GPU等专用芯片以较低的成本提供海量算力,已经成为机器学习领域的核心利器,在人工智能时代发挥着越来越重要的作用。如何利用GPU这一利器赋能业务场景,是很多技术研发者都要面临的问题。本文分享了美团外卖搜索/推荐业务中模型预估的GPU架构设计及落地的过程,希望能对从事相关应用研发的同学有所帮助或启发。
1 前言
近些年,随着机器学习技术的蓬勃发展,以GPU为代表的一系列专用芯片以优越的高性能计算能力和愈发低廉的成本,在机器学习领域得到广泛认可和青睐,且与传统的CPU体系不断融合,形成了新的异构硬件生态。
在这种技术浪潮之中,很多技术研发者会面临着这样的问题:在我们的业务上应用GPU硬件能获得什么?如何快速、平滑地从传统CPU体系基础上完成切换?站在机器学习算法设计的角度,又会带来什么影响和改变?在GPU生态下众多的技术路线和架构选型中,如何找到一条最适合自身场景的路径?
美团外卖搜索推荐团队,也面临着类似的挑战和问题。本文我们会分享美团外卖搜索/推荐业务中,模型预估的GPU架构设计与落地过程,并将一些技术细节和测试数据做了详尽的披露,希望能为广大的技术同行提供一些有价值的参考。
2 背景
当前,美团外卖主要通过搜索和推荐两种流量分发方式,满足用户对“万物到家”的需求。除了首页的搜索、推荐功能外,重点品类会在首页增加独立入口(下文称之为“金刚”),每个金刚入口中都有类似于首页搜索、推荐的区域,而不同场景入口共同服务于外卖的最终成单。首页、金刚、店内的联动关系如下图所示:
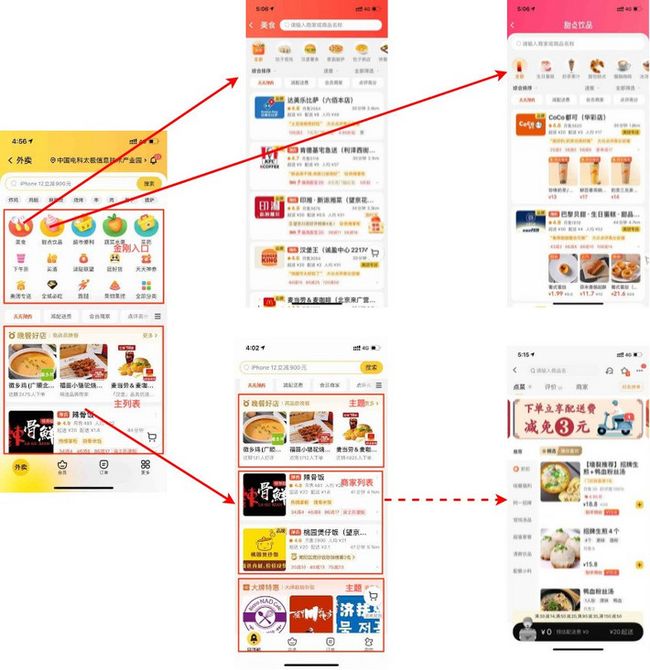
面向点击率(CTR)/转化率(CVR)预估的深度学习,是每一个电商类搜索/推荐产品中的核心技术,直接决定了产品的用户体验和转化效果,同时也是机器资源消耗的“大户”。而CTR/CVR精排模型的设计和实践,也是美团外卖搜索推荐(下称搜推)技术团队必须要攻克且不断追求卓越的必争之地。
从搜推系统设计的角度上看,不同的搜索、推荐入口会自然形成独立的调用链路。在传统的模型设计思路下,会对不同入口链路、不同漏斗环节的CTR/CVR/PRICE多个目标独立设计模型,这也是美团外卖搜推过往模型设计的经典方式。而从2021年起,基于多场景全局优化的考量,搜推场景的CTR/CVR预估模型开始逐步走向多模型统一,综合利用多个入口的数据、结合不同入口自身的业务特点实现多个入口的联动优化,逐步实现“One Model to Serve All”的目标。
从模型计算实践的角度上看,外卖精排模型的发展,让模型Dense网络的计算量显著膨胀,以CPU为计算主力的软硬件架构已经难以应对算法的发展需求,即便成本消耗大幅加剧,算力天花板仍然“近在咫尺”。而GPU硬件面向稠密计算的算力优势,恰恰吻合新的模型特点,可以从根本上打破精排模型预估/训练中的算力困局。因此,从2021年开始,美团外卖搜推场景的深度学习体系开始逐步从纯CPU架构走向CPU+GPU的异构硬件计算平台,以满足美团外卖模型算法演进对算力的新要求。
本文接下来的内容,会从外卖搜推场景的精排模型设计出发,结合美团实际的软硬件特点,为大家详细分享在外卖精排模型预估领域,从纯CPU架构转型到CPU+GPU异构平台的探索和实践过程,供广大技术同行参考。
3 外卖搜推场景下的精排模型
本章节主要介绍在外卖场景下多模型统一的演进思路、模型特点以及在实践中的挑战。本文只对模型设计思路做简单的说明,引出后续模型计算在GPU落地中的实践思考。
3.1 精排模型的设计思路
如前文所述,在美团外卖多入口联动的场景特点下,经典的单体模型设计存在着以下局限:
- 首页推荐与各金刚入口推荐各维护一个精排模型,不仅维护成本高而且训练数据割裂,导致精排模型不能捕捉到用户在所有推荐场景的兴趣。
- 推荐场景的精排模型只使用推荐场景的训练样本,未利用用户在其他重要入口的训练样本,比如搜索、订单页,模型只学习到用户在局部场景的偏好信息。
- 推荐场景的训练样本中存在Position Bias问题,具体是指用户点击一个商家,有可能只是因为该商家在推荐Feeds中排序位置比较靠前,而非因为用户对此商家真正感兴趣,此类Bias会引起模型训练有偏。
- 多目标之间存在贝叶斯约束,网络结构中未考虑,CXR=CTR × CVR,CXR预估值应比CTR小,模型在验证集上会出现CXR比CTR还高的现象,预估不准确。
基于此,在2021年,美团外卖搜推场景提出了向超越单体的多模型统一演进、逐步实现“One Model to Serve All”的思想,这一理念在模型设计中具体体现在:
- CTR/CXR多目标的融合,实现多目标预测的模型统一。
- 场景专家网络与Attention网络的融合,实现不同流量入口之间的模型泛化和统一。
- 领域专属网络和共享网络的融合,实现推荐场景向搜索场景的迁移学习。


随着外卖精排模型的发展和演进,模型Dense网络的参数量显著增加,单次推理的FLOPs达到26M,对CPU计算架构造成了巨大压力。另一方面,我们采用Float 16压缩、特征自动选择、网络交叉替代手动交叉特征等技术手段,将模型由100G缩小到10G以内,并且过程中通过模型的优化,做到了模型效果无损。
综上,外卖搜推精排模型稠密部分计算复杂、稀疏部分体积可控,这些良好的特性,为我们在GPU硬件架构上落地推理计算提供了相对适宜的模型算法基础。接下来,我们将探讨如何在高吞吐、低耗时的外卖搜索推荐系统中,利用GPU硬件有效解决外卖精排模型在线预估中的成本和性能问题,并给出我们的实践过程和结果。
3.2 模型应用的特点与挑战
在搜索/推荐技术领域中,稀疏模型预估(CTR/CVR)是决定算法效果的核心要素,模型预估服务是搜索推荐系统中必不可少的组成部分,业内各大公司已有很多经典的实现方案。在讨论具体实践之前,先介绍一下我们的场景特点:
① 需求层面
- 模型结构:如前文介绍,外卖场景下的精排模型的稠密网络部分相对复杂,单次推理的FLOPs达到26M;而模型的稀疏部分经过大量的优化,体积得到了有效的控制,模型规模在10G以内。
- 服务质量要求:推荐服务作为经典的高性能To C场景,业内大部分同类系统的超时控制在百毫秒量级,分解到预估服务,超时一般需要控制在十毫秒的量级。
② 软件框架层面
- 开发框架:模型开发采用TensorFlow框架[1]。作为主流的深度学习第二代框架,TensorFlow具备强大的模型表达能力,这也导致其算子粒度比较小,这一特点无论是对CPU还是GPU架构都会带来很大的额外开销。
- 在线服务框架:采用TensorFlow Serving框架[2]。基于此框架,可将离线训练好的机器学习模型部署到线上,并利用rpc对外提供实时预估服务。TensorFlow Serving支持模型热更新及模型版本管理,主要特点是使用灵活,性能较好。
③ 硬件层面
- 机型特性:美团基于提升算力密度的考量,在预估服务采用了GPU BOX机型。相对于传统的GPU插卡机型,这一类机型每张GPU卡配套的CPU和内存相对有限,这需要我们在设计在线服务时,精细化的考量CPU、GPU上的计算和数据分布,达到更好的利用率均衡。
- GPU固有属性:GPU kernel大体上可以划分为传输数据、kernel启动、kernel计算等几个阶段[3],其中每个kernel的启动需要约10us左右。因此,GPU预估会面临一个普适问题,大量的小算子导致每个kernel的执行时间很短,kernel启动的耗时占了大部分。相邻的kernel之间需要通过读写显存进行数据的传输,产生大量的访存开销。而GPU的访存吞吐远远低于计算吞吐,导致性能低下,GPU的利用率并不高。

总结而言,与业内其他主流搜推场景相对比,我们的CTR模型预估场景有两个明显特点:
- 稠密网络部分计算复杂度高,相对的,稀疏网络在模型设计环节经过了大量的优化,体积相对较小。
- 使用GPU BOX机型,单GPU卡的CPU配额受限,需要针对性优化CPU的计算负荷。
基于这两个特点,我们在面向GPU的优化实践中就可以更具针对性了。
4 模型服务架构概览
本章节简要介绍美团外卖搜推在线预估服务的整体架构和角色分工,也是外卖搜推精排模型在GPU落地实践的工程系统基础。
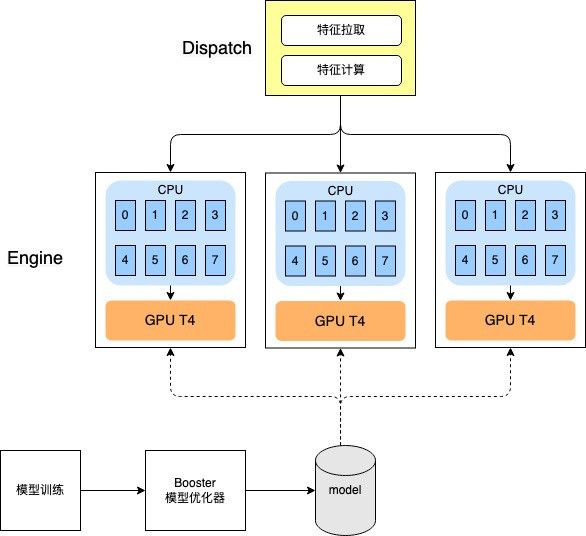
系统关键角色
- Dispatch:承担着特征获取和特征计算的职能,如前文所述,美团使用GPU BOX机型搭建预估服务,推理计算的CPU资源本身就十分吃紧,因此自然会考虑将在线特征工程部分独立部署,避免CPU资源的抢占。本部分和GPU实践关系不大,不是本文的重点。
- Engine:承担着模型在线推理的职能,通过RPC的方式输入特征矩阵、输出预估结果。采用GPU BOX机型(单容器8核+1 NVIDIA Tesla T4),平均响应时间需控制在20ms以内,下文所述GPU优化实践主要面向这一模块的特点进行。
- Booster:在模型更新过程中离线执行的模型优化器,内部以Optimizer插件的方式,混合了手工优化器插件和DL编译优化器插件,是下文所述GPU优化操作的执行者。
5 GPU优化实践
本章节将展开分享精排模型预估计算在GPU架构落地中的优化过程。
与CV、NLP等经典机器学习领域不同,以CTR模型为代表的稀疏模型由于结构多变、包含大量业务特化等原因,硬件供应商难以对这一类未收敛的模型结构提供端到端优化工具。因此,在CTR模型大规模应用的领域中,一般会结合GPU特性,面向使用场景对模型执行Case By Case的优化措施。按模型优化的目标来区分,可以大致分类为系统优化和计算优化:
① 系统优化:一般指通过对计算、存储、传输的调度,使CPU+GPU的异构硬件体系可以更有效率的协同和被使用。典型的系统优化包括:
- 设备摆放
- 算子融合
- GPU并发/流水线优化
② 计算优化:一般指面向硬件特性,优化模型前向推理网络的结构设计和算子执行逻辑,使模型推理计算在GPU上的计算开销更小,效率更高。典型的计算优化包括:
- 冗余计算去除
- 量化计算
- 高性能库的应用
在本文介绍的优化工作中,我们对上述常见优化中的大部分思路进行了探索和实践,下文会逐一进行阐述,并给出优化效果和面向实际场景的总结分析。
5.1 系统优化
5.1.1 设备摆放
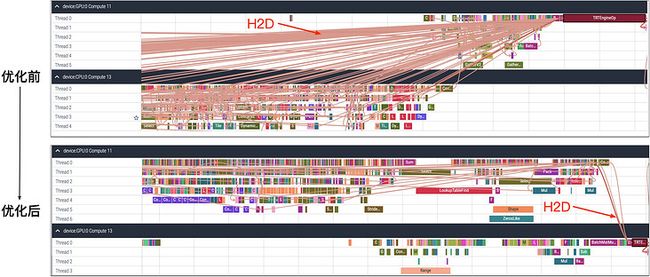
TensorFlow会为计算图中每个Node自动设置Runtime Device,计算较重者放置在GPU,计算较轻者放置在CPU。在复杂计算图中完成一次完整的inference,数据会在CPU和GPU之间反复传输。由于H2D/D2H传输很重,这会造成数据传输耗时远大于op(operator)内部计算耗时,在GPU下模型一次预估耗时为秒级别,远高于只使用CPU时的耗时。此外,如前所述,我们所使用的GPU机型上CPU资源受限(一张T4卡仅对应8核CPU),这也是我们在异构架构设计中需要解决的核心技术挑战。
为解决TensorFlow自动设定Runtime Device不合理的问题,我们为计算图中每个Node手动Set Runtime Device。考虑到CPU资源受限,我们尽量的将计算较重的子图(包括Attention子图、MLP子图)放置在GPU计算,计算较轻的子图(主要为Embedding查询子图)放置在CPU计算。
为进一步减少设备间数据传输,我们在CPU和GPU之间增加Concat op和Split op,CPU数据先Concat到一起再传输到GPU,之后再按需Split成多份并传给对应op,将H2D/D2H从上千次降低到数次。如下图所示,设备摆放优化之前,有大量的H2D数据传输;优化之后,H2D减少为3次,优化效果十分明显。
5.1.2 All On GPU
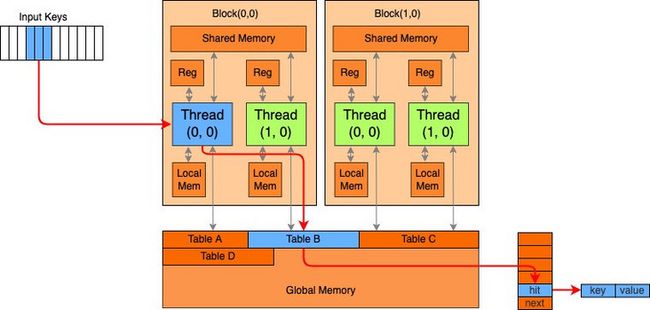
完成基本的设备摆放优化后,计算较轻的Sparse查询部分在CPU完成,计算较重的Dense计算部分在GPU完成。虽然CPU上计算较轻,但压测发现其仍旧是整体吞吐瓶颈。考虑到整体计算图较小(约2G),我们自然的想到是否可以将整图放在GPU执行,绕开CPU配额的限制,此即All On GPU。为了将原在CPU进行的Saprse查询改为在GPU执行,我们新增了LookupTable op的GPU实现。如下图所示,HashTable放置在GPU Global Memory,它的Key与Value统一存储在Bucket中。针对输入的多组Key,利用多个Block的Threads并行查询。
同时,为提高GPU利用效率,降低kernel launch开销,我们利用TVM对计算图进行编译优化(下文会进行详细介绍)。优化后的All On GPU模型图解决了CPU资源受限带来的瓶颈,整体吞吐提升明显(qps 55->220,约4倍)。
5.1.3 算子融合
外卖搜推精排模型十分复杂,计算图中包含上万个计算Node。GPU上执行计算图时,每个Node都有kernel launch开销,多个Node之间还有访问显存开销。此外,TensorFlow框架本身在Node执行时会带来一定开销,每个Node执行时都会创建、销毁Input/Output Tensor,内存控制引入额外成本。因此,计算图中Node过多会严重影响执行效率。为解决这一问题,常用的方法是进行算子融合,即在计算结果等价的前提下,将多个Node融合成一个Node,尽量降低计算图Node数量,这样既可以将Node之间的访问显存开销转为访问寄存器开销,同时也可以减少计算图中每个Node带来的固定开销。
算子融合主要通过三种方式进行:
- 特定算子手动融合。例如模型训练阶段中,针对一个Embedding Table会有多个Node访问,在线预估阶段可将其融合成一个Node,即查询Node和Embedding Table一一对应。此后可进一步融合算子,一个Node负责查询多个Embeddding Table。
- 常见算子自动融合,主要是利用TensorFlow Grappler[4]优化器进行算子自动融合。
- 利用深度学习编译器自动融合,下文会详细进行介绍。
5.2 计算优化
5.2.1 FP16低精度优化
一方面,在CPU架构下,为了降低内存开销,已经将Embedding Table压缩为FP16[5]存储,但是计算时仍会展开为FP32,这引入了转换开销;另一方面,模型预估仅进行模型图的前向计算,使用低精度计算引入的误差较小。因此,业界普遍使用低精度方式进行模型预估计算。
针对当前的业务场景,我们尝试了FP16、INT8[6]等低精度计算,FP16半精度计算对模型效果无明显影响,INT8量化则会造成效果衰减。因此,我们采用FP16半精度计算的方式,在不影响模型效果的前提下,进一步提升预估服务的吞吐。
5.2.2 broadcast优化
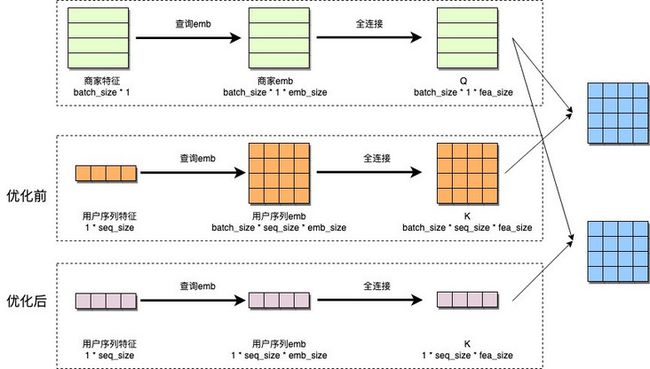
模型图中的数据可以分为user和item两类。通常情况下,请求中包含一个user以及多个item。在模型Sparse部分,user和item分别获取Embedding;在模型Dense部分,两类Embedding组合成矩阵后进行计算。经过深入分析,我们发现模型图中存在冗余查询和计算。如下图橙色部分所示,在模型Sparse部分,user信息先被broadcast成batchsize大小再去查询Embedding,导致同一个Embedding查询了batchsize次;在模型Dense部分,user信息同样被broadcast成batchsize大小,再进行之后所有计算,实际上在和item交叉之前不必broadcast user,同样存在冗余计算。
针对以上问题,我们对模型图进行了手工优化,如下图紫色部分所示,在模型Sparse部分,user信息只查询一次Embedding;在模型Dense部分,user信息与item交叉时再broadcast成batchsize大小,即整体上将user信息的broadcast后置。
5.2.3 高性能库应用
使用CPU时,可以利用Intel MKL[7]库对计算进行加速。受限于CPU硬件特点,加速效果有限。使用GPU时,我们可以利用Tensor Core[8]进行加速计算。每个Tensor Core都是一个矩阵乘累加计算单元,当前使用的NVIDIA T4卡具有320个Tensor Core,在混合精度计算时算力为65 TFLOPS,在单精度计算时算力为8.1 TFLOPS,具有极强的推理性能。在TensorFlow中,可利用cuBLAS[9]调用Tensor Core进行GEMM加速计算,利用cuDNN[10]调用Tensor Core进行CNN、RNN网络加速计算。
5.3 基于DL编译器的自动优化
随着深度学习网络越来越复杂(Wider And Deeper),硬件设备越来越多样(CPU、GPU、NPU),神经网络的优化工作也变得越来越困难。在单一硬件、单一框架上的优化会受到优化库限制,很难进一步调优。在不同硬件、不同框架的优化又很难做到通用,优化很难移植。这导致优化神经网络时,需要大量的手动调优工作,成本很高。
为了降低手动优化的成本,业界普遍使用深度学习编译器(Deep Learning Compiler)对计算图进行自动调优。比较流行的深度学习编译器包括TensorRT[11]、TVM[12]、XLA[13]等,我们在当前的模型场景下利用深度学习编译器做了较多的优化尝试,下文会详细进行介绍。
5.3.1 基于TensorRT的尝试
TensorRT是NVIDIA推出的高性能深度学习推理优化框架,支持自动算子融合、量化计算、多流执行等多种优化手段,并且可以针对具体kernel选择最优实现。TensorRT的各优化均通过对应开关控制,使用很简单;但是整体闭源,并且支持的算子不多,只能对计算图的部分算子做优化,遇到不识别的算子则会跳过,十分影响优化效率。利用TensorRT优化后的计算图,仍旧存在大量op,整体性能提升有限。为解决这个问题,我们从以下两个角度进行尝试。
① 手动切分子图
利用TensorRT进行图优化时,会先利用Union Find算法在全图中寻找可识别op并将其聚类,每个聚类进行具体的编译优化,并产生一个对应的TRTEngineOp。由于计算图中存在大量不识别op,对聚类过程造成了干扰,即使可识别OP也不一定能完成聚类,则无法进行对应编译优化,造成优化效率较低。为解决这一问题,图优化前我们先进行手动切图,将全计算图切分为若干个子图,每个可识别op都放入对应子图中,并将子图送入TensorRT进行优化。通过这一方法,有效解决了可识别op未优化的问题,有效降低了全图OP数量。
② 算子替换
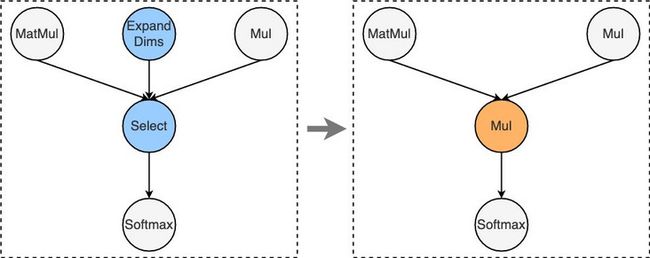
如前所述,TensorRT支持OP类型有限,全图中存在大量TensorRT无法识别的op,导致优化效率偏低。为了缓解这一问题,我们将TensorRT不识别的OP尽量替换成其支持的等价op。例如下图中,TensorRT无法识别Select op,我们将其替换成TensorRT支持的Multiply op,并将Select关联的ExpandDims op从图中消掉。经过类似的等价转换操作,有效降低了未识别op数量,提高了编译优化覆盖率。
5.3.2 基于TVM的尝试
在尝试TensorRT优化时我们发现,TensorRT对TensorFlow的算子覆盖率较低(只能覆盖约50+算子),在当前的模型计算图中,有十多个算子无法支持。即使经过复杂的算子替换优化工作,仍然存在多个算子难以替换。由此我们思考采用其他的深度学习编译器进行图优化。
TVM是陈天奇团队推出的端到端机器学习自动编译框架,在业界广泛使用。和TensorRT相比,TVM代码开源,具有更强的拓展性和定制能力。此外,TVM支持的TensorFlow算子超过130个,算子覆盖率远超TensorRT。在当前计算图中,TVM不支持的OP只有自定义的LookupTable,这一OP负责查询Embedding,无需进行编译优化。
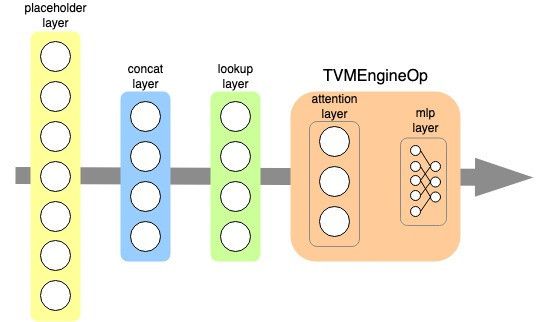
因此,我们尝试利用TVM取代TensorRT对当前计算图进行自动编译优化。考虑到TensorFlow对TensorRT、XLA均做了官方支持,实现了对应的wrapper op,但目前尚未支持TVM,我们对TensorFlow做了适配改造,采用和TensorRT类似的方式,实现了TVMEngineOp以支持TVM。考虑模型特点,我们将计算较重的Attention子图和MLP子图放入了TVMEngineOp中,利用TVM进行编译优化,如下图所示:
6 性能表现与分析
本章节展示实际生产环境下的测试数据,并分析上文一系列业内典型优化思路,在我们的特定场景下的表现及其背后原因。
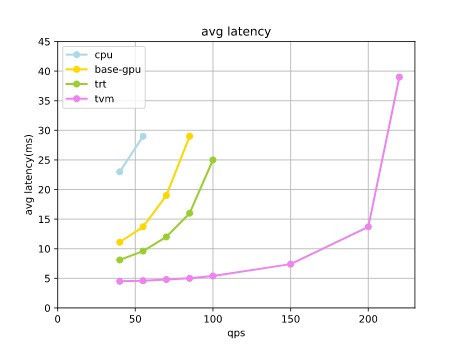
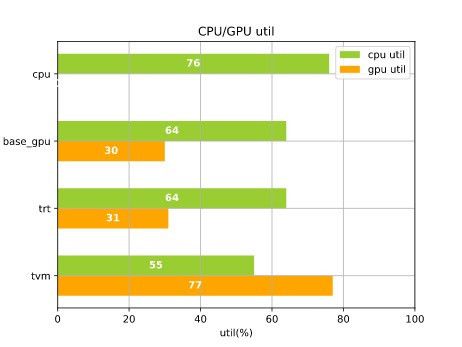
压测环境中,CPU环境为32核Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz+32G内存,GPU环境为8核Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz+Tesla T4 GPU+16G内存。上图中,左图对比了不同QPS下(x轴),精排模型在不同优化手段下的推理耗时(y轴),其中base-gpu表示只经过简单的图优化并在GPU计算,trt表示经过TensorRT优化并在GPU计算,tvm表示经过TVM优化且叠加All On GPU优化并在GPU计算;右图表示极限QPS下,不同优化手段对应的CPU和GPU利用率。从图中可以看出:
- 只利用CPU进行预估计算时,极限qps为55,此时CPU利用率已经高达76%,成为瓶颈。
- 利用常规手工优化(设备摆放+算子融合+Broadcast优化+高性能库)的GPU预估时,相同qps下latency大幅降低,且可以将极限qps提升至85(较CPU版提升55%)。到达极限吞吐时GPU利用率并不高,瓶颈仍旧为CPU利用率。
- 利用TensorRT优化预估(手工优化+TensorRT+FP16)时,得益于图编译优化,相同qps下latency降低约40%。由于瓶颈仍为CPU,极限吞吐未变化。
- 利用TVM优化预估(手工优化+TVM+FP16+All On GPU)时,将所有OP都放置于GPU计算,CPU只负责基本的RPC,极大缓解了CPU配额的瓶颈。相同qps下latency大幅降低约70%,极限吞吐大幅提升约120%。到达极限吞吐时,GPU利用率较高,成为瓶颈。
经过一系列优化,整体吞吐提升约4倍(qps从55->220),优化效果十分明显。
7 总结
综上,我们针对美团外卖场景的业务特点,将经典的CTR/CVR模型从多入口、多环节、多目标的单体模型,逐步演进到“One Model to Serve All”的多模型统一形态。
同时,结合美团的硬件条件和基础,实现了纯CPU预估架构向CPU+GPU异构架构的切换,在固定成本前提下,有效的释放了算力空间,计算吞吐提升了近4倍。针对GPU BOX机型对CPU资源的限制,我们采用手工优化+DL编译优化结合、模型网络计算All On GPU的思路,有效的提升了GPU在模型预估计算中的利用率,并在本文中详细分享了GPU落地中的优化过程和实测数据指标。
8 作者简介
- 杨杰、俊文、瑞东、封宇、王超、张鹏等,来自到家事业群/到家研发平台/搜索推荐技术部。
- 王新、陈卓、駃飞等,来自基础研发平台/数据科学与平台部/数据平台中心。
9 参考文献
- [1] https://www.usenix.org/system/files/conference/osdi16/osdi16-abadi.pdf
- [2] https://www.tensorflow.org/tfx/guide/serving
- [3] https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
- [4] https://www.tensorflow.org/guide/graph_optimization
- [5] https://en.wikipedia.org/wiki/Half-precision_floating-point_format
- [6] https://www.nvidia.com/en-us/data-center/tensor-cores/
- [7] https://www.intel.com/content/www/us/en/develop/documentation/get-started-with-mkl-for-dpcpp/top.html
- [8] https://www.nvidia.com/en-us/data-center/tensor-cores/
- [9] https://docs.nvidia.com/cuda/cublas/index.html
- [10] https://developer.nvidia.com/zh-cn/cudnn
- [11] https://docs.nvidia.com/deeplearning/frameworks/tf-trt-user-guide/index.html
- [12] https://tvm.apache.org/docs/
- [13] https://www.tensorflow.org/xla
阅读美团技术团队更多技术文章合集
前端 | 算法 | 后端 | 数据 | 安全 | 运维 | iOS | Android | 测试
| 在公众号菜单栏对话框回复【2021年货】、【2020年货】、【2019年货】、【2018年货】、【2017年货】等关键词,可查看美团技术团队历年技术文章合集。

| 本文系美团技术团队出品,著作权归属美团。欢迎出于分享和交流等非商业目的转载或使用本文内容,敬请注明“内容转载自美团技术团队”。本文未经许可,不得进行商业性转载或者使用。任何商用行为,请发送邮件至[email protected]申请授权。