基于GAN的图像修复--论文笔记
文献下载看下载处或评论链接
/1 Region Normalization for Image Inpainting
主要内容:将损坏的图像输入到神经网络中可能会产生问题,例如无效像素的卷积、归一化的均值和方差。但是,当前方法无法解决网络中的均值和方差漂移问题。当前方法大多采用 feature normalization(FN,特征归一化) 进行训练,这些FN方法大多在空间维度上进行归一化,忽略了损坏区域对归一化的影响。本文提出Region normalization((RN,区域归一化)来解决上述问题。根据输入的mask(隐码)将像素划分为不同的区域,并计算每个区域的均值和方差来实现归一化。
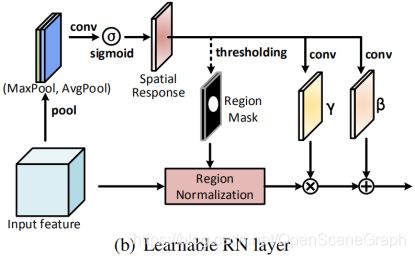
网络结构:在实现细节上提出两种RN,一个是basic RN(RN-B),另一个是learnable RN(RN-L)。basic RN如下图所示。对未损坏区域(红色部分)、损坏区域(绿色部分)分别归一化,然后会有两组affine transformation(仿射变换)参数。在网络的前面几层中,输入图像具有较大的损坏区域,会导致严重的均值和方差漂移。因此,使用RN-B通过分区域归一化来解决这一问题。
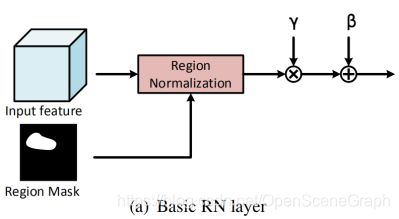
经过多个卷积层以后,未损坏区域和损坏区域会融合在一起。这个时候再使用RN-L,利用输入特征的空间关系来检测损坏区域,为RN生成region mask(区域隐码)。RN-L如下图所示,首先使用 maxpool 和 avgpool 得到两个feature map并拼接在一起。然后使用sigmoid函数得到一个spatial response map(空间响应图)。最后,通过阈值得到 region mask。
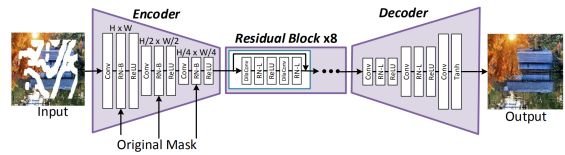
本文使用了 EdgeConnect 方法的架构。(EdgeConnect包括一个 edge generator 和一个 image generator),在本文中,作者使用了 image generator 做为基础网络。同时,作者把 instance normalization 替换为 RN, RN-B, RN-L. 整体架构如下图所示。
/2 Coherent Semantic Attention for image inpainting
主要内容:以往的图像修复,往往没有考虑像素之间的连续性,映射到语义上来说就是没有考虑特征的连续性,从而导致色彩的断层或者线条的断层。图中shift-net和Contextual Attention都是专做中心修复的,可以明显看出色彩的断层。而PC和GC用于随机马赛克修复,可以看出明显的人工修复痕迹。本文提出了一种全新的 Coherent Semantic Attention (CSA,连贯性语义注意力机制)层,并分为粗、细两步骤,网络使用U-Net结构。

网络结构:模型分为粗修复和精细修复两个步骤,其中粗修复(Rough net)用的是pix2pix文章中的U-net网络,快并且效果不错。精细修复网络(Refinement network)整体也是U-net架构,其中每个卷积分成两次完成,第一次是升降维度,第二次是上下采样, 类似于分离卷积,不过降维用的3×3的卷积,采样用的空洞卷积。连贯性语义注意力机制(CSA)在32×32×256那层,效果不错并且时间消耗少。
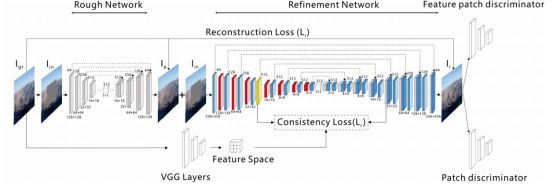
(1) Coherent Semantic Attention 具体分为两个模块:第一部分称为搜索阶段,第二部分称为生成阶段。其中蓝色区域为马赛克区域,灰色为上下文区域,需要针对蓝色区域中每一个点找到最相关的上下文区域并且替换进来,这样所有的马赛克区域就都被上下文区域填满,再进行第二步生成阶段。生成阶段中,我们采用光标扫描的方式从上至下从左至右进行生成。

(2)Consistency loss(一致性损失)
由于整体结构用的U-net架构,所以我们要保证编码器和解码器对应层需要语义一致性,并且要让Coherent semantic attention层能够更好的工作,所以我们用VGG提取原图的特征空间,并将这个特征空间作为CSA(Coherent semantic attention)层和其对应的解码器层的标签并计算L2距离,这样就能够保证编码器和解码器对应层需要语义一致性并且提升CSA的效果。
(3)Feature patch discriminator(特征块判别器)
我们用VGG提取图片的特征空间,并在这个特征空间上利用patch discriminator进行对抗损失计算,这样能够更加好的帮助生成器理解图像信息,同时稳定辨别器训练。
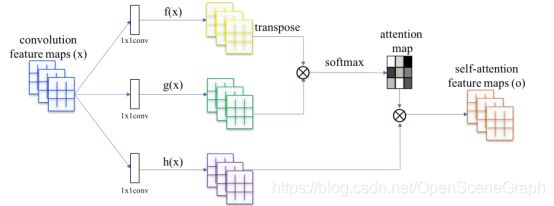
/3 Self-Attention Generative Adversarial Networks
主要内容:卷积只有局部的感受野,大范围的依赖关系只能通过多层卷积进行处理。这可能影响网络学习到长依赖关系:1、小模型可能无法学习;2、优化算法可能很难找到多层卷积的合适参数来捕捉这种依赖关系;3、这种参数化可能对之前没见过的图片很不稳定,容易失败。而单纯增大卷积核扩大感受野是个办法,但增大了计算量。本文提出了一种Self-Attention Generative Adversarial Networks(SAGAN),引入自注意力机制学习long range dependency(长期依赖);在生成器和判别器中引入spectral normalization(光谱归一化)等操作(不平衡训练)提高训练稳定性。
网络结构:如下图所示为自注意力机制,对每一行执行softmax操作。