MobileNet v1、v2、v3
MobileNetV1
《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
Abstract
MobileNets是为移动和嵌入式设备提出的高效模型。MobileNets基于流线型架构(streamlined),使用深度可分离卷积(depthwise separable convolutions,即Xception变体结构)来构建轻量级深度神经网络。
一句话概括,V1 就是 把 vgg 中标准卷积层换成了深度可分离卷积;(相比VGG16准确率减少了0.9%,但模型参数只有VGG的1/32)
Xception结构:https://zhuanlan.zhihu.com/p/50897945
Introduction
深度卷积神经网络将多个计算机视觉任务性能提升到了一个新高度,总体的趋势是为了达到更高的准确性构建了更深更复杂的网络,但是这些网络在尺度和速度上不一定满足移动设备要求。MobileNetv1描述了一个高效的网络架构,允许通过两个超参数(α参数是一个倍率因子,用来调整卷积核的个数,ρ是控制输入网络的图像尺寸参数)直接构建非常小、低延迟、易满足嵌入式设备要求的模型。
Related Work
现阶段,在建立小型高效的神经网络工作中,通常可分为两类工作:
- 压缩预训练模型。获得小型网络的一个办法是减小、分解或压缩预训练网络,例如
量化压缩(product quantization)、哈希(hashing )、剪枝(pruning)、矢量编码( vector quantization)和霍夫曼编码(Huffman coding)等;此外还有各种分解因子(various factorizations )用来加速预训练网络;还有一种训练小型网络的方法叫蒸馏(distillation ),使用大型网络指导小型网络,这是对论文的方法做了一个补充,后续有介绍补充。 - 直接训练小型模型。 例如
Flattened networks利用完全的因式分解的卷积网络构建模型,显示出完全分解网络的潜力;Factorized Networks引入了类似的分解卷积以及拓扑连接的使用;Xception network显示了如何扩展深度可分离卷积到InceptionV3 networks;Squeezenet使用一个bottleneck用于构建小型网络。
本文提出的MobileNet网络架构,允许模型开发人员专门选择与其资源限制(延迟、大小)匹配的小型模型,MobileNets主要注重于优化延迟同时考虑小型网络,从深度可分离卷积的角度重新构建模型。
Architecture
Depthwise Separable Convolution
MobileNet是基于深度可分离卷积的。通俗的来说,深度可分离卷积(Depthwise Separable Convolution)干的活是:把标准卷积分解成深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)。这么做的好处是可以大幅度降低参数量和计算量。
分解过程示意图如下:
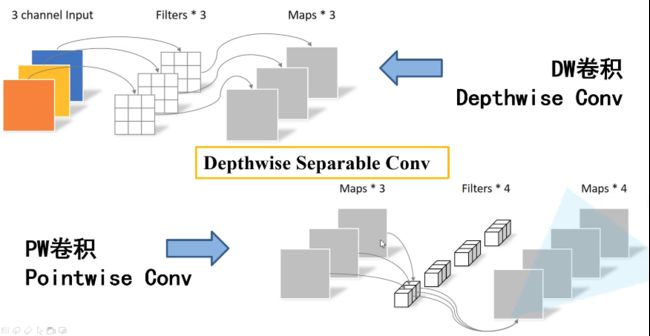

(a)中的标准卷积滤波器被两层代替:(b)中的深度卷积和©中的逐点卷积以构建深度可分离的滤波器。
![]() 标准卷积的卷积计算公式为:
标准卷积的卷积计算公式为:


深度卷积的卷积公式为:

深度分类卷积示例
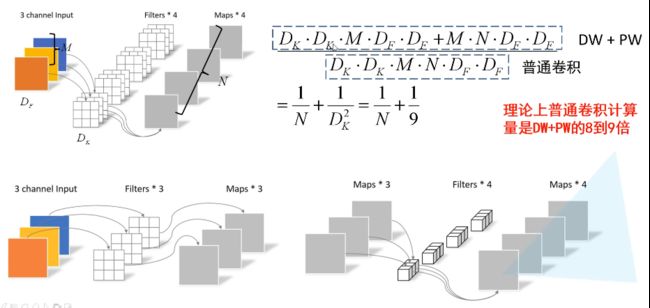
当 D K = 3 D_K=3 DK=3时,MobileNet使用可分离卷积减少了8到9倍的计算量,只损失了一点准确度。
这种深度可分离卷积虽然很好的减少计算量,但同时也会损失一定的准确率。从下图可以看到,使用传统卷积的准确率比深度可分离卷积的准确率高约1%,但计算量却增大了9倍。

网络结构与训练
标准卷积和MobileNet中使用的深度分离卷积结构对比如下:

图3.左:具有batchnorm和ReLU的标准卷积层。 右:Depthwise可分离卷积,其中Depthwise和Pointwise层紧随其后是batchnorm和ReLU6。
Relu6

Relu6 对 大于 0 的部分做了一个边界,作者认为,在模型精度要求不是很高的情况下,边界使得模型鲁棒性更强;强行压缩数值比较大的特征,避免了个性特征,也相当于 规范了特征,防止过拟合,玄学要自己体会;
注意:如果是需要下采样,则在第一个深度卷积上取步长为2.
MobileNet具体结构
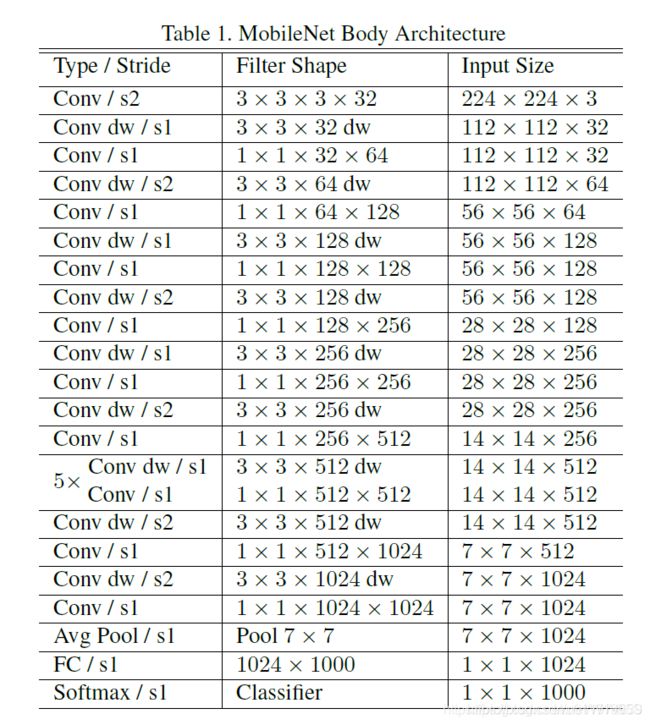
表中标Conv的表示普通卷积,Conv dw代表刚刚说的DW卷积(depthwise convolution),s表示步距。
除了最后的FC层没有非线性激活函数,其他层都有BN和ReLU非线性函数.
我们的模型几乎将所有的密集运算放到 1 × 1卷积上,这可以使用general matrix multiply (GEMM) functions优化。在MobileNet中有95%的时间花费在 1×1卷积上,这部分也占了75%的参数

剩余的其他参数几乎都在FC层上了。
在TensorFlow中使用RMSprop对MobileNet做训练,使用类似InceptionV3 的异步梯度下降。与训练大型模型不同的是,我们较少使用正则和数据增强技术,因为小模型不易陷入过拟合;没有使用side heads or label smoothing,我们发现在深度卷积核上放入很少的L2正则或不设置权重衰减的很重要,因为这部分参数很少。
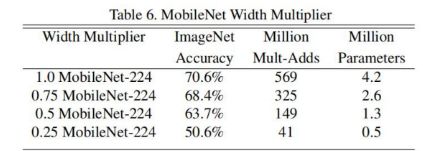
Width Multiplier: Thinner Models
我们引入的第一个控制模型大小的超参数是:宽度因子 α (Width multiplier ),用于控制输入和输出的通道数,即输入通道从 M变为 αM ,输出通道从 N变为 αN。

Resolution Multiplier: Reduced Representation
我们引入的第二个控制模型大小的超参数是:分辨率因子 ρ(resolution multiplier ),用于控制输入和内部层表示。即用分辨率因子控制输入的分辨率。


下面的示例展现了宽度因子和分辨率因子对模型的影响:

第一行是使用标准卷积的参数量和Mult-Adds;第二行将标准卷积改为深度分类卷积,参数量降低到约为原本的1/10,Mult-Adds降低约为原本的1/9。使用 α 和 ρ和 α和ρ参数可以再将参数降低一半,Mult-Adds再成倍下降。
转:https://blog.csdn.net/u011974639/article/details/79199306
MobileNetV2
paper: https://arxiv.org/abs/1801.04381
v1的问题:![]()
MobileNetV2 是由 谷歌 在 2018 年提出,相比 V1,准确率更好,模型更小;
模型亮点:
- Inverted Residuals(倒残差结构)
- Linear bottlenecks
倒残差结构
一看到 残差,就想到 resnet 了,先来看看 resnet 的 residual block
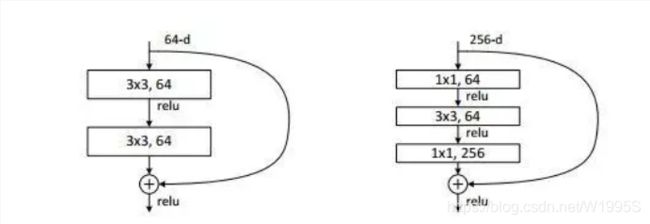
我们看右边的 block,在 resnet 中 这个 block 专为 深层网络设计,可大大减少 参数量;它先 通过 1x1 把 256 channel 变成 64 做降维,然后是 3x3 conv,再接着 1x1 还原为 256 channel 做升维;
总结一句就是先降维再升维,两头胖,中间瘦;
而 倒残差结构就是 两头瘦,中间胖;
如下图,(注意倒残差结构中基本使用的都是ReLU6激活函数,但是最后一个1x1的卷积层使用的是线性激活函数)

在具体网络设计时,经过试验,作者并不是把 所有 block 都加上了 残差结构(shortcut连接),所以 V2 中有两种 倒残差结构;在使用倒残差结构时需要注意下,并不是所有的倒残差结构都有shortcut连接,只有当stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut连接(只有当shape相同时,两个矩阵才能做加法运算,当stride=1时并不能保证输入特征矩阵的channel与输出特征矩阵的channel相同)。


Linear bottlenecks
残差结构 末尾 是 Linear 而不是 Relu,为什么呢?
作者经过研究,发现在 V1 中 depthwise 中有 0 卷积的原因就是 Relu 造成的,换成 Linear 解决了这个问题 。
转:https://zhuanlan.zhihu.com/p/70703846
MoblieNet V3
MobileNet V3发表于2019年, 该v3版本结合了v1的深度可分离卷积、v2的Inverted Residuals和Linear Bottleneck、SE模块,利用NAS(神经结构搜索)来搜索网络的配置和参数。 这种方式已经远远超过了人工调参了,太恐怖了。
v3在v2的版本上有以下的改进:
- 作者发现,
计算资源耗费最多的层是网络的输入和输出层,因此作者对这两部分进行了改进。如下图所示,上面是v2的最后输出几层,下面是v3的最后输出的几层。可以看出,v3版本将平均池化层提前了。在使用1×1卷积进行扩张后,就紧接池化层-激活函数,最后使用1×1的卷积进行输出。通过这一改变,能减少10ms的延迟,提高了15%的运算速度,且几乎没有任何精度损失。其次,对于v2的输入层,通过3×3卷积将输入扩张成32维。作者发现使用ReLU或者switch激活函数,能将通道数缩减到16维,且准确率保持不变。这又能节省3ms的延时。

- 由于**
嵌入式设备计算sigmoid是会耗费相当大的计算资源**的,因此作者提出了h-switch作为激活函数。且随着网络的加深,非线性激活函数的成本也会随之减少。所以,只有在较深的层使用h-switch才能获得更大的优势。

- 在v2的block上引入
SE模块,SE模块是一种轻量级的通道注意力模块。在depthwise之后,经过池化层,然后第一个fc层,通道数缩小4倍,再经过第二个fc层,通道数变换回去(扩大4倍),然后与depthwise进行按位相乘。
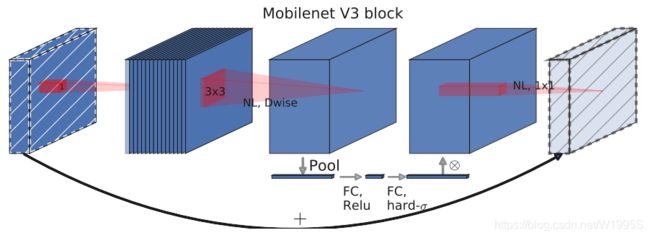
最后,v3的结构如下图所示。作者提供了两个版本的v3,分别是large和small,对应于高资源和低资源的情况。两者都是使用NAS进行搜索出来的。

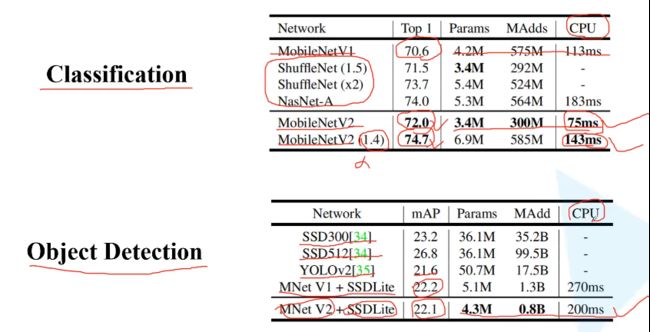
从下面的试验结果,可以看出v3-large的准确率和计算速度都高于v2。所以,AutoML搭出来的网络,已经能代替大部分调参了。

重新回顾了mobilenet系列,可以看出,准确率在逐步提高,延时也不断下降。虽然在imagenet上的准确率不能达到state-of-art,但在同等资源消耗下,其优势就能大大体现出来。
转:https://www.cnblogs.com/dengshunge/p/11334640.html