yml文件配置环境。
conda env create -n pulse -f pulse.yml
不过我自己安装,报了下面的错误:
Solving environment: failed
ResolvePackageNotFound:***
这是因为,环境配置文件是在别的电脑上面导出来的,不适合我们电脑的配置,删除包的具体信息就可以解决,即删除包名称第二个等号后面的内容。
比如:
- blas=1.0=mkl
- ca-certificates=2020.1.1=0
改成:
- blas=1.0
- ca-certificates=2020.1.1
还有dlib库的安装也遇到了问题,需要先安装cmake,再安装dlib。
pip install cmake
pip install dlib
如果还是安装不成功,可以先将dlib19.19.0版本下载下来,在本地安装。
我将dlib19.19.0版本文件,上传到了我的百度网盘。
下载地址(提取码:6666):
https://pan.baidu.com/s/16KHEdZ0KD_pQPRRiGuq5Ew
最后安装本地文件就可以了。
pip install dlib-19.19.0-cp38-cp38-win_amd64.whl.whl
第三步:运行模型
项目给我们提供了预训练模型,需要下载。
我也已经下载好,上传到了我的百度网盘。
下载地址(提取码:6666):
https://pan.baidu.com/s/16KHEdZ0KD_pQPRRiGuq5Ew
在代码文件的根目录下面,创建两个文件夹,分别命名为:cache、realpics 。
将上面下载好的,预训练模型(三个文件),放到 cache 文件夹内。
然后将一张人像照片放到 realpics 文件夹内,我们以下图为例:
先运行下面语句,对图片进行降分辨率处理。
python align_face.py
生成的图片会放到 input 文件夹内。

最后运行run.py文件
python run.py
就会在 runs 文件夹下生成脑补图。
都是金发碧眼,但是不怎么像——
如果运行过程中遇到这个错误:
Could not find a face that downscales correctly within epsilon
有两个方法可以解决:
1.增加迭代次数
python run.py -steps=5000
2、增大eps
出现这个问题,是因为L2 损失大于eps,我们通过增大eps的值,就可以避免这个错误
在run.py文件的39行。
原代码:
parser.add_argument('-eps', type=float, default=2e-3, help='Target for downscaling loss (L2)')
修改成:
parser.add_argument('-eps', type=float, default=8e-2, help='Target for downscaling loss (L2)')
这样基本就没有问题了。
我将运行项目期间遇到的问题都写出来了,希望大家跟着可以运行的顺利一些~
如果想要运行新出的这个MAE算法。
项目地址是:
https://github.com/facebookresearch/mae
项目提供了 Colab,要登陆Google账户才能运行,如果可以登录的话,可以直接在线体验算法效果:
https://colab.research.google.com/github/facebookresearch/mae/blob/main/demo/mae_visualize.ipynb
wx搜索【喵宁一】第一时间阅读文章~