【C语言进阶学习笔记】三、字符串函数+内存函数详解(2)
本篇文章继续上一篇文章【C语言进阶学习笔记】三、字符串函数详解(1)(爆肝吐血整理,建议收藏!!!)
来详细介绍和学习字符串操作函数及内存操作函数。
文章目录
-
- 九、strtok
- 十、strerror
- 字符分类函数∶
- 字符转换函数:
- 十一、memcpy
- 十二、memmove
- 十三、memcmp(简单了解)
- 十四、memset(简单了解)
九、strtok
char* strtok(char* str, const char* sep);
头文件:string.h
函数名:strtok
函数参数:
【参数1】str,要被分割的字符串起始位置
【参数2】sep,被用于分割的字符集合起始位置
函数返回类型:char* ,标记的位置
函数功能:字符串分割
应用举例:
#include
详解:
(1)sep参数是个字符串,定义了用作分隔符的字符集合
(2)第一个参数指定一个字符串,它包含了0个或者多个由sep字符串中一个或者多个分隔符分割的标记。
(3)strtok函数找到str中的下一个标记,并将其用\0结尾,返回一个指向这个标记的指针。
(注:strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容并且可修改。)
(4)strtok函数的第一个参数不为NULL),函数将找到str中第一个标记,strtok函数将保存它在字符串中的位置。
(5)strtok函数的第一个参数为NULL),函数将在同一个字符串中被保存的位置开始,查找下一个标记。
(6)如果字符串中不存在更多的标记,则返回NULL指针。
十、strerror
char* strerror(int errnum);
头文件:string.h
函数名:strerror
函数参数:errnum, int类型,表示错误码编号
函数返回类型:char* ,返回错误码对应的错误信息
函数功能:Get a system error message(strerror) or prints a user - supplied error
message(_strerror). 返回系统的错误信息(就是程序出错时,用这个函数返回错误的原因信息)
错误码-- - 所对应的错误信息。
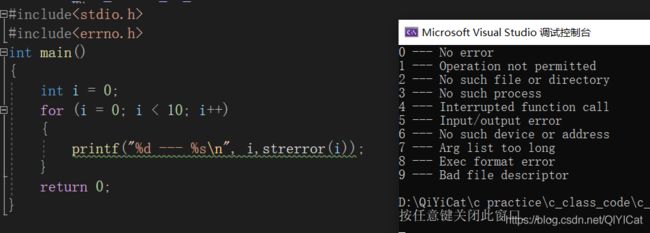
实际在使用的时候,错误码并非由我们来控制的,而是接收系统返回的错误信息
printf("%s\n", strerror(errno));
//errno是一个全局的错误码的变量
//当C语言的库函数在执行的过程中发生了错误,就会把对应的错误码,赋值到errno中
//errno需要引用头文件 errno.h
实际使用举例:
打开文件
#include
perror:直接打印错误信息 相当于两步操作:
1.首先将错误码转换成错误信息
2.打印错误信息(包含自定义信息)
使用:perror(“fopen”);
头文件:stdio.h 不需要主动传参errno
strerror:将错误码转换成错误信息,如果要打印还需要借助打印函数,比如printf等等
字符分类函数∶

字符转换函数:

举例:
大写字母转小写
#include 
内存函数
十一、memcpy
在之前的学习中,我们知道字符串拷贝可以使用strcpy函数,但是,当我们拷贝的数据不是字符串的时候,比如说int类型、double类型,还能使用strcpy函数吗?strcpy函数在拷贝的时候是以\0为字符串拷贝的结束标志,那么在拷贝其它类型数据的时候,拷贝该结束的时候不一定存在\0。所以使用strcpy函数肯定是行不通的。那怎么办呢?实际上我们可以使用memcpy函数-- - 内存拷贝函数,用来拷贝任意类型数据。
举例:
#include拷贝前:

拷贝后:

算法分析 + 图解:
memcpy函数可以拷贝任意类型的数据,为什么呢?首先我们思考一下,不同类型的函数参数实际在使用时所对应的内存状态是什么情况?比如说char类型的数据,如果要拷贝的话,是不是应该按照char类型的长度(1)为单位一个字节一个字节来拷贝。int类型的数据,如果要拷贝的话,是不是也应该按照int类型的长度(4)为单位4个字节4个字节来拷贝….如果是double类型呢,8个字节为单位?那结构体呢?
显然,如果我们按照这种方式思考就陷入的经验陷阱中,实际上,如果我们跳出来考虑,无论任何类型的数据,都是1个字节的整数倍(1倍到n倍,n为大于等于1的正整数),如果我们不考虑数据的类型,均按照一个字节一个字节来拷贝,最终不管什么类型的数据都可以成功被拷贝。(这时候,有的同学可能会考虑,既然可以一个字节一个字节来拷贝,为什么不按照1个bit一个bit来拷贝呢?回答:1.没必要,按照字节为单位拷贝已经可以满足我们的需求的,如果要按照更小的单位bit来拷贝只会导致程序执行的次数无端增加。2.操作不方便,以字节为单位拷贝可以通过将指针强制类型转换成char * 来操作,那么以bit为单位呢?该怎么操作,是不是很麻烦!)

函数介绍:memcpy void* memcpy(void* dest, const void* src, size_t count);
头文件:string.h
函数名:memcpy
函数参数:
参数1:destination, 类型:char* ,表示内存拷贝的目的位置
参数2:source,类型:char* ,表示内存拷贝的起始位置
参数3:count,类型:size_t,表示拷贝内存字节的个数
函数返回类型: void*, 实际上就是返回destination(目的地)的起始位置
函数功能:内存拷贝
重点内容:
(1)函数memcpy从source的位置开始向后复制num个字节的数据到destination的内存位置。
(2)这个函数在遇到’\0’的时候并不会停下来。
(3)如果source和destination有任何的重叠,复制的结果都是未定义的。
模拟实现memcpy
#include
注意: mencpy函数应该拷贝不重叠的内存 ,memmove函数可以拷贝重叠的内存
C语言规定menmcy只要实现了不重叠的情况拷贝就可以了,而VS中的memmcy中实现了既可以拷贝不重叠,又可以拷贝重叠。
C语言规定重叠拷贝的情况交给memmove处理就可以了。
十二、memmove
假设我们有一个整型数组 1 2 3 4 5 6 7 8 9 10 ,如果我们想要将前5个数字拷贝到第3 - 8个位置上,也就是:
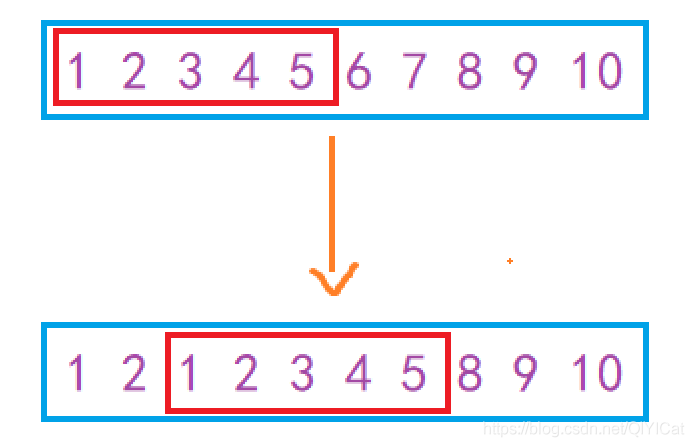
如果我们通过memcpy可以做到吗?试验以下就知道了:
执行前:

执行后:
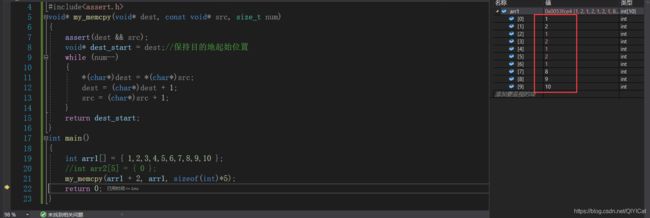
得到的结果是:1 2 1 2 1 2 1 8 9 10并不是我们想要的 1 2 1 2 3 4 5 8 9 10
为什么呢?
从我们刚刚模拟实现memcpy中方法中,我们知道memcpy在进行拷贝的时候,是按照从前往后的方式进行的,如果这个地方按照从前往后的方式进行拷贝,那么拷贝一开始的时候,就会出现后面需要被拷贝的数据被覆盖掉,比如说3,一开始将1放到3这个位置,3就被覆盖掉了,后面如果要拷贝3,从这个位置取出数据的时候,实际上取出的是1。
既然从前往后的拷贝方式不行,那么从后往前拷贝呢?

分析后,可以发现从后向前的拷贝方式是可以的,不会出现后面需要被拷贝的数据提前被覆盖的情况。
但是,如果我们拷贝 3 4 5 6 7 到 1 2 3 4 5的位置上,那么从前往后的拷贝方式还行得通吗?
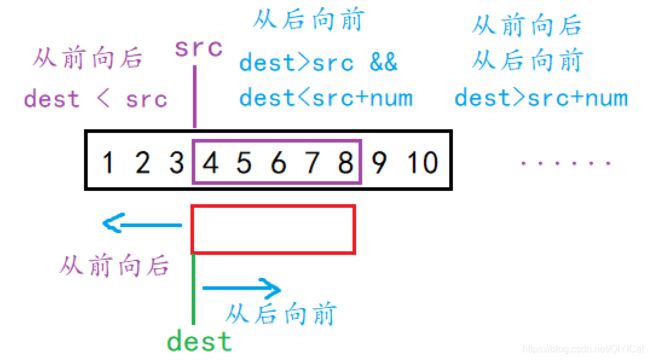
是不是发现从后向前拷贝会出现数据提前被覆盖的情况。所以这时候我们需要进行分情况讨论:
情况一:如果dest在src的右边,如果按照从后往前的方式,就会出现数据提前被覆盖,所以只能按照从前往后的方式拷贝

情况二:如果dest在src的左边且dest不超过src + num(拷贝数据的个数,也就是图中紫色方框的横向长度),如果按照从前往后的方式,就会出现数据提前被覆盖,所以只能按照从后往前的方式拷贝
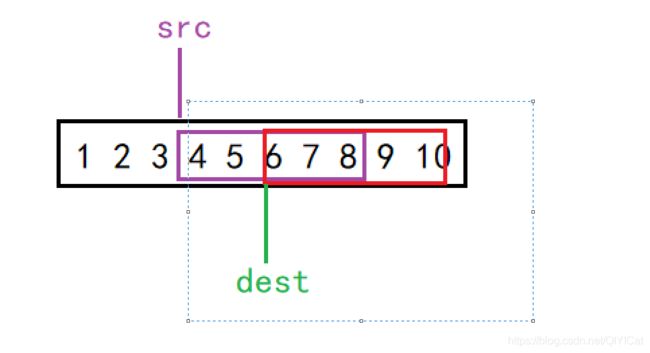
情况三:如果dest > src + num(拷贝数据的个数,也就是图中紫色方框的横向长度),那么无论按照从后向前,还是从前向后的方式,均不会出现数据提前被覆盖的情况,所以两个方式均可以。

为了方便我们实际编程,我们可以将情况二、情况三合并起来,这样就得到:
函数介绍:memmove void* memmove(void* dest, const void* src, size_t count);
头文件:string.h
函数名:memmove
函数参数:
参数1:destination, 类型:char* ,表示内存移动的目的位置
参数2:source,类型:char* ,表示内存移动的起始位置
参数3:count,类型:size_t,表示移动内存字节的个数
函数返回类型: void*, 实际上就是返回destination(目的地)的起始位置
函数功能:内存移动
重点内容
(1)和memcpy的差别就是memmove函数处理的源内存块和目标内存块是可以重叠的。
(2)如果源空间和目标空间出现重叠,就得使用memmove函数处理。
模拟实现memmove函数
#include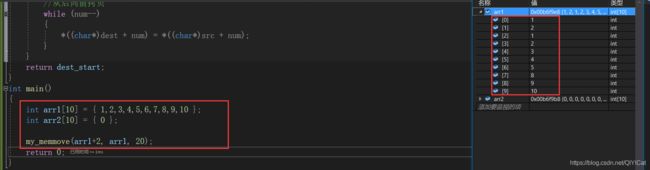
十三、memcmp(简单了解)
int memcmp(const void* buf1, const void* buf2, size_t count);
(1)比较从ptr1和ptr2指针开始的num个字节
(2)返回值如下 :

举例:
#include
十四、memset(简单了解)
作用:Sets buffers to a specified character.(将缓冲区设置为指定的字符)
void* memset(void* dest, int c, size_t count);
相关信息:

以字节为单位设置内存
举例:
#include