内存屏障需要解决我们前面提到的两个问题,一个是编译器的优化乱序和CPU的执行乱序,我们可以分别使用优化屏障和内存屏障这两个机制来解决
从CPU层面来了解一下什么是内存屏障
CPU的乱序执行,本质还是,由于在多CPU的机器上,每个CPU都存在cache,当一个特定数据第一次被特定一个CPU获取时,由于在该CPU缓存中不存在,就会从内存中去获取,被加载到CPU高速缓存中后就能从缓存中快速访问。当某个CPU进行写操作时,它必须确保其他的CPU已经将这个数据从他们的缓存中移除,这样才能让其他CPU安全的修改数据。显然,存在多个cache时,我们必须通过一个cache一致性协议来避免数据不一致的问题,而这个通讯的过程就可能导致乱序访问的问题,也就是运行时的内存乱序访问。现在的CPU架构都提供了内存屏障功能,在x86的cpu中,实现了相应的内存屏障。
写屏障(store barrier)、读屏障(load barrier)和全屏障(Full Barrier),主要的作用是:
Ø 防止指令之间的重排序
Ø 保证数据的可见性
store barrier
store barrier称为写屏障,相当于storestore barrier, 强制所有在storestore内存屏障之前的所有执行,都要在该内存屏障之前执行,并发送缓存失效的信号。所有在storestore barrier指令之后的store指令,都必须在storestore barrier屏障之前的指令执行完后再被执行。也就是进制了写屏障前后的指令进行重排序,是的所有store barrier之前发生的内存更新都是可见的(这里的可见指的是修改值可见以及操作结果可见)
load barrier
load barrier称为读屏障,相当于loadload barrier,强制所有在load barrier读屏障之后的load指令,都在load barrier屏障之后执行。也就是进制对load barrier读屏障前后的load指令进行重排序, 配合store barrier,使得所有store barrier之前发生的内存更新,对load barrier之后的load操作是可见的.
Full barrier
full barrier成为全屏障,相当于storeload,是一个全能型的屏障,因为它同时具备前面两种屏障的效果。强制了所有在storeload barrier之前的store/load指令,都在该屏障之前被执行,所有在该屏障之后的的store/load指令,都在该屏障之后被执行。禁止对storeload屏障前后的指令进行重排序。
处理器支持哪种内存重排序(LoadLoad重排序、LoadStore重排序、StoreStore重排序和StoreLoad重排序),就会提供能够禁止相应重排序的指令,这些指令就被称为基本内存屏障一LoadLoad屏障、Load Store屏障、 StoreStore屏障和StoreLoad 屏障。
总结:内存屏障只是解决顺序一致性问题,不解决缓存一致性问题,缓存一致性是由cpu的缓存锁以及MESI协议来完成的。而缓存一致性协议只关心缓存一致性,不关心顺序一致性。所以这是两个问题。
编译器层面如何解决指令重排序问题
在编译器层面,通过volatile关键字,取消编译器层面的缓存和重排序。保证编译程序时在优化屏障之前的指令不会在优化屏障之后执行。这就保证了编译时期的优化不会影响到实际代码逻辑顺序。
如果硬件架构本身已经保证了内存可见性,那么volatile就是一个空标记,不会插入相关语义的内存屏障。如果硬件架构本身不进行处理器重排序,有更强的重排序语义,那么volatile就是一个空标记,不会插入相关语义的内存屏障。
在JMM中把内存屏障指令分为4类,通过在不同的语义下使用不同的内存屏障来进制特定类型的处理器重排序,从而来保证内存的可见性
LoadLoad Barriers, load1 ; LoadLoad; load2 , 确保load1数据的装载优先于load2及所有后续装载指令的装载
StoreStore Barriers,store1; storestore;store2 , 确保store1数据对其他处理器可见优先于store2及所有后续存储指令的存储
LoadStore Barries, load1;loadstore;store2, 确保load1数据装载优先于store2以及后续的存储指令刷新到内存
StoreLoad Barries, store1; storeload;load2, 确保store1数据对其他处理器变得可见, 优先于load2及所有后续装载指令的装载;这条内存屏障指令是一个全能型的屏障,在前面讲cpu层面的内存屏障的时候有提到。它同时具有其他3条屏障的效果.
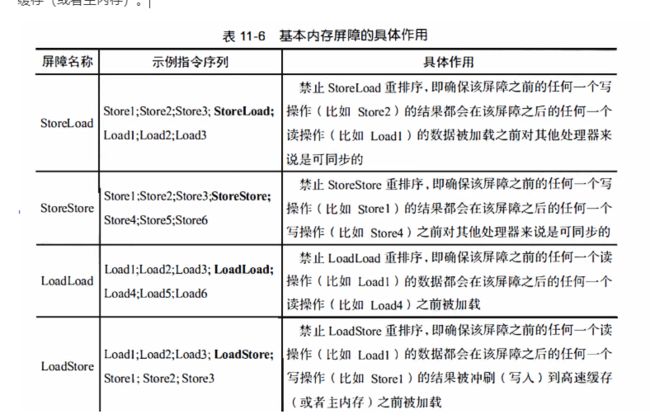
基本内存屏障可以统一用XY来表示, 其中的X和Y可以代表Load或者Store。 基本内存屏障是对一类指令的称呼。这类指令的作用是禁止该指令左侧的任何X操作与该指令右侧的任何Y操作之间进行重排序, 从而确保该指令左侧的所有X操作先于该指令右侧的Y操作即内存操作作用到主内存(或者高速缓存)上。
编译器(JIT编译器)、运行 时(Java虚拟机)和处理器都会尊重内存屏障,从而保障其作用得以落实。
因此,内存屏障需要得到编译器等多方的尊重, 其作用才能落实。
基本内存屏障的作用只是保障其左侧的X操作(比如读, 即X代表Load)先于其右侧的Y操作(比如写, 即Y代表Store)被提交,它并不全面禁止重排序。
XY屏障两侧的内存操作仍然可以在不越过内存屏障本身的情况下在各自的范围内进行重排序, 并且XY屏障左侧的非X操作与屏障右侧的非Y操作之间仍然可以进行重排序(即越过内存屏障本身)。
就处理器的具体实现而言,许多处理器往往将StoreLoad屏障实现为一个通用基本内存屏障(General-purpose Barrier)StoreLoad 屏障能够替代其他基本内存屏障, 但是它的开销也是最大的一StoreLoad 屏障会清空无效化队列,并将写缓冲器中的条目冲刷(写入) 高速缓存 。 因此,StoreLoad 屏障既可以将其他处理器对共享变最所做的更新同步到该处理器的高速缓存中,又可以使其执行处理器对共享变量所做的共享对其他处理器来说可同步。
整理不易,有收获请点个赞