目标检测 | YOLO系列超全讲解v1,v2,v3
-
- 前言
- 一、YOLOv1
-
- 1. 网络结构
- 2. 实现方法
- 3. 损失函数
- 4. 缺点
- 二、YOLOv2
-
- 1. 网络结构
- 2. 改进方法
- 3. YOLO9000
- 4. 网络训练细节
- 三、YOLOv3
-
- 1. 网络结构
- 2. 改进方法
- 3. 损失函数
- 4. 性能比较
资料汇总选自
B站大佬:霹雳吧啦Wz
csdn大佬:AI菌 和 AI小白一枚 和 小小将 和 木卯_THU
注:本文为学习记录笔记,以学习积累为主。如表述错误或侵权,烦请提示指出;如有不能理解的部分,可以前往以上博主的文章中查看更详细的说明讲解。
前言
从Two Stage到One Stage:
Two stage(先选取候选框,再进行回归调整候选框和分类):RCNN,SPP-Net,Fast-RCNN,Faster-RCNN,Mask-RCNN等
One stage(直接回归调整候选框及分类):SSD,YOLO系列,RetinaNet,RefineDet等
- 有关RCNN系列的详细过程,可查看《目标检测 | RCNN算法系列汇总+详解(包括Fast, Faster)》
- YOLO官网:作者Joseph Redmon的个人网站
- YOLOv1论文地址:https://arxiv.org/abs/1506.02640
- YOLOv2论文地址:https://pjreddie.com/darknet/yolo/
- YOLOv3论文地址:https://arxiv.org/pdf/1804.02767
- YOLOv4论文地址:https://arxiv.org/abs/2004.10934
- YOLOv5的Github源码:https://github.com/ultralytics/yolov5
一、YOLOv1
2016年,Joseph Redmon等人提出了一种单阶段(one-stage)的目标检测网络,在 PASCAL VOC2007 的测试集上达到了 63.4 mAP,在 448 × 448 的输入图像上的二推理能达到 45 FPS。作者将其取名为:You Only Look Once。
- 利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别
- 虽然Faster RCNN中也直接用整张图作为输入,但是Faster-RCNN整体还是采用了RCNN那种 proposal+classifier的思想。而YOLOv1直接回归。
1. 网络结构
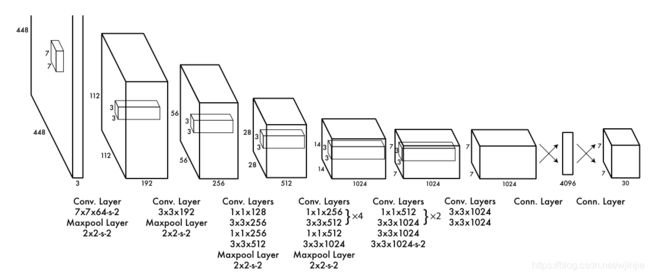
符合一阶段的卷积神经网络,由整张图片直接到检测目标位置和概率值。网络结构图中没有标s意味着默认步距stride为1。
- 网络输入:448×448×3的彩色图片。
- 中间层:由若干卷积层和最大池化层组成,用于提取图片的抽象特征。
- 全连接层:由两个全连接层组成,用来预测目标的位置和类别概率值。
- 网络输出:7×7×30的预测结果。
2. 实现方法
在YOLOv1中,它将整张图片输入后平均分为S×S个网格(grid cell),当某个目标的中心落在这个网格中,那么这个网格就负责预测它。对于Faster-RCNN需要训练一个RPN网络获得目标候选框区域,然后再映射到特征图上得到特征矩阵,这消耗了大量时间空间。
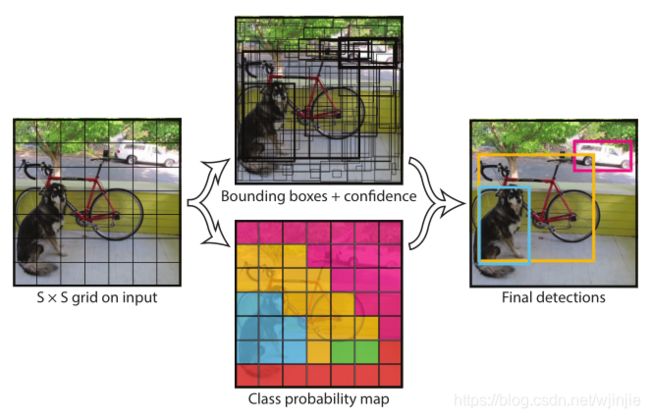
具体步骤:
- 输入图像分为S×S个网格,如果某个object的中心落在这个网格中,则这个网格就负责预测这个object
- 每个网格要预测 B 个bounding box,每个 bounding box 除了要回归自身的位置和一个值,即 (x, y, w, h) 和 confidence 共5个值。
- 每个网格还要预测一个类别信息,记为C类。则SxS个网格,每个网格要预测B个bounding box还要预测C个categories。总的输出就是S × S × (5×B+C)的张量。如下图输出结果的网络结构所示。
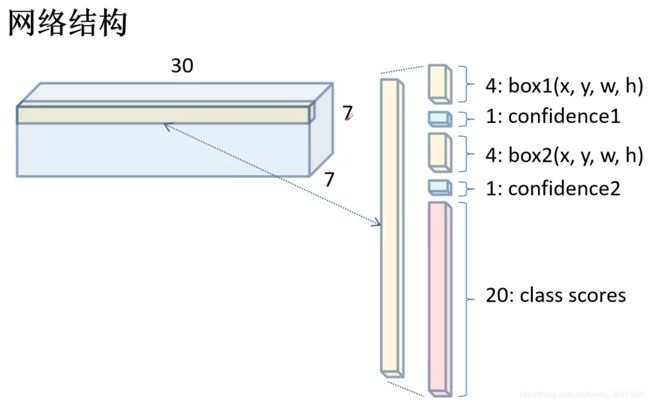
实际操作:
在YOLOv1的CVPR 2016论文中,图片输入为448×448的像素,S图片划分网格量=7,B每个网格预测边框量=2,C类别个数=20。于是,网格输出=7×7×(5×2+20)
在test的时候,每个网格预测的class信息和bounding box预测的confidence信息相乘,根据上一步可以预测出S×S×B个目标窗口,然后根据阈值去除可能性比较低的目标窗口,最后用NMS非极大值抑制去除冗余窗口即可得到最终的检测结果。
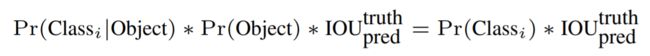
该表达式含义:
等式左边第一项就是每个网格预测的类别信息
第二三项就是每个bounding box预测的confidence,代表了所预测的box中含有object的置信度和这个box预测准确率;其中,第二项表示如果有object落在一个grid cell里,则第一项取1,否则取0;第三项是预测的bounding box和实际的groundtruth之间的IoU值。
整体上,这个乘积即encode了预测的box属于某一类的概率,也有该box准确度的信息
3. 损失函数
YOLOv1损失分为三类。1.目标 bounding box坐标预测的损失,2. confidence置信度预测的损失,3.classes分类预测的损失。原论文中都是使用sum-squared error loss误差平方和进行计算。

3.1 bounding box坐标检测损失
对于x和y的向量都是用预测值减去真实标签值的平方就是误差平方和;对于w和h,先进行开根处理,再做误差平方,这样可以提升小目标的损失,消除大尺寸框和小尺寸框之间的差异。
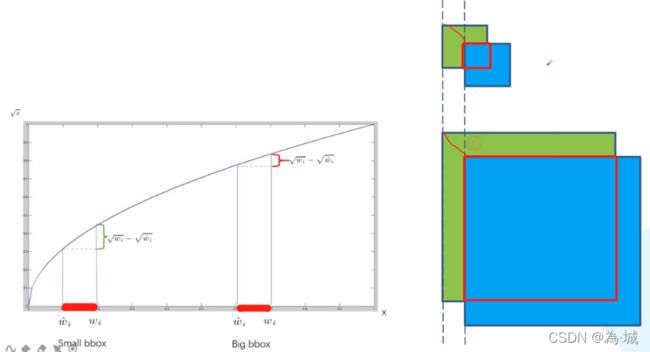
开根处理原因:
下图右侧为两个目标bbox候选框,当平移相同的宽和高后,对于小目标的IoU是明显小于大目标的IoU的,所以不适合于IoU与x的线性关系(即类似x和y的处理)。于是下图左侧的根号下的关系能够满足小目标IoU小,大目标IoU大的特征。
3.2 confidence和classes的损失
confidence分为含有object和不含object的损失,即正样本和负样本。在正样本中,真实值为1;负样本真实值为0。于是,confidence 损失需要计算正负样本,而 bounding box 以及 class 损失都只计算正样本的。正样本的 confidence 真实值应该为预测框与真实物体框的 IoU 数值;负样本的 confidence 真实值应该为 0。
3.3 处理目标不均衡
目标检测问题是一个典型的类别数目不均衡的问题,在7×7的grid cell格点中,含有物体的格点一般比较少。所以需要让含有物体的格点在损失函数中的权重更大,让模型更加重视含有物体的格点所造成的损失。于是在bbox坐标误差损失中代入λ_coord取值5;对于不含目标的置信度预测损失代入λ_noobj=0.5。
4. 缺点
- 对群体性的相互靠近的小目标检测效果差。由于YOLOv1对于每个grid cell值设置预测两个bounding box,且设置的classes类别相同。所以当群体目标聚集在一起时,检测会出现问题。
- 当目标比例出现不一致时,即新的长宽比,预测能力很差。
- 主要的错误都是定位不准确。由于直接预测坐标信息,对不常见的目标泛华能力差。
二、YOLOv2
YOLOv2作者命名为(Better, Faster, Stronger),基于YOLOv1的不足,提出了很多改进方法,主要是保持检测速度,改善recall,提升定位的准确度,同时保持分类的准确性。
1. 网络结构
YOLOv2使用Global Average Pooling,使用Batch Normilazation来让训练更稳定,加速收敛,使model规范化。v2采用 Darknet-19(有19个卷积层和5个maxpooling层)作为特征提取网络,即backbone,Darknet-19整体结构如下:
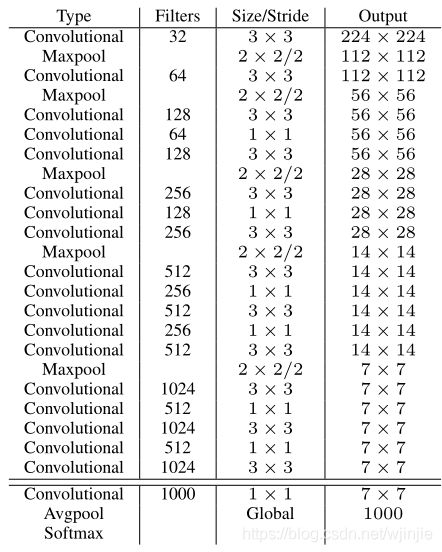
Darknet-19 与 YOLOv1、VGG16网络对比:
VGG-16: 大多数检测网络框架都是以VGG-16作为基础特征提取器,它功能强大,准确率高,但是计算复杂度较大,所以速度会相对较慢。因此YOLOv2的网络结构将从这方面进行改进。
YOLOv1: 基于GoogLeNet的自定义网络(具体看上周报告),比VGG-16的速度快,但是精度稍不如VGG-16。
Darknet-19: 速度方面,处理一张图片仅需要55.8亿次运算,相比于VGG306.9亿次,速度快了近6倍。精度方面,在ImageNet上的测试精度为:top1准确率为72.9%,top5准确率为91.2%。
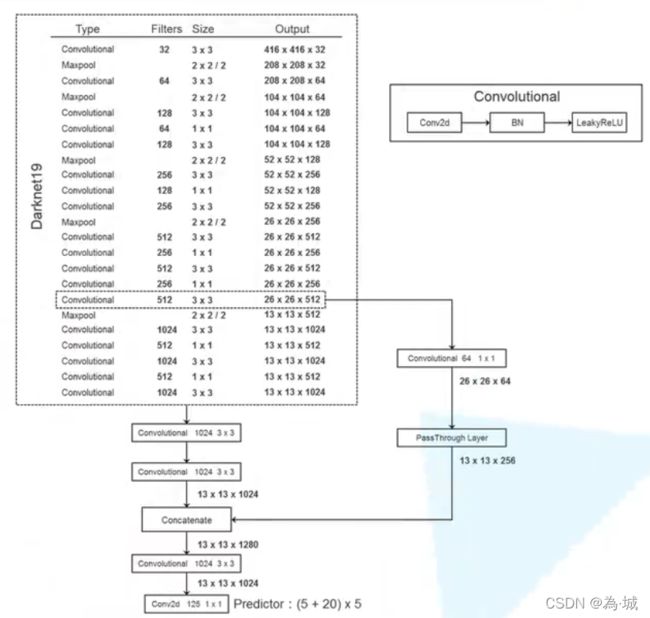
YOLOv2模型框架如下:
- Convolutional卷积层(右上侧)由conv2d+BN+LeakyReLU组成;
- 基于Darknet19,移除了最后的卷积层,保留卷积大小3×3卷积核为1024的卷积层(输出13x13x1024);
- 添加三个3×3的1024卷积核的卷积层;
- 最后输出了一个1×1的Predictor卷积层,输出的个数为我们的检测。
- 并且在最后一个3x3x512层添加了一个Pass Through Layer,使得连接在最后一个卷积层之前做了特征融合。
更多具体的训练过程,跳转《目标检测|YOLOv2原理与实现(附YOLOv3)》以及《深度学习之目标检测(七)–YOLO v2理论介绍》
2. 改进方法
2.1 Batch Normalization
简称BN层,即批量标准化。在每一层卷积后,都增加了批量标准化(Batch Normalization)进行预处理。
BN层能够对数据进行预处理,完成图像均衡化,解决反向传播的梯度消失/爆炸,去噪等功能,提升训练速度,并且起到一些正则化效果,达到了 2% mAP 的提升,可以移除 Dropout 层。
使用Batch Normalization对网络进行优化,让网络提高了收敛性,同时还消除了对其他形式的正则化(regularization)的依赖。
关于Batch Normalization的更多资料,可以阅读《Batch Normalization原理与实战》 以及 《深度学习笔记(三):BatchNorm(BN)层》
2.2 High resolution classifier
YOLOv1使用ImageNet的图像分类样本采用 224×224 作为输入,来训练CNN卷积层。然后在训练目标检测时,检测用的图像样本采用更高分辨率的 448×448 像素图像作为输入,但这样不一致的输入分辨率肯定会对模型性能有一定影响。
而YOLOv2采用更高分辨率的分类器,在采用 224224 图像进行分类模型预训练后,再采用 448448 高分辨率样本对分类模型进行微调(10个epoch),带来了4%的mAP提升。
2.3 Convolution with anchor boxes
在YOLOv1中,作者通过全连接层直接预测边界框的位置并且做回归;而在Faster RCNN算法只用卷积层与Region Proposal Network来预测Anchor Box的偏移值与置信度,而不是直接预测坐标值。于是,通过预测偏移量而不是坐标值能够简化问题,让神经网络学习起来更容易,对于卷积层有以下变化:
- 为了使检测所用的特征图分辨率更高,移除其中的一个 pool 层。
- 借鉴Faster RCNN的做法,YOLOv2 移除了 YOLOv1 中的全连接层直接预测,而采用了卷积和 anchor boxes 来确定边界框。
- 在检测模型中,保证特征图有奇数个位置,即YOLOv2 不是采用 448×448大小的图片输入,而是采用416×416大小。由于YOLOv2下采样的步长为32,对于416×416大小,通过5个pooling后最终的特征图大小为13×13,其特征图的只有一个center cell中心位置。
- YOLOv2 使用了 Anchor boxes 之后,每个位置的各个 anchor box 都单独预测一套分类概率值,这和 SSD 比较类似(但 SSD 没有预测置信度,而是把 background 作为一个类别来处理)。YOLOv1 只能预测 7 × 7 × 2 = 98 个 bounding box,而 YOLOv2 则使用 Anchor boxes 之后能预测上千个边界框(13 × 13× num_anchors),提升召回率。
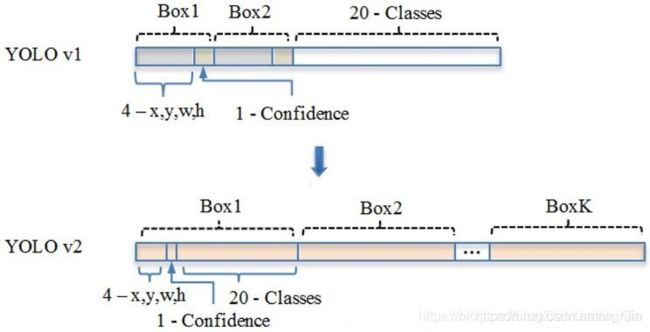
2.4 Dimension Clusters
在Faster R-CNN 以及 SSD 中,作者并没有明确地给出采用那些作者给定的 Anchor 或者 Default Box的尺寸,基本上为工程经验得到。于是,YOLOv2尝试统计出更符合样本中对象尺寸的先验框,这样就可以减少网络微调先验框到实际位置的难度。
YOLOv2的做法是对训练集中标注的Anchor Box边框进行K-means聚类分析,以寻找尽可能匹配样本的边框尺寸。如果我们用标准的欧式距离的k-means,会导致尺寸大的框比小框产生更多的错误。
聚类的目的是使 Anchor boxes 和临近的 ground truth boxes有更大的IOU值,因此自定义的距离度量公式为 :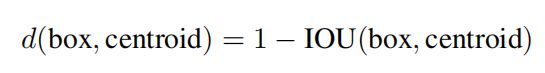
centroid是聚类时被选作中心的边框,box就是其它边框,d就是两者间的“距离”,IOU越大,“距离”越近。到聚类中心的距离越小越好,但IOU值是越大越好,所以使用 1 - IOU;这样就保证距离越小,IOU值越大。
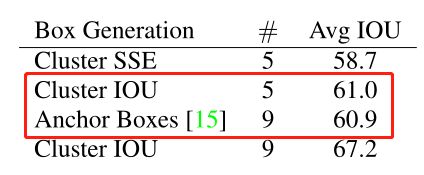
从下表可以看出,YOLOv2采用5种 Cluster(61.0) 比 Faster R-CNN 采用9种 Anchor(60.9) 得到的平均 IoU 还略高,并且当 YOLOv2 采用9种时,平均 IOU 有显著提高(67.2)。说明 K-means 方法的生成的Anchor boxes 更具有代表性。为了权衡精确度和速度的开销,最终选择K=5。
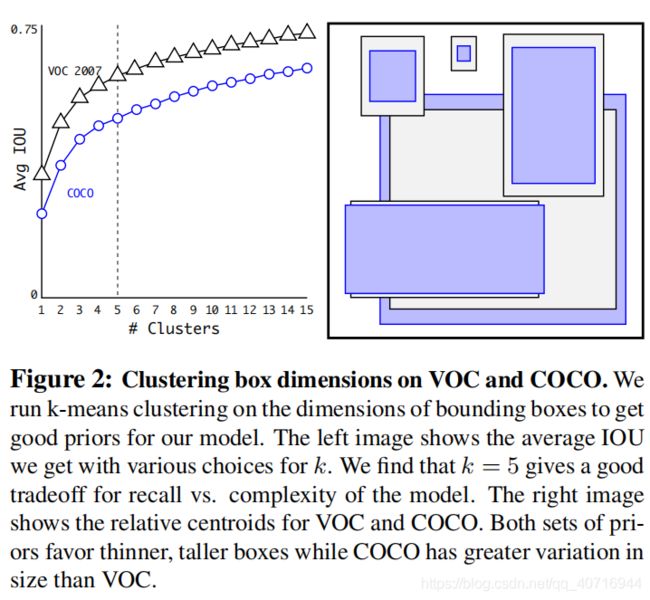
下图黑蓝图形为在 VOC 和 COCO 数据集上的聚类分析结果,随着聚类中心数目的增加,平均 IoU 值(各个边界框与聚类中心的IoU的平均值)是增加的。综合考虑模型复杂度和召回率,作者最终选取 5 个聚类中心作为先验框,其相对于图片的大小如右边图所示。
2.5 Direct location prediction
在 Faster R-CNN 算法中,是通过预测 bounding box 与 ground truth 的位置偏移值,间接得到bounding box的位置。公式如下: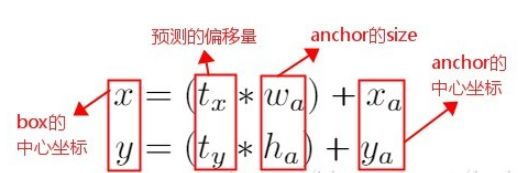
这个公式是无约束的,预测的边界框很容易向任何方向偏移。因此,每个位置预测的边界框可以落在图片任何位置,这会导致模型的不稳定性。
为了让网络的结果能落在这一范围内,网络使用一个 Logistic Activation来对于网络预测结果进行限制,让结果介于0到1之间。 网络在每一个网格单元中预测出5个Bounding Boxes,每个Bounding Boxes有五个坐标值tx,ty,tw,th,t0,他们的关系见下图(蓝色的是要预测的bounding box,黑色虚线框是Anchor box):
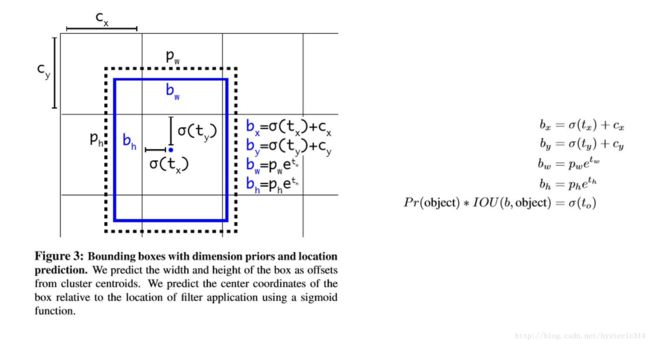
2.6 Fine-Grained Features
细粒度特征,可以理解成对不同层的物体预测的精细研究。YOLOv2 提出了一种 Pass Through Layer层来利用更精细的特征图,把高分辨率的浅层特征连接到低分辨率的深层特征(把特征堆积在不同Channel中)而后进行融合和检测。
具体操作是:先获取前层的26×26的特征图,将其同最后输出的13×13的特征图进行连接,而后输入检测器进行检测(而在YOLOv1中网络的FC层起到了全局特征融合的作用),以此来提高对小目标的检测能力。
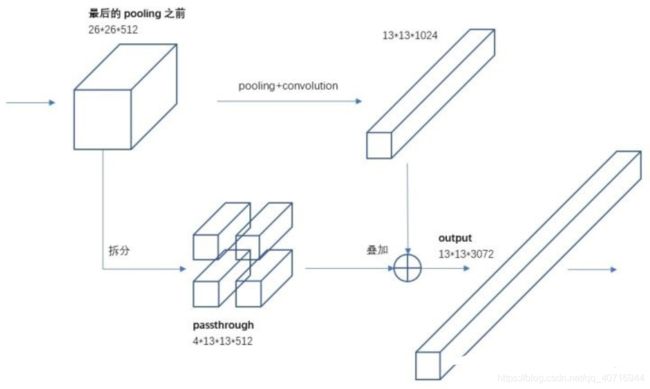
Passthrough层与ResNet网络的shortcut类似,以前面更高分辨率的特征图为输入,然后将其连接到后面的低分辨率特征图上。前面的特征图维度是后面的特征图的2倍,passthrough层抽取前面层的每个2×2的局部区域,然后将其转化为channel维度,对于26×26×512的特征图,经Passthrough层处理之后就变成了13×13×2048的新特征图(特征图大小降低4倍,而channles增加4倍),这样就可以与后面的13×13×1024特征图连接在一起形成13×13×3072的特征图,然后在此特征图基础上卷积做预测。示意图如下:
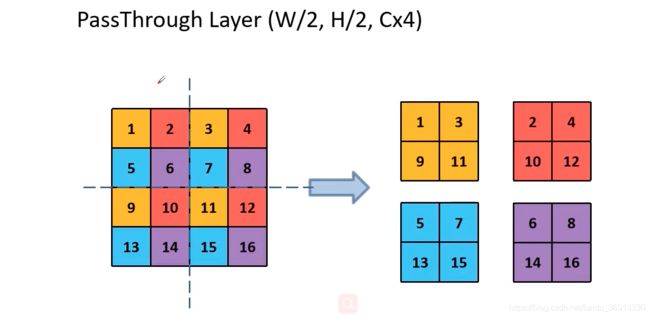
2.7 Multi-Scale Training
采用多尺度训练,替换固定尺寸训练。作者希望YOLOv2能健壮的运行于不同尺寸的图片之上,所以把这一想法用于训练model中。区别于之前的补全图片的尺寸的方法,YOLOv2每迭代几次都会改变网络参数。每10个Batch,网络会随机地选择一个新的图片尺寸,由于使用了下采样参数是32,所以不同的尺寸大小也选择为32的倍数{320,352……608},最小320×320,最大608×608,网络会自动改变尺寸,并继续训练的过程。
在测试时,YOLOv2 可以采用不同大小的图片作为输入,在 VOC 2007 数据集上的效果如下图所示。
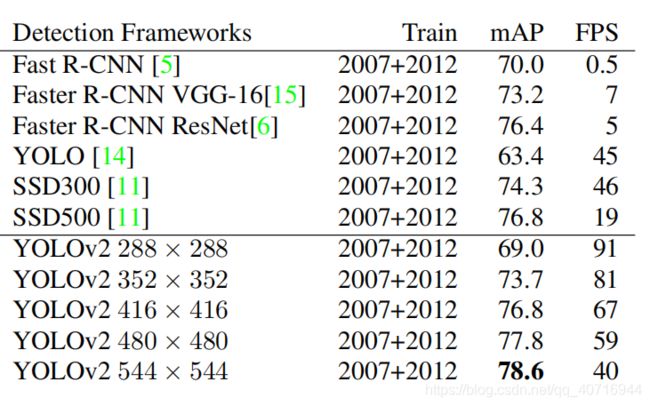
可以看到采用较小分辨率时,YOLOv2 的 mAP 值略低,但是速度更快,而采用高分辨输入时,mAP 值更高,但是速度略有下降,对于 544 × 544 的输入图,mAP 高达 78.6%。值得注意的是,这只是测试时输入图片大小不同,而实际上用的是同一个采用Multi-Scale Training训练得到的模型。
3. YOLO9000
YOLO9000 是在 YOLOv2 的基础上提出的一种可以检测超过 9000 个类别的模型,其主要贡献点在于提出了一种分类和检测的联合训练策略。
一般来说,检测数据集的标注要比分类数据集打标签繁琐的多,所以 ImageNet 分类数据集比 VOC 等检测数据集高出几个数量级。在 YOLO 中,边界框的预测其实并不依赖于物体的标签,所以YOLO可以实现在分类和检测数据集上的联合训练。
对于检测数据集,可以用来学习预测物体的边界框、置信度以及为物体分类,而对于分类数据集可以仅用来学习分类,但是其可以大大扩充模型所能检测的物体种类。在训练时,如果是检测样本,按照 YOLOv2 的 loss 计算误差,而对于分类样本,只计算分类误差。
通过联合训练策略,YOLO9000 可以快速检测出超过 9000 个类别的物体,总体 mAP 值为 19.7%。从某方面说,YOLOv2的改进策略亮点并不是很突出,但是YOLO9000算是开创之举。
4. 网络训练细节
由于作者在论文中没有体现误差,损失函数等内容,对于相关细节可跳转《目标检测|YOLOv2原理与实现(附YOLOv3)》 以及《YOLO v2 损失函数源码分析》
三、YOLOv3
2018年,作者Redmon在YOLOv2的基础上做了一系列的改进,但是正如作者所说,这仅仅是他们近一年的一个工作报告(TECH REPORT),不算是一个完整的paper,因为他们实际上是把其它论文的一些工作在YOLO上尝试了一下。其核心在于做大做强,再创辉煌。可跳转视频霹雳吧啦Wz《yolo系列理论合集》查看详细讲解。
小小将 认为,YOLOv3 最大的变化为backbone中的残差模型以及采用FPN特征金字塔结构。
其中,在YOLOv3中保留的步骤有:
- 通过划分grid cell单元格来做检测,只是每次划分的数量尺寸不一样。
- 采用 Leaky ReLU 作为激活函数
- 进行端到端的训练,用一个loss function损失函数完成训练
- 保留YOLOv2中的batch normalization批量标准化处理作为正则化、加速收敛和避免过拟合的方法。
- 保留YOLOv2中的多尺度训练,替换固定尺寸训练,即通过采用不同分辨率的图像,在速度和准确率之间选择。
1. 网络结构
YOLOv3 的第一个改进之处就是将 backbone 替换为 Darknet-53。而在 YOLOv2 中采用的是 Darknet-19 这样一个网络。Darknet-53 的top-1准确率相较于 Darknet-19 有比较大的提升,与 ResNet 性能相当,但是FPS即检测速度比 ResNet 要好很多。Darknet-53 如下图所示。YOLOv3最大的变化为使用残差模型和采用FPN(feature pyramid networks)架构。
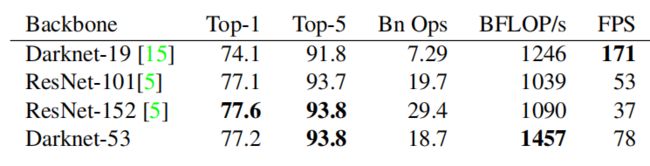
注:top-1和top-5准确率
模型在 ImageNet 数据集上进行推理,按照置信度排序总共生成 5 个标签。按照第一个标签预测计算正确率,即为 Top-1 正确率;前五个标签中只要有一个是正确的标签,则视为正确预测,称为 Top-5 正确率。
Darknet-53网络结构有如下特点,如下图所示。
- 这个网络主要是由一系列的1x1和3x3的卷积层组成;
- 将convolution卷积层升级为卷积层+BN层+激活层,即每个卷积层后都会跟一个BN层和一个LeakyReLU层;
- 没有采用最大池化层,转而采用步长为2的卷积层进行下采样,即左图框下面的那个卷积,使得输出图像减小为原来的一半;
- 左图中的每个方框框柱的就是一个residual残差结构,将两层卷积层后与主分支的输出进行相加,即右下图;
- 作者说因为网络中有53个convolutional layers,所以叫做Darknet-53(最后的Connected是全连接层也算卷积层)。
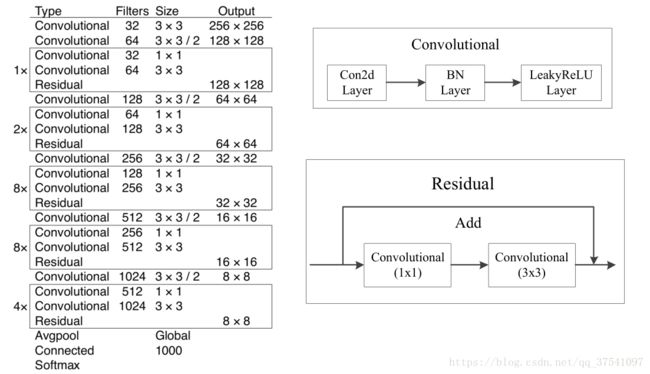
整个v3结构里面,是没有池化层和全连接层的。前向传播过程中,张量的尺寸变换是通过改变卷积核的步长来实现的,比如stride=(2, 2),这就等于将图像边长缩小了一半(即面积缩小到原来的1/4)。
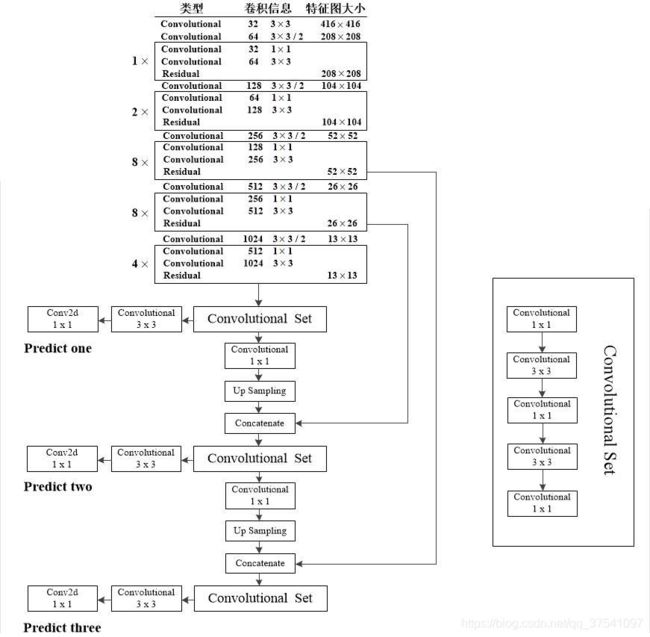
YOLOv3的416模型网络结构,即输入图像尺寸为416×416,预测的三个特征层大小分别为52,16,13。结构如下图所示:
- 其中的convolution set卷积集合由五层卷积层组成
- 通过up sample上采样扩大尺寸为原来的两倍
- concatenate完成了通过上采样与来自backbone中的卷积匹配拼接
- 预测器 Conv 1×1 就是一个卷积层,三个分别输出不同shape尺寸的feature map
2. 改进方法
2.1 多尺度预测
为了能够预测多尺度的目标,当输入图片为416×416时,YOLOv3基于k-means方法对不同size的目标进行检测(越精细的grid cell就可以检测出越精细的物体),得到的九组预设边界框尺寸,并将其划分到3个尺度特征图上,尺度更大的特征图使用更小的anchor先验框,和SSD类似。这些预设的框被称为 bounding box priors,这个和 Anchor 以及 Default box 其实是一个概念。
在COCO数据集上选择的9种Anchors的尺寸如下所示:

YOLOv3 借鉴了==FPN (feature pyramid networks)==特征金字塔的思路,Concatenate层与来自backbone里的相同特征图大小的残差层拼接,可参考YOLOv3网络结构。在COCO数据集(有80个分类)上进行预测时,每一个预测特征层上会张量为 N × N × [ 3 ∗ ( 4 + 1 + 80 ) ] 。N为特征图大小。
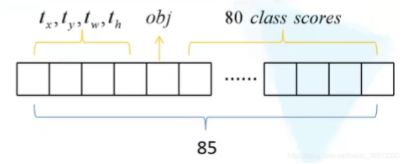
由下采样次数不同,得到的N不同,最终三个Predict(从上到下)的shape分别为:[13, 13, 255]、[26, 26, 255]、[52, 52, 255]。
2.2 目标边界框预测
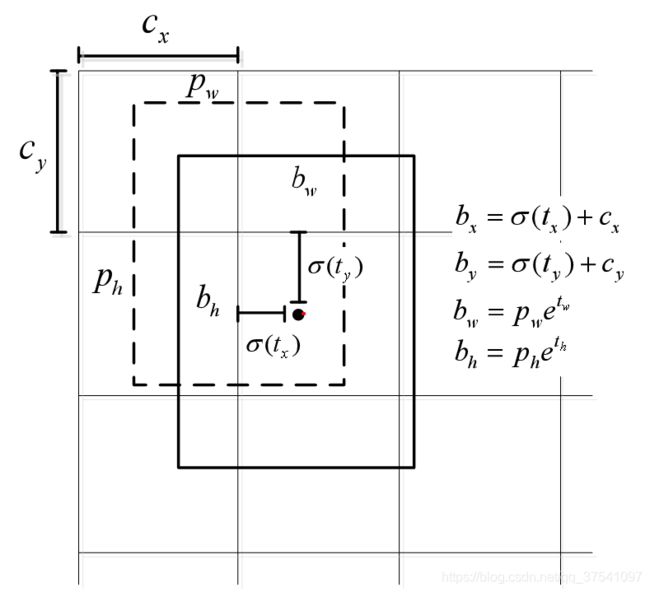
下图中虚线矩形框为先验框,即预设边界框,实线矩形框为通过网络预测的偏移量计算得到的预测边界框。通过右下角的式子可以计算得出实际预测框 b 的尺寸。
注:虚线框 Anchor 的中心画到了 cell 的左上角,它的中心坐标就是 ( c x , c y ) (c_x,c_y) (cx,cy),宽度和高度分别是 p w p_w pw和 p h p_h ph,σ是sigmoid函数。sigmoid函数目的是将预测偏移量缩放到0到1之间,能够将预设边界框的中心坐标固定在一个cell ( c x , c y ) (c_x,c_y) (cx,cy)当中,作者说这样能加快网络收敛。
2.3 正负样本的匹配
- positive正样本:对每一个 ground box 会分配一个 bounding box prior,一张图片中有几个 GT 目标,就有几个正样本。并且将与 GT box 重合度最高(IoU 分数最大)的 bounding box prior 作为正样本。可产生confidence置信度 loss、检测框 loss、类别 loss。其中置信度标签为 1 (亦可选择预测边界框与 GT box 的 ioU 分数);类别标签对应类别为1,其余为 0。
- ignore忽略样例:对于那些与某个 GT box 重合度超过一定阈值(论文中使用 0.5),但是又不是最大的,则它既不是正样本也不是负样本,直接将其进行丢弃不用于计算损失。
- negative负样本:对于剩下的样本(与所有 GT box 的 IoU 分数都小于 0.5)则认为是负样本。负样本仅仅用于计算置信度损失,置信度标签为 0。
3. 损失函数

对于神经网络来说,损失函数的设计也非常重要。YOLOv3文中并没有直接给出损失函数的表达式。YOLOv3的损失函数主要分为三个部分:目标置信度损失,目标分类损失,目标定位偏移量损失;其中 λ 1 , λ 2 , λ 3 λ_1,λ_2,λ_3 λ1,λ2,λ3为平衡系数,表示三种loss之间的比例。
3.1 目标置信度损失
目标置信度可以理解为预测目标矩形框内存在目标的概率,采用二值交叉熵损失(Binary Cross Entropy) 方法; o i o_i oi∈{0, 1} 表示预测目标边界框i中是否真实存在目标,0表示不存在,1表示存在。

假设上图右边蓝色的部分是 bounding box prior,绿色边界框是 GT box,黄色就是预测的 4 个边界框回归参数作用于蓝色的 bounding box prior 得到预测目标边界框。黄色和绿色的边界框的 IoU 就是 o i o_i oi了。可以直接取 0 和 1。
3.2 目标分类损失
目标分类损失同样采用的是二值交叉熵损失,同一目标可同时归为多类,比如猫可归为猫类以及动物类,这样能够应对更加复杂的场景。

需要注意的是,COCO 数据集有 80 个类别,所以类别数在 85 维输出中占了 80 维,每一维独立代表一个类别的置信度。作者使用 Sigmoid 激活函数替代了 YOLOv2 中的 softmax,取消了类别之间的互斥,可以使网络更加灵活。但是经过 Sigmoid 处理可能出现认为目标既是猫又是狗的情况(两个概率都大于 0.5)。所以 80 个概率之和并不是等于 1 的。
3.3 目标定位损失
采用的是真实偏差值与预测偏差值差的平方和,通过左下角的式子能够得到目标定位损失值。

目标定位xywh也是由均方差来计算loss的,其中预测的xy进行sigmoid来与lable xy求差,label xy是grid cell中心点坐标,其值在0-1之间,所以predict出的xy要sigmoid。
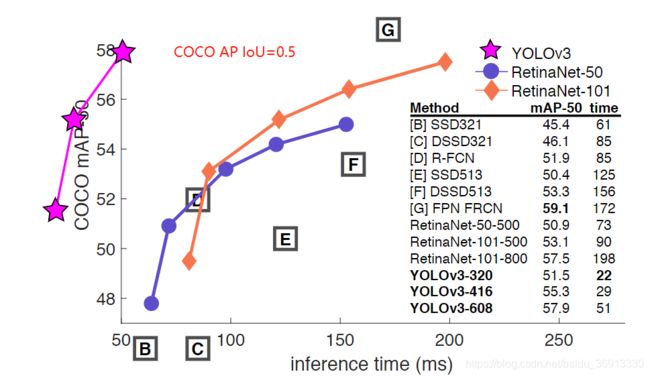
4. 性能比较
通过在 COCO 数据集上正确率的对比我们可以看出,相比于其他网络而言,YOLOv3 速度非常的快,但是正确率并没有那么高。而在满足检测精度差不都的情况下,YOLOv3具有更快的推理速度!
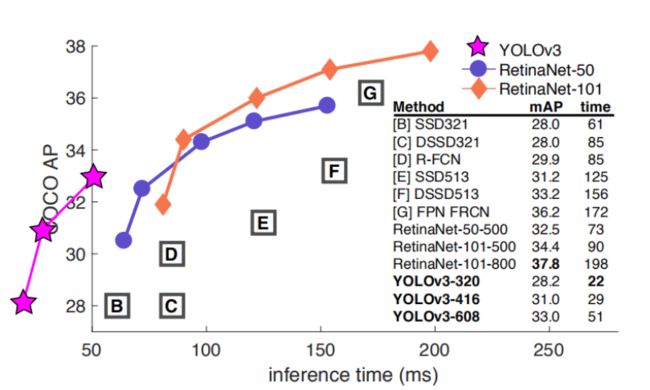
当 IoU=0.5 时候的 AP 对应的是 PASCAL VOC 的评价指标了,可见其检测效果对于其他网络而言还是有竞争力的,且速度奇快无比。