1,什么是垂直/水平拆分模式
2,基于客户端与服务器端实现分表分库的区别
3,单表达到多大的量开始分表分库
4,数据库分表分库策略有哪些
5, shardingSphere 实战分库分表
6,为什么不推荐使用mycat 实现分库分表
7,分表分库后查询存在哪些优缺点
8,分表分库后如何实现分页查询
9,分表分库后如何实现排序查询;
垂直/水平拆分模式
1,数据库拆分主要指分库分表,其目的主要是分散数据库压力,达到横向发展,满足均衡访问等。
2, 数据库拆分主要有2种形式: 垂直拆分和水平拆分。
A 垂直拆分:
将不同的业务功能相关的表放到不同的数据库中,也就是类似于 微服务架构中 会员数据库/订单数据库/支付数据库
B 水平拆分:
当一张表的业务量行数如果超过 500 行,分页/排序效率还是非常低,可以对同一个表数据实现拆分放到多个不同的数据库表中存放。
Mayikt_memberdb01
Mayikt_user
Mayikt_memberdb02
Mayikt_user
基于客户端与服务器端实现分表分库的区别:
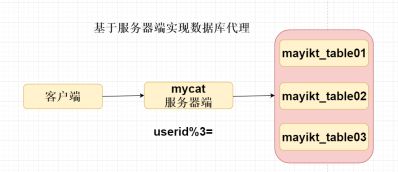
1,基于服务器端mycat 实现数据库代理
优点: 能够保证数据库 的安全性
缺点: 效率比较低
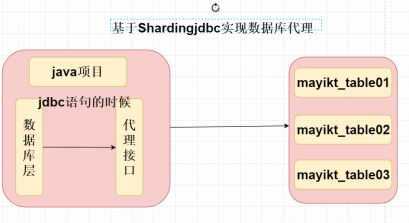
2,基于客户端Shardingjdbc 实现数据库代理:
优点: 效率比较高
缺点: 不能够保证数据库的安全性,内存溢出;
单表达到多大量开始分表分库:
【推荐】单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
摘自:阿里巴巴java开发手册
数据库分表分库策略有哪些:
取余/取模 均匀存放数据 缺点: 不够扩容。
按照范围分片: 1-500万 501万-10000万;
按照日期进行分片 日志,订单信息 同居
按照枚举值分片;
二进制取模范围分片:
一致性hash 分片,类似于HashMap 缺点 数据存放不均匀。
按照目前字段前缀指定的进行分区 mayikt wuhan
按照前缀ASCII 码和值进行取模范围分片。
主流分片算法: 取余/取模 日期 一致性hash 分片
根据user_id
Userid=1%2=1
Userid=2%2=0
Userid=3%2=1
Userid=4%2=0
不能实现扩容。
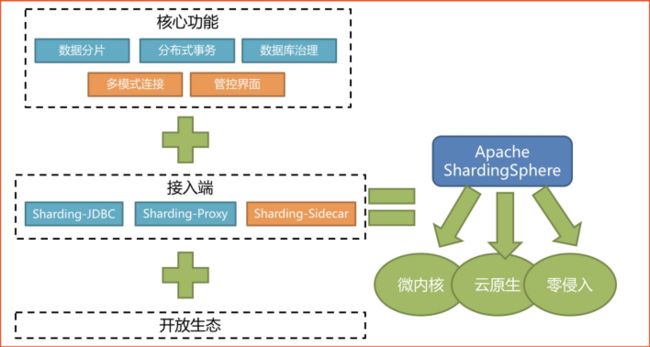
ShardingSphere 实战分表分库
ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC, Sharding-PROXY 和 Sahriding 这三款 相互独立的产品组成。
他们均提供标准化的数据分片,分布式事务 和数据库治理功能,可适用于java同构,已购语言,云原生等各种多样化的应用场景。
Sharding_JDBC 可以实现
分库 & 分表
- 读写分离
- 分片策略定制化
- 无中心化分布式主键
SharingdSphere 环境搭建:
数据库准备;
DROP TABLE IF EXISTS `mayikt_user_0`;
CREATE TABLE `mayikt_user_0` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of mayikt_user_0
-- ----------------------------
INSERT INTO `mayikt_user_0` VALUES ('2', 'mayikt2', '2');
INSERT INTO `mayikt_user_0` VALUES ('4', 'mayikt4', '4');
INSERT INTO `mayikt_user_0` VALUES ('6', 'mayikt6', '6');
INSERT INTO `mayikt_user_0` VALUES ('8', 'mayikt8', '8');
-- ----------------------------
-- Table structure for mayikt_user_1
-- ----------------------------
DROP TABLE IF EXISTS `mayikt_user_1`;
CREATE TABLE `mayikt_user_1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of mayikt_user_1
-- ----------------------------
INSERT INTO `mayikt_user_1` VALUES ('1', 'mayikt1', '1');
INSERT INTO `mayikt_user_1` VALUES ('3', 'mayikt3', '3');
INSERT INTO `mayikt_user_1` VALUES ('5', 'mayikt5', '5');
INSERT INTO `mayikt_user_1` VALUES ('7', 'mayikt7', '7');
INSERT INTO `mayikt_user_1` VALUES ('9', 'mayikt9', '9');
Maven 依赖:
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.3.5.RELEASE
com.taotao
sharding-jdbc
0.0.1-SNAPSHOT
sharding-jdbc
Demo project for Spring Boot
1.8
log4j
log4j
1.2.17
org.projectlombok
lombok
org.springframework.boot
spring-boot-starter-aop
org.apache.commons
commons-lang3
com.baomidou
mybatis-plus-boot-starter
3.3.2
mysql
mysql-connector-java
8.0.20
com.alibaba
fastjson
1.2.62
org.projectlombok
lombok
io.shardingsphere
sharding-jdbc-spring-boot-starter
3.1.0
io.shardingsphere
sharding-jdbc-spring-namespace
3.1.0
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-test
test
org.junit.vintage
junit-vintage-engine
org.springframework.boot
spring-boot-maven-plugin
application.yml 配置文件
# 数据源 mayiktdb
sharding:
jdbc:
datasource:
names: shard1,shard2
# 第一个数据库
shard1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/mayikt-member?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8
username: root
password: root
shard2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3306/mayikt?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8
username: root
password: root
# 水平拆分的数据库(表) 配置分库 + 分表策略 行表达式分片策略
config:
sharding:
#默认数据源(未设置分表策略的表将默认用此数据源)
default-database-name: shard1
#默认分库策略
default-database-strategy:
standard:
sharding-column: id
precise-algorithm-class-name: com.taotao.rfspringboot.config.DataBasePreciseRule
tables:
mayikt_user: ##虚拟表名称 mayikt_user_0 mayikt_user_1
actual-data-nodes: shard$->{1..2}.mayikt_user_$->{0..2} # 没有带上 分片字段
table-strategy:
standard: ##SELECT * FROM mayikt_user_1 where id =1
precise-algorithm-class-name: com.taotao.rfspringboot.config.MayiktRangeShardingAlgorithm
sharding-column: id
# 打印执行的数据库
props:
sql:
show: true
# 打印执行的sql语句
spring:
main:
allow-bean-definition-overriding: true
server:
port: 8081
mybatis-plus:
# 如果是放在src/main/java目录下 classpath:/com/yourpackage/*/com.exchange.mapper/*Mapper.com.exchange.mapper
# 如果是放在resource目录 classpath:/com.exchange.mapper/*Mapper.com.exchange.mapper
mapper-locations: classpath:/mapper/*.xml
#实体扫描,多个package用逗号或者分号分隔
typeAliasesPackage: com.taotao.rfspringboot.entity
global-config:
#主键类型 0:"数据库ID自增", 1:"用户输入ID",2:"全局唯一ID (数字类型唯一ID)", 3:"全局唯一ID UUID";
#若采用雪花算法生成id,需要在生成的实体类中将id的type = IdType.AUTO去掉
id-type: 0
#字段策略 0:"忽略判断",1:"非 NULL 判断"),2:"非空判断"
field-strategy: 2
#驼峰下划线转换
db-column-underline: true
#刷新mapper 调试神器
#refresh-mapper: true
#数据库大写下划线转换
#capital-mode: true
# Sequence序列接口实现类配置
#逻辑删除配置(下面3个配置)
logic-delete-value: Y
logic-not-delete-value: N
#sql-injector: com.nky.pork.quality.standard.conf.MybatisPlusConfig
configuration:
#配置返回数据库(column下划线命名&&返回java实体是驼峰命名),自动匹配无需as(没开启这个,SQL需要写as: select user_id as userId)
map-underscore-to-camel-case: true
cache-enabled: false
#配置JdbcTypeForNull, oracle数据库必须配置
jdbc-type-for-null: 'null'
entity:
package com.taotao.shardingjdbc.entity;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
/**
*@author tom
*Date 2020/11/6 0006 8:27
*
*/
@Data
@TableName("mayikt_user")
public class Mayikt_user {
private Integer id;
private String name;
private Integer age;
public Mayikt_user(Integer id, String name, Integer age) {
this.id = id;
this.name = name;
this.age = age;
}
}
数据库访问:
package com.taotao.shardingjdbc.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.taotao.shardingjdbc.entity.MayiktUser;
import org.apache.ibatis.annotations.Select;
import java.util.List;
/**
*@author tom
*Date 2020/11/6 0006 8:29
*
*/
public interface MayiktUserMapper extends BaseMapper {
/**
* 查询所有
*
* @return
*/
@Select("SELECT * FROM mayikt_user")
List userList();
/**
* 分页查询
*
* @return
*/
@Select("SELECT * FROM mayikt_user limit 0,2")
List userListPage();
/**
* 排序
*
* @return
*/
@Select("SELECT * FROM mayikt_user order by id desc ")
List userOrderBy();
/**
* get by id
*
* @return
*/
@Select("SELECT * FROM mayikt_user where id =#{id} ")
List getByUserId(Long id);
}
Controller:
package com.taotao.shardingjdbc.controller;
import com.taotao.shardingjdbc.entity.MayiktUser;
import com.taotao.shardingjdbc.mapper.MayiktUserMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
/**
*@author tom
*Date 2020/11/6 0006 8:41
*
*/
@RestController
public class UserController {
@Autowired
private MayiktUserMapper mayiktUserMapper;
@RequestMapping("/insertUser")
public String insertUser(){
for (int i = 0; i <10 ; i++) {
MayiktUser mayiktUser=new MayiktUser(i,"mykt"+i,i);
try {
mayiktUserMapper.insert(mayiktUser);
}catch (Exception e){
e.printStackTrace();
}
}
return "success";
}
/**
* 查询所有
*/
@RequestMapping("/userList")
public List userList(){
return mayiktUserMapper.userList();
}
/**
* 分页查询
*/
@RequestMapping("/userListPage")
public List userListpage(){
return mayiktUserMapper.userListPage();
}
/**
* 排序
*/
@RequestMapping("/userOrderBy")
public List userOrderBy(){
return mayiktUserMapper.userOrderBy();
}
@RequestMapping("/getByUserId")
public List getByUserId(Long id){
return mayiktUserMapper.getByUserId(id);
}
}
package com.taotao.rfspringboot.config;
import io.shardingsphere.api.algorithm.sharding.PreciseShardingValue;
import io.shardingsphere.api.algorithm.sharding.standard.PreciseShardingAlgorithm;
import java.util.Collection;
/**
* 数据库分片规则
*
* @author Mos
*/
public class DataBasePreciseRule implements PreciseShardingAlgorithm {
@Override
public String doSharding(Collection databaseNames, PreciseShardingValue shardingValue) {
/**
* databaseNames 所有分片库的集合
* shardingValue 为分片属性,其中 logicTableName 为逻辑表,columnName 分片健(字段),value 为从 SQL 中解析出的分片健的值
*/
for (String databaseName : databaseNames) {
String value = shardingValue.getValue() % databaseNames.size()+1 + "";
if (databaseName.endsWith(value)) {
System.out.println(databaseName+"&&&"+shardingValue.getValue() +"*********"+databaseNames.size());
return databaseName;
}
}
throw new IllegalArgumentException();
}
}
package com.taotao.rfspringboot.config;
import io.shardingsphere.api.algorithm.sharding.PreciseShardingValue;
import io.shardingsphere.api.algorithm.sharding.standard.PreciseShardingAlgorithm;
import lombok.extern.slf4j.Slf4j;
import java.util.Collection;
@Slf4j
public class MayiktRangeShardingAlgorithm implements PreciseShardingAlgorithm {
@Override
public String doSharding(Collection databaseNames, PreciseShardingValue shardingValue) {
/**
* databaseNames 所有分片库的集合
* shardingValue 为分片属性,其中 logicTableName 为逻辑表,columnName 分片健(字段),value 为从 SQL 中解析出的分片健的值
*/
for (String databaseName : databaseNames) {
String value = shardingValue.getValue() % databaseNames.size() + "";
if (databaseName.endsWith(value)) {
return databaseName;
}
}
throw new IllegalArgumentException();
}
}
归并数据原理
1.SELECT * FROM mayikt_user
底层发出多条语句查询每张表数据,在本地实现数据合并