统计学——基于R(第四版) 第一章 笔记
1.1数据与统计学
统计学的含义,数据及其分类和来源
1.1.1 什么是统计学
收集数据
数据分析
- 描述统计:利用图表,计算简单统计量
- 推断统计:根据样本判断总体(参数估计和假设检验)
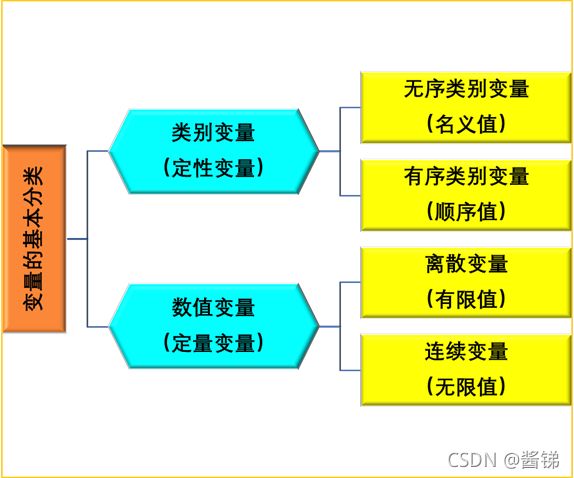
1.1.2 变量与数据
变量
数据
- 变量的观测结果就是数据
- 变量的基本分类
1.1.3 数据的来源
总体
样本
样本量
概率抽样
- 简单随机抽样
- 分层抽样
- 系统抽样
- 整群抽样
1.2 R语言的初步使用
1.2.1 R软件的下载、安装与更新
install.packages("installr") #先安装包“installr”
library(installr) #加载包
updateR() #更新
1.2.2 对象赋值与运行
sum(x) #计算对象x总和
mean(x) #计算对象x平均数
barplot(x) #绘制对象x条形图
1.2.3 编写代码脚本
R代码最好是在脚本文件中编写
R控制台->文件->新建程序脚本命令,弹出R编辑器
编写完成后,选中输入的代码右键“运行当前行或所选代码”
1.2.4 查看帮助文档
help(sum) #弹出sum函数具体说明
?plotmath #效果与上同
help(package="stats") #state包具体说明
var #直接输入函数名,看该函数源代码
1.2.5 包的安装与加载
显示已安装包的名称
#显示已安装包的名称
.packages(all.available=TRUE)
安装 加载 卸载 解除 包
install.packages("car")#安装包car
install.packages(c("car","vcd")#同时安装几个包
library(car)#加载包car
require(car)#效果与上同
remove.packages("vcd")#从R中彻底删除vcd包
detach("vcd")#解除(非删除)加载到R界面中的vcd包
本书例题习题用到的所有包
install.packages(c("agricolae","aplpack","BSDA",
"car","corrgram","DescTools","doBy","e1071","fmsb"
,"forecast","ggplot2","gmodels","gplots","gridExtra",
"HH","Hmisc","lm.beta","lsr","pastecs","plotrix","plyr",
"psych","reshape","scatterplot3d","sm","TeachingDemos",
"vcd","vioplot"))
1.3 R语言数据处理
R软件自带数据集,输入名称可查看该数据集,help函数查看详细信息
- 查看数据集
help(Titanic)#查看泰坦尼克号的数据
?Titanic#与上同
1.3.1 创建R格式数据
数据基本类型
- 向量vector
- 矩阵martrix
- 数组array
- 数据框dataframe
- 因子factor
- 列表list
1. 向量 矩阵 数组
- 向量:一维数组
录入向量用c函数,seq函数,rep函数
元素只能是同一类型数据
- 创建 访问向量
# 用c函数创建向量
a<-c(2,5,8,3,9) # 数值型向量
b<-c("甲","乙","丙","丁") # 字符型向量
c<-c("TRUE","FALSE","FALSE","TRUE") # 逻辑值向量
# 创建向量其他方法
v1<-1:6 # 产生1~6的等差数列
v2<-seq(from=2,to=4,by=0.5) # 在2~4之间产生步长为0.5的等差数列
v3<-rep(1:3,times=3) # 将1~3的向量重复3次
v4<-rep(1:3,each=3) # 将1~3的向量中每个元素重复3次
v1;v2;v3;v4 # 运行向量v1,v2,v3,v4
[1] 1 2 3 4 5 6
[1] 2.0 2.5 3.0 3.5 4.0
[1] 1 2 3 1 2 3 1 2 3
[1] 1 1 1 2 2 2 3 3 3
a<-c(2,5,8,3,9)
a[c(2,5)]
[1]5 9
- 矩阵:二维数组
每个元素类型相同
创建:matrix函数
添加行名:rownames函数
添加列名:colnames函数
转置:t函数
- 创建 添名 转置 矩阵
# 用matrix函数创建矩阵
a<-1:6 # 生成1到6的数值向量
mat<-matrix(a, # 创建向量a的矩阵
nrow=2,ncol=3, # 矩阵行数为2,列数为3
byrow=TRUE) # 按行填充矩阵的元素
# 用rownames,colnames函数添加行名和列名
rownames(mat)=c("甲","乙") # 添加行名
colnames(mat)=c("A","B","C") # 添加行名
# 用t函数对矩阵转置
t(mat) # 矩阵转置
- 数组
数组与矩阵相似,但维度可>2
创建:array函数
2. 数据框
表格结构的数据,类似excel中数据表
- 创建:data.frame函数
> # 写入姓名和分数向量
> names<-c("刘文涛","王宇翔","田思雨","徐丽娜","丁文斌") # 写入姓名向量
> stat<-c(68,85,74,88,63) # 写入各门课程分数向量
> math<-c(85,91,74,100,82)
> econ<-c(84,63,61,49,89)
>
> # 将向量组织成数据框形式
> table1_1<-data.frame(学生姓名=names,统计学=stat,数学=math,经济学=econ)
> # 将数据组织成数据框形式,并储存在对象table1_1中
>
> table1_1
学生姓名 统计学 数学 经济学
1 刘文涛 68 85 84
2 王宇翔 85 91 63
3 田思雨 74 74 61
4 徐丽娜 88 100 49
5 丁文斌 63 82 89
- 查看:
输入数据名称显示全部数据
head:默认显示前6行,head(table,3)显示table前3行
tail:默认显示后6行,tail(table,3)显示table后3行
class:查看数据类型
nrow:查看行数
ncol:查看列数
dim:同时查看行数列数
str:数据量大时查看数据的结构
> table1_1 # 显示table1_1中的数据
学生姓名 统计学 数学 经济学
1 刘文涛 68 85 84
2 王宇翔 85 91 63
3 田思雨 74 74 61
4 徐丽娜 88 100 49
5 丁文斌 63 82 89
> head(table1_1,3) ;tail(table1_1,3) # 查看前3行和后3行
学生姓名 统计学 数学 经济学
1 刘文涛 68 85 84
2 王宇翔 85 91 63
3 田思雨 74 74 61
学生姓名 统计学 数学 经济学
3 田思雨 74 74 61
4 徐丽娜 88 100 49
5 丁文斌 63 82 89
> # 查看数据框的行数和列数
> nrow(table1_1) # 查看table1_1的行数
[1] 5
> ncol(table1_1) # 查看table1_1的行数
[1] 4
> dim(table1_1) # 同时查看行数和列数
[1] 5 4
> # 查看数据的类型
> class(table1_1)
[1] "data.frame"
str函数能显示什么:table是一个数据框,有4个变量,每个变量有5个观测值,$后是数值变量。
当数据量较大时,会省略很多数据。
> # 查看数据结构
> str(table1_1) # 查看tabe1_1的数据结构
'data.frame': 5 obs. of 4 variables:
$ 学生姓名: chr "刘文涛" "王宇翔" "田思雨" "徐丽娜" ...
$ 统计学 : num 68 85 74 88 63
$ 数学 : num 85 91 74 100 82
$ 经济学 : num 84 63 61 49 89
-
"$"符号
指定分析的变量
分析多个变量可写方括号[ ] -
合并
rbind:按行合并数据框(列变量必须相同)
cbind:按列合并数据框(行变量必须相同) -
排序
sort:默认升序排列 decreasing=FALSE
需要降序时设置参数decreasing=TRUE
order:base包 排序结果扩散整个表格区域
arrange:dplyr包 默认升序, 降序设置参数desc(变量名)
-筛选 重命名 汇总
select:dplyr包 变量筛选或重命名
summarise:数据汇总
3. 因子 列表
- 因子:类别变量
水平:因子取值
factor:将向量编码为因子
as.numeric:将因子转换为数值
# 将无序因子转换为数值
a<-c("金融","地产","医药","医药","金融","医药") # 向量a
f1<-factor(a) # 将向量a编码为因子
as.numeric(f1) # 将因子转换为数值
# 将无序因子转换为有序因子或数值
b<-c("很好","好","一般","差","很差") # 向量b
# 将向量b编码为有序因子
f2<-factor(b,ordered=TRUE,levels=c("很好","好","一般","差","很差"))
as.numeric(f2) # 将因子转换为数值
- 列表:一些对象的集合
list:创建列表
一个列表中可能包含若干向量、矩阵、数据框等
1.3.2 数据读取和保存
read.csv:读取csv格式,默认包含标题header=FALSE
write.csv:保存csv格式在指定路径中
save:保存R格式在指定路径中
# 读取包含标题的csv格式数据
table1_1<-read.csv("C:/example/chap01/table1_1.csv")
# 读取不包含标题的csv格式数据
table1_1<-read.csv("C:/example/chap01/table1_1.csv",header=FALSE)
# 将tablel_1存为csv格式文件
write.csv(table1_1,file="C:/mydata/chap01/table1_1.csv")
# 将tablel_1存为R格式文件
save(table1_1,file="C:/mydata/chap01/table1_1.RData")
1.3.3 随机数和数据抽样
- 生成随机数
在相应分布函数前加字母r
set.seed():设定随机种子,使每次运行产生相同一组随机数
- 随机的正态、均匀、卡方分布
> # 生成随机数
> rnorm(n=20,mean=0,sd=1) # 产生20个标准正态分布随机数
[1] 0.19924726 -0.14862256 -0.14541055 0.02397014 2.05726569 0.54070243
[7] -1.52293849 -2.67969794 -0.69149187 -0.08224751 0.02491882 0.54702979
[13] -1.40102709 1.15944832 0.83127697 0.69801977 -0.85458047 0.68958163
[19] -2.28993715 0.17042557
> set.seed(15) # 设定随机数种子
> rnorm(n=20,mean=50,sd=5) # 产生20个均值为50、标准差为5的正态分布随机数
[1] 51.29411 59.15560 48.30191 54.48599 52.44008 43.72307 50.11394 55.45387
[9] 49.33939 44.62499 54.27505 48.17510 50.82777 43.78608 57.29644 49.98194
[17] 49.89558 50.16053 44.16361 47.40214
> runif(n=20,min=0,max=10) # 在0到10之间产生20个均匀分布随机数
[1] 9.152619 4.574306 9.210739 2.591188 3.437781 4.291725 3.302786 7.528325
[9] 8.438981 0.108724 6.667001 7.141199 7.685038 9.419001 2.480386 9.107371
[17] 6.278621 7.761303 8.178044 2.735253
> rchisq(n=20,df=15) # 产生20个卡方分布随机数
[1] 11.658757 17.344157 23.824789 11.781247 16.588682 12.754254 16.175599
[8] 10.401406 15.980531 18.076179 30.238385 9.272893 18.784349 23.903483
[15] 19.380283 17.850878 19.912369 12.756399 22.108622 11.625485
- 数据抽样
sample:从已知数据集中抽取简单随机样本
> # 抽取随机样本
> N<-1:20 # 1到20的数值向量
> n1<-sample(N,size=10);n1 # 无放回抽取10个数据
[1] 7 17 13 5 18 11 10 3 9 6
> n2<-sample(N,size=10,replace=TRUE);n2 # 有放回抽取10个数据
[1] 3 8 2 11 9 6 19 14 20 9
> Ncols<-c("black","red","green","blue","yellow") # 5种不同的颜色向量
> ncols<-sample(Ncols,size=8,replace=TRUE);ncols # 有放回抽取8个颜色
[1] "green" "yellow" "yellow" "black" "green" "green" "red" "blue"
1.3.4 数据类型的转换
- 变量换向量
as.vector
# 将table1_1中的统计学分数、统计学分数和数学分数转换为向量
table1_1<-read.csv("C:/example/chap01/table1_1.csv")
vector1<-as.vector(table1_1$统计学);vector1 # 将统计学分数转换成向量
vector2<-as.vector(c(table1_1$统计学,table1_1$数学));vector2 # 将统计学和数学分数合并转换成
vector3<-as.vector(as.matrix(table1_1[,2:4]));vector3 # 将数据框转换为向量
- 数据框 矩阵 换
as.matrix:数据框换矩阵
as.data.frame:矩阵换数据框
# 将数据框转换为矩阵
table1_1<-read.csv("C:/example/chap01/table1_1.csv")
mat<-as.matrix(table1_1[,2:4]) # 转换为矩阵mat
rownames(mat)=table1_1[,1] # 矩阵的行名为table1_1第1列的名称
mat # 查看矩阵
# 将矩阵转化成数据框
as.data.frame(mat)
- 短格式数据换长格式
合并一些列->长格式
拆开->短格式
melt:reshape2包 短转长
gather:tidyr包 短转长
dcast:reshape2包 长转短
spread:tidyr包 长转短
- 有标识变量:melt函数中的id.vars称为标识变量,用于指定按哪些因子汇集其他变量的值
- melt:融合列表(id.vars variable.name value.name)
> # 将短格式数据转换为长格式——有标识变量
> table1_1
姓名 统计学 数学 经济学
1 刘文涛 68 85 84
2 王宇翔 85 91 63
3 田思雨 74 74 61
4 徐丽娜 88 100 49
5 丁文彬 63 82 89
> library(reshape2) # 加载reshape2包
> tab.long<-melt(table1_1,id.vars="姓名",variable.name="课程",value.name="分数")
> # 融合table1_1与id变量,并命名variable.name="课程",value.name="分数“
> tab.long # 显示tab.long
姓名 课程 分数
1 刘文涛 统计学 68
2 王宇翔 统计学 85
3 田思雨 统计学 74
4 徐丽娜 统计学 88
5 丁文彬 统计学 63
6 刘文涛 数学 85
7 王宇翔 数学 91
8 田思雨 数学 74
9 徐丽娜 数学 100
10 丁文彬 数学 82
11 刘文涛 经济学 84
12 王宇翔 经济学 63
13 田思雨 经济学 61
14 徐丽娜 经济学 49
15 丁文彬 经济学 89
- 无标识变量:不使用id变量,自动融合
- melt函数无标识变量融合数据
> # 将短格式数据转换为长格式——无标识变量
> table1_3
统计学 数学 经济学
1 68 85 84
2 85 91 63
3 74 74 61
4 88 100 49
5 63 82 89
> library(reshape2) # 加载reshape2包
> tab.long<-melt(table1_3,variable.name="课程",value.name="分数")
No id variables; using all as measure variables
> head(tab.long,3) # 显示tab.long的前6行
课程 分数
1 统计学 68
2 统计学 85
3 统计学 74
- gather函数融合为长格式 有标识
> # 使用tidyr包中的gather函数转换为长格式(有标识变量)
> table1_1
姓名 统计学 数学 经济学
1 刘文涛 68 85 84
2 王宇翔 85 91 63
3 田思雨 74 74 61
4 徐丽娜 88 100 49
5 丁文彬 63 82 89
> library(tidyr)
> df1<-gather(table1_1,key="课程",value="分数","统计学","数学","经济学") # key为融合后的变量名称
> df1
姓名 课程 分数
1 刘文涛 统计学 68
2 王宇翔 统计学 85
3 田思雨 统计学 74
4 徐丽娜 统计学 88
5 丁文彬 统计学 63
6 刘文涛 数学 85
7 王宇翔 数学 91
8 田思雨 数学 74
9 徐丽娜 数学 100
10 丁文彬 数学 82
11 刘文涛 经济学 84
12 王宇翔 经济学 63
13 田思雨 经济学 61
14 徐丽娜 经济学 49
15 丁文彬 经济学 89
gather函数无标识变量融合
> # 使用tidyr包中的gather函数转换为长格式(无标识变量)
> table1_3
统计学 数学 经济学
1 68 85 84
2 85 91 63
3 74 74 61
4 88 100 49
5 63 82 89
> library(tidyr)
> df2<-gather(table1_3,key="课程",value="分数","统计学","数学","经济学")
> df2
课程 分数
1 统计学 68
2 统计学 85
3 统计学 74
4 统计学 88
5 统计学 63
6 数学 85
7 数学 91
8 数学 74
9 数学 100
10 数学 82
11 经济学 84
12 经济学 63
13 经济学 61
14 经济学 49
15 经济学 89
1.3.5 生成频数表
频数分布表
频数分布
频数
- 生成频数表
一个类别变量——简单频数表(一维列联表)
两个类别变量——二维列联表(二维表,交叉表)
多个类别变量——多维列联表(高维表)
函数:
table:base包 生成列联表
ftable:stats包 生成列联表 默认将最后一个变量作为列变量,设置参数row.vars,col.vars可改变位置
structable:vcd包 生成列联表 可创建形式多样的多维扁平化表。formula使表达式,指定行列变量。data是继承的对象。direction是拆分方向h水平c垂直。split_vertical是逻辑向量,指定每个维度是否拆分,默认为FALSE。subset为可选向量,指定要使用的观测子集,
prop.table:将频数表转化成百分比表
addmargins:为列联表添加边际和
- 一维:
> # 生成满意度的简单频数表
> example1_1<-read.csv("example1_1.csv")
> mytable<-table(example1_1$社区);mytable
A社区 B社区 C社区 D社区
27 17 21 15
> # 生成频数表
> prop.table(mytable)*100 # 将频数表转化成百分比表
A社区 B社区 C社区 D社区
33.75 21.25 26.25 18.75
- 二维:
> # 生成社区与态度的二维列联表
> example1_1<-read.csv("example1_1.csv")
> attach(example1_1) # 绑定数据
> mytable1<-table(态度,社区);mytable1 # 生成性别和满意度的二维列联表
社区
态度 A社区 B社区 C社区 D社区
反对 13 5 7 6
赞成 14 12 14 9
> addmargins(mytable1) # 为列联表添加边际和
社区
态度 A社区 B社区 C社区 D社区 Sum
反对 13 5 7 6 31
赞成 14 12 14 9 49
Sum 27 17 21 15 80
> addmargins(prop.table(mytable1)*100) # 将列联表转换成百分比表
社区
态度 A社区 B社区 C社区 D社区 Sum
反对 16.25 6.25 8.75 7.50 38.75
赞成 17.50 15.00 17.50 11.25 61.25
Sum 33.75 21.25 26.25 18.75 100.00
- 三维
> # 生成三维频数表(列变量为“社区”)
> example1_1<-read.csv("example1_1.csv")
> mytable2<-ftable(example1_1,row.vars=c("性别","态度"),col.vars="社区")
> # 行变量为性别和态度,列变量为社区
> mytable2
社区 A社区 B社区 C社区 D社区
性别 态度
男 反对 4 3 5 2
赞成 5 7 8 2
女 反对 9 2 2 4
赞成 9 5 6 7
> # 为列联表添加边际和
> ftable(addmargins(table(example1_1$性别,example1_1$态度,example1_1$社区)))
A社区 B社区 C社区 D社区 Sum
男 反对 4 3 5 2 14
赞成 5 7 8 2 22
Sum 9 10 13 4 36
女 反对 9 2 2 4 17
赞成 9 5 6 7 27
Sum 18 7 8 11 44
Sum 反对 13 5 7 6 31
赞成 14 12 14 9 49
Sum 27 17 21 15 80
> # 生成三维频数表(列变量为"社区",行变量为“性别”和"满意度")
> ftable(example1_1,row.vars=c("社区"),col.vars=c("性别","态度"))
性别 男 女
态度 反对 赞成 反对 赞成
社区
A社区 4 5 9 9
B社区 3 7 2 5
C社区 5 8 2 6
D社区 2 2 4 7
Untable:DescTools包 列联表转化成数据框
as.data.frame:里欸蓝标转化成带有类别频数的数据框
# 将列联表转换成原始数据框
read.csv("C:/example/chap01/example1_1.csv")
example1_1<-read.csv("C:/example/chap01/example1_1.csv")
library(DescTools)
mytable<-ftable(example1_1) # 生成多维列联表
df<-Untable(mytable) # 将列联表转化成原始数据框
head(df,3);tail(df,3) # 显示前3行和后3行
Untable(table(example1_1)) # 将列联表转化成数据框
# 将列联表转换成带有交叉频数标签的数据框
read.csv("C:/example/chap01/example1_1.csv")
example1_1<-read.csv("C:/example/chap01/example1_1.csv")
tab<-ftable(example1_1) # 生成列联表(可用table函数生成)
df<-as.data.frame(tab);df # 将列联表转化成带有类别频数的数据框
- 计算描述统计量
频数(frequency) :落在各类别中的数据个数
比例(proportion) :某一类别数据个数占全部数据个数的比值
百分比(percentage) :将对比的基数作为100而计算的比值
比率(ratio) :不同类别数值个数的比值
类别化:转化为因子数据
例:销售额生成频数分布表
- 确定要分的组数
确定组数的方法有几种。设组数为,根据Sturges给出的组数确定方法,=1+〖log_10 ()〗∕〖log_10 (2) 〗。当然这只是个大概数,具体的组数可根据需要适当调整。有60个数据的话,=1+〖log_10 (100)〗∕〖log_10 (2) 〗=8,或使用R函数nclass.Sturges(example1_2$销售额),得=8,因此,可以将数据大概分成8组。当然,这只是个大概数,实际分组时,可根据需要适当调整。 - 确定各组的组距(组的宽度)
组距可根据全部数据的最大值和最小值及所分的组数来确定,即组距=(最大值-最小值) ÷ 组数。 - 统计出各组的频数即得频数分布表
在统计各组频数时,恰好等于某一组上限的变量值一般不算在本组内,而算在下一组,即一个组的数值x满足a≤
cut:base包
grouped.data:actuar包
Freq:DescTools包
使用Freq函数创建的频数分布表有level组别,freq各组的频数,perc各组频数百分比,cumfreq累计频数,cumperc累计频数百分比
如果要分成特定组距的组,使用参数break确定一个分组切割点的数值向量
# 使用默认分组,含上限值
tab<- Freq(example1_2$销售额)
# 指定组距=15(不含上限值)
library(DescTools)
tab1<-Freq(example1_2$销售额,breaks=c(160,175,190,205,220,235,250,265,280),right=FALSE)
# 指定组距=15,不含上限值
tab2<-data.frame(分组=tab1$level,频数=tab1$freq,频数百分比=tab1$perc*100,累积频数=tab1$cumfreq,累积百分比=tab1$cumperc*100)
# 重新命名频数表中的变量
print(tab2,digits=3) # 用print函数定义输出结果的小数位数
1.4 R语言绘图基础
两大底层绘图系统:base grid
主要介绍graphics包
1.4.1 基本绘图函数
graphics包无需加载
包中函数大致分为两类:产生独立图形的函数&在图形上添加标题注释线段等函数
plot:反函数,可绘制多种图形
barplot:条形图
hist:直方图
boxplot:箱线图
legend:添加图例
layout:页面布局
mtext:为图形添加注释文本
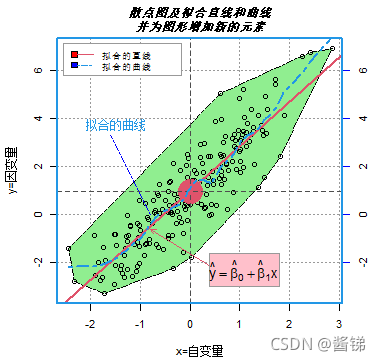
例
par(mai=c(0.6,0.6,0.4,0.4),cex=0.7) # 设置图形边界和符号的大小
set.seed(2025) # 设置随机数种子
x <- rnorm(200) # 产生200个标准正态分布的随机数
y <- 1+2*x +rnorm(200) # 产生变量y的随机数
d<-data.frame(x,y) # 将数据组织成数据框d
plot(d,xlab="x=自变量",ylab="y=因变量") # 绘制散点图
grid(col="grey60") # 添加网格线
axis(side=4,col.ticks="blue",lty=1) # 添加坐标轴
polygon(d[chull(d),],lty=6,lwd=1,col="lightgreen") # 添加多边形并填充底色
points(d) # 重新绘制散点图
points(mean(x),mean(y),pch=19,cex=5,col=2) # 添加均值点
abline(v=mean(x),h=mean(y),lty=2,col="gray30") # 添加均值水平线和垂直线
abline(lm(y~x),lwd=2,col=2) # 添加回归直线
lines(lowess(y ~ x,f=1/6),col=4,lwd=2,lty=6) # 添加拟合曲线
segments(-0.8,0,-1.6,3.3,lty=6,col="blue") # 添加线段
arrows(0.45,-2.2,-0.8,-0.6,code=2,angle=25,length=0.06,col=2)
# 添加带箭头的线段
text(-2.2,3.5,labels=expression("拟合的曲线"),adj=c(-0.1,0.02),col=4)
# 添加注释文本
rect(0.4, -1.6, 1.8,-3,col="pink",border="grey60") # 添加矩形
mtext(expression(hat(y)==hat(beta)[0]+hat(beta)[1]*x),cex=0.9,side=1,line=-2.5,adj=0.7) # 添加注释表达式
legend("topleft",legend=c("拟合的直线","拟合的曲线"),lty=c(1,6),col=c(2,4),cex=0.8,fill=c("red","blue"),box.col="grey60",ncol=1,inset=0.02) # 添加图例
title("散点图及拟合直线和曲线\n并为图形增加新的元素",cex.main=1,font.main=4) # 增加标题并折行,使用斜体字
box(col=4,lwd=2) # 添加边框14
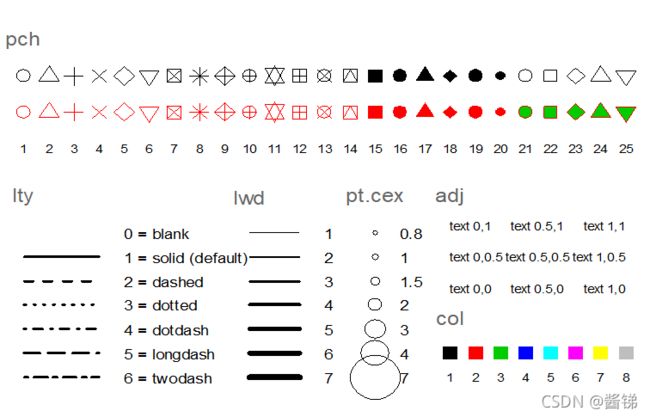
1.4.2 图形控制和页面布局
- 图形参数
- par函数参数
绘图符号pch
线型lty
线宽lwd
点的大小pt.cex
位置调整参数adj
主要颜色col
- 页面布局
页面分割和图形组合方法
- par函数参数
mfrow和mfcol将绘图页面分割成nr*nc矩阵
mfrow=c(nr,nc)按行填充各图
mfcol=c(nr,nc)按列填充各图
# 图1-5(a)的绘制代码
par(mfrow=c(2,2),mai=c(0.4,0.4,0.3,0.1),cex=0.7,mgp=c(2,1,0),cex.axis=0.8,cex.main=0.8,font.main=1)
set.seed(123) # 设置随机数种子
x<-rnorm(100) # 生成100个标准正态分布随机数
y<-rexp(100) # 生成100个指数分布随机数
plot(x,y,col=sample(c("black","red","blue"),100,replace=TRUE),main="(a) 散点图")
boxplot(x,y,col=2:3,main="(b) 箱线图")
hist(x,col="orange1",ylab="y",main="(c) 直方图")
barplot(runif(5,10,20),col=2:6,main="(d) 条形图")
- layout函数参数
向量c(nr,nc) 可以设置widths和heights将矩阵分割成大小不同的区域
# 2行2列的图形矩阵,第2列为1个图
layout(matrix(c(1,2,3,3),nrow=2,ncol=2,byrow=TRUE),heights=c(2,1))
layout.show(3)
# 2行2列的图形矩阵,第2列为1个图
layout(matrix(c(1,2,3,3),nrow=2,ncol=2),heights=c(2,1))
layout.show(3)
# 2行3列的图形矩阵,第2行为3个图
layout(matrix(c(1,1,1,2,3,4),nrow=2,ncol=3,byrow=TRUE),widths=c(3:1),heights=c(2,1))
layout.show(4)
# 3行3列的图形矩阵,第2行为2个图
layout(matrix(c(1,2,3,4,5,5,6,7,8),3,3,byrow=TRUE),widths=c(2:1),heights=c(1:1))
layout.show(8)
8幅图的layout函数布局
# 绘制代码
n=100;set.seed(12);x<-rnorm(n);y<-rexp(n)
layout(matrix(c(1,2,3,4,5,5,6,7,8),3,3,byrow=TRUE),widths=c(2:1),heights=c(1:1))
par(mai=c(0.3,0.3,0.3,0.1),cex.main=0.9,font.main=1)
barplot(runif(8,1,8),col=2:7,main="(a) 条形图")
pie(1:12,col=rainbow(6),labels="",border=NA,main="(b) 饼图")
qqnorm(y,col=1:7,pch=19,xlab="",ylab="",main="(c) Q-Q图")
plot(x,y,pch=19,col=c(1,2,4),xlab="",ylab="",main="(d) 散点图")
plot(rnorm(25),rnorm(25),cex=(y+2),col=2:4,lwd=2,xlab="",ylab="",main="(e) 气泡图")
plot(density(y),col=4,lwd=1,xlab="",ylab="",main="(f) 核密度图");polygon(density(y),col="gold",border="blue")
hist(rnorm(1000),col=3,xlab="",ylab="",main="(g) 直方图")
boxplot(x,col=2,main="(h) 箱线图")

1.4.3 图形颜色
- 颜色名称和颜色集合函数
colors:查看R软件中657种颜色名称
graphics包中参数
col,bg,fg.col 用来设置绘图区中绘制的数据符号、线条、文本等元素颜色
grDevices包中参数
cm.colors,heat.colors,rainbow,topo.colors 提供颜色集合
例:
# col的设置
x<-1:10 # 生成1到10的等差数列
a<- LETTERS[1:10] # 生成字母标签向量
par(mfrow=c(1,2),mai=c(0.4,0.4,0.3,0.2),cex=0.8,cex.axis=0.7,cex.lab=0.8,mgp=c(2,1,0),cex.main=0.9,font.main=1) # 图形参数设置
barplot(x,names=a,col=c("red","green"),main="(a) 循环使用2种颜色")
barplot(x,names=a,col=1:8,main="(b) 重复使用颜色1:8")
# 颜色集合
par(mfrow=c(2,3),mai=c(0.3,0.3,0.3,0.1),cex=0.7,mgp=c(1,1,0),cex.axis=0.7,cex.main=1,font.main=1)
x<-1:7
names<-LETTERS[1:7] # 生成字母标签向量
barplot(x,names=names,col=rainbow(7),main="col=rainbow()")
barplot(x,names=names,col=rainbow(7,start=0.4,end=0.5),main="col=rainbow(start=0.4,end=0.5)")
barplot(x,names=names,col=heat.colors(7),main="col=heat.colors()")
barplot(x,names=names,col=terrain.colors(7),main="col=terrain.colors()")
barplot(x,names=names,col=topo.colors(7),main="col=topo.colors()")
barplot(x,names=names,col=cm.colors(7),main="col=cm.colors()")

2. 调色板
对图形进行配色
display.brewer.all:RColorBrewer包 查看R的调色板,多种色系
brewer.pal:创建自己的调色板
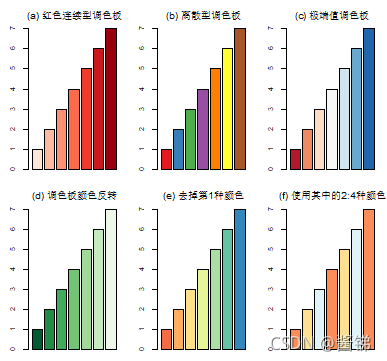
# 图1-9的绘制代码——使用调色板
library(RColorBrewer)
par(mfrow=c(2,3),mai=c(0.1,0.3,0.3,0.1),cex=0.6,font.main=1)
palette1<-brewer.pal(7,"Reds") # 7种颜色的红色连续型调色板
palette2<-brewer.pal(7,"Set1") # 7种颜色的离散型调色板
palette3<-brewer.pal(7,"RdBu") # 7种颜色的红蓝色极端值调色板
palette4<-rev(brewer.pal(7,"Greens")) # 调色板颜色反转
palette5<-brewer.pal(8,"Spectral")[-1] # 去掉第1种颜色,使用其余7种
palette6<-brewer.pal(6,"RdYlBu")[2:4] # 使用其中的2:4种颜色
barplot(1:7,col=palette1,main="(a) 红色连续型调色板")
barplot(1:7,col=palette2,main="(b) 离散型调色板")
barplot(1:7,col=palette3,main="(c) 极端值调色板")
barplot(1:7,col=palette4,main="(d) 调色板颜色反转")
barplot(1:7,col=palette5,main="(e) 去掉第1种颜色")
barplot(1:7,col=palette6,main="(f) 使用其中的2:4种颜色")