ICCV2021 | 简单有效的长尾视觉识别新方案:蒸馏自监督(SSD)
前言
本文提出了一种概念上简单但特别有效的长尾视觉识别的多阶段训练方案,称为蒸馏自监督(Self Supervision to Distillation, SSD)。在三个长尾识别基准:ImageNet-LT、CIFAR100-LT和iNaturist 2018上取得了SOTA结果。在不同的数据集上,SSD比强大的LWS基准性能高出2.7%到4.5%。
本文来自公众号CV技术指南的论文分享系列
关注公众号CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。

论文:Self Supervision to Distillation for Long-Tailed Visual Recognition
Backgound
深度学习通过在大规模、平衡和精选的数据集(如ImageNet和Kinetics上训练强大的神经网络,在图像和视频领域的视觉识别方面取得了显著的进展。与这些人工平衡的数据集不同,真实世界的数据总是遵循长尾分布,这使得收集平衡数据集更具挑战性,特别是对于样本稀少的自然类。然而,由于数据分布高度不平衡,直接从长尾数据中学习会导致显著的性能退化。
缓解长尾训练数据造成的恶化的一系列常见方法是基于类别重新平衡策略,包括重新采样训练数据和设计成本敏感的重新加权损失函数。这些方法可以有效地减少训练过程中头部类的支配,从而产生更精确的分类决策边界。然而,由于原始数据分布是扭曲的,而过度参数化的深层网络很容易拟合这种合成分布,因此它们经常面临过拟合尾类的风险。

图1.真实世界的数据总是遵循长尾数据分布,这是由几个样本丰富的头部类(即蓝色立方体)主导的,但也包含许多数据稀缺的尾类(即绿立方体和黄色立方体),称为原始分布。直接从长尾数据学习可能会导致性能显著下降。处理不平衡问题的一种常见方法是重新采样,即随机地从头类中丢弃图像,并从尾类中重复采样图像(相同的图像用唯一的罗马数字标记),从而产生均匀分布。这种策略可能会导致尾部类过多,而头部类不合适。
为了克服这些问题,最近的工作分离了表示学习和分类器训练的任务。该两阶段训练方案首先学习原始数据分布下的视觉表示,然后在类均衡采样下训练冻结特征的线性分类器。事实证明,这个简单的两阶段训练方案能够处理过度拟合的问题,并在标准的长尾基准上设定了新的SOTA性能。然而,这种两阶段训练方案不能很好地处理不平衡的标签分配问题,特别是在表征学习阶段。
创新思路
论文的目标是设计一种新的长尾视觉识别学习范式,以期共享两种长尾识别方法的优点,即对过拟合问题具有较强的鲁棒性,并有效地处理不平衡标签问题。为了达到这一目标,论文的想法是研究如何将标签相关性纳入到一个多阶段的训练方案中。
受到模型压缩中知识蒸馏工作的启发,作者观察到由教师网络产生的软标签能够捕获类之间的内在关系,这可能有助于通过将知识从头部类转移到尾部类来进行长尾识别,如图1所示。因此,软标签为标签建模的多阶段训练策略提供了一种实用的解决方案。
基于上述分析,论文提出了一种概念上简单但特别有效的长尾视觉识别的多阶段训练方案,称为蒸馏自监督(Self Supervision to Distillation, SSD)。
SSD的主要贡献有两个方面:
(1)用于学习有效的长尾识别网络的自蒸馏框架;
(2)自监督引导的蒸馏标签生成模块,为自蒸馏提供更少偏向但更多信息的软标签。
具体地说,首先将多级长尾训练流水线简化在一个简单的自精馏框架内,在该框架中我们能够自然地自动挖掘标签关系,并结合这种固有的标签结构来提高多级训练的泛化性能。
然后,为了进一步提高自精馏框架的健壮性,论文从长尾训练集本身出发,提出了一种自监督的增强精馏标签生成模块。自监督学习能够在没有标签的情况下学习有效的视觉表征,并且可以平等对待每幅图像,从而缓解了标签分布不平衡对软标签生成的影响。
综上所述,论文的主要贡献如下:
-
提出了一种简单有效的多阶段训练框架(SSD)。在该框架中,通过将软标签建模引入特征学习阶段,共享了再平衡采样和解耦训练策略的优点。
-
提出了一种自监督引导的软标签生成模块,该模块可以同时从数据域和标签域生成鲁棒的软标签。这些软标签通过从头到尾传递知识来提供有效的信息。
-
SSD在三个具有挑战性的长尾识别基准测试(包括ImageNet-LT、CIFAR100-LT和iNaturist 2018数据集)上实现了SOTA性能。
Methods
蒸馏自监控(SSD)的总体框架如图2所示。SSD由三个步骤组成:(1)自监督引导的特征学习;(2)中间软标签生成;(3)联合训练和自蒸馏。

图2.自监督蒸馏(SSD)框架的管道。
论文首先使用实例平衡抽样同时训练标签监督和自监督下的初始教师网络。
然后,通过类均衡采样细化类决策边界,在视觉表示的基础上训练一个单独的线性分类器。这种新的分类器产生训练样本的软标签,用于自蒸馏。
最后,在前一阶段的软标签和原始训练集中的硬标签的混合监督下训练一个自精馏网络。由于硬标签和软标签在是否偏向头部类的问题上存在语义鸿沟,论文对这两种监督分别采用了两个分类头。
自监督引导的特征学习
在这一阶段,在原始的长尾数据分布下训练网络进行分类任务。分类任务由两部分组成:一是传统的C-Way分类任务,其目的是将图像分类到C语义类别;二是纯粹从数据本身出发的平衡的自监督分类任务。虽然C-way分类任务提供了丰富的语义信息,但它也受到长尾标签的影响。尾部类的样本可能会被数据丰富的类淹没,从而导致表示不足的问题。
因此,论文构造了均衡的自监督分类任务,例如预测图像旋转和实例判别,这些任务在不受标签影响的情况下平等地考虑每幅图像。旋转预测识别{0◦,90◦,180◦,270◦}之间的旋转角度。实例判别将每个图像视为一个单一类别,该类别等同于TON-WAY分类,其中N是训练集中的图像数量。
中间软标签生成
在此阶段,需要在冻结要素之上的类平衡设置下调优分类器,以生成提取的标签。论文选择了可学习权重缩放(LWS)方法,因为它在各种设置下都有良好的性能。它学习重新调整分类器的权重,以避免类头部的倾向。在给定图像的情况下,微调的分类器提供了相对平衡和软的标签,集成了标签驱动和数据驱动的信息,作为下一步自蒸馏的教师监督。
联合训练和自蒸馏
由于表示和分类器是在不同的采样策略下分别训练的,因此整个网络可能不是最优的。然而,在分类器学习阶段对骨干网络进行直接微调会损害泛化能力。相反,论文提出在原有的长尾数据分布下,结合原始标签和平衡提取标签的混合监督,联合训练另一个骨干网络和分类器。
在这个阶段对网络进行初始化,因为以前的表示仍然是相对有偏差的,很难通过微调来摆脱局部极小值。此外,其他自训练论文也发现类似的结论,即从头开始训练学生比由老师初始化学生要好。在学习混合监督后,最终的模型可以获得比教师模型更高的性能,此外,额外的分类器微调步骤是可选的,但建议进一步提高性能(IV-分类器微调)。
通过自我监督增强特征学习
在特征学习的第一阶段,论文选择使用标准监督任务和自监督任务以多任务学习的方式训练骨干网络。由于标签的高度偏见,监督任务可能会忽略数据稀缺类的图像,而自监督任务会平等对待每个样本,而不受长尾标签的影响。形式上,设θ为共享骨干网的参数,ω为监督任务的参数,ω为自监督任务的选择参数。
然后,有标签的输入图像的自监督任务损失函数可表示为L_self(x;θ,ω_Self),L_sup(x,y;θ,ω_sup)表示监督交叉熵损失。这一阶段的总损失如下所示:
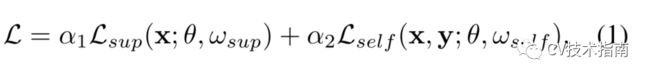
选择旋转预测和实例判别作为自监督代理任务。网络可以通过解决这些代理任务来学习正确地表示图像。
旋转预测
预测图像旋转是一种简单而有效的经典的自监督任务。给定一个图像,将其在{0◦,90◦,180◦,270◦}之间随机旋转一个角度,以获得旋转的x‘。这两个图像同时发送到网络。原始图像用于原始的交叉熵损失。选择旋转的x‘来预测旋转度,该旋转度可以表示为一个4向平衡分类问题。在这种情况下,特定参数ω自身被实现为传统的4向线性分类器。
实例判别
在实例判别任务中,将每幅图像看作一个不同的类别,并学习一个非参数分类器对每幅图像进行分类。形式化地称图像的ℓ2-归一化嵌入,v‘i是从具有不同变换的图像副本中提取的ℓ2归一化嵌入。实例判别的损失可能是:
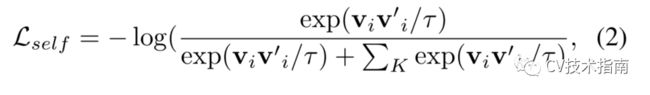
其中τ是温度,K是作为底片样本的其他图像的数量,可以从内存库和当前小批次中检索。论文建立了一个带有特征队列的动量网络,以产生大量的负样本,并利用MLP投影头ω自身将主干输出转换到低维特征空间。
基于自蒸馏的长尾识别
论文用硬标签和软标签来表示训练图像。目标是学习一个嵌入函数F,它编码成特征向量f=F(x;θ),以及两个分类器G_hard和G_soft,特征向量f将被发送到两个线性分类器G_hard和G_soft,以得到输出逻辑z_hard=G_hard(F)和z_sof t=G_soft(F)。z~表示教师模型的输出,则软标签为:

T是默认设置为2的温度。然后,知识蒸馏损失写成:
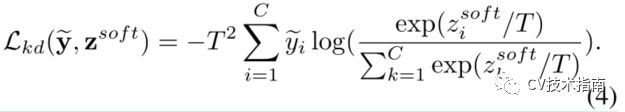
对于硬标签监督,使用标准交叉熵损失Lce。因此,最终的损失是这两个损失的组合:
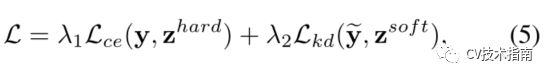
Conclusion
在三个长尾识别基准:ImageNet-LT、CIF AR100-LT和iNaturist 2018上取得了SOTA结果。在不同的数据集上,SSD比强大的LWS基准性能高出2.7%到4.5%。
1. ImageNet-LT数据集的TOP-1精度。与以ResNeXt-50为主干的SOTA方法进行比较。

2. 在不平衡因子为100、50和10的CIFAR100-LT数据集上的TOP-1精度。与以ResNet-32为骨干网络的最新方法进行了比较。

欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “入门指南“可获取计算机视觉入门所有必备资料。

其它文章
AAAI2021 | 任意方向目标检测中的动态Anchor学习
ICCV2021 | 用于视觉跟踪的学习时空型transformer
论文的科学写作与哲学
计算机视觉中的传统特征提取方法总结
ICCV2021 | TOOD:任务对齐的单阶段目标检测
Pytorch 数据流中常见Trick总结
计算机视觉中的transformer模型创新思路总结
PNNX: PyTorch 神经网络交换格式
论文创新的常见思路总结 | 卷积神经网络压缩方法总结
神经网络超参数的调参方法总结 | 数据增强方法总结
Batch Size对神经网络训练的影响 | 计算机视觉入门路线
论文创新的常见思路总结 | 池化技术总结
归一化方法总结 | 欠拟合与过拟合技术总结
注意力机制技术总结 | 特征金字塔技术总结
2021-视频监控中的多目标跟踪综述
一文概括机器视觉常用算法以及常用开发库
统一视角理解目标检测算法:最新进展分析与总结
给模型加入先验知识的常见方法总结 | 谈CV领域审稿
全面理解目标检测中的anchor | 实例分割综述总结综合整理版
HOG和SIFT图像特征提取简述 | OpenCV高性能计算基础介绍
目标检测中回归损失函数总结 | Anchor-free目标检测论文汇总
2021年小目标检测最新研究综述 | 小目标检测常用方法总结
单阶段实例分割综述 | 语义分割综述 | 多标签分类概述
视频目标检测与图像目标检测的区别
视频理解综述:动作识别、时序动作定位、视频Embedding
资源分享 | SAHI:超大图片中对小目标检测的切片辅助超推理库