图像处理入门基础(OpenCV)
文章目录
- 图像处理入门基础(OpenCV)
- 引言
- 1. OpenCV库基础操作
-
- 图像处理的概念与基本操作
-
- 图片、GIF、视频
- 像素:画面中最小的点
- 分辨率=画面水平方向的像素值 * 画面垂直方向的像素值
-
- 屏幕分辨率
- 图像分辨率
- 图像的基本概念
- 使用OpenCV加载并保存图片
-
- 说明
- 加载图片
- 2. OpenCV库进阶操作
-
- 图像基本操作
-
- ROI
- 通道分割与合并
- 颜色空间转换
-
- 特定颜色物体追踪
- 阈值分割
-
- 固定阈值分割
- 自适应阈值
- Otsu阈值
- 小结
- 图像几何变换
-
- 缩放图片
- 翻转图片
- 平移图片
- 绘图功能
-
- 画线
- 画矩形
- 添加文字
- 小结
- 图像间数学运算
-
- 图片相加
- 图像混合
- 按位操作
- 小结
- 平滑图像
-
- 滤波与模糊
- 均值滤波
- 方框滤波
- 高斯滤波
- 中值滤波
- 双边滤波
- 图像锐化
- 边缘检测
-
- Canny边缘检测
- 先阈值分割后检测
- 小结
- 腐蚀与膨胀
-
- 啥叫形态学操作
- 腐蚀
- 膨胀
- 开/闭运算
- 使用OpenCV摄像头与加载视频
-
- 打开摄像头
- 播放本地视频
- 录制视频
- 小结
- 3. 图像分类任务概念导入
-
- 计算机视觉中的图像分类任务
-
- 图像分类的基本任务
- 人工智能与深度学习
- 计算机视觉的子任务
- 图像分类问题的经典数据集
-
- MNIST手写数字识别
- Cifar数据集
-
- CIFAR-10
- CIFAR-100
- ImageNet数据集
- 4. PaddleClas数据增强代码解析与实战
- 5. 参考资料
图像处理入门基础(OpenCV)
引言
OpenCV是计算机视觉中经典的专用库,其支持多语言、跨平台,功能强大。OpenCV-Python为OpenCV提供了Python接口,使得使用者在Python中能够调用C/C++,在保证易读性和运行效率的前提下,实现所需的功能。
本章节主要介绍基于OpenCV的基础和进阶操作。
1. OpenCV库基础操作
图像处理的概念与基本操作
图片、GIF、视频





趣味视频项目
像素:画面中最小的点
分辨率=画面水平方向的像素值 * 画面垂直方向的像素值
屏幕分辨率
例如,屏幕分辨率是1024×768,也就是说设备屏幕的水平方向上有1024个像素点,垂直方向上有768个像素点。像素的大小是没有固定长度的,不同设备上一个单位像素色块的大小是不一样的。
例如,尺寸面积大小相同的两块屏幕,分辨率大小可以是不一样的,分辨率高的屏幕上面像素点(色块)就多,所以屏幕内可以展示的画面就更细致,单个色块面积更小。而分辨率低的屏幕上像素点(色块)更少,单个像素面积更大,可以显示的画面就没那么细致。
图像分辨率
例如,一张图片分辨率是500x200,也就是说这张图片在屏幕上按1:1放大时,水平方向有500个像素点(色块),垂直方向有200个像素点(色块)。
在同一台设备上,图片分辨率越高,这张图片1:1放大时,图片面积越大;图片分辨率越低,这张图片1:1缩放时,图片面积越小。(可以理解为图片的像素点和屏幕的像素点是一个一个对应的)。
但是,在屏幕上把图片超过100%放大时,为什么图片上像素色块也变的越大,其实是设备通过算法对图像进行了像素补足,我们把图片放的很大后看到的一块一块的方格子,虽然理解为一个图像像素,但是其实是已经补充了很多个屏幕像素;同理,把图片小于100%缩小时,也是通过算法将图片像素进行减少。

图像的基本概念
- 常见图片格式:jpg、png、gif、psd、tiff、bmp等
- 参考资料:几种常见图片格式的区别
使用OpenCV加载并保存图片
- 加载图片,显示图片,保存图片
- OpenCV函数:
cv2.imread(),cv2.imshow(),cv2.imwrite()
说明
大部分人可能都知道电脑上的彩色图是以RGB(红-绿-蓝,Red-Green-Blue)颜色模式显示的,但OpenCV中彩色图是以B-G-R通道顺序存储的,灰度图只有一个通道。
OpenCV默认使用BGR格式,而RGB和BGR的颜色转换不同,即使转换为灰度也是如此。一些开发人员认为R+G+B/3对于灰度是正确的,但最佳灰度值称为亮度(luminosity),并且具有公式:0.21R+0.72G+0.07*B
图像坐标的起始点是在左上角,所以行对应的是y,列对应的是x。
加载图片
使用cv2.imread()来读入一张图片:
-
参数1:图片的文件名
- 如果图片放在当前文件夹下,直接写文件名就行了,如’lena.jpg’
- 否则需要给出绝对路径,如’D:\OpenCVSamples\lena.jpg’
-
参数2:读入方式,省略即采用默认值
cv2.IMREAD_COLOR:彩色图,默认值(1)cv2.IMREAD_GRAYSCALE:灰度图(0)cv2.IMREAD_UNCHANGED:包含透明通道的彩色图(-1)
经验之谈:路径中不能有中文噢,并且没有加载成功的话是不会报错的,
print(img)的结果为None,后面处理才会报错,算是个小坑。
%matplotlib inline
import numpy as np
import cv2
import matplotlib.pyplot as plt
# 加载彩色图
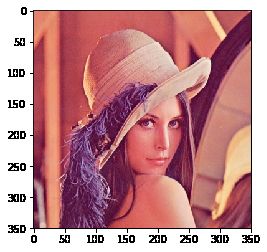
img = cv2.imread('lena.jpg', 1)
# 将彩色图的BGR通道顺序转成RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 显示图片
plt.imshow(img)
# 打印图片的形状
print(img.shape)
# 形状中包括行数、列数和通道数
height, width, channels = img.shape
# img是灰度图的话:height, width = img.shape
(350, 350, 3)
# 加载灰度图
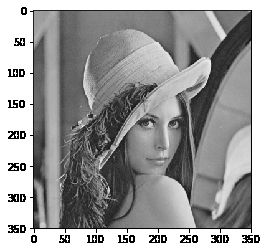
img = cv2.imread('lena.jpg', 0)
# 将彩色图的BGR通道顺序转成RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
img.shape
(350, 350, 3)
# 加载彩色图
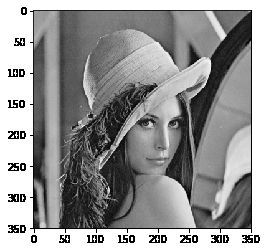
img = cv2.imread('lena.jpg', 1)
# 将彩色图的BGR通道直接转为灰度图
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
plt.imshow(img,'gray')
img.shape
(350, 350)
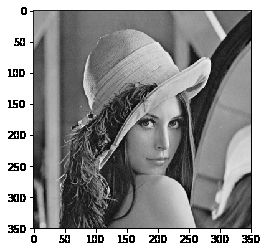
# 加载灰度图
img = cv2.imread('lena.jpg', 0)
# 显示这张灰度图
plt.imshow(img,'gray')
img.shape
(350, 350)
# 查看一下plt.imshow的用法
# ?plt.imshow
# 加载四通道图片
img = cv2.imread('cat.png',-1)
# 将彩色图的BGR通道顺序转成RGB,注意,在这一步直接丢掉了alpha通道
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
img.shape
(2180, 1911, 3)
img = cv2.imread('cat.png',-1)
# 和上图对比一下
plt.imshow(img)
img.shape
(2180, 1911, 4)

# 加载彩色图
img = cv2.imread('cat.png',1)
# 不转颜色通道
plt.imshow(img)
img.shape
(2180, 1911, 3)
img = cv2.imread('cat.png', 1)
# 转颜色通道为RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
img.shape
(2180, 1911, 3)

2. OpenCV库进阶操作
import math
import random
import numpy as np
%matplotlib inline
import cv2
import matplotlib.pyplot as plt
# 创建一副图片
img = cv2.imread('cat.png')
# 转换颜色通道
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
图像基本操作
学习ROI感兴趣区域,通道分离合并等基本操作。
ROI
ROI:Region of Interest,感兴趣区域。。
截取ROI非常简单,指定图片的范围即可
# 截取猫脸ROI
face = img[0:740, 400:1000]
plt.imshow(face)

通道分割与合并
彩色图的BGR三个通道是可以分开单独访问的,也可以将单独的三个通道合并成一副图像。分别使用cv2.split()和cv2.merge():
# 创建一副图片
img = cv2.imread('lena.jpg')
# 通道分割
b, g, r = cv2.split(img)
# 通道合并
img = cv2.merge((b, g, r))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)

RGB_Image=cv2.merge([b,g,r])
RGB_Image = cv2.cvtColor(RGB_Image, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(12,12))
#显示各通道信息
plt.subplot(141)
plt.imshow(RGB_Image,'gray')
plt.title('RGB_Image')
plt.subplot(142)
plt.imshow(r,'gray')
plt.title('R_Channel')
plt.subplot(143)
plt.imshow(g,'gray')
plt.title('G_Channel')
plt.subplot(144)
plt.imshow(b,'gray')
plt.title('B_Channel')
Text(0.5,1,'B_Channel')

颜色空间转换
最常用的颜色空间转换如下:
- RGB或BGR到灰度(COLOR_RGB2GRAY,COLOR_BGR2GRAY)
- RGB或BGR到YcrCb(或YCC)(COLOR_RGB2YCrCb,COLOR_BGR2YCrCb)
- RGB或BGR到HSV(COLOR_RGB2HSV,COLOR_BGR2HSV)
- RGB或BGR到Luv(COLOR_RGB2Luv,COLOR_BGR2Luv)
- 灰度到RGB或BGR(COLOR_GRAY2RGB,COLOR_GRAY2BGR)
经验之谈:颜色转换其实是数学运算,如灰度化最常用的是:
gray=R*0.299+G*0.587+B*0.114。
参考资料:OpenCV中的颜色空间
img = cv2.imread('lena.jpg')
# 转换为灰度图
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 保存灰度图
cv2.imwrite('img_gray.jpg', img_gray)
True
特定颜色物体追踪
HSV是一个常用于颜色识别的模型,相比BGR更易区分颜色,转换模式用COLOR_BGR2HSV表示。
经验之谈:OpenCV中色调H范围为[0,179],饱和度S是[0,255],明度V是[0,255]。虽然H的理论数值是0°~360°,但8位图像像素点的最大值是255,所以OpenCV中除以了2,某些软件可能使用不同的尺度表示,所以同其他软件混用时,记得归一化。
相关参考知识:
- RGB、HSV和HSL颜色空间
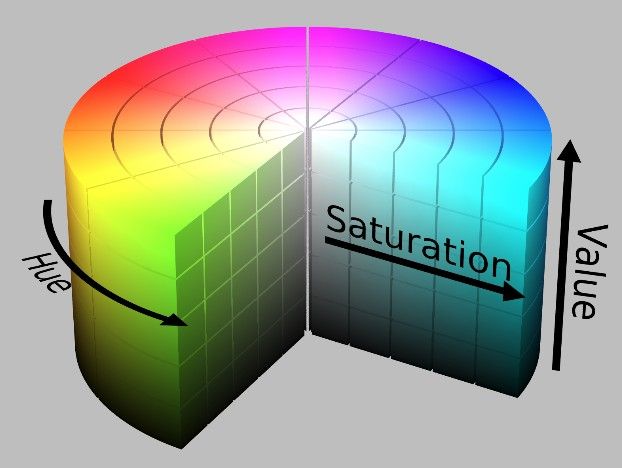
现在,我们实现一个使用HSV来只显示视频中蓝色物体的例子,步骤如下:
- 捕获视频中的一帧
- 从BGR转换到HSV
- 提取蓝色范围的物体
- 只显示蓝色物体
# 加载一张有天空的图片
sky = cv2.imread('sky.jpg')
# 蓝色的范围,不同光照条件下不一样,可灵活调整
lower_blue = np.array([15, 60, 60])
upper_blue = np.array([130, 255, 255])
# 从BGR转换到HSV
hsv = cv2.cvtColor(sky, cv2.COLOR_BGR2HSV)
# inRange():介于lower/upper之间的为白色,其余黑色
mask = cv2.inRange(sky, lower_blue, upper_blue)
# 只保留原图中的蓝色部分
res = cv2.bitwise_and(sky, sky, mask=mask)
# 保存颜色分割结果
cv2.imwrite('res.jpg', res)
True
res = cv2.imread('res.jpg')
res = cv2.cvtColor(res, cv2.COLOR_BGR2RGB)
plt.imshow(res)

其中,bitwise_and()函数暂时不用管,后面会讲到。那蓝色的HSV值的上下限lower和upper范围是怎么得到的呢?其实很简单,我们先把标准蓝色的BGR值用cvtColor()转换下:
blue = np.uint8([[[255, 0, 0]]])
hsv_blue = cv2.cvtColor(blue, cv2.COLOR_BGR2HSV)
print(hsv_blue)
[[[120 255 255]]]
结果是[120, 255, 255],所以,我们把蓝色的范围调整成了上面代码那样。
经验之谈:Lab颜色空间也经常用来做颜色识别,有兴趣的同学可以了解下。
阈值分割
- 使用固定阈值、自适应阈值和Otsu阈值法"二值化"图像
- OpenCV函数:
cv2.threshold(),cv2.adaptiveThreshold()
固定阈值分割
固定阈值分割很直接,一句话说就是像素点值大于阈值变成一类值,小于阈值变成另一类值。
cv2.threshold()用来实现阈值分割,ret是return value缩写,代表当前的阈值。函数有4个参数:
- 参数1:要处理的原图,一般是灰度图
- 参数2:设定的阈值
- 参数3:最大阈值,一般为255
- 参数4:阈值的方式,主要有5种,详情:ThresholdTypes
- 0: THRESH_BINARY 当前点值大于阈值时,取Maxval,也就是第四个参数,否则设置为0
- 1: THRESH_BINARY_INV 当前点值大于阈值时,设置为0,否则设置为Maxval
- 2: THRESH_TRUNC 当前点值大于阈值时,设置为阈值,否则不改变
- 3: THRESH_TOZERO 当前点值大于阈值时,不改变,否则设置为0
- 4:THRESH_TOZERO_INV 当前点值大于阈值时,设置为0,否则不改变
参考资料:基于opencv的固定阈值分割_自适应阈值分割
import cv2
# 灰度图读入
img = cv2.imread('lena.jpg', 0)
# 颜色通道转换
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 阈值分割
ret, th = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
plt.imshow(th)

th[100]
array([[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0],
...,
[255, 255, 255],
[255, 255, 255],
[255, 255, 255]], dtype=uint8)
# 应用5种不同的阈值方法
# THRESH_BINARY 当前点值大于阈值时,取Maxval,否则设置为0
ret, th1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
# THRESH_BINARY_INV 当前点值大于阈值时,设置为0,否则设置为Maxval
ret, th2 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY_INV)
# THRESH_TRUNC 当前点值大于阈值时,设置为阈值,否则不改变
ret, th3 = cv2.threshold(img, 127, 255, cv2.THRESH_TRUNC)
# THRESH_TOZERO 当前点值大于阈值时,不改变,否则设置为0
ret, th4 = cv2.threshold(img, 127, 255, cv2.THRESH_TOZERO)
# THRESH_TOZERO_INV 当前点值大于阈值时,设置为0,否则不改变
ret, th5 = cv2.threshold(img, 127, 255, cv2.THRESH_TOZERO_INV)
titles = ['Original', 'BINARY', 'BINARY_INV', 'TRUNC', 'TOZERO', 'TOZERO_INV']
images = [img, th1, th2, th3, th4, th5]
plt.figure(figsize=(12,12))
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.imshow(images[i], 'gray')
plt.title(titles[i], fontsize=8)
plt.xticks([]), plt.yticks([])

经验之谈:很多人误以为阈值分割就是二值化。从上图中可以发现,两者并不等同,阈值分割结果是两类值,而不是两个值。
自适应阈值
看得出来固定阈值是在整幅图片上应用一个阈值进行分割,它并不适用于明暗分布不均的图片。 cv2.adaptiveThreshold()自适应阈值会每次取图片的一小部分计算阈值,这样图片不同区域的阈值就不尽相同。它有5个参数,其实很好理解,先看下效果:
- 参数1:要处理的原图
- 参数2:最大阈值,一般为255
- 参数3:小区域阈值的计算方式
ADAPTIVE_THRESH_MEAN_C:小区域内取均值ADAPTIVE_THRESH_GAUSSIAN_C:小区域内加权求和,权重是个高斯核
- 参数4:阈值方式(跟前面讲的那5种相同)
- 参数5:小区域的面积,如11就是11*11的小块
- 参数6:最终阈值等于小区域计算出的阈值再减去此值
建议读者调整下参数看看不同的结果。
# 自适应阈值对比固定阈值
img = cv2.imread('lena.jpg', 0)
# 固定阈值
ret, th1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
# 自适应阈值, ADAPTIVE_THRESH_MEAN_C:小区域内取均值
th2 = cv2.adaptiveThreshold(
img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 4)
# 自适应阈值, ADAPTIVE_THRESH_GAUSSIAN_C:小区域内加权求和,权重是个高斯核
th3 = cv2.adaptiveThreshold(
img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 17, 6)
titles = ['Original', 'Global(v = 127)', 'Adaptive Mean', 'Adaptive Gaussian']
images = [img, th1, th2, th3]
plt.figure(figsize=(12,12))
for i in range(4):
plt.subplot(2, 2, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i], fontsize=8)
plt.xticks([]), plt.yticks([])

Otsu阈值
在前面固定阈值中,我们是随便选了一个阈值如127,那如何知道我们选的这个阈值效果好不好呢?答案是:不断尝试,所以这种方法在很多文献中都被称为经验阈值。Otsu阈值法就提供了一种自动高效的二值化方法。
小结
cv2.threshold()用来进行固定阈值分割。固定阈值不适用于光线不均匀的图片,所以用cv2.adaptiveThreshold()进行自适应阈值分割。- 二值化跟阈值分割并不等同。针对不同的图片,可以采用不同的阈值方法。
图像几何变换
- 实现旋转、平移和缩放图片
- OpenCV函数:
cv2.resize(),cv2.flip(),cv2.warpAffine()
缩放图片
缩放就是调整图片的大小,使用cv2.resize()函数实现缩放。可以按照比例缩放,也可以按照指定的大小缩放:
我们也可以指定缩放方法interpolation,更专业点叫插值方法,默认是INTER_LINEAR,全部可以参考:InterpolationFlags
缩放过程中有五种插值方式:
- cv2.INTER_NEAREST 最近邻插值
- cv2.INTER_LINEAR 线性插值
- cv2.INTER_AREA 基于局部像素的重采样,区域插值
- cv2.INTER_CUBIC 基于邻域4x4像素的三次插值
- cv2.INTER_LANCZOS4 基于8x8像素邻域的Lanczos插值
img = cv2.imread('cat.png')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 按照指定的宽度、高度缩放图片
res = cv2.resize(img, (400, 500))
# 按照比例缩放,如x,y轴均放大一倍
res2 = cv2.resize(img, None, fx=2, fy=2, interpolation=cv2.INTER_LINEAR)
plt.imshow(res)

plt.imshow(res2)

翻转图片
镜像翻转图片,可以用cv2.flip()函数:
其中,参数2 = 0:垂直翻转(沿x轴),参数2 > 0: 水平翻转(沿y轴),参数2 < 0: 水平垂直翻转。
dst = cv2.flip(img, 1)
plt.imshow(dst)

平移图片
要平移图片,我们需要定义下面这样一个矩阵,tx,ty是向x和y方向平移的距离:
M = [ 1 0 t x 0 1 t y ] M = \left[ \begin{matrix} 1 & 0 & t_x \newline 0 & 1 & t_y \end{matrix} \right] M=[10tx01ty]
平移是用仿射变换函数cv2.warpAffine()实现的:
# 平移图片
import numpy as np
# 获得图片的高、宽
rows, cols = img.shape[:2]
# 定义平移矩阵,需要是numpy的float32类型
# x轴平移200,y轴平移500
M = np.float32([[1, 0, 100], [0, 1, 500]])
# 用仿射变换实现平移
dst = cv2.warpAffine(img, M, (cols, rows))
plt.imshow(dst)

绘图功能
- 绘制各种几何形状、添加文字
- OpenCV函数:
cv2.line(),cv2.circle(),cv2.rectangle(),cv2.ellipse(),cv2.putText()
绘制形状的函数有一些共同的参数,提前在此说明一下:
- img:要绘制形状的图片
- color:绘制的颜色
- 彩色图就传入BGR的一组值,如蓝色就是(255,0,0)
- 灰度图,传入一个灰度值就行
- thickness:线宽,默认为1;对于矩形/圆之类的封闭形状而言,传入-1表示填充形状
- lineType:线的类型。默认情况下,它是8连接的。cv2.LINE_AA 是适合曲线的抗锯齿线。
画线
画直线只需指定起点和终点的坐标就行:
img = cv2.imread('lena.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 画一条线宽为5的红色直线,参数2:起点,参数3:终点
cv2.line(img, (0, 0), (800, 512), (255, 0, 0), 5)
plt.imshow(img)
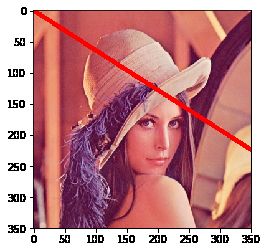
画矩形
画矩形需要知道左上角和右下角的坐标:
# 画一个矩形,左上角坐标(40, 40),右下角坐标(80, 80),框颜色为绿色
img = cv2.rectangle(img, (40, 40), (80, 80), (0, 255, 0),2)
plt.imshow(img)
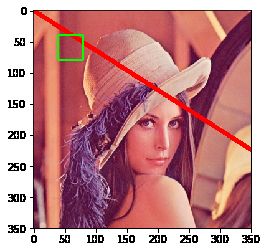
# 画一个矩形,左上角坐标(40, 40),右下角坐标(80, 80),框颜色为绿色,填充这个矩形
img = cv2.rectangle(img, (40, 40), (80, 80), (0, 255, 0),-1)
plt.imshow(img)

添加文字
使用cv2.putText()添加文字,它的参数也比较多,同样请对照后面的代码理解这几个参数:
- 参数2:要添加的文本
- 参数3:文字的起始坐标(左下角为起点)
- 参数4:字体
- 参数5:文字大小(缩放比例)
# 添加文字,加载字体
font = cv2.FONT_HERSHEY_SIMPLEX
# 添加文字hello
cv2.putText(img, 'hello', (10, 200), font,
4, (255, 255, 255), 2, lineType=cv2.LINE_AA)
array([[[255, 0, 0],
[255, 0, 0],
[255, 0, 0],
...,
[237, 148, 130],
[232, 143, 125],
[196, 107, 89]],
[[255, 0, 0],
[255, 0, 0],
[255, 0, 0],
...,
[233, 145, 125],
[231, 144, 124],
[195, 108, 88]],
[[255, 0, 0],
[255, 0, 0],
[255, 0, 0],
...,
[239, 151, 129],
[234, 150, 126],
[195, 113, 89]],
...,
[[ 87, 26, 60],
[ 92, 28, 62],
[ 91, 24, 57],
...,
[160, 68, 83],
[165, 67, 82],
[163, 63, 75]],
[[ 80, 18, 55],
[ 90, 26, 61],
[ 93, 26, 59],
...,
[167, 71, 85],
[174, 72, 86],
[173, 69, 80]],
[[ 79, 17, 54],
[ 91, 27, 62],
[ 96, 29, 64],
...,
[169, 73, 87],
[178, 73, 87],
[180, 74, 86]]], dtype=uint8)
plt.imshow(img)
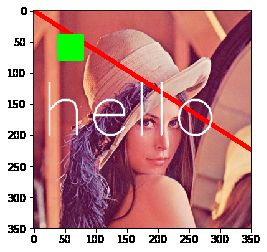
# 参考资料 https://blog.csdn.net/qq_41895190/article/details/90301459
# 引入PIL的相关包
from PIL import Image, ImageFont,ImageDraw
from numpy import unicode
def paint_chinese_opencv(im,chinese,pos,color):
img_PIL = Image.fromarray(cv2.cvtColor(im,cv2.COLOR_BGR2RGB))
# 加载中文字体
font = ImageFont.truetype('NotoSansCJKsc-Medium.otf',25)
# 设置颜色
fillColor = color
# 定义左上角坐标
position = pos
# 判断是否中文字符
if not isinstance(chinese,unicode):
# 解析中文字符
chinese = chinese.decode('utf-8')
# 画图
draw = ImageDraw.Draw(img_PIL)
# 画文字
draw.text(position,chinese,font=font,fill=fillColor)
# 颜色通道转换
img = cv2.cvtColor(np.asarray(img_PIL),cv2.COLOR_RGB2BGR)
return img
plt.imshow(paint_chinese_opencv(img,'中文',(100,100),(255,255,0)))

小结
cv2.line()画直线,cv2.circle()画圆,cv2.rectangle()画矩形,cv2.ellipse()画椭圆,cv2.polylines()画多边形,cv2.putText()添加文字。- 画多条直线时,
cv2.polylines()要比cv2.line()高效很多。 - 要在图像中打上中文,可以用PIL库结合OpenCV实现。
图像间数学运算
- 图片间的数学运算,如相加、按位运算等
- OpenCV函数:
cv2.add(),cv2.addWeighted(),cv2.bitwise_and()
图片相加
要叠加两张图片,可以用cv2.add()函数,相加两幅图片的形状(高度/宽度/通道数)必须相同。numpy中可以直接用res = img + img1相加,但这两者的结果并不相同:
x = np.uint8([250])
y = np.uint8([10])
print(cv2.add(x, y)) # 250+10 = 260 => 255
print(x + y) # 250+10 = 260 % 256 = 4
[[255]]
[4]
如果是二值化图片(只有0和255两种值),两者结果是一样的(用numpy的方式更简便一些)。
图像混合
图像混合cv2.addWeighted()也是一种图片相加的操作,只不过两幅图片的权重不一样,γ相当于一个修正值:
d s t = α × i m g 1 + β × i m g 2 + γ dst = \alpha\times img1+\beta\times img2 + \gamma dst=α×img1+β×img2+γ
img1 = cv2.imread('lena.jpg')
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
img2 = cv2.imread('cat.png')
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2RGB)
img2 = cv2.resize(img2, (350, 350))
# 两张图片相加
res = cv2.addWeighted(img1, 0.6, img2, 0.4, 0)
plt.imshow(res)
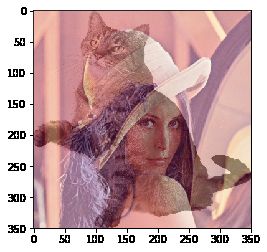
按位操作
按位操作包括按位与/或/非/异或操作,有什么用途呢?
如果将两幅图片直接相加会改变图片的颜色,如果用图像混合,则会改变图片的透明度,所以我们需要用按位操作。首先来了解一下
掩膜(mask)的概念:掩膜是用一副二值化图片对另外一幅图片进行局部的遮挡
img1 = cv2.imread('lena.jpg')
img2 = cv2.imread('logo.jpg')
img2 = cv2.resize(img2, (350, 350))
# 把logo放在左上角,所以我们只关心这一块区域
rows, cols = img2.shape[:2]
roi = img1[:rows, :cols]
# 创建掩膜
img2gray = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
ret, mask = cv2.threshold(img2gray, 10, 255, cv2.THRESH_BINARY)
mask_inv = cv2.bitwise_not(mask)
# 保留除logo外的背景
img1_bg = cv2.bitwise_and(roi, roi, mask=mask_inv)
dst = cv2.add(img1_bg, img2) # 进行融合
img1[:rows, :cols] = dst # 融合后放在原图上
plt.imshow(dst)

小结
cv2.add()用来叠加两幅图片,cv2.addWeighted()也是叠加两幅图片,但两幅图片的权重不一样。cv2.bitwise_and(),cv2.bitwise_not(),cv2.bitwise_or(),cv2.bitwise_xor()分别执行按位与/或/非/异或运算。掩膜就是用来对图片进行全局或局部的遮挡。
平滑图像
- 模糊/平滑图片来消除图片噪声
- OpenCV函数:
cv2.blur(),cv2.GaussianBlur(),cv2.medianBlur(),cv2.bilateralFilter()
滤波与模糊
关于滤波和模糊:
- 它们都属于卷积,不同滤波方法之间只是卷积核不同(对线性滤波而言)
- 低通滤波器是模糊,高通滤波器是锐化
低通滤波器就是允许低频信号通过,在图像中边缘和噪点都相当于高频部分,所以低通滤波器用于去除噪点、平滑和模糊图像。高通滤波器则反之,用来增强图像边缘,进行锐化处理。
常见噪声有椒盐噪声和高斯噪声,椒盐噪声可以理解为斑点,随机出现在图像中的黑点或白点;高斯噪声可以理解为拍摄图片时由于光照等原因造成的噪声。
均值滤波
均值滤波是一种最简单的滤波处理,它取的是卷积核区域内元素的均值,用cv2.blur()实现,如3×3的卷积核:
k e r n e l = 1 9 [ 1 1 1 1 1 1 1 1 1 ] kernel = \frac{1}{9}\left[ \begin{matrix} 1 & 1 & 1 \newline 1 & 1 & 1 \newline 1 & 1 & 1 \end{matrix} \right] kernel=91[111111111]
img = cv2.imread('lena.jpg')
blur = cv2.blur(img, (3, 3)) # 均值模糊
img = cv2.imread('lena.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
blur = cv2.blur(img, (9, 9)) # 均值模糊
plt.imshow(blur)
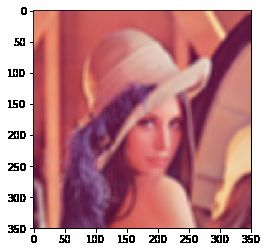
方框滤波
方框滤波跟均值滤波很像,如3×3的滤波核如下:
k = a [ 1 1 1 1 1 1 1 1 1 ] k = a\left[ \begin{matrix} 1 & 1 & 1 \newline 1 & 1 & 1 \newline 1 & 1 & 1 \end{matrix} \right] k=a[111111111]
用cv2.boxFilter()函数实现,当可选参数normalize为True的时候,方框滤波就是均值滤波,上式中的a就等于1/9;normalize为False的时候,a=1,相当于求区域内的像素和。
# 前面的均值滤波也可以用方框滤波实现:normalize=True
blur = cv2.boxFilter(img, -1, (9, 9), normalize=True)
plt.imshow(blur)
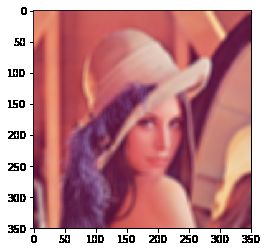
高斯滤波
前面两种滤波方式,卷积核内的每个值都一样,也就是说图像区域中每个像素的权重也就一样。高斯滤波的卷积核权重并不相同:中间像素点权重最高,越远离中心的像素权重越小。
显然这种处理元素间权值的方式更加合理一些。图像是2维的,所以我们需要使用2维的高斯函数,比如OpenCV中默认的3×3的高斯卷积核:
k = [ 0.0625 0.125 0.0625 0.125 0.25 0.125 0.0625 0.125 0.0625 ] k = \left[ \begin{matrix} 0.0625 & 0.125 & 0.0625 \newline 0.125 & 0.25 & 0.125 \newline 0.0625 & 0.125 & 0.0625 \end{matrix} \right] k=[0.06250.1250.06250.1250.250.1250.06250.1250.0625]
OpenCV中对应函数为cv2.GaussianBlur(src,ksize,sigmaX):
参数3 σx值越大,模糊效果越明显。高斯滤波相比均值滤波效率要慢,但可以有效消除高斯噪声,能保留更多的图像细节,所以经常被称为最有用的滤波器。均值滤波与高斯滤波的对比结果如下(均值滤波丢失的细节更多)
# 均值滤波vs高斯滤波
gaussian = cv2.GaussianBlur(img, (9, 9), 1) # 高斯滤波
plt.imshow(gaussian)

中值滤波
中值又叫中位数,是所有数排序后取中间的值。中值滤波就是用区域内的中值来代替本像素值,所以那种孤立的斑点,如0或255很容易消除掉,适用于去除椒盐噪声和斑点噪声。中值是一种非线性操作,效率相比前面几种线性滤波要慢。
median = cv2.medianBlur(img, 9) # 中值滤波
plt.imshow(median)
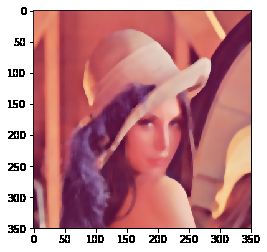
双边滤波
模糊操作基本都会损失掉图像细节信息,尤其前面介绍的线性滤波器,图像的边缘信息很难保留下来。然而,边缘(edge)信息是图像中很重要的一个特征,所以这才有了双边滤波。用cv2.bilateralFilter()函数实现:可以看到,双边滤波明显保留了更多边缘信息。
blur = cv2.bilateralFilter(img, 9, 75, 75) # 双边滤波
plt.imshow(blur)
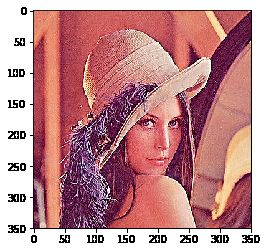
图像锐化
kernel = np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]], np.float32) #定义一个核
dst = cv2.filter2D(img, -1, kernel=kernel)
plt.imshow(dst)

边缘检测
Canny J . A Computational Approach To Edge Detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1986, PAMI-8(6):679-698.
- Canny边缘检测的简单概念
- OpenCV函数:
cv2.Canny()
Canny边缘检测方法常被誉为边缘检测的最优方法:
cv2.Canny()进行边缘检测,参数2、3表示最低、高阈值,下面来解释下具体原理。
经验之谈:之前我们用低通滤波的方式模糊了图片,那反过来,想得到物体的边缘,就需要用到高通滤波。
Canny边缘检测
Canny边缘提取的具体步骤如下:
- 使用5×5高斯滤波消除噪声:
边缘检测本身属于锐化操作,对噪点比较敏感,所以需要进行平滑处理。
K = 1 256 [ 1 4 6 4 1 4 16 24 16 4 6 24 36 24 6 4 16 24 16 4 1 4 6 4 1 ] K=\frac{1}{256}\left[ \begin{matrix} 1 & 4 & 6 & 4 & 1 \newline 4 & 16 & 24 & 16 & 4 \newline 6 & 24 & 36 & 24 & 6 \newline 4 & 16 & 24 & 16 & 4 \newline 1 & 4 & 6 & 4 & 1 \end{matrix} \right] K=2561[1464141624164624362464162416414641]
2. 计算图像梯度的方向:
首先使用Sobel算子计算两个方向上的梯度$ G_x 和 和 和 G_y $,然后算出梯度的方向:
θ = arctan ( G y G x ) \theta=\arctan(\frac{G_y}{G_x}) θ=arctan(GxGy)
保留这四个方向的梯度:0°/45°/90°/135°,有什么用呢?我们接着看。
- 取局部极大值:
梯度其实已经表示了轮廓,但为了进一步筛选,可以在上面的四个角度方向上再取局部极大值
- 滞后阈值:
经过前面三步,就只剩下0和可能的边缘梯度值了,为了最终确定下来,需要设定高低阈值:
- 像素点的值大于最高阈值,那肯定是边缘
- 同理像素值小于最低阈值,那肯定不是边缘
- 像素值介于两者之间,如果与高于最高阈值的点连接,也算边缘,所以上图中C算,B不算
Canny推荐的高低阈值比在2:1到3:1之间。
img = cv2.imread('lena.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
edges = cv2.Canny(img, 30, 70) # canny边缘检测
plt.imshow(edges)

先阈值分割后检测
其实很多情况下,阈值分割后再检测边缘,效果会更好。
_, thresh = cv2.threshold(img, 124, 255, cv2.THRESH_BINARY)
edges = cv2.Canny(thresh, 30, 70)
plt.imshow(edges)

小结
- Canny是用的最多的边缘检测算法,用
cv2.Canny()实现。
腐蚀与膨胀
- 了解形态学操作的概念
- 学习膨胀、腐蚀、开运算和闭运算等形态学操作
- OpenCV函数:
cv2.erode(),cv2.dilate(),cv2.morphologyEx()
啥叫形态学操作
形态学操作其实就是改变物体的形状,比如腐蚀就是"变瘦",膨胀就是"变胖"。
经验之谈:形态学操作一般作用于二值化图,来连接相邻的元素或分离成独立的元素。腐蚀和膨胀是针对图片中的白色部分!
腐蚀
腐蚀的效果是把图片"变瘦",其原理是在原图的小区域内取局部最小值。因为是二值化图,只有0和255,所以小区域内有一个是0该像素点就为0。
这样原图中边缘地方就会变成0,达到了瘦身目的
OpenCV中用cv2.erode()函数进行腐蚀,只需要指定核的大小就行:
img = cv2.imread('lena.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
kernel = np.ones((5, 5), np.uint8)
erosion = cv2.erode(img, kernel) # 腐蚀
plt.imshow(erosion)

这个核也叫结构元素,因为形态学操作其实也是应用卷积来实现的。结构元素可以是矩形/椭圆/十字形,可以用
cv2.getStructuringElement()来生成不同形状的结构元素,比如:
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5)) # 矩形结构
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5)) # 椭圆结构
kernel = cv2.getStructuringElement(cv2.MORPH_CROSS, (5, 5)) # 十字形结构
膨胀
膨胀与腐蚀相反,取的是局部最大值,效果是把图片"变胖":
dilation = cv2.dilate(img, kernel) # 膨胀
plt.imshow(dilation)

开/闭运算
先腐蚀后膨胀叫开运算(因为先腐蚀会分开物体,这样容易记住),其作用是:分离物体,消除小区域。这类形态学操作用cv2.morphologyEx()函数实现:
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5)) # 定义结构元素
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel) # 开运算
plt.imshow(opening)
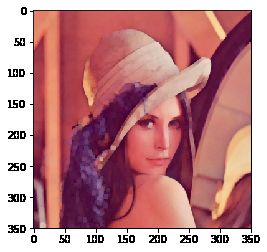
闭运算则相反:先膨胀后腐蚀(先膨胀会使白色的部分扩张,以至于消除/"闭合"物体里面的小黑洞,所以叫闭运算)
closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel) # 闭运算
plt.imshow(closing)

经验之谈:很多人对开闭运算的作用不是很清楚,但看上图↑,不用怕:如果我们的目标物体外面有很多无关的小区域,就用开运算去除掉;如果物体内部有很多小黑洞,就用闭运算填充掉。
使用OpenCV摄像头与加载视频
学习打开摄像头捕获照片、播放本地视频、录制视频等。
- 打开摄像头并捕获照片
- 播放本地视频,录制视频
- OpenCV函数:
cv2.VideoCapture(),cv2.VideoWriter()
import IPython
# 加载视频
IPython.display.Video('demo_video.mp4')
video element.
打开摄像头
要使用摄像头,需要使用cv2.VideoCapture(0)创建VideoCapture对象,参数0指的是摄像头的编号,如果你电脑上有两个摄像头的话,访问第2个摄像头就可以传入1,依此类推。
# 打开摄像头并灰度化显示
import cv2
capture = cv2.VideoCapture(0)
while(True):
# 获取一帧
ret, frame = capture.read()
# 将这帧转换为灰度图
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', gray)
if cv2.waitKey(1) == ord('q'):
break
capture.read()函数返回的第1个参数ret(return value缩写)是一个布尔值,表示当前这一帧是否获取正确。cv2.cvtColor()用来转换颜色,这里将彩色图转成灰度图。
另外,通过cap.get(propId)可以获取摄像头的一些属性,比如捕获的分辨率,亮度和对比度等。propId是从0~18的数字,代表不同的属性,完整的属性列表可以参考:VideoCaptureProperties。也可以使用cap.set(propId,value)来修改属性值。比如说,我们在while之前添加下面的代码:
# 获取捕获的分辨率
# propId可以直接写数字,也可以用OpenCV的符号表示
width, height = capture.get(3), capture.get(4)
print(width, height)
# 以原分辨率的一倍来捕获
capture.set(cv2.CAP_PROP_FRAME_WIDTH, width * 2)
capture.set(cv2.CAP_PROP_FRAME_HEIGHT, height * 2)
经验之谈:某些摄像头设定分辨率等参数时会无效,因为它有固定的分辨率大小支持,一般可在摄像头的资料页中找到。
播放本地视频
跟打开摄像头一样,如果把摄像头的编号换成视频的路径就可以播放本地视频了。回想一下cv2.waitKey(),它的参数表示暂停时间,所以这个值越大,视频播放速度越慢,反之,播放速度越快,通常设置为25或30。
# 播放本地视频
capture = cv2.VideoCapture('demo_video.mp4')
while(capture.isOpened()):
ret, frame = capture.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', gray)
if cv2.waitKey(30) == ord('q'):
break
录制视频
之前我们保存图片用的是cv2.imwrite(),要保存视频,我们需要创建一个VideoWriter的对象,需要给它传入四个参数:
- 输出的文件名,如’output.avi’
- 编码方式FourCC码
- 帧率FPS
- 要保存的分辨率大小
FourCC是用来指定视频编码方式的四字节码,所有的编码可参考Video Codecs。如MJPG编码可以这样写: cv2.VideoWriter_fourcc(*'MJPG')或cv2.VideoWriter_fourcc('M','J','P','G')
capture = cv2.VideoCapture(0)
# 定义编码方式并创建VideoWriter对象
fourcc = cv2.VideoWriter_fourcc(*'MJPG')
outfile = cv2.VideoWriter('output.avi', fourcc, 25., (640, 480))
while(capture.isOpened()):
ret, frame = capture.read()
if ret:
outfile.write(frame) # 写入文件
cv2.imshow('frame', frame)
if cv2.waitKey(1) == ord('q'):
break
else:
break
小结
- 使用
cv2.VideoCapture()创建视频对象,然后在循环中一帧帧显示图像。参数传入数字时,代表打开摄像头,传入本地视频路径时,表示播放本地视频。 cap.get(propId)获取视频属性,cap.set(propId,value)设置视频属性。cv2.VideoWriter()创建视频写入对象,用来录制/保存视频。
3. 图像分类任务概念导入
计算机视觉中的图像分类任务
图像分类的基本任务

对人类来说,识别猫和狗是件非常容易的事。但对计算机来说,即使是一个精通编程的高手,也很难轻松写出具有通用性的程序(比如:假设程序认为体型大的是狗,体型小的是猫,但由于拍摄角度不同,可能一张图片上猫占据的像素比狗还多)。
在早期的图像分类任务中,通常是先人工提取图像特征,再用机器学习算法对这些特征进行分类,分类的结果强依赖于特征提取方法,往往只有经验丰富的研究者才能完成。

在这种背景下,基于神经网络的特征提取方法应运而生。Yann LeCun是最早将卷积神经网络应用到图像识别领域的,其主要逻辑是使用卷积神经网络提取图像特征,并对图像所属类别进行预测,通过训练数据不断调整网络参数,最终形成一套能自动提取图像特征并对这些特征进行分类的网络。

人工智能与深度学习
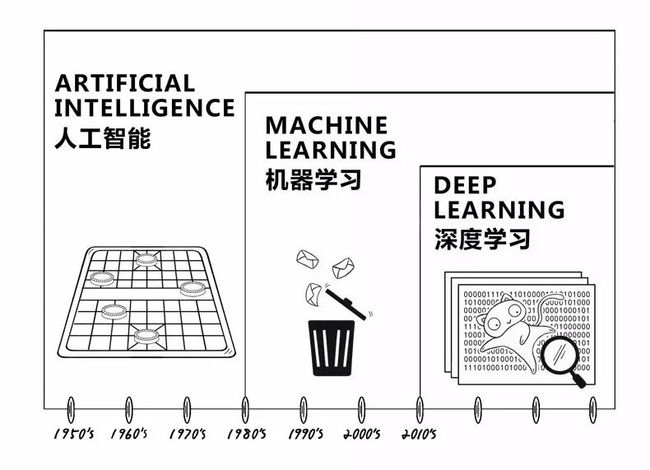
图源:公众号tuputech

图源《如何创造可信的AI》
计算机视觉的子任务

- Image Classification: 图像分类,用于识别图像中物体的类别(如:bottle、cup、cube)。
- Object Localization: 目标检测,用于检测图像中每个物体的类别,并准确标出它们的位置。
- Semantic Segmentation: 图像语义分割,用于标出图像中每个像素点所属的类别,属于同一类别的像素点用一个颜色标识。
- Instance Segmentation: 实例分割,值得注意的是,目标检测任务只需要标注出物体位置,实例分割任务不仅要标注出物体位置,还需要标注出物体的外形轮廓。
图像分类问题的经典数据集
MNIST手写数字识别
MNIST是一个手写体数字的图片数据集,该数据集来由美国国家标准与技术研究所(National Institute of Standards and Technology (NIST))发起整理,一共统计了来自250个不同的人手写数字图片,其中50%是高中生,50%来自人口普查局的工作人员。该数据集的收集目的是希望通过算法,实现对手写数字的识别。

数据集链接
%matplotlib inline
import numpy as np
import cv2
import matplotlib.pyplot as plt
import paddle
print('视觉相关数据集:', paddle.vision.datasets.__all__)
视觉相关数据集: ['DatasetFolder', 'ImageFolder', 'MNIST', 'FashionMNIST', 'Flowers', 'Cifar10', 'Cifar100', 'VOC2012']
from paddle.vision.datasets import MNIST
mnist = MNIST(mode='test')
for i in range(len(mnist)):
if i == 0:
sample = mnist[i]
print(sample[0].size, sample[1])
Cache file /home/aistudio/.cache/paddle/dataset/mnist/t10k-images-idx3-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/mnist/t10k-images-idx3-ubyte.gz
Begin to download
Download finished
Cache file /home/aistudio/.cache/paddle/dataset/mnist/t10k-labels-idx1-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/mnist/t10k-labels-idx1-ubyte.gz
Begin to download
..
Download finished
(28, 28) [7]
# 查看测试集第一个数字
plt.imshow(mnist[0][0])
print('手写数字是:', mnist[0][1])
手写数字是: [7]
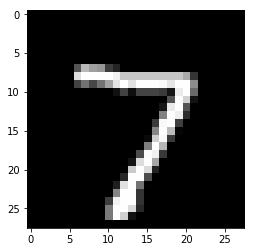
# 查看测试集第11个数字
plt.imshow(mnist[10][0])
print('手写数字是:', mnist[10][1])
手写数字是: [0]

Cifar数据集
CIFAR-10
CIFAR-10数据集由10个类的60000个32x32彩色图像组成,每个类有6000个图像。有50000个训练图像和10000个测试图像。
数据集分为五个训练批次和一个测试批次,每个批次有10000个图像。测试批次包含来自每个类别的恰好1000个随机选择的图像。训练批次以随机顺序包含剩余图像,但一些训练批次可能包含来自一个类别的图像比另一个更多。总体来说,五个训练集之和包含来自每个类的正好5000张图像。
以下是数据集中的类,以及来自每个类的10个随机图像:

这些类完全相互排斥。汽车和卡车之间没有重叠。“汽车”包括轿车,SUV,这类东西。“卡车”只包括大卡车。都不包括皮卡车。
CIFAR-10 python版本
CIFAR-100
CIFAR-100数据集就像CIFAR-10,除了它有100个类,每个类包含600个图像。,每类各有500个训练图像和100个测试图像。CIFAR-100中的100个类被分成20个超类。每个图像都带有一个“精细”标签(它所属的类)和一个“粗糙”标签(它所属的超类)
以下是CIFAR-100中的类别列表:
| 超类 | 类别 |
|---|---|
| 水生哺乳动物 | 海狸,海豚,水獭,海豹,鲸鱼 |
| 鱼 | 水族馆的鱼,比目鱼,射线,鲨鱼,鳟鱼 |
| 花卉 | 兰花,罂粟花,玫瑰,向日葵,郁金香 |
| 食品容器 | 瓶子,碗,罐子,杯子,盘子 |
| 水果和蔬菜 | 苹果,蘑菇,橘子,梨,甜椒 |
| 家用电器 | 时钟,电脑键盘,台灯,电话机,电视机 |
| 家用家具 | 床,椅子,沙发,桌子,衣柜 |
| 昆虫 | 蜜蜂,甲虫,蝴蝶,毛虫,蟑螂 |
| 大型食肉动物 | 熊,豹,狮子,老虎,狼 |
| 大型人造户外用品 | 桥,城堡,房子,路,摩天大楼 |
| 大自然的户外场景 | 云,森林,山,平原,海 |
| 大杂食动物和食草动物 | 骆驼,牛,黑猩猩,大象,袋鼠 |
| 中型哺乳动物 | 狐狸,豪猪,负鼠,浣熊,臭鼬 |
| 非昆虫无脊椎动物 | 螃蟹,龙虾,蜗牛,蜘蛛,蠕虫 |
| 人 | 宝贝,男孩,女孩,男人,女人 |
| 爬行动物 | 鳄鱼,恐龙,蜥蜴,蛇,乌龟 |
| 小型哺乳动物 | 仓鼠,老鼠,兔子,母老虎,松鼠 |
| 树木 | 枫树,橡树,棕榈,松树,柳树 |
| 车辆1 | 自行车,公共汽车,摩托车,皮卡车,火车 |
| 车辆2 | 割草机,火箭,有轨电车,坦克,拖拉机 |
CIFAR-100 python版本
from paddle.vision.datasets import Cifar10
cifar10 = Cifar10(mode='test')
# 查看测试集第2张图
plt.imshow(cifar10[1][0])
print('图片类别编码是:', cifar10[1][1])
Cache file /home/aistudio/.cache/paddle/dataset/cifar/cifar-10-python.tar.gz not found, downloading https://dataset.bj.bcebos.com/cifar/cifar-10-python.tar.gz
Begin to download
Download finished
图片类别编码是: 8

ImageNet数据集
- ImageNet数据集是一个计算机视觉数据集,是由斯坦福大学的李飞飞教授带领创建。该数据集包合 14,197,122张图片和21,841个Synset索引。Synset是WordNet层次结构中的一个节点,它又是一组同义词集合。ImageNet数据集一直是评估图像分类算法性能的基准。
- ImageNet 数据集是为了促进计算机图像识别技术的发展而设立的一个大型图像数据集。2016 年ImageNet 数据集中已经超过干万张图片,每一张图片都被手工标定好类别。ImageNet 数据集中的图片涵盖了大部分生活中会看到的图片类别。ImageNet最初是拥有超过100万张图像的数据集。如图下图所示,它包含了各种各样的图像,并且每张图像都被关联了标签(类别名)。每年都会举办使用这个巨大数据集的ILSVRC图像识别大赛。
http://image-net.org/download-imageurls

PaddleClas图像分类开发套件
飞桨产品全景
4. PaddleClas数据增强代码解析与实战
# 创建一副图片
img = cv2.imread('lena.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
class RandFlipImage(object):
""" random flip image 随机翻转图片
flip_code:
1: Flipped Horizontally 水平翻转
0: Flipped Vertically 上下翻转
-1: Flipped Horizontally & Vertically 水平、上下翻转
"""
def __init__(self, flip_code=1):
# 设置一个翻转参数,1、0或-1
assert flip_code in [-1, 0, 1
], "flip_code should be a value in [-1, 0, 1]"
self.flip_code = flip_code
def __call__(self, img):
# 随机生成0或1(即是否翻转)
if random.randint(0, 1) == 1:
return cv2.flip(img, self.flip_code)
else:
return img
# 初始化实例,默认随机水平翻转
flip = RandFlipImage()
plt.imshow(flip(img))
# 默认随机上下翻转
flip = RandFlipImage(0)
plt.imshow(flip(img))

# 默认既水平翻转又上下翻转
flip = RandFlipImage(-1)
plt.imshow(flip(img))

class RandCropImage(object):
""" random crop image """
""" 随机裁剪图片 """
def __init__(self, size, scale=None, ratio=None, interpolation=-1):
self.interpolation = interpolation if interpolation >= 0 else None
if type(size) is int:
self.size = (size, size) # (h, w)
else:
self.size = size
self.scale = [0.08, 1.0] if scale is None else scale
self.ratio = [3. / 4., 4. / 3.] if ratio is None else ratio
def __call__(self, img):
size = self.size
scale = self.scale
ratio = self.ratio
aspect_ratio = math.sqrt(random.uniform(*ratio))
w = 1. * aspect_ratio
h = 1. / aspect_ratio
img_h, img_w = img.shape[:2]
bound = min((float(img_w) / img_h) / (w**2),
(float(img_h) / img_w) / (h**2))
scale_max = min(scale[1], bound)
scale_min = min(scale[0], bound)
target_area = img_w * img_h * random.uniform(scale_min, scale_max)
target_size = math.sqrt(target_area)
w = int(target_size * w)
h = int(target_size * h)
i = random.randint(0, img_w - w)
j = random.randint(0, img_h - h)
img = img[j:j + h, i:i + w, :]
if self.interpolation is None:
return cv2.resize(img, size)
else:
return cv2.resize(img, size, interpolation=self.interpolation)
crop = RandCropImage(350)
plt.imshow(crop(img))

class RandomErasing(object):
def __init__(self, EPSILON=0.5, sl=0.02, sh=0.4, r1=0.3,
mean=[0., 0., 0.]):
self.EPSILON = EPSILON
self.mean = mean
self.sl = sl
self.sh = sh
self.r1 = r1
def __call__(self, img):
if random.uniform(0, 1) > self.EPSILON:
return img
for attempt in range(100):
area = img.shape[1] * img.shape[2]
target_area = random.uniform(self.sl, self.sh) * area
aspect_ratio = random.uniform(self.r1, 1 / self.r1)
h = int(round(math.sqrt(target_area * aspect_ratio)))
w = int(round(math.sqrt(target_area / aspect_ratio)))
if w < img.shape[2] and h < img.shape[1]:
x1 = random.randint(0, img.shape[1] - h)
y1 = random.randint(0, img.shape[2] - w)
if img.shape[0] == 3:
img[0, x1:x1 + h, y1:y1 + w] = self.mean[0]
img[1, x1:x1 + h, y1:y1 + w] = self.mean[1]
img[2, x1:x1 + h, y1:y1 + w] = self.mean[2]
else:
img[0, x1:x1 + h, y1:y1 + w] = self.mean[1]
return img
return img
erase = RandomErasing()
y1 + w] = self.mean[0]
img[1, x1:x1 + h, y1:y1 + w] = self.mean[1]
img[2, x1:x1 + h, y1:y1 + w] = self.mean[2]
else:
img[0, x1:x1 + h, y1:y1 + w] = self.mean[1]
return img
return img
erase = RandomErasing()
plt.imshow(erase(img))
5. 参考资料
- 面向初学者的OpenCV-Python教程
- OpenCV学习—OpenCV图像处理基本操作
- OpenCV 4计算机视觉项目实战(原书第2版)