基于FPGA的MobileNet V2卷积神经网络加速器
MobileNet V2介绍
MobileNetV2是在V1基础之上的改进。V1主要思想就是深度可分离卷积。而V2则在V1的基础上,引入了Linear Bottleneck 和 Inverted Residuals。下图是MobileNet V2中的一个基本模块
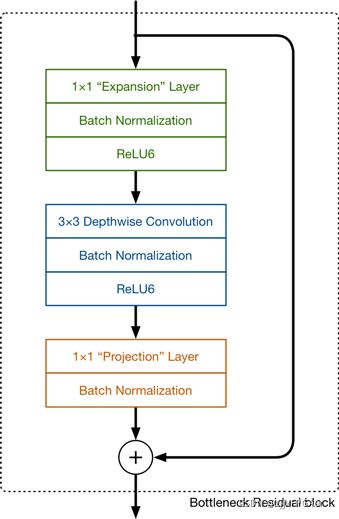
可以看到,该模块由三个卷积组成,第一第三个卷积是标准的1x1卷积,起到升维和降维的作用,而中间的是一个depthwise卷积,每一个卷积层之后,都紧接着一个BN层,以加速网络的收敛。
同时,我们观察到,该模块的输入和输出有一个残差连接,即输入和最终的输出求和,这就是MobileNet V2中的Inverted Residuals,同时,我们注意到,第三个卷积层之后,并没有跟着一个激活函数,这就是上面所说的Linear Bottleneck,因为从高维向低维转换时,使用ReLU激活函数可能会造成信息丢失或破坏(不使用非线性激活数数)。所以在最后一个卷积之后,我们不再使用ReLU激活函数而是使用线性激活函数。
有了上边的基础,整体的网络结构就很好理解了,如下图所示
 下图则是MobileNet V2和其他网络在参数量、计算复杂度方面的对比,可以看到,MobileNet V2的参数数目为3.4M,乘累加数目为300M.
下图则是MobileNet V2和其他网络在参数量、计算复杂度方面的对比,可以看到,MobileNet V2的参数数目为3.4M,乘累加数目为300M.

模型训练以及参数预处理
模型训练,我们采用的是一个有5种花卉类别的数据集,输入图像的尺寸为3x224x224,我们仅修改网络的最后一层(即将输出向量维度由1000改为5)
以下是训练代码:
import os
import torchvision.transforms as transforms
from torchvision import datasets
import torch.utils.data as data
import torch
import numpy as np
import matplotlib.pyplot as plt
import torchvision.models as models
#模型加载
model = models.mobilenet_v2(pretrained=True)
model.classifier = torch.nn.Sequential(torch.nn.Dropout(p=0.5),
torch.nn.Linear(1280, 5))
print(model)
model.load_state_dict(torch.load('model.pkl')) #在训练过的参数的基础上再进行训练
#参数
BATCH_SIZE=32
DEVICE='cuda'
#数据集加载
path='F:\\data\\flower_photos\\flower_photos'
flower_class=['daisy','dandelion','roses','sunflowers','tulips']
transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
}
image_path = path
trainset = datasets.ImageFolder(root=image_path,
transform=transform["train"])
trainloader = data.DataLoader(trainset, BATCH_SIZE, shuffle=True)
print(trainset.classes) #根据分的文件夹的名字来确定的类别
print(trainset.class_to_idx) #按顺序为这些类别定义索引为0,1...
# print(trainset.imgs) #返回从所有文件夹中得到的图片的路径以及其类别
def imshow(image):
for i in range(image.size(0)):
img = image[i] # plt.imshow()只能接受3-D Tensor,所以也要用image[0]消去batch那一维
img = img.numpy() # FloatTensor转为ndarray
img = np.transpose(img, (1, 2, 0)) # 把channel那一维放到最后
# 显示图片
plt.imshow(img)
plt.show()
#损失函数和优化器
loss_f = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.00001)
# 模型训练和参数优化
epoch_n = 10
torch.cuda.empty_cache()
model=model.to(DEVICE)
for epoch in range(epoch_n):
print("Epoch {}/{}".format(epoch + 1, epoch_n))
print("-" * 10)
# 设置为True,会进行Dropout并使用batch mean和batch var
model.train(True)
running_loss = 0.0
running_corrects = 0
# enuerate(),返回的是索引和元素
for batch, data in enumerate(trainloader):
X, y = data
X=X.to(DEVICE)
y=y.to(DEVICE)
y_pred = model(X)
# pred,概率较大值对应的索引值,可看做预测结果
_, pred = torch.max(y_pred.data, 1)
# 梯度归零
optimizer.zero_grad()
# 计算损失
loss = loss_f(y_pred, y)
loss.backward()
optimizer.step()
# 计算损失和
running_loss += float(loss)
# 统计预测正确的图片数
running_corrects += torch.sum(pred == y.data)
if batch%10==9:
print("loss=",running_loss/(BATCH_SIZE*10))
print("acc is {}%".format(running_corrects.item()/(BATCH_SIZE*10)*100.0))
running_loss=0
running_corrects=0
torch.save(model.state_dict(),'model.pkl')
训练完成后,为了加快推理速度,我们首先进行了一个BN融合,即将BN层参数和卷积层参数融合在一起,这样在推理时就可省去BN层的计算。
以下就是进行参数BN融合以及保存的代码
import torchvision.transforms as transforms
from torchvision import datasets
import torch.utils.data as data
import torch
import torchvision.models as models
#数据
path='F:\\data\\flower_photos\\flower_photos'
transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
}
trainset = datasets.ImageFolder(root=path,transform=transform["train"])
trainloader = data.DataLoader(trainset,100, shuffle=True)
image=torch.zeros((3670,3,224,224))
label=torch.zeros((3670,))
for batch,data in enumerate(trainloader):
X,y=data
image[batch*100:batch*100+y.size(0),:,:,:]=X
label[batch*100:batch*100+y.size(0)]=y
image.numpy().tofile("image.bin")
label.numpy().tofile("label.bin")
model = models.mobilenet_v2(pretrained=False)
model.classifier = torch.nn.Sequential(torch.nn.Dropout(p=0.5),
torch.nn.Linear(1280, 5))
print(model)
model.load_state_dict(torch.load('model.pkl'))
model=model.eval()
def SaveFoldedInvertedResidualParam(param_dict,i):
#
Wc1=(param_dict['conv.0.1.weight']/(torch.sqrt(param_dict['conv.0.1.running_var']+0.00001))).view(-1,1,1,1)*\
param_dict['conv.0.0.weight']
bc1=param_dict['conv.0.1.bias']-param_dict['conv.0.1.weight']*param_dict['conv.0.1.running_mean']/torch.sqrt(
param_dict['conv.0.1.running_var']+0.00001)
Wc2=(param_dict['conv.1.1.weight'] / (torch.sqrt(param_dict['conv.1.1.running_var'] + 0.00001))).view(-1,1,1,1) * param_dict[
'conv.1.0.weight']
bc2 =param_dict['conv.1.1.bias']-param_dict['conv.1.1.weight'] * param_dict['conv.1.1.running_mean'] / torch.sqrt(
param_dict['conv.1.1.running_var'] + 0.00001)
Wc3 = (param_dict['conv.3.weight'] / (torch.sqrt(param_dict['conv.3.running_var'] + 0.00001))).view(-1,1,1,1)* param_dict[
'conv.2.weight']
bc3 = param_dict['conv.3.bias']-param_dict['conv.3.weight'] * param_dict['conv.3.running_mean'] / torch.sqrt(
param_dict['conv.3.running_var'] + 0.00001)
#保存参数
Wc1.numpy().tofile("FoldedInvertedResidual.{}.Wc1.bin".format(i))
bc1.numpy().tofile("FoldedInvertedResidual.{}.bc1.bin".format(i))
Wc2.numpy().tofile("FoldedInvertedResidual.{}.Wc2.bin".format(i))
bc2.numpy().tofile("FoldedInvertedResidual.{}.bc2.bin".format(i))
Wc3.numpy().tofile("FoldedInvertedResidual.{}.Wc3.bin".format(i))
bc3.numpy().tofile("FoldedInvertedResidual.{}.bc3.bin".format(i))
def SaveFoldedHeadParam(param_dict1,param_dict2):
Wc1=(param_dict1['1.weight']/torch.sqrt(param_dict1['1.running_var']+0.00001)).view(-1,1,1,1)*param_dict1['0.weight']
bc1=param_dict1['1.bias']-param_dict1['1.weight']*param_dict1['1.running_mean']/torch.sqrt(param_dict1['1.running_var']+0.00001)
Wc1.numpy().tofile("Head.Wc1.bin")
bc1.numpy().tofile("Head.bc1.bin")
#
Wc2=(param_dict2['conv.0.1.weight']/torch.sqrt(param_dict2['conv.0.1.running_var']+0.00001)).view(-1,1,1,1)*param_dict2['conv.0.0.weight']
bc2=param_dict2['conv.0.1.bias']-param_dict2['conv.0.1.weight']*param_dict2['conv.0.1.running_mean']/torch.sqrt(0.00001+param_dict2['conv.0.1.running_var'])
Wc2.numpy().tofile("Head.Wc2.bin")
bc2.numpy().tofile("Head.bc2.bin")
#
Wc3=(param_dict2['conv.2.weight']/torch.sqrt(0.00001+param_dict2['conv.2.running_var'])).view(-1,1,1,1)*param_dict2['conv.1.weight']
bc3=param_dict2['conv.2.bias']-param_dict2['conv.2.weight']*param_dict2['conv.2.running_mean']/torch.sqrt(0.00001+param_dict2['conv.2.running_var'])
Wc3.numpy().tofile("Head.Wc3.bin")
bc3.numpy().tofile("Head.bc3.bin")
def SaveFoldedTailParam(param_dict1,param_dict2):
Wc1=(param_dict1['1.weight']/torch.sqrt(param_dict1['1.running_var']+0.00001)).view(-1,1,1,1)*param_dict1['0.weight']
bc1=param_dict1['1.bias']-param_dict1['1.weight']*param_dict1['1.running_mean']/torch.sqrt(0.00001+param_dict1['1.running_var'])
Wc1.numpy().tofile("Tail.Wc1.bin")
bc1.numpy().tofile("Tail.bc1.bin")
#
param_dict2['1.weight'].numpy().tofile("Tail.Wf1.bin")
param_dict2['1.bias'].numpy().tofile('Tail.bf1.bin')
def folded_param_save(model):
SaveFoldedHeadParam(model.features[0].state_dict(),model.features[1].state_dict())
#feature2,16-->96-->24
SaveFoldedInvertedResidualParam(param_dict=model.features[2].state_dict(),i=0)
# feature3,24-->144-->24
SaveFoldedInvertedResidualParam(param_dict=model.features[3].state_dict(),i=1)
# feature4,24-->144-->32
SaveFoldedInvertedResidualParam(param_dict=model.features[4].state_dict(),i=2)
# feature5,32-->192-->32
SaveFoldedInvertedResidualParam(param_dict=model.features[5].state_dict(),i=3)
# feature6,32-->192-->32
SaveFoldedInvertedResidualParam(param_dict=model.features[6].state_dict(),i=4)
# feature7,32-->192-->64
SaveFoldedInvertedResidualParam(param_dict=model.features[7].state_dict(),i=5)
# feature8,64-->384-->64
SaveFoldedInvertedResidualParam(param_dict=model.features[8].state_dict(),i=6)
# feature9,64-->384-->64
SaveFoldedInvertedResidualParam(param_dict=model.features[9].state_dict(),i=7)
# feature10,64-->384-->64
SaveFoldedInvertedResidualParam(param_dict=model.features[10].state_dict(),i=8)
# feature11,64-->384-->96
SaveFoldedInvertedResidualParam(param_dict=model.features[11].state_dict(),i=9)
# feature12,96-->576-->96
SaveFoldedInvertedResidualParam(param_dict=model.features[12].state_dict(),i=10)
# feature13,96-->576-->96
SaveFoldedInvertedResidualParam(param_dict=model.features[13].state_dict(),i=11)
# feature14,96-->576-->160
SaveFoldedInvertedResidualParam(param_dict=model.features[14].state_dict(),i=12)
# feature15,160-->960-->160
SaveFoldedInvertedResidualParam(param_dict=model.features[15].state_dict(),i=13)
# feature16,160-->960-->160
SaveFoldedInvertedResidualParam(param_dict=model.features[16].state_dict(),i=14)
# feature17,160-->960-->320
SaveFoldedInvertedResidualParam(param_dict=model.features[17].state_dict(),i=15)
#Tail
SaveFoldedTailParam(param_dict1=model.features[18].state_dict(),param_dict2=model.classifier.state_dict())
folded_param_save(model)
保存得到的权重参数以及数据集:

加速器HLS设计
由于MobileNet V2由多个计算构成,因此我们设计了多个IP,分别加速不同的运算,主要有:
pwconv:加速point-wise卷积
dwconv:加速depth-wise卷积
conv:加速网络第一层的标准3x3s2卷积(网络第一层计算量也很大,因此也得加速,很无奈)
fc:加速全局平均池化层和全连接层
工程代码如下:
 这里,我们着重看dwconv和pwconv的设计。
这里,我们着重看dwconv和pwconv的设计。
dwconv
dwconv,depth-wise卷积,一个通道对应一个卷积核,因此没有标准卷积中的通道求和操作,如下图所示
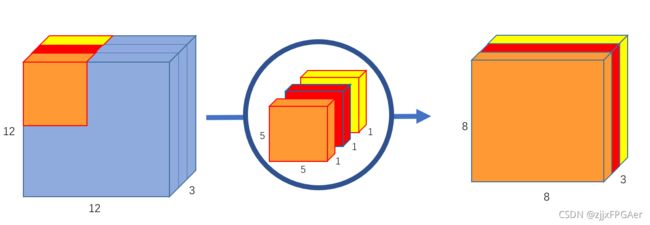 我们将该卷积过程分为三个阶段:加载数据、计算卷积以及写回结果,为了掩盖数据的传输时间,我们进行了粗粒度流水线,即乒乓(双缓冲)操作,部分代码如下:
我们将该卷积过程分为三个阶段:加载数据、计算卷积以及写回结果,为了掩盖数据的传输时间,我们进行了粗粒度流水线,即乒乓(双缓冲)操作,部分代码如下:
//
bool pp=true;
BlockID load_block,com_block,store_block;
//阶段1
load_block.ch=0;
load_block.row=0;
load_block.col=0;
load_wrapper(in1,in2,weight,wt_buff1,fm_in_buff1,fm_size,load_block,stride);
//阶段2
update_block(o_fm_size,load_block);
com_block.ch=0;
com_block.row=0;
com_block.col=0;
compute(fm_in_buff1,wt_buff1,bias_buff[com_block.ch/Tm],fm_out_buff1,stride);
load_wrapper(in1,in2,weight,wt_buff2,fm_in_buff2,fm_size,load_block,stride);
//
update_block(o_fm_size,load_block);
update_block(o_fm_size,com_block);
store_block.ch=0;
store_block.row=0;
store_block.col=0;
while(1){
#pragma HLS LOOP_TRIPCOUNT min=62 max=62 avg=62
if(load_block.ch+Tm>channel)
break;
if(pp){
load_wrapper(in1,in2,weight,wt_buff1,fm_in_buff1,fm_size,load_block,stride);
compute(fm_in_buff2,wt_buff2,bias_buff[com_block.ch/Tm],fm_out_buff2,stride);
store_output(out1,out2,fm_out_buff1,fm_size,store_block,stride);
pp=false;
}
else{
load_wrapper(in1,in2,weight,wt_buff2,fm_in_buff2,fm_size,load_block,stride);
compute(fm_in_buff1,wt_buff1,bias_buff[com_block.ch/Tm],fm_out_buff1,stride);
store_output(out1,out2,fm_out_buff2,fm_size,store_block,stride);
pp=true;
}
update_three_block(o_fm_size,load_block,com_block,store_block);
}
if(pp){
compute(fm_in_buff2,wt_buff2,bias_buff[com_block.ch/Tm],fm_out_buff2,stride);
store_output(out1,out2,fm_out_buff1,fm_size,store_block,stride);
//
update_three_block(o_fm_size,load_block,com_block,store_block);
store_output(out1,out2,fm_out_buff2,fm_size,store_block,stride);
}
else{
compute(fm_in_buff1,wt_buff1,bias_buff[com_block.ch/Tm],fm_out_buff1,stride);
store_output(out1,out2,fm_out_buff2,fm_size,store_block,stride);
//
update_three_block(o_fm_size,load_block,com_block,store_block);
store_output(out1,out2,fm_out_buff1,fm_size,store_block,stride);
}
这里我们并没有直接使用DATAFLOW指令,而是通过显示的if-else加乒乓变量实现,综合结果表明,乒乓操作生效了,如下图所示
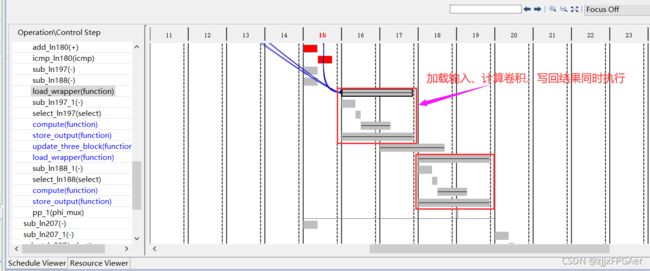
同时,为了加快数据传输,我们将接口位宽增大为64bit,可一次性传输4个16bit的定点数,此外,我们还是用了多个传输接口,以进一步增大数据传输的带宽

pwconv
pwconv,即1x1的标准卷积,它不改变特征图的大小,只改变特征图的通道数,在MobileNet V2中,它起着升维和降维的作用,此外,mobilenet v2的主要计算量都集中在pwconv,因此,加速pwconv是最重要的。
然而,不同于3x3标准卷积,pwconv实际上就是一个矩阵乘法,其计算/访存比较低,是memory-bounded的,因此,设计的思路主要就是增大数据传输的带宽,包括增大接口位宽、增大突发传输长度以及增加接口数目等。
下面是加载输入特征的代码:
void load_input(data_t fm_in_buff[Tn][Tp],data_pack_t* in1,data_pack_t* in2,unsigned short n,unsigned short basePixAddr,unsigned short fm_size,bool flag){
//load input tile In[n:n+Tn][basePixAddr:basePixAddr+Tp]
//load In_interleave[n/4:n/4+1][basePixAddr:basePixAddr+Tp][:]
unsigned short nn;
unsigned short i;
int length;
if(flag){
length=49;
}
else{
length=Tp;
}
for(i=0;i<length;i++){
#pragma HLS PIPELINE
data_pack_t tmp1=*(in1+(n/4)*fm_size*fm_size+basePixAddr+i);
data_pack_t tmp2=*(in2+(n/4+1)*fm_size*fm_size+basePixAddr+i);
for(int k=0;k<Tn/2;k++){
#pragma HLS UNROLL
fm_in_buff[k][i].range(15,0)=tmp1.range(16*k+15,16*k);
fm_in_buff[4+k][i].range(15,0)=tmp2.range(16*k+15,16*k);
}
}
}
可以看到,为了增加数据传输带宽,这里使用了两个接口(in1,in2)来并行的读取数据,并且每个接口,位宽都是64bit的,和HP接口的最大64bit相匹配,同时,两个接口的数据读取都是地址连续的,这样可以通过较长的突发传输长度,来抵消读地址通道握手所需的时间以及第一个数据读出所需等待的时间的开销。
和dwconv一样,pwconv也通过乒乓操作来掩盖数据的传输时间:
硬件设计
在vivado中进行block design,结果如下:

综合、实现、生成bitstream
SDK设计
SDK代码如下,这里就不一一列出
数据集和权重被存储在SD卡上,我们通过xilinx提供的ff.h中的API进行数据的读取,以下是整个工程的main文件
#include"inference.h"
#include"pl_conv.h"
#include "xtime_l.h"
#pragma GCC optimize(3,"Ofast","inline")
int main()
{
SD_Init(); //import!
pl_pwconv_init(&hls_pwconv);
pl_dwconv_init(&hls_dwconv);
pl_shortcut_init(&hls_shortcut);
pl_conv_init(&hls_conv);
pl_fc_init(&hls_fc);
int N=250;
NetParam_q *netParam=(NetParam_q*)malloc(sizeof(NetParam_q));
SpaceAllocateq(netParam);
ReadParamq("weight\\",netParam);
short* image=(short*)malloc(sizeof(short)*(N*3*224*224));
read_param_q(image,N*3*224*224,"weight\\image.bin");
float* label=(float*)malloc(sizeof(float)*N);
read_param(label,N,"weight\\label.bin");
int correct=0;
short *out=(short*)malloc(sizeof(short)*5);
Xil_DCacheFlush();
printf("N=%d\n",N);
XTime tEnd, tCur;
u32 tUsed;
for(int i=0;i<N;i++){
printf("i=%d\n",i);
XTime_GetTime(&tCur);
inference_q(image+i*3*224*224,netParam,out);
XTime_GetTime(&tEnd);
tUsed = ((tEnd-tCur)*1000000)/(COUNTS_PER_SECOND);
xil_printf("total time elapsed is %d us\r\n",tUsed);
float max_idx=-1;
int max_value=-9999;
for(int k=0;k<5;k++)
if(out[k]>max_value){
max_value=out[k];
max_idx=k;
}
if(max_idx==label[i])
correct++;
printf("%d,%d\n",(int)max_idx,(int)label[i]);
}
printf("test accuracy is %f\n",correct/(float)N);
SpaceDeleteq(netParam);
return 0;
}
注意:不要忘了修改堆栈大小,否则无法读取这么多测试数据,整个程序会卡住
结果
我们测试了250张图片,下图的结果表明,每张图片推理用时约为91ms,推理的准确率为98%(显然这个推理时间还能继续提升(只用了7020的一半资源))
