Week 2 reference、链表| CS61B-Spring-2018
文章目录
- References
-
- 1. 声明变量
- 2. 参数传递
- 3. 黄金定律(GRoE)
- 4. 数组实例化
- 链表
-
- 一、IntList
-
- 1. 构造
- 2. size()
- 3. get()
- 二、SLList单向链表
-
- IntList的缺陷
- 1. 改进1:重命名
- 2.1. 改进2.1:加入中介
- 2.2. 改进2.2:加入方法辅助链表构建
-
- 改进1 与 改进2
- 3. 改进3:public and private
-
- 改进3
- 4. 改进4:嵌套类
-
- 改进4
- 5. 改进5:size()与缓存
-
- 5.1 加入size()
- 5.2 使用缓存重写size()
- 改进5
- 6.1. 改进6.1:空链表
- 6.2. 改进6.2:加入addLast()方法
- 6.3. 改进6.3:修复addList()--Sentinel Nodes
-
- 改进6
- 三、DLList双向链表
-
- SLList的缺陷
- 7. 改进7:双向链表
-
- 改进7
- 8. 改进8:哨兵节点升级
-
- 改进8
- 9. 改进9:泛型
References
Walrus a = new Walrus(1000, 8.3);
Walrus b;
b = a;
b.weight = 5;
System.out.println(a);
System.out.println(b);
对b的改变会影响a吗?–会。
因为new Walrus(1000, 8.3)新建了一个对象,将其赋值给a即是令a的内存空间指向该对象。而b=a则是将a的内存空间的内容复制给b的内存空间,也就是在b的内存空间中填充指向Walrus的地址。当使用b.weight=5改变该对象的实例变量后,a还指向该对象,因此也会改变a.weight的值。
1. 声明变量
-
Java的八种原始类型: byte, short, int, long, float, double, boolean, char。当声明某个类型的变量时,Java将找到一个连续的块,该块的位数恰好足以容纳该类型的东西。例如,如果声明一个int,则会得到一个32位的块。如果声明一个字节,则会得到一个8位的块。块内存储数据本身。
-
其他所有内容(包括数组、链表、对象等)都不是原始类型,而是reference type。在声明这些reference type时,声明的变量存储的是指向这些对象的地址。无论对象是什么类型,Java都会分配一个64位的框,用来存地址。
-
String s:声明变量,为s分配64位存储地址的空间。(不写入内容,也不创建对象)
s = new String;:创建对象,为一个空字符串分配空间;对s进行初始化。
String s = new String;:声明;创建对象;初始化
注意: 每个变量都必须声明类型和初始化。
可以将new视为返回创建的新对象的地址。 -
当我们使用new 关键字创建类的实例时,Java为每个字段创建位框,其中每个框的大小由每个字段的类型定义。例如,如果一个Walrus对象具有一个 int变量和一个double变量,则Java将分配两个框,总计96位(32 + 64)以容纳两个变量。这些将设置为默认值,例如0。然后,构造函数进入并将这些位填充为适当的值。构造函数的返回值将返回盒子所在的内存位置,通常是64位地址。然后可以将该地址存储在类型为“reference type”的变量中。
Ps.如果丢失与地址对应的bits,则对象可能会丢失。例如,如果特定对象的地址的唯一副本存储在中x,对x进行重新赋值时,如x = null,则将导致永久丢失该对象。这不一定是一件坏事,因为经常会决定对一个对象已完成操作,因此简单地丢弃地址是安全的。
2. 参数传递
方法传参时,就是copy bits,也就是把主函数中要传的参数bits完全复制给方法参数。(copy bits就是pass by value,在Java中只pass by value)
练习:
public class PassByValueFigure {
public static void main(String[] args) {
Walrus walrus = new Walrus(3500, 10.5);
int x = 9;
doStuff(walrus, x);
System.out.println(walrus);
System.out.println(x);
}
public static void doStuff(Walrus W, int x) {
W.weight = W.weight - 100;
x = x - 5;
}
}
调用的函数doStuff是否会对walrus和x产生影响?
—会改变walrus的值,但不会影响x。
3. 黄金定律(GRoE)
y = x copies all the bits from x to y.
4. 数组实例化
int[] x = new int[]{0, 1, 2, 95, 4};
int[] x为声明,new int[]{0, 1, 2, 95, 4}为初始化
注意:数组的大小是在创建数组时指定的,不能更改!
链表
一、IntList
这一节实现了链表的基本构建。(最初级的方法)
1. 构造
事实证明,实现一个非常基本的链表很简单,如下所示:
public class IntList {
public int first;
public IntList rest;
/** 构造函数 */
public IntList(int f, IntList r) {
first = f;
rest = r;
}
}
这样的列表很难使用。例如,如果我们要列出数字5、10和15,则可以执行以下操作:
IntList L = new IntList(5, null);
L.rest = new IntList(10, null);
L.rest.rest = new IntList(15, null);
或者,我们可以向后构建列表,从而产生稍微更好但更难理解的代码:
IntList L = new IntList(15, null);
L = new IntList(10, L);
L = new IntList(5, L);
注意: 代码是从右往左执行的,所以将L赋值给new IntList的rest的操作 在 改变L存储的地址之前。

虽然原则上可以使用IntList来存储任何整数列表,但是生成的代码非常难看并且容易出错。
2. size()
两种方法:递归(recursion)和迭代(iteration)
迭代:需要指针p
/** Return the size of the list using iteration! */
public int iterativeSize() {
IntList p = this;
int totalSize = 0;
while (p != null) {
totalSize += 1;
p = p.rest;
}
return totalSize;
}
递归:需要basecase,即无法进行迭代的情况
/** Return the size of the list using... recursion! */
public int size() {
//basecase
if (rest == null) {
return 1;
}
return 1 + this.rest.size();
}
练习:您可能想知道为什么我们不做类似的事情if (this == null) return 0;。为什么不起作用?
答案:想想当call size() 时会发生什么。您正在一个对象上调用它,例如L.size() 。如果L为null,则将出现NullPointer错误!
为什么???
3. get()
递归:
public int get(int i){
//basecase
if(i==0) return first;
return this.rest.get(i-1);
}
二、SLList单向链表
这一节改进、实现了单向链表的构建。
IntList的缺陷
- 不利于不知道递归的人的使用,使用起来不simple —改进1、改进2
- naked linked list,调用时需用
IntList L = new IntList(5, null);,不能隐藏null等IntList的实现细节。不好看且不好用。—改进1、改进2 - 外部类能够直接对IntList类中的first和rest属性进行操作,可能会产生bug。—改进3
剩下的改进4、5、6是在完成前三个改进的基础上进行的改进。
1. 改进1:重命名
原IntList构建方法:
public class IntList {
public int first;
public IntList rest;
public IntList(int f, IntList r) {
first = f;
rest = r;
}
...
重命名并丢弃辅助方法。现IntNode:
public class IntNode {
public int item;
public IntNode next;
public IntNode(int i, IntNode n) {
item = i;
next = n;
}
}
2.1. 改进2.1:加入中介
直接调用naked list不好看也不好用,给naked list穿一个衣服:用SLList当做main函数与IntNode之间的中间人。
public class SLList {
public IntNode first;
public SLList(int x) {
first = new IntNode(x, null);
}
}
2.2. 改进2.2:加入方法辅助链表构建
- addFirst与getFirst
/** Adds an item to the front of the list. */
public void addFirst(int x) {
first = new IntNode(x, first);
}
/** Retrieves the front item from the list. */
public int getFirst() {
return first.item;
}
- IntList链表的创建 vs SLList链表的创建
SLList L = new SLList(15);
L.addFirst(10);
L.addFirst(5);
int x = L.getFirst();
IntList L = new IntList(15, null);
L = new IntList(10, L);
L = new IntList(5, L);
int x = L.first;
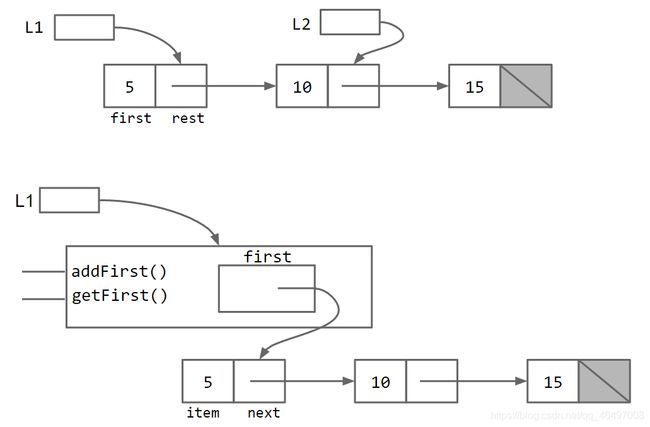
改进1 与 改进2
1 隐藏了Null指针、next指针等细节
2 更方便实用,不需要理解递归
3. 改进3:public and private
-
private:
private变量和方法只能由本.java文件中的代码访问;其他类不能访问 -
public:
其他类可以使用。因此,必须让public属性的方法和变量永远保持可用和正常工作。否则其他类在使用时会出错。
改进3
- private让使用该类的用户可以忽略(因此无需理解)某些代码,因此更便于使用与理解。
- private降低了其他类使用该类出错的风险。
eg. 让最后一个node自己指向自己。会出错。因此不应该让外部直接访问到SLList的实例变量first。如果需要访问或操作,应该用get和set方法或其他方法辅助外部类对该类的属性进行操作。
SLList L = new SLList(15);
L.addFirst(10);
L.first.next.next = L.first.next;
4. 改进4:嵌套类
嵌套类:将一个类放入另一个类中。如果一个类明显是另一个类的附属,可以作为嵌套类。
将嵌套类声明为static意味着静态类内部的方法无法也不必访问外部类的任何成员(方法与变量)。在这种情况下,这意味着在IntNode不能够访问first,addFirst或getFirst。
public class SLList {
public static class IntNode {
public int item;
public IntNode next;
public IntNode(int i, IntNode n) {
item = i;
next = n;
}
}
private IntNode first;
...
改进4
使用嵌套类能够节省内存,且使代码易读。
5. 改进5:size()与缓存
5.1 加入size()
SLList不是递归的。因为它没有一个类型为SLList的属性。为了递归实现size(),需要一个private(因为只有size()方法会用到该辅助方法,外部类不需要访问)辅助方法来与naked recursive data structure(即IntNode)进行交互。
/** Returns the size of the list starting at IntNode p. */
private static int size(IntNode p) {
if (p.next == null) {
return 1;
}
return 1 + size(p.next);
}
public int size() {
return size(first);
}
ps. 名字一样但参数不同的方法称为overloaded。
5.2 使用缓存重写size()
之前的递归size()方法所消耗的时间与链表的数据长度成正比。改进size(),使其与链表的数据长度无关:
public class SLList {
... /* IntNode declaration omitted. */
private IntNode first;
private int size;
public SLList(int x) {
first = new IntNode(x, null);
size = 1;
}
public void addFirst(int x) {
first = new IntNode(x, first);
size += 1;
}
public int size() {
return size;
}
...
}
这种保存重要数据以加快检索速度的做法有时称为缓存。
改进5
- 具有了size()方法。
- 改进size()方法,使速度更快。
6.1. 改进6.1:空链表
重写构造函数:
public SLList() {
first = null;
size = 0;
}
6.2. 改进6.2:加入addLast()方法
使用迭代方法:
public void addLast(int x) {
size += 1;
IntNode p = first;
while (p.next != null) {
p = p.next;
}
p.next = new IntNode(x, null);
}
但是,当创建空链表时,因为p.next无法访问,addLast()会出现空指针错误。
6.3. 改进6.3:修复addList()–Sentinel Nodes
- 修复addList()最简单的方法:加入
if (first == null) {
first = new IntNode(x, null);
return;
}
但是,应该尽量避免使用特殊情况。虽然这里特殊情况很少,但是在其他数据结构中,有可能有很多特殊情况。
- 更好的方法:使空链表与非空链表具有相同的结构——创建哨兵节点。

public class SLList {
public static class IntNode {
public int item;
public IntNode next;
public IntNode(int i, IntNode n) {
item = i;
next = n;
}
}
private IntNode sentinel;
private int size;
public SLList() {
sentinel = new (63, null)
size = 0;
}
public SLList(int x) {
sentinel = new IntNode(63, null);
sentinel.next = new IntNode(x, null);
size = 1;
}
public void addFirst(int x) {
sentinel.next = new IntNode(x, sentinel.next);
size += 1;
}
public int getFirst() {
return sentinel.next.item;
}
public int size() {
return size;
}
public void addLast(int x) {
size += 1;
IntNode p = sentinel;
while (p.next != null) {
p = p.next;
}
p.next = new IntNode(x, null);
}
}
改进6
- 能够建立空链表、addLast
- 使空链表与非空链表具有一样的结果,去掉了特殊情况。
三、DLList双向链表
这一节改进单向链表为双向链表。
SLList的缺陷
- addLast太慢,因为要遍历整个链表。
- 解决方案1:
在SLList类中加入一个属性:last,指向最后一个节点
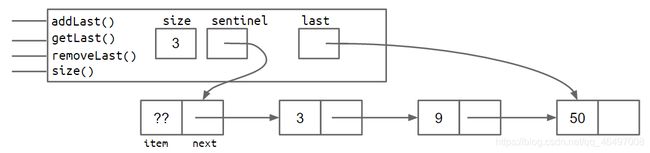
- 解决方案1的缺陷:
removeLast操作慢,因为必须要遍历找到倒数第二个。
解决方案2见改进7.
7. 改进7:双向链表
public class IntNode {
public IntNode prev;
public int item;
public IntNode next;
}
- 当链表为空时,只有一个哨兵节点:

- 当链表不为空时:
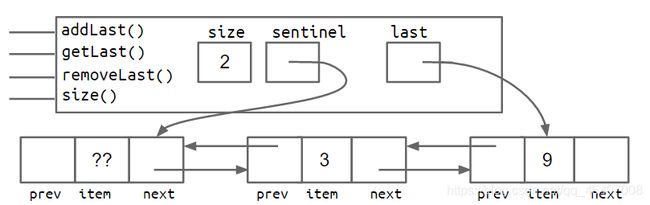
改进7
- 使addLast和removeLast更快。
- 缺陷:有特殊情况出现—DLList的Last属性有时指向哨兵节点,有时指向真正的节点。
8. 改进8:哨兵节点升级
为了去掉DLList的特殊情况:
- 解决方案1:
再添加一个sentinel哨兵节点指向最后一个节点。
空链表时:
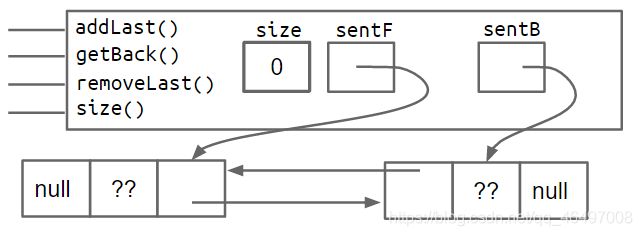
非空链表时:
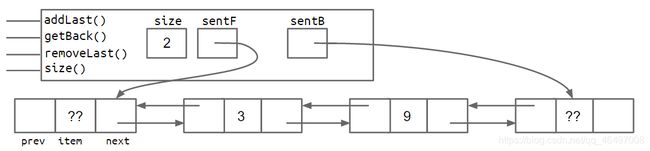
- 解决方案2:
将链表实现为环形,使链表(包括哨兵节点)的最后一个节点永远指向哨兵节点(即第一个节点);链表的哨兵节点的pre指针不为null,而是最后一个节点。也即:令最后一个节点是哨兵节点的前一个节点。
空链表:
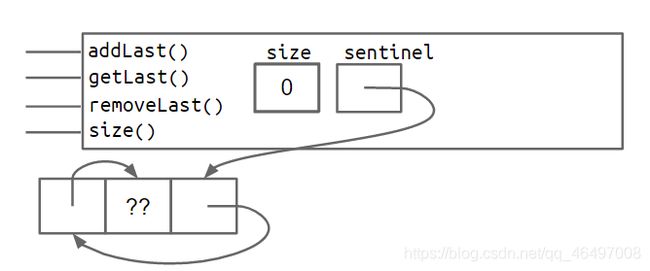
非空链表:
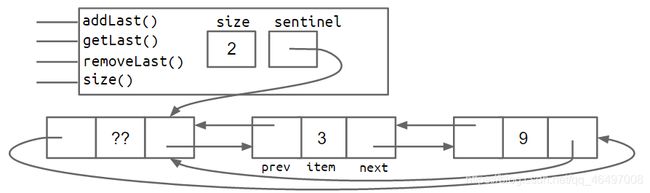
改进8
去掉了DLList的特殊情况—DLList的Last属性有时指向哨兵节点,有时指向真正的节点。
9. 改进9:泛型
使链表中不仅可以存储整数,还可以是任意类型的数据。
泛型使用的法则:
- 在实现数据结构的.java文件中,仅在文件顶部、类名之后使用<>指定一次通用类型名。
public class DLList<T> {
private IntNode sentinel;
private int size;
public class IntNode {
public IntNode prev;
public T item;
public IntNode next;
...
}
...
}
- 在其他使用您的数据结构的.java文件中,只需在声明时在<>中指定一次特定的所需类型,并在实例化时使用空的<>。
DLList<String> d2 = new DLList<>("hello");
d2.addLast("world");
ps.DLList也可以,但是实例化中的Integer是完全多余的。
- 如果您需要实例化一个普通的基本类型,使用Integer,Double,Character,Boolean,Long,Short,Byte,或Float。