深度学习分布式训练DP、DDP通信原理
日常在「九点澡堂子」裸泳,欢迎关注 ~
前言
上周末开始写这篇文章,一度以为自己快要写完了。
写着写着发现参考资料有点争议,下文讲到的PS架构的实现在网络上说法不一。
鉴于是一个快要被淘汰的方案, Parrots里直接省略了该实现,所以堂妹对它背后的实现确实不太清楚。
本着传播知识的良知,不敢造次,查了很多资料,发现众说纷纭。
涉及上层模型的搭建场景,众所周知(假装),堂妹接触底层多一些,
于是乎,堂妹拉着贵司的研究员们一起探讨这个问题,毕竟他们模型搭的多。
凌晨2点,大佬依然在线…
大概是现代人的标配吧,害。
有争议的那个实现目前确实用的不多,大部分人都是「会用就行」,借此机会,就把它搞清楚吧。
在此悄咪咪感谢一起探讨这个方案在实际模型中如何应用的盆友们,solute
这次的话题是基于模型加速,目前常见的加速⏩方式如图所示,
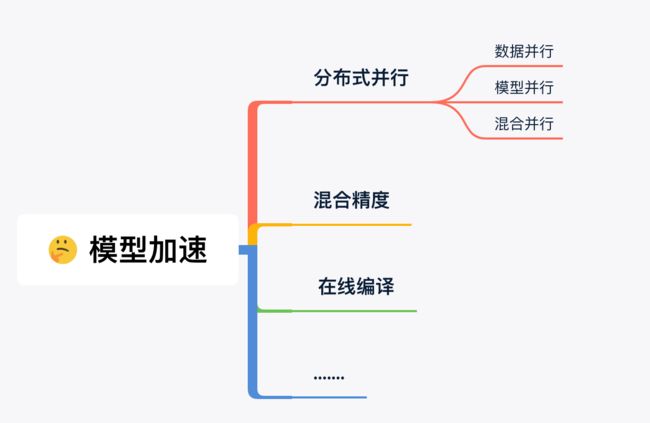
而在上述的各种方法里,「数据并行」是最最常用的方式之一,它和「模型并行」都属于分布式训练,偶尔还会看到两者的混用。
本次重点分享一下数据并行背后的原理。
分布式训练
分布式、高并发、多线程等关键词经常出现在各大公众号的头条文章标题,别以为它们只是传统计算机的常聊话题,在深度学习领域,一旦数据量/模型规模上去了,一张V100早已满足不了诉求。
DDL在逼近,哪能等得了你龟速训练,这时单机多卡、多机多卡的分布式训练应运而生。
需求是第一生产力。
在最初的模型生产方式上,单机单卡,即信息都在一台机器上,自给自足,没有太多和外界沟通的诉求。
一旦卡数/机器增加(一般的 ,我们在一台机器上配备8张卡),就涉及了「分工合作」加快进展,这就用到了分发技术,我们称之为“分布式训练”。
数据并行
当任务数据的量非常大,但是模型本身规模不大(显存可以放得下)的时候,可以把数据按照一定的规则分配到不同的机器/卡上分工合作。
同时,每个机器/卡都加载同一个模型,各自单独地根据输入数据计算梯度,并对梯度按照一定规则进行通信,这即梯度的汇总更新。
接下来就是对模型参数的更新,确保每个iter结束的时候,所有卡上的参数一致。当然,这也要求初始化的时候每张卡的参数一致。
数据并行的目的,就是希望在同样的时间内:
-
更多的数据同时训练,加快了同等量级数据的训练完成时间,
-
相当于增大 batch_size,梯度下降方向会更贴合数据集整体的实际情况。
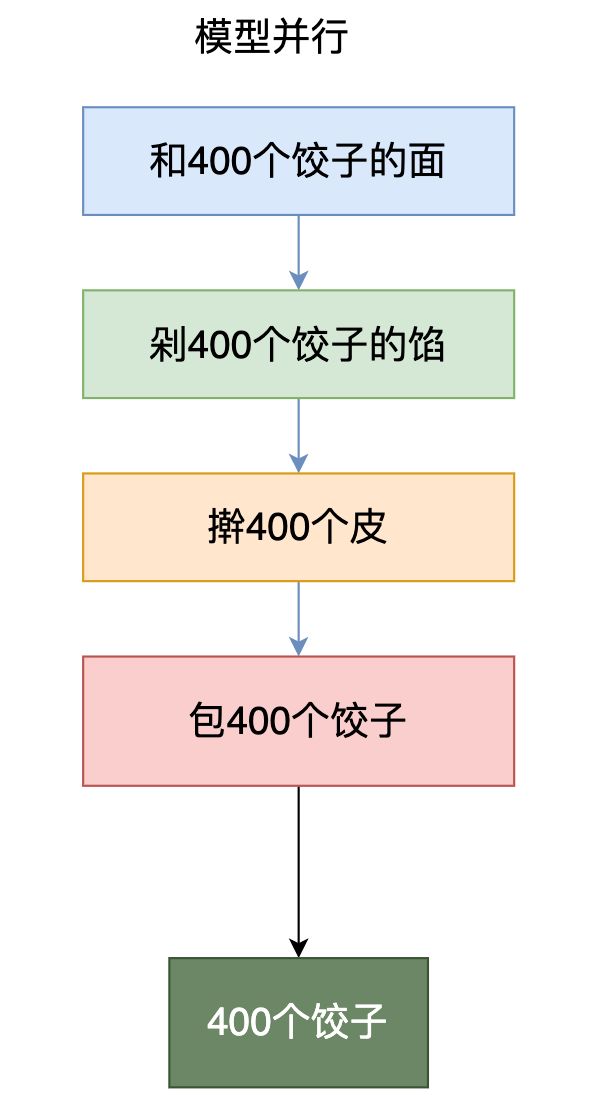
举个:
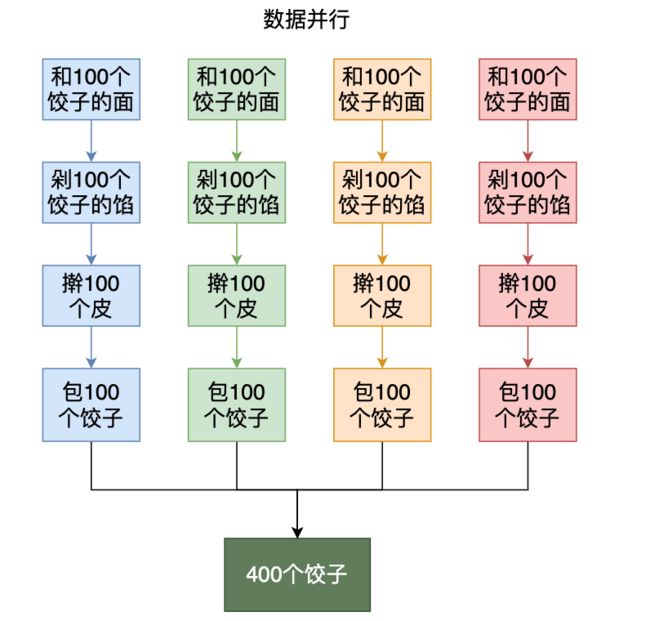
冬至的时候我们组织了个包饺子活动,包饺子可以分为四个步骤,和面,剁馅,擀皮,包饺子。如果我们的目标是包400只饺子,有四个人参与这个活动,如下图所示,每种颜色代表一个不同的人,「数据并行」就是如下这种分工方式:
用模型训练流程来表示,则如下图。
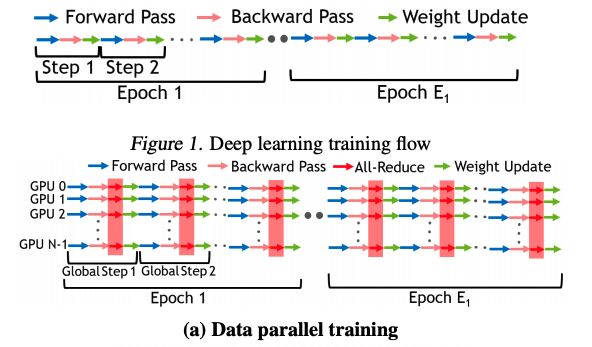
这其中,All-Reduce就是达成数据并行的重要操作,也是本文后文的重点。
模型并行
当模型本身非常大,显存已经放不下了,比如医疗场景下的3D数据非常耗显存的场景。
这个时候就要把模型拆分成多个模块,放到多个机器/卡中,然后每个卡计算这个模型中的一部分。
当一个模块的输入来自另一个模块的输出时,需要进行通信。
还是。
在模型并行中,完整的网络被切分到不同的设备。
如图,将数据喂给GPU1,数据在GPU1上进行它负责的网络部分的前向计算,将结果喂给GPU1和GPU2,进行第二部分网络的计算,然后继续进行前向计算…
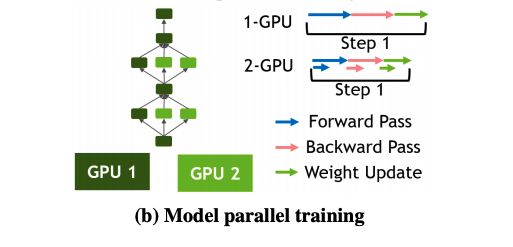
from[6]
可以看到,模型并行并不会涉及各张卡上的权重参数同步更新,而是会在各个GPU的模型之间流动,所谓流动,涉及不同卡之间,又是通信。
模型并行可以在模型的任意一层进行,如果在前面的层中用到了数据并行,则根据当前层的计算规则决定要不要将数据归并到一起。
参数的分发可以在线性的全连接层等无参数顺序要求的层进行,也可以在多任务模型中,将不同的任务执行代码块分发到不同的卡。
目前大多数的业务场景,仅使用数据并行就可以满足需求,随着模型复杂程度的 加深,模型并行的策略也逐渐被引入到日常业务中,但因为计算效率不高,应用较少。
深度学习里的通信原理
目前主流框架里都有分布式相关的接口,但并不是直接支持模型并行,还是以数据并行方式为主。
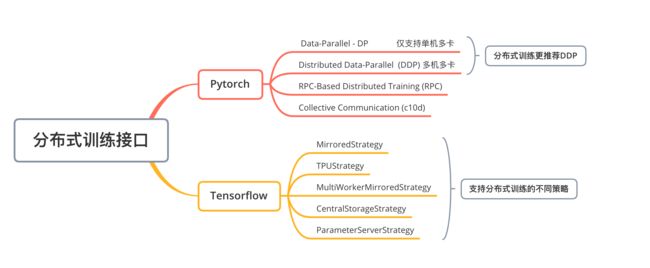
Tip:在DP和DDP之间,官方更推荐DDP。
DistributedDataParallel和 DataParallel之间的区别是:DistributedDataParallel 使用multiprocessing,即为每个GPU创建一个进程,而 DataParallel使用多线程。通过使用multiprocessing,每个GPU都有其专用的进程,这避免了Python解释器的GIL导致的性能开销。
当下,Pytorch以它的灵活性占据了AI框架的半壁江山,这里不展开介绍用法(网上都有),我们具体看一下背后的通信原理。
在Pytorch支持的分布式方式中:
- DP使用的是Parameter Server(PS)架构;
- DDP官网推荐,性能优于DP, All-reduce架构;
- apex是英伟达出品的工具库,封装了DistributedDataParallel,All-Reduce架构。
可见All-Reduce 架构是众望所归。
PS架构已经慢慢退出历史舞台,我们一般都用不到了,毕竟DDP挺香。
接下来,我们就看一下在深度学习中这两种架构的应用方式。
Allreduce
前面在介绍模型数据并行的过程中,我们提到了Allreduce操作,该操作是常用通信模式的一种。
在说Allreduce之前,先看下reduce。
reduce称为规约运算,是一系列运算操作的统称,细分来说包括SUM、MIN、MAX、PROD、LOR等。
reduce意为减少/精简,因为其操作在每个进程上获取一个输入元素数组,通过执行操作后,将得到精简的更少的元素。例如下面的Reduce sum:
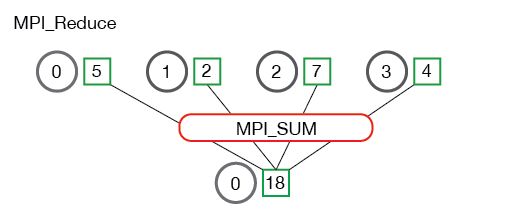
多值Reduce sum:
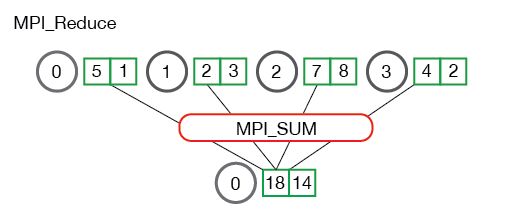
All reduce则是在所有的节点进程上都应用同样的reduce操作。All reduce sum:
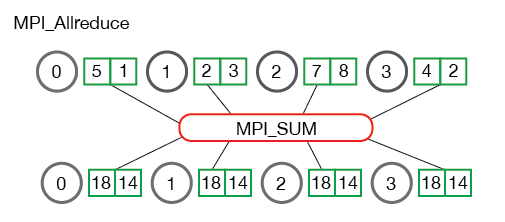
从图中可以看出,all reduce操作可通过单节点上reduce+broadcast操作完成。
用下图展示了四个进程的训练过程,每个进程有四个数据,进行一次Allreduce sum的结果:
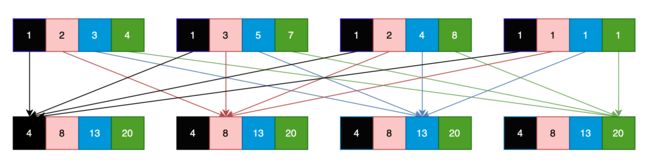
每个进程的1号数据是所有进程1号数据的和,同理2,3,4号数据也都是所有进程对应数据的和。
注意:所有进程在进行Allreduce之前,会进行一次同步,然后才开始做通信,其他通信执行也是类似,会默认做一次同步。
Allreduce方式也分多种,目前Parrots和Pytorch框架里用的都是Ring AllReduce 这种方式,而在进程间传输的就是模型参数的梯度。
在训练过程的表现可以如下图所示。
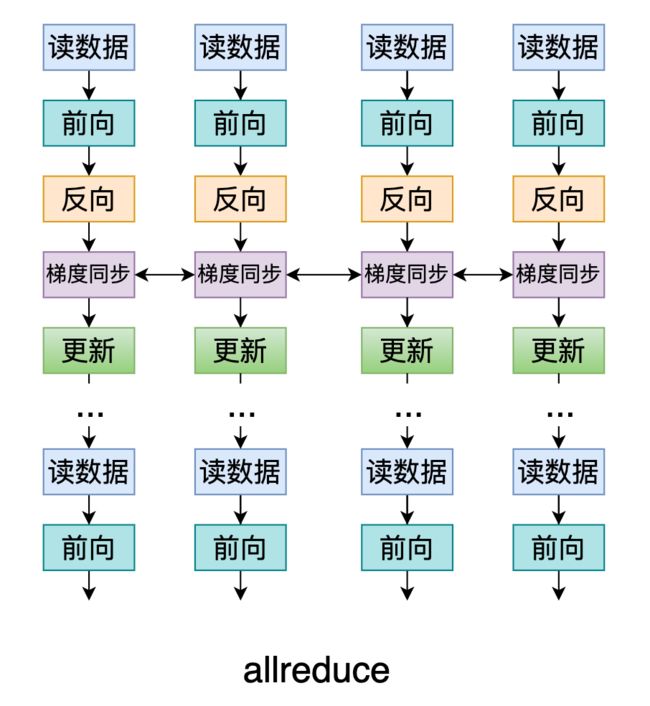
其中,这个闭环的Ring可以这张图表示。
多卡训练的每张卡对应一个worker,所有worker形成一个闭环,接受上家的梯度,再把累加好的梯度传给下家。
最终计算完成后更新整个环上worker的梯度(这样所有worker上的梯度就相等了),然后每张卡各自求梯度反向传播。
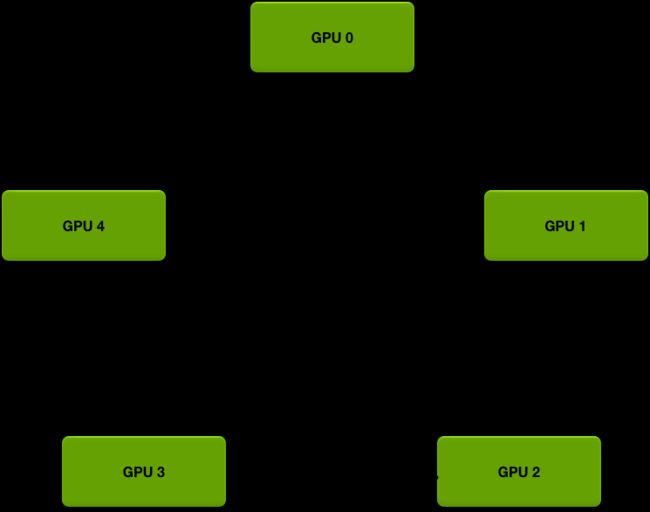
这个过程的具体分解可以参考[7],作者图解的非常直观详细,这里不当搬运工啦, 感兴趣的同学可以围观。
Parameter Server
PS架构则是定义了一个Parameter server和多个worker。
这里的server和worker就对应了我们训练用到的多卡,通常DP接口中输入参数的第一张卡被用作「server」,其他卡号就是对应的workers。
它在深度学习的应用如图所示:
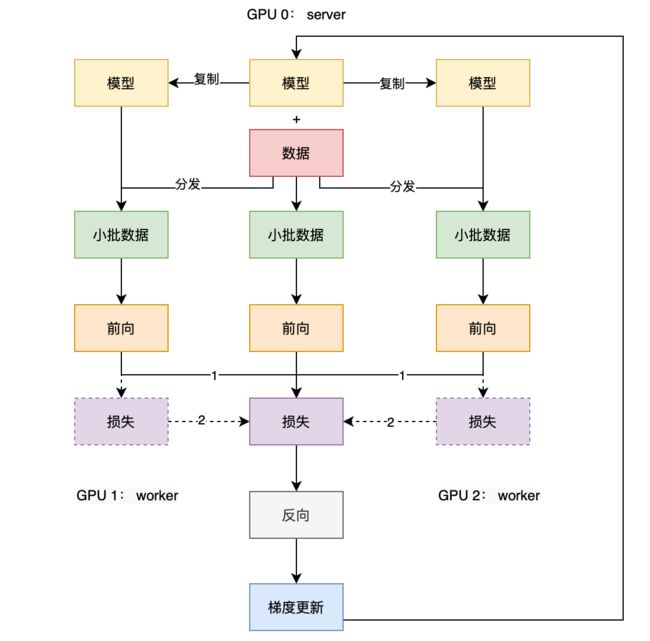
Server 负责:
-
将数据切成等量大小,从 device0分发到其他卡上并把模型复制到各个卡上
-
前向计算损失和反向计算梯度
-
更新参数
-
在下一个 iter开始的时候把参数更新到worker上
worker负责:
-
载入server分发过来的数据和模型
-
模型前向计算
PS架构在训练中的劣势显而易见:
-
通信的成本随着卡数的增加而增加;
-
server负担过重,容易显存爆炸。
也正因为第二点劣势,引发了网络上关于损失和反向的过程在哪做的争议。
图上标注1的地方就是Pytroch原生DP的实现方式,标注为2的方式就是研究员们因为server负担过重而重写的DP实现。
还有的设计是只把server用作梯度更新,进一步减轻负担,比如下面这个过程:
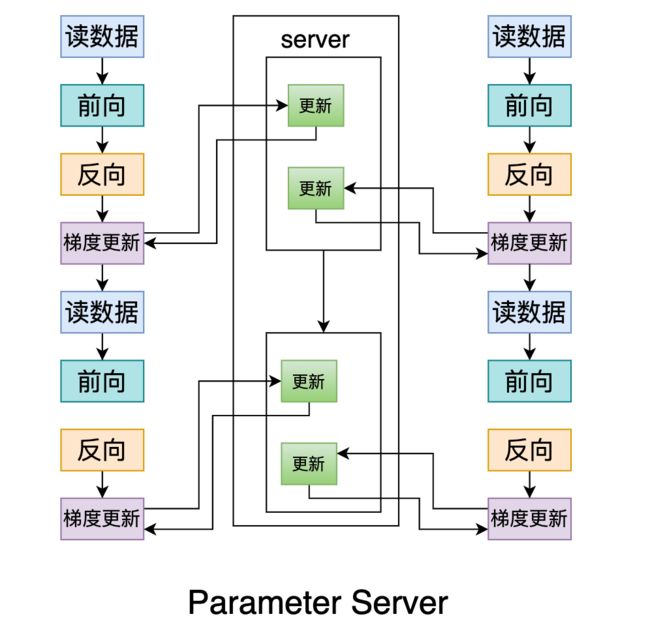
so,原理是固定的,实现是多样的,所谓争议就是大家理解/实现不一样而已~
以上就是主流框架用到的分布式训练相关原理啦。
[参考资料]
[1]https://tech.preferred.jp/en/blog/technologies-behind-distributed-deep-learning-allreduce/
[2]https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/
[3]https://zhuanlan.zhihu.com/p/68615246
[4]https://zhuanlan.zhihu.com/p/343951042
[5]https://zhuanlan.zhihu.com/p/276122469
[6]https://arxiv.org/pdf/1907.13257.pdf
[7]https://andrew.gibiansky.com/blog/machine-learning/baidu-allreduce/