云智慧 AIOps 社区是由云智慧发起,针对运维业务场景,提供算法、算力、数据集整体的服务体系及智能运维业务场景的解决方案交流社区。该社区致力于传播 AIOps 技术,旨在与各行业客户、用户、研究者和开发者们共同解决智能运维行业技术难题,推动 AIOps 技术在企业中落地,建设健康共赢的AIOps 开发者生态。
引言
近年来,随着互联网以及移动设备的普及,数字化转型加速并受到各大企业追捧。与此同时,非IT领域的发展报告——毕马威商业分析报告中提到的10个行业中,大多也都提到了数字化转型与数字化转型加速。 随着数字化的不断深入,全球IT已经进入了新的”ABCD”时代,即AI(人工智能)、Bigdata(大数据)、cloud computing(云计算)与Digital(数字化)。这些技术方向支撑着企业数字化的进程,让IT即业务成为了企业发展的方向。 大量业务向“互联网+”与数字化方向迁移,企业IT规模正在高速扩展,运维人员每天都要面对数以万计的运维对象。 这种现状正好说明了“当下是运维最好的时代,也是运维最坏的时代”。

智能运维面临的问题与挑战
首先,如何理解“当下是运维最好的时代,也是运维最坏的时代”这句话?最好的时代,是因为运维的重要性被提高到了空前高度。IT系统支撑着企业业务的运行,很多IT系统运行状况的好坏,直接影响了企业核心业务发展;最坏的时代,则是因为我们面对的系统空前复杂,云计算,容器技术,微服务架构的逐步普及,让我们过往几十数百台主机的系统规模,一跃变为成千上万的运维对象。各行各业龙头企业的IT规模已经与运维人员的比例形成了绝大差距,这也给运维带来了空前的影响。
智能运维场景系统性分析
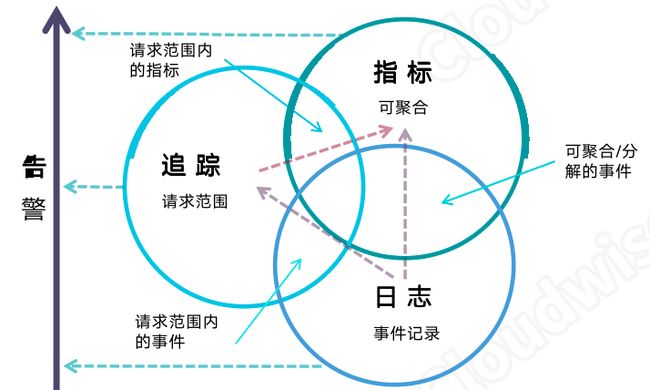
接下来,让我们从运维人员日常会遇到的场景出发,看看运维人员的主要工作内容。首先是运维的范围,它围绕“指标”、“日志”、“调用链”这三个基础指标以及“告警”这个派生指标进行研究。
Peter Bourgon 在 2017 年 “Distributed Tracing Summit” 上对运维面对的 Logging、Metrics、Tracing进行了系统性的阐述,得到运维界的广泛认可。 根据其描述,运维的场景分为“一元场景”、“二元场景”、“转化场景”三个大类。
此外,运维人员每天都要面对的指标:比如容量指标,CPU、内存、磁盘的使用率。无论是“指标”、“日志”还是“调用链”,我们对它进行监控,设定阈值,它们都会产生“告警”,也就是说“告警”是前三者的派生指标。 指标、日志、追踪,按照他们的组合和转换关系,就形成了一元、转化和二元的运维场景。
- 一元场景
指标:可聚合的逻辑计量单元
日志:对离散的不连续的事件的一种记录
追踪:单次请求范围内的所有信息,即调用链信息
- 转化场景
日志→指标:通过日志获得指标数据
日志→追踪:通过对日志的聚合和转化得到追踪
追踪→指标:通过调用链的分析获得调用范围内的指标
指标、日志、追踪→告警: 多个源头产生的告警
二元场景
日志+指标 :可聚合/分解的事件
日志+追踪:一个调用周期内的事件
追踪+指标:一个调用周期内的指标
智能运维建设思路
面对上述的这些挑战,云智慧的应对解决思路主要有以下4条:
- 全栈式监控,统一化管理。主要是从基础架构、应用性能、用户体验构建等方面,从底层设施到上层业务形成全面监控体系,主动对业务、基础设施的运行状态进行全面感知。
- 数据统一采集,建立运维数仓。对客户现有工具的数据进行统一收集和纳管,将数据标准化、场景化、共建、共享、共用。
- 建立标准,构建运维体系。通过对云上云下的离散资源数据、关系复杂的逻辑数据、核心指标数据,按照业务层级结构进行关联,形成资源图谱和指标体系。
- 数据可视化,数据价值化。主要是通过采集到的告警、指标、性能、资产资源的数据进行关联融合,形成不同驾驶分仓,呈现不同数据场景。如:系统运行综合态势、业务变化趋势等。
解决方案与功能场景介绍
解决方案整体架构
基于以上运维解决思路,云智慧的整体解决方案如下图所示,整个解决方案的整体架构主要分为三大部分:
- 左侧部分:整个产品的设计参考了相关行业的体系指南,包括:国际标准ISO20000、ITSS、ITIL4、业务连续性性能管理、DevOps、AIOps等。
- 中间部分:是整个解决方案的核心。底层是我们监控工具层,负责监控数据的采集;中间层主要是数字运维中台,主要是对立体化工具采集的数据进行处理;最上层为智能运维场景。平台的整个设计思路是运维通用能力下沉,Pass平台化;业务场景化上浮,Saas化。
- 右侧部分:主要是平台能够提供与第三方无缝集成的能力,集成包括配置、性能、告警、日志数据等。

功能场景介绍
接下来,我们将对基础监控场景、云化监控场景、智能告警、融合场景的分析以及涵盖数据价值化等一体化运维相关场景进行详细介绍。
- 全栈式监控,多维度覆盖
云智慧全栈式监控场景能够对IDC基础设施到上层业务进行全方位监控。包括面向机房动力环境设施、服务器硬件、操作系统、网络、应用、业务等运行健康度状态、性能状况进行实时监控与管理。
平台能够提供有代理(agent)、无代理(snmp、wmi、syslog、jdbc等协议的方式)来监控方式,当代理采集的监测指标无法满足用户的监控需求时,用户可以通过云智慧产品提供的开放采集能力,开发相关指标来满足个性化的监控需求。
目前云智慧全栈式监控中用户的数据中心都是两地三中心模式。此外,为了满足业务连续性的需要,还提供分布式、跨中心的部署,来满足用户多中心监管需要。

- 自动网络拓扑,快速会诊故障
在网络监控场景中,不得不提的就是自动发现拓扑能力。当故障发生时,它可以帮助网络运维人员快速对故障进行诊断。首先运维人员可以基于ICMP、ARP、SNMP以及LLDP通过一键发现迅速地将当前网段中的数据进行实时收集;故障定位主要是通过告警事件与故障设备进行关联,便于网络运维人员迅速发现问题、定位问题 ;故障分析是借助已发现的拓扑,查看故障设备的告警详细信息,以及当前指标状况,综合各方面信息彻底解决故障。
- 通过流量,精准分析业务的可用性
网络流量监控场景主要是通过网络流量对业务的可用性进行精准分析。流量监控主要是根据网络五元组(源ip、源端口、目标ip、目标端口、协议)针对业务及应用突发的异常大流量,及时发现网络性能异常,实施预警。另一方面,通过网络流量,用户可以分析企业网络流量的利用率是否合理,也给网络后期扩展提供依据,避免投资的浪费。

实时监控网络配置,让网络配置过程合规化
网络日常运维工作中,为解决网络的一些问题(如:系统的升级、打补丁、网络日常维护等),运维人员需要进行相关的备份操作和变更前后的网络配置文件检查动作。因此,这里说的网络配置场景就是解决运维人员在进行上述操作前后文件失败时能够及时预警,并通知相关运维人员发现变更异常状态。
同时提供配置文件的回溯查看功能,通过界面查看变更前和变更后文件内容,极大的提升了网络运维人员的日常工作效率。

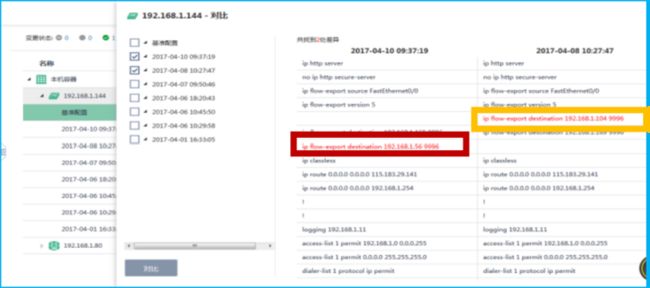
下图中红色和黄色部分就是两次不同时间的配置文件的对比, 用户可以从上百行甚至上千行的文件中迅速找到,变更前后不一样的地方。(黄色)变更前的IP是192.168.1.104,(红色)变更后IP是192.168.1.56,无需通过登录设备检查。
- 合理规划IP地址使用,提高网络安全
网络管理的第四个场景,那就是IP地址管理。通过IP地址管理功能可以帮助数据中心合理的分配网络地址的日常使用和长期规划,从而提高网络安全性。
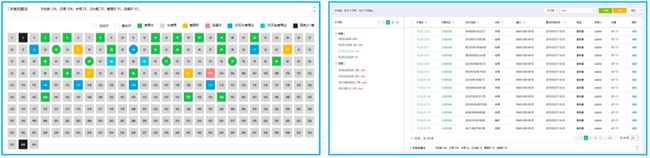
定时扫描,精准监测:通过工具定期扫描子网,提供子网中IP地址的可用性状态。用户可以检查某个特定IP的状态是保留还是可用。该工具接受多个子网导入,帮助扫描整个网络,获取IP地址的状态。
可视界面,实时查:基于可视化的界面中,以不同的颜色区分IP地址的使用状态,包括:使用中、未使用、管理IP、保留IP等。
- 关注业务的连续性,洞察用户真实体验
关于业务连续性监测场景,云智慧主要是通过端到端的链路式监测方式,主动感知用户的真实体验。
- 端到端链路追踪,主动感知业务状态:全面实时获取服务端性能数据,通过应用、 组件、集群、容器及代码等逐层深入分析,帮助企业定位分析自身服务端性能问题。
- 全方位主动监测,了解用户体验:实时感知终端用户是否遭遇了崩溃、卡顿、页面加载缓慢等体验不佳问题。
- 快速响应,一键分析:可实时分析用户操作数据,预测用户体验评分,帮助运维团队更高效、精准地进行用户投诉分析,提升用户满意度。
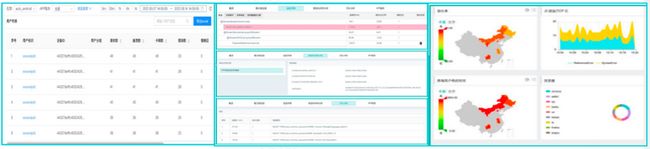
- 可观测性 云原生 监测,让瞬息万变运维简单化
随着业务云化的不断深入,k8s和容器化对业务的伸缩性和扩展性的要求越来越灵活。当故障发生时,从IT运维团队、网络团队到业务团队均在故障排查时变得越来越困难。基于可观测性的云原生监测,主要是通过收集业务日志、监测指标以及业务链路关系等相关数据进行融合,构建业务拓扑链路。此外,还可以快速对故障进行分析、定位、快速恢复业务,保障业务的稳定性、安全性。 例如:从右侧视图中,我们可以看出,用户在app端发生故障时,通过业务拓扑链路,发现是在“深圳的集群节点发生故障”,集群对应的IP是192.168.100.50这个服务发生故障。同时可以再次下钻分析,看看具体是哪个指标引起的故障。
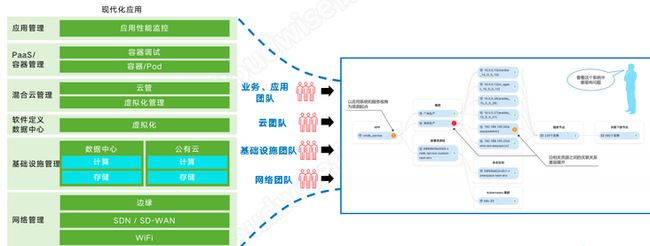
- 云原生 的微服务监测,玩转应用弹性伸缩
现在业务的连续性的要求高,大多数新业务的开发的技术都是基于微服务架构,通过k8s编排能力,在业务高峰期能够实现动态扩展,弹性伸缩。那么同时给运维工作也带来了很多难度。
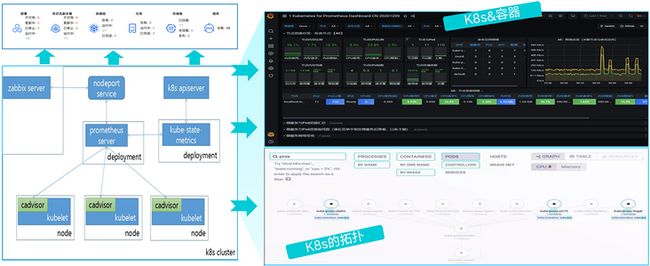
企业云之后对微服务的监测,一方面主要是通过K8s的自带组件,cadvisor、kube-stat-metrics进行数据采集,另一方面则是通过开源方案promethues方式采集数据,最后通过zabbix调用promethues、cadvisor、kube-stat-metrics API获取数据进行统一监测与管理。
展现方面主要通过目前比较主流的grafana插件对监控的指标进行展现,包括:pod可用性、pod状态、node状态、node的cpu、men、IO、网络可用性、服务可用性等相关指标进行监控。
拓扑是根据开源Weave Scope插件,会自动构建应用和集群的逻辑拓扑。比如 pod、容器、服务、Pod 以及 Pod 之间的依赖关系。
此外,数据展示可以利用开源的grafana工具进行各种形式的展示,来满足不同用户对数据分析的需要,同时可以利用云智慧飞鱼平台(一款可视化的工具)对数据进行大屏可视化。
- 事件处理流水线,快速实现全生命周期管理
告警是构建全面监控能力不可或缺的一部分,尤其是当下的用户环境中一般不仅仅只有一种监控工具,而是多种监控工具的整合。为了实现告警事件统一化、智能化的管理,云智慧的智能告警平台对各类监控工具事件进行整合,同时通过五大流水线的过程(告警丰富、告警压缩、告警抑制、告警通知、事件处置)来快速实现事件全生命周期管理。

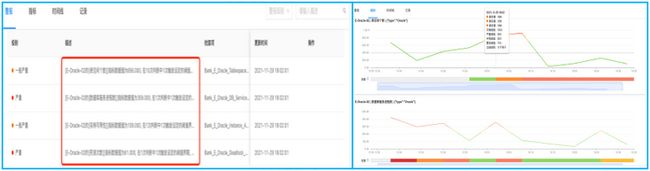
- 海量告警智能分析,一站式故障排查和定位
下图为一站式智能告警故障排查和定位的场景,通过图片我们可以看到oracle数据发生了故障,由此针对海量的告警进行收敛识别,发现了关于oracle表空间、进程、实例、死锁的5条告警。同时能根据告警相关的基本规则,通过自动学习的算法能力,如:集群合并、IP合并等把同一时间与该告警相关的告警进行了聚合。最后通过告警与指标关联,查看当前该告警的指标趋势,发现可能是死锁引起的问题。因此,通过对告警的智能分析,我们可以避免无效告警、告警风暴的发生,快速对故障的排查和定位,全面提升告警管理能力。
- 一键化设置,快速规避无效告警
在日常运维中,企业信息中心经常会因为消除故障或者是问题对软硬件升级等进行变更。此时,往往会发生已监控的设备在变更窗口期会产生大量的告警,并且这些告警是运维人员已知或者是可预见性的。与此同时,如果有真实的告警发生,往往会被淹没,发生重大事故。为了防止类似的问题,云智慧可以提供灵活的维护期策略,如根据告警源、IP、主机名、级别等条件设置变更窗口的时间,来杜绝以上问题的发生,加强变更的安全性。

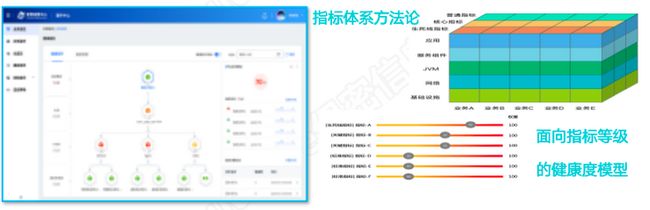
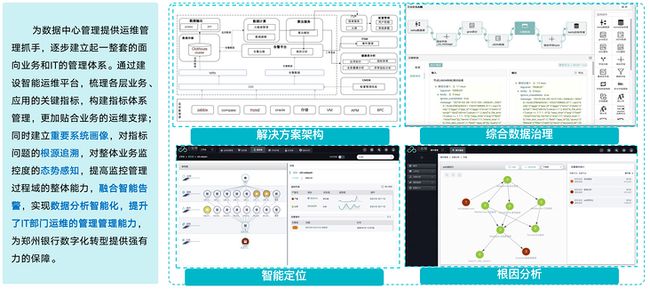
- 依托数据指标为基础,打造业务运维体系
融合场景主要有两个维度,一个是指标体系管理,另一个是基于配置资源图谱。在IT发展的过程中,用户信息化经过多年完善已经完成了大量的工具平台建设,但是由于工具数据之间没有融合,只能单方面反映问题,因此不能充分发挥数据的作用。通过云智慧的指标体系方法论和基于实践的健康度模型,我们可以对各工具数据进行融合,构建业务的分层画像,为我们的业务健康度进行实时评分,多维度综合分析(拓扑、指标、告警)。此外,依托数据指标为基础,打造业务的运维体系,能够对故障进行实时预警、实时分析以及及时处置。
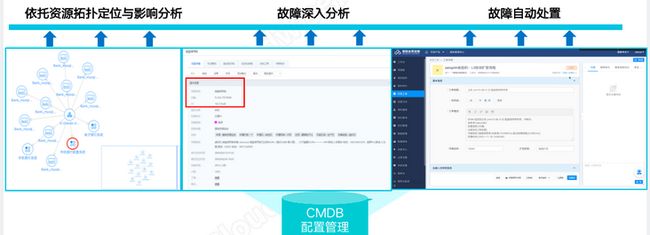
- 构建配置资源图谱,助力故障根源因分析
配置资源图谱故障场景主要是依托CMDB的层级拓扑对故障CI进行定位。打通事件与CMDB,把CMDB中的相关CI关键属性信息(如IP地址、主机名、应用标识、负责人、电话、资源的所属位置等)丰富到告警事件中,加强告警的易读性和准确性。同时通过告警生成工单,在处置的过程中,关联CI保障数据的准确性,对故障进行闭环管理,加强CMDB配置数据的流动性和唯一性。其目标就是通过配置资源图谱拓扑可视化能力,帮助运维人员对故障进行根因分析、故障自动处置,快速恢复业务。
- 数据可视化,让数据不再沉睡
采集的大量的数据,如何做到数据场景化,数据价值化呢?在这里,主要依托于云智慧的运维数据中台,通过对监控系统数据、告警事件数据、业务系统数据、资产配置等数据进行融合与关联,同时基于客户的业务特点,和IT运维人员的关注点,进行展示。 下图为某航空公司的大屏数据展示效果,从机房动力环境监控、综合业务系统运行资源监控到航空运营分析平台,进行全方面数据展示。

- 平台自服务,解决后顾之忧
目前云智慧平台拥有完善的自我监控服务能力。不仅有自我监测能力,此外,还有一键部署、自动巡检、报告推送、动态扩展的能力等。一方面平台能够对产品自身所部署的组件运行状态进行全面检查,另一方面能够对巡检的结果进行报告推送。 此外,平台内置应用商店,除了平台的一键自动化部署外,尤其是服务异常时,还支持动态扩展,满足客户业务的动态的调整。
价值与优势
- 方案优势:运营数据,价值共创

- 产品优势:不是工具的堆砌,而是运维的未来

案例分享
- 某 国企 一体化智能运维项目案例

- 某地产一体化运营项目案例

- 某银行智能运维平台项目案例
写在最后
近年来,在AIOps领域快速发展的背景下,IT工具、平台能力、解决方案、AI场景及可用数据集的迫切需求在各行业迸发。基于此,云智慧在2021年8月发布了AIOps社区, 旨在树起一面开源旗帜,为各行业客户、用户、研究者和开发者们构建活跃的用户及开发者社区,共同贡献及解决行业难题、促进该领域技术发展。
社区先后 开源 了数据可视化编排平台-FlyFish、运维管理平台 OMP 、云服务管理平台-摩尔平台、 Hours 算法等产品。
可视化编排平台-FlyFish:
项目介绍:https://www.cloudwise.ai/flyF...
Github地址: https://github.com/CloudWise-...
Gitee地址: https://gitee.com/CloudWise/f...
行业案例:https://www.bilibili.com/vide...
部分大屏案例:

您可以添加小助手(xiaoyuerwie)备注:飞鱼。加入开发者交流群,可与业内大咖进行1V1交流!
也可通过小助手获取云智慧AIOps资讯,了解FlyFish最新进展!