RDD常用算子编程-附有代码
一.RDD常用操作
transformation are lazy, noting actually happen until an action is called
action trigger the computation
action returns values to driver or writes data to external storage
二. Transformat
create a new dataset from an existing one
RDD是不可变,所以过程RDDA –》 transforma –》RDDB
map
from pyspark import SparkConf, SparkContext conf = SparkConf().setMaster('local[2]').setAppName('spark1024') sc = SparkContext(conf=conf) data = [1,2,3,4] rdd1 = sc.parallelize(data) rdd2 = rdd1.map(lambda x: x*2)结果:
将func函数作用到数据集的每一个元素上,生成一个新的分布式的数据集返回
filter
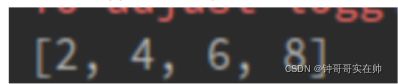
data = [1, 2, 3, 4] rdd1 = sc.parallelize(data) rdd2 = rdd1.filter(lambda x: x >2)结果:
flatMap
data = ['hello word', 'hello kitty', 'hello spark'] rdd1 = sc.parallelize(data) rdd2 = rdd1.flatMap(lambda x: x.split(' '))结果:
groupByKey
data = ['hello word', 'hello kitty', 'hello spark'] rdd1 = sc.parallelize(data) rdd2 = rdd1.flatMap(lambda x: x.split(' ')).map(lambda s:(s, len(s))) rdd3 = rdd2.groupByKey() print(rdd3.collect()) return rdd3.map(lambda x:{x[0]:list(x[1])}).collect()结果:
reduceByKey
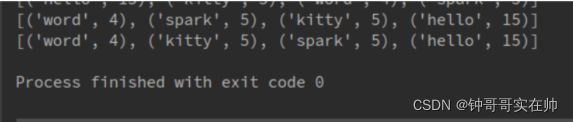
data = ['hello word', 'hello kitty', 'hello spark'] rdd1 = sc.parallelize(data) rdd2 = rdd1.flatMap(lambda x: x.split(' ')).map(lambda s: (s, len(s))) rdd3 = rdd2.reduceByKey(lambda a, b: a + b) rdd4 = rdd3.sortByKey(ascending=False) print(rdd4.collect()) rdd5 = rdd3.map(lambda x:(x[1], x[0])).sortByKey().map(lambda x:(x[1], x[0])) return rdd5.collect()结果:
union
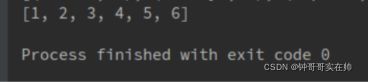
a = sc.parallelize([1,2,3]) b = sc.parallelize([4,5,6]) c = a.union(b) return c.collect()结果:
distinct
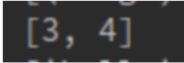
a = sc.parallelize([1,2,3,1]) c = a.distinct(a) print(c.collect())结果:
[1, 2, 3]
join
a = sc.parallelize([('A','a1'), ('B','b1'),('F','f1')]) b = sc.parallelize([('A', 'a2'), ('B', 'b2'), ('B', 'b3'), ('B', 'b1'), ('E', 'e1')]) return a.join(b).collect()结果:


三. Action
- collect
- count
- take
- reduce
- saveAsTextFile
- foreach
conf = SparkConf().setMaster('local[2]').setAppName('spark1024') sc = SparkContext(conf=conf) data = [1, 2, 3, 4, 5, 6, 7, 8, 9] rdd = sc.parallelize(data) print(rdd.count()) print(rdd.collect()) print(rdd.sum()) print(rdd.take(3)) print(rdd.max()) print(rdd.min()) print(rdd.reduce(lambda x, y:x+y)) rdd.foreach(lambda x: print(x)) rdd.saveAsTextFile('rdd') sc.stop()
四. 案例
txt目录文件夹内容可以为以空格分开的单词, 可以有多个文件:
My father was a self-taught mandolin player. He was one of the best string instrument players in our town. He could not read music, but if he heard a tune a few times, he could play it. When he was younger, he was a member of a small country music band. They would play at local dances and on a few occasions would play for the local radio station. He often told us how he had auditioned and earned a position in a band that featured Patsy Cline as their lead singer. He told the family that after he was hired he never went back. Dad was a very religious man. He stated that there was a lot of drinking and cursing the day of his audition and he did not want to be around that type of environment.
案例代码:
from pyspark import SparkConf, SparkContext import os if __name__ == '__main__': conf = SparkConf().setMaster('local[2]').setAppName('spark1024') sc = SparkContext(conf=conf) path = r'/home/spark/txt' files = os.listdir(path) files = [os.path.join(path, file)for file in files] rdd_total = sc.parallelize([]) for file in files: rdd = sc.textFile(file).flatMap(lambda x: x.split(' ')).map(lambda x:(x, 1)) rdd_total += rdd word_frequencys = rdd_total.reduceByKey(lambda x, y: x+y).map(lambda x:(x[1], x[0])).sortByKey(ascending=False).map(lambda x:(x[1], x[0])) print('取前3个高频单词', word_frequencys.take(3)) print('单词总数:', rdd_total.count()) for (word, frequency) in word_frequencys.collect(): print(word, ':', frequency)