动手学深度学习2——二维卷积层
二维卷积层
深度学习中的卷积运算实际上是互相关运算。
互相关运算:即输入数组和核数组对应位置相乘求和的过程。
特征图:二维卷积层输出的二维数组可以看作是输入在空间维度(高和宽)上某一级的表征。
感受野:影响元素x的前向计算的所有可能输入区域(可能大于输入的实际尺寸)叫做x的感受野。



多输入通道和多输出通道
多输入通道:当输入数据含多个通道时,需要构造一个输入通道数与输入数据的通道数相同的卷积核,从而能够与含多通道的输入数据做互相关运算。
多输出通道:当输入通道有多个时,因为对各个通道的结果做了累加,所以不论输入通道数是多少,输出通道数总是为1。
1x1卷积层:1x1卷积层的作用与全连接层等价。
池化层pooling
池化层:为了缓解卷积层对位置的过度敏感性。
同卷积层一样,池化层每次对输入数据的一个固定形状窗口(又称池化窗口)中的元素计算输出。不同于卷积层里计算输入和核的互相关性,池化层直接计算赤化窗口内元素的最大值或者平均值。该运算也分别叫做最大池化或平均池化。
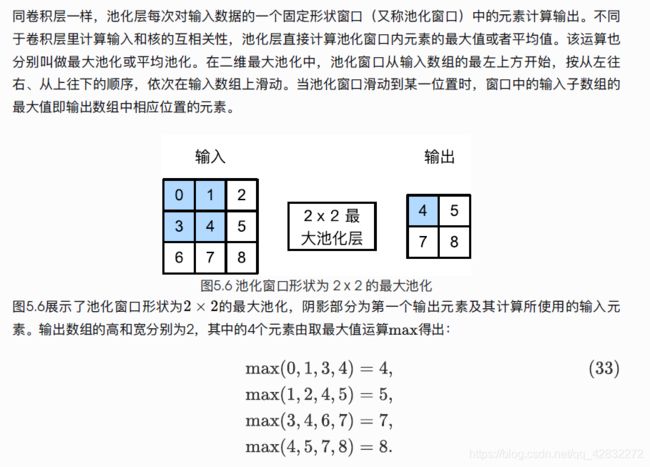
池化层对物体边缘检测有很好的效果。

多通道:在处理多通道输入数据时,池化层对每个输入通道分别池化,而不是像卷积层那样将各通道的输入按通道相加。这意味着池化层的输出通道数与输入通道数相等。可以指定池化层的填充和步幅。
卷积神经网络

LeNet模型:
import time
import torch
from torch import nn,optim
import sys
sys.path.append('..')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1,6,5), #in_channels,out_channels,kernel_size
nn.Sigmoid(),
nn.MaxPool2d(2,2), #kernel_size,stride
nn.Conv2d(6,16,5),
nn.Sigmoid(),
nn.MaxPool2d(2,2)
)
self.fc = nn.Sequential(
nn.Linear(16*4*4,120),
nn.Sigmoid(),
nn.Linear(120,84),
nn.Sigmoid(),
nn.Linear(84,10)
)
def forward(self,img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0],-1))
return output
net = LeNet()
print(net)
获取数据和训练模型
在这里插入代码片
深度卷积神经网络(ALEXNET)

简化后的AlexNet:
import time
import torch
from torch import nn,optim
import sys
sys.path.append('..')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1,96,11,4), #in_channels,out_channels,kernel_size,stride,padding
nn.ReLU(),
nn.MaxPool2d(3,2), #kernel_size,stride 减小卷积窗口,
# 使用填充为2来使得输入和输出的高和宽一致,且增大输出通道数
nn.Conv2d(96,256,5,1,2),
nn.ReLU(),
nn.MaxPool2d(3,2),
#连续3个卷积层,且使用更小的卷积窗口,除了最后的卷积层外,进一步增大了输出通道数
#前两个卷积层后不使用池化层来减小输入的高和宽
nn.Conv2d(256,384,3,1,1),
nn.ReLU(),
nn.Conv2d(384,384,3,1,1),
nn.ReLU(),
nn.Conv2d(384,256,3,1,1),
nn.ReLU(),
nn.MaxPool2d(3,2)
)
#这里全连接层的输出个数比LeNet中的大数倍,使用丢弃层来缓解过拟合
self.fc=nn.Sequential(
nn.Linear(256*5*5,4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096,4096),
nn.ReLU(),
nn.Dropout(0.5),
#输出层
nn.Linear(4096,10),
)
def forward(self,img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0],-1))
return output
net = AlexNet()
print(net)
读取数据:
在这里插入代码片
训练:
在这里插入代码片
使用重复元素的网络(VGG)

import time
import torch
from torch import nn,optim
import sys
sys.path.append('..')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
conv_arch = ((1,1,64),(1,64,128),(2,128,256),(2,256,512),(2,512,512))
fc_feature = 512*7*7
fc_hidden_units = 4096
def vgg(conv_arch,fc_features,fc_hidden_units=4096):
net = nn.Sequential(
for i,(num_convs,in_channels,out_channels) in enumerate(conv_arch):
net.add_module("vgg_block_"+str(i+1),vgg_block(num_convs,in_channels,out_channels))
net.add_module("fc",nn.Sequential(d21.FlattenLayer(),
nn.Linear(fc_features,fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units,fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units,10)))
return net
net = vgg(conv_arch,fc_feature,fc_hidden_units)
x = torch.rand(1,1,224,224)
for name,blk in net named_children():
x = blk(x)
print(name,'output shape:',x.shape)
获取数据和训练模型:
在这里插入代码片
NIN块
卷积层的输入和输出通常是四维数组(样本,通道,高,宽)。
import time
import torch
from torch import nn,optim
import torch.nn.functional as F
import sys
sys.path.append("..")
#import d21zh_pytorch as d21
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def nin_block(in_channels,out_channels,kernel_size,stride,padding):
blk = nn.Sequential(
nn.Conv2d(in_channels,out_channels,kernel_size,stride,padding),
nn.ReLU(),
nn.Conv2d(out_channels,out_channels,kernel_size=1),
nn.ReLU(),
nn.Conv2d(out_channels,out_channels,kernel_size=1),
nn.ReLU()
)
return blk
class GlobalAvgPool2d(nn.Module):
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self,x):
return F.avg_pool2d(x,kernel_size = x.size()[2:])
net = nn.Sequential(
nin_block(1.96,kernel_size=11,stride=4,padding=0),
nn.MaxPool2d(kernel_size=3,stride=2),
nin_block(96,256,kernel_size=5,stride=1,padding=2),
nn.MaxPool2d(kernel_size=3,stride=2),
nin_block(256,384,kernel_size=3,stride=1,padding=1),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Dropout(0.5),
#标签类别数是10
nin_block(384,10,kernel_size=3,stride=1,padding=1),
GlobalAvgPool2d(),
#将四维的输出转成二维的输出,其形状为(批量大小,10)
d21.FlattenLayer()
)
x = torch.rand(1,1,224,224)
for name,blk in net.named_children():
x = blk(x)
print(name,'output shape:',x.shape)
获取数据和训练模型:
batch_size = 128
# “out of memory”如果出现“out of memory”的报错信息,可减小batch_size或resize
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size,
resize=224)
lr, num_epochs = 0.002, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer,
device, num_epochs)
含并行连结的网络(GOOGLENET)
import time
import torch
from torch import nn,optim
import torch.nn.functional as F
import sys
sys.path.append("..")
#import d21zh_pytorch as d21
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class Inception(nn.Module):
def __init__(self,in_c,c1,c2,c3,c4):
super(Inception, self).__init__()
#线路1 单1 x 1卷积层
self.p1_1 = nn.Conv2d(in_c,c1,kernel_size=1)
#线路2 1 x 1卷积层后接3 x 3卷积层
self.p2_1 = nn.Conv2d(in_c, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3,
padding=1)
# 线路3 1 x 1卷积层后5 x 5卷积层
self.p3_1 = nn.Conv2d(in_c, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5,
padding=2)
# 线路4 3 x 3最大池化层后接1 x 1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1,
padding=1)
self.p4_2 = nn.Conv2d(in_c, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
return torch.cat((p1, p2, p3, p4), dim=1)
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2,padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
d2l.GlobalAvgPool2d())
net = nn.Sequential(b1, b2, b3, b4, b5,
d2l.FlattenLayer(), nn.Linear(1024, 10))
net = nn.Sequential(b1, b2, b3, b4, b5, d2l.FlattenLayer(),
nn.Linear(1024, 10))
X = torch.rand(1, 1, 96, 96)
for blk in net.children():
X = blk(X)
print('output shape: ', X.shape)
batch_size = 128
# 如果出现“out of memory”的报错信息,可减小batch_size或resize
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size,
resize=96)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer,
device, num_epochs)
批量归一化

批量归一化层:
在这里插入代码片
RESNET残差网络
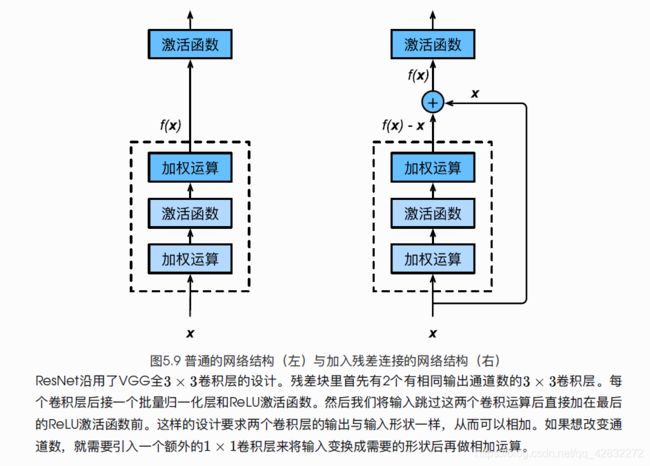
在这里插入代码片
DENSENT稠密连接网络

稠密块
import time
import torch
from torch import nn,optim
import torch.nn.functional as F
import sys
sys.path.append("..")
#import d21zh_pytorch as d21
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def conv_block(in_channels,out_channels):
blk = nn.Sequential(
nn.BatchNorm2d(in_channels),
nn.ReLU(),
nn.Conv2d(in_channels,out_channels,kernel_size=3,padding=1)
)
return blk
class DenseBlock(nn.Module):
def __init__(self,num_convs,in_channels,out_channels):
super(DenseBlock, self).__init__()
net=[]
for i in range(num_convs):
in_c = in_channels+i*out_channels
net.append(conv_block(in_c,out_channels))
self.net = nn.ModuleList(net)
self.out_channels = in_channels+num_convs*out_channels
def forward(self,x):
for blk in self.net:
y = blk(x)
x = torch.cat((x,y),dim=1)
return x
blk = DenseBlock(2,3,10)
x = torch.rand(4,3,8,8)
y = blk(x)
print(y.shape)
过渡层
def transition_block(in_channels,out_channels):
blk = nn.Sequential(
nn.BatchNorm2d(in_channels),
nn.ReLU(),
nn.Conv2d(in_channels,out_channels,kernel_size=1),
nn.AvgPool2d(kernel_size=2,stride=2)
)
return blk
blk = transition_block(23,10)
blk(y).shape
DENSENET模型
#DENSENET模型
net = nn.Sequential(
nn.Conv2d(1,64,kernel_size=7,stride=2,padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2,padding=1)
)
num_channels, growth_rate = 64, 32 # num_channels为当前的通道数
num_convs_in_dense_blocks = [4, 4, 4, 4]
for i, num_convs in enumerate(num_convs_in_dense_blocks):
DB = DenseBlock(num_convs, num_channels, growth_rate)
net.add_module("DenseBlosk_%d" % i, DB)
# 上一个稠密块的输出通道数
num_channels = DB.out_channels
# 在稠密块之间加入通道数减半的过渡层
if i != len(num_convs_in_dense_blocks) - 1:
net.add_module("transition_block_%d" % i,
transition_block(num_channels, num_channels // 2))
num_channels = num_channels // 2
net.add_module("BN", nn.BatchNorm2d(num_channels))
net.add_module("relu", nn.ReLU())
net.add_module("global_avg_pool", d2l.GlobalAvgPool2d())
#GlobalAvgPool2d的输出: (Batch, num_channels, 1, 1)
net.add_module("fc", nn.Sequential(d2l.FlattenLayer(),
nn.Linear(num_channels, 10)))
X = torch.rand((1, 1, 96, 96))
for name, layer in net.named_children():
X = layer(X)
print(name, ' output shape:\t', X.shape)