目标跟踪 SiamRPN++(SiamRPN++:Evolution of Siamese Visual Tracking with Very Deep Networks)
文章标题:《SiamRPN++:Evolution of Siamese Visual Tracking with Very Deep Networks》
文章地址:(1) https://arxiv.org/pdf/1812.11703v1.pdf、(2) https://lb1100.github.io/SiamRPN++/
github地址:https://github.com/STVIR/pysot
2019年 CVPR 的一篇文章。
作者来自商汤研究院(SenseTime Research),中国科学院自动化研究所(CISIA),中科院计算所(ICT)。
摘要
基于暹罗网络(siamese network)的跟踪器的做法是:对匹配模板和搜索区域各自做卷积后,把得到的特征做互相关(cross-correlation)。然而这类跟踪器与最先进的算法相比仍然存在差距,不能发挥深层网络提取的特征,例如 ResNet-50 或更深的网络。本文我们证明了它的主要原因是没有严格平移不变性(translation invariance)。
( the core reasion comes from the lack of strict translation invariance)
通过全面的理论分析和实验验证,用一个简单且高效的空间感知采样(spatial aware sampling)策略打破了这一限制,成功地训练了一个由 ResNet 所驱动的暹罗跟踪器,获得了显著的性能提升。
另外,我们提出了一个新的模块来进行 layer-wise 和 depth-wise 的汇聚,这不仅提升了准确度,并且减小了模型尺寸。
我们做了广泛的消融实验,证明了我们提出的跟踪器的有效性,在 5 5 5 个大型跟踪基准上取得了最好的成绩:OTB2015,VOT2018,UAV123,LaSOT,TrackingNet。
介绍
视觉目标跟踪在过去的几十年里受到了越来越多的关注,一直是一个非常活跃的研究方向。它在视觉监控、人机交互、增强现实等多个领域有着广泛的应用。尽管最近已经取得了很大的进展,但由于照明变化、遮挡和背景杂乱等因素,仍然被普遍认为是一个非常具有挑战性的任务。
最近基于暹罗网络(siamese network)的跟踪器受到了广泛的关注。它把跟踪任务看做:学习到目标模板和搜索区域的特征表示,把它们进行互相关,学习这个互相关后的一般相似图。为了保证跟踪效率,这个暹罗相似度函数通常是离线学习的,在实际运行的时候就固定住。CFNet 和 DSiam 跟踪器会在线更新模型,分别用了移动平均的模板和快速转换模块。 SiamRNN 引入了区域提议网络(RPN),用在 Siamese network 之后,并且同时用了分类和回归来做跟踪。DaSiamRPN 跟踪器进一步引入了干扰感知模块,提高了模型的辨别能力。
虽然以上的 Siamese 跟踪器取得了很好的跟踪性能,尤其是在精度和速度方面取得了平衡。不过,即使是性能最好的SiamPRN ,在 OTB2015 等基准上的精度与目前最先进的跟踪器仍有显著的差距。我们观察到,所有这些跟踪器都在类似 AlexNet 的架构上构建了自己的网络,并多次尝试使用更复杂的架构(如 ResNet-50)来训练Siamese跟踪器,但没有任何性能增益。基于这样的观察,我们对现有的暹罗追踪器进行了分析,发现其核心原因在于严格平移不变性的破坏。由于目标可能出现在搜索区域的任何位置,因此学习后的目标模板特征表示应该保持空间不变,我们进一步从理论上发现,在现代深度架构中,只有变种的零填充(zero-padding)的 AlexNet 满足这种空间不变限制。
为了克服这种限制,用更深网络来驱动 Siamese 跟踪器,通过广泛的实验验证,我们通过引入了一种简单且高效的采样策略来打破这种空间不变性(spatial invariance)的限制。我们用 ResNet 作为骨干(backbone)来训练一个基于 SiamRPN 的跟踪器,获得的显著的性能提升。得益于 ResNet 的架构,我们为互相关操作(cross-correlation)提出了一种layer-wise 的特征汇聚结构,帮助跟踪器从多级网络中学习到的特征来预测相似度(similarity map)。通过分析用于互相关(cross-correlation)的暹罗网络结构,我们发现两条网络支路在参数量方面非常不平衡,于是我们进一步提出了深度可分离互相关结构(depth-wise separable correlation),这不仅极大地减少了目标模板支路的参数量,而且使得整个模型的训练过程更加稳定。另外,我们还发现了一个有趣的现象,同一类的目标在相同的通道上会得到较高的响应,其余的通道会被抑制。正交性质也会提高跟踪器的性能。
总地来说,我们的主要贡献如下:
∙ \bullet ∙ 对 Siamese 跟踪器进行了深入的分析,证明了使用更深的网络时准确度的下降,是由于破坏了平移不变性。
∙ \bullet ∙ 提出了一种简单而有效的采样策略来打破空间不变性限制,成功地训练了由 ResNet 架构驱动的 Siamese 跟踪器。
∙ \bullet ∙ 提出了一种 layer-wise 的特征聚合结构来进行互相关(cross-correlation)操作,帮助跟踪器从多级特征中预测相似性图(similarity map)。
∙ \bullet ∙ 提出了一种深度可分离互相关(depth-wise separable correlation)结构来增强互相关,产生多个不同语义的相似图(similarity map)。
基于上述理论分析和技术贡献,我们开发了一种高效的更正模型,在跟踪准确度上达到了最先进的水平,以 35 FPS 35\text{FPS} 35FPS 的速度运行。我们取名为 SiamRPN++ \text{SiamRPN++} SiamRPN++,我们用 MobileNet 做了一个变种,不仅很快,性能也很能打,运行速度达到 70 FPS 70\text{FPS} 70FPS。为了促进研究,代码和训练好的模型也开源了。
相关工作
引文还蛮多的,自己看。
Siamese Tracking with Very Deep Networks
(用很深的网络来做暹罗跟踪)
本文最重要的一个发现是,如果使用更深的网络,基于暹罗网络的跟踪算法的性能可以显著提高。但是,简单滴用更深的网络(如 ResNet)是不行的,达不到预期。我们发现这和暹罗跟踪器的内在限制有关。所以我们先对暹罗网络进行深入的分析。
Analysis on Siamese Networks for Tracking
基于暹罗网络的跟踪算法把视觉跟踪任务看做一个互相关(cross-correlation)的问题,它用一个结构为暹罗网络的深度模型,从中学习跟踪相似度图。一个支路学习跟踪目标模板的特征表示,另一个支路学习搜索区域的特征表示。目标模板的图片一般从序列第一帧选取,用 z \textbf{z} z 表示。要在语义特征嵌入空间 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) 中,从后续视频帧 x \textbf{x} x 中找到最相似的范例: f ( z , x ) = ϕ ( z ) ∗ ϕ ( x ) + b (1) f(\textbf{z}, \textbf{x}) = \phi(\textbf{z}) * \phi(\textbf{x}) + b \tag{1} f(z,x)=ϕ(z)∗ϕ(x)+b(1) 其中 b b b 用来建模相似值的偏移(model the offset of the similarity value)。
在设计暹罗跟踪器时,这个简单的匹配函数天然地隐含了两个内在的限制。
∙ \bullet ∙ 特征提取部分和收缩部分对于平移不变性存在内在性约束(The contracting part and the feature extractor used in Siamese trackers have an intrinsic restriction for strict translation invariance): f ( z , x [ △ τ j ] ) = f ( z , x ) [ △ τ j ] f(\textbf{z},\textbf{x}[\triangle\tau_j]) = f(\textbf{z},\textbf{x})[\triangle\tau_j] f(z,x[△τj])=f(z,x)[△τj],其中 [ △ τ j ] [\triangle\tau_j] [△τj] 是平移子窗口操作(translation shift sub window operator),保证了训练和推理的有效性。
∙ \bullet ∙ 收缩部分(contracting part)对于结构对称性(structure symmetry)存在内在性约束(intrinsic restriction)。例如 f ( z , x ′ ) = f ( x ′ , z ) f(\textbf{z}, \textbf{x}') = f(\textbf{x}',\textbf{z}) f(z,x′)=f(x′,z),这是适合做相似学习的(which is appropriate for the similarity learning)。
经过详尽的分析,我们发现用不了深层网络的核心原因在于两个方面。具体来说,一个原因是 padding 会破坏平移不变性。另外一个是, RPN \text{RPN} RPN 需要非对称(asymmetrical)的特征来做分类和回归。我们将引入空间感知的采样策略来应对第一个问题,第二个问题在后面章节讨论。
只有在没有 padding 的网络中,才符合严格的平移不变性(strict translation invariance),例如改造过的 no-padding 的 AlexNet。先前大家用的暹罗跟踪网络都比较浅,所以符合这种限制。如果我们用 ResNet、MobileNet 等现代网络,为了使网络更深,会不可避免地用到 padding,这将破坏平移不变性。我们的假设是,违反了这一点会导致空间偏差。
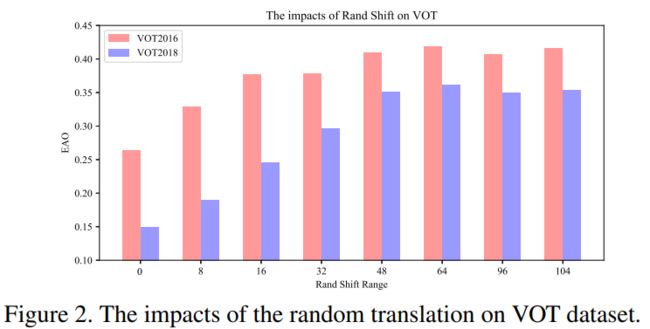
我们在一个没有 padding 的网络上进行模拟实验来证明我们的假设。我们把漂移(shift)定义为:在数据增强中,均匀分布产生的最大平移范围(max range of translation generated by a uniform distribution in data augmentation)。我们的实验如下。首先,把目标放在中心,分别设置 3 3 3 个漂移范围( 0 0 0, 16 16 16, 32 32 32)进行 3 3 3 次训练实验。收敛后,将测试数据集生成的热图进行汇总,结果如图(1)所示。

在第一个实验中,shift 量为 0 0 0,在边界处预测概率降至零。这表明无论测试目标的外表是什么,都学到了一个强力的中心偏置。另外两个实验表明增加漂移(shift)的范围可以逐渐防止模型崩塌为这种没有用的解。定量结果表明,shift 为 32 32 32 的汇聚热力图更接近测试对象的位置分布。实验证明,该采样策略有效地缓解了没有 padding 的网络对平移不变性的破坏。
为了防止在目标上产生一个强烈的中心偏置,我们用空间感知采样策略(spatial aware sampling strategy),用 ResNet-50 作为骨干来训练 SiamRPN,通过在搜索图上进行均匀分布来采样匹配目标。如图(2)所示,在 VOT2018 上零漂移(zero shift)的性能下降到了 0.14 0.14 0.14,合适漂移( ± 64 \pm64 ±64像素)对于训练深度暹罗跟踪器至关重要。
ResNet-driven Siamese Tracking
基于上述分析,可以消除中心偏差的影响。一旦我们消除了学习到的对于中心位置偏差,任何现成的网络(例如 MobileNet, ResNet 等)都可以迁移学习用来跟踪。另外,我们可以自适应地构造网络拓扑结构,发挥深度网络的性能。
这一小节将会讨论如何把深度神经网络搞到我们的跟踪算法里。特别地,我们的实验主要集中在 ResNet-50 上。原本的 ResNet-50 下采样倍率很大,Stride 为 32 32 32 个像素,对于我们的任务(dense Siamese network)是不太合适的。

如图(3)所示,我们修改了 c o n v 4 conv4 conv4 和 c o n v 5 conv5 conv5 中的东西,使整个网络的下采样倍数(stride)为 8 8 8。
(原本经过 c o n v 4 conv4 conv4 之后是 16 16 16 倍,经过 c o n v 5 conv5 conv5 之后是 32 32 32 倍了)
同时通过空洞卷积(dilated convolutions)来增加感受野(receptive field)。再加一个 1 × 1 1 \times 1 1×1 的卷积层把每一个 block 的输出通道数降至 256 256 256。
由于每一层都保留着 padding,模板特征的空间尺寸增至 15 15 15,这么大的面积对于相关(correlation)的计算带来较大的负担。于是我们裁剪出中间的 7 × 7 7\times7 7×7 的区域当做模板特征,其中每个格子仍然能捕捉整个目标区域。
像 SiamRPN 那样,我们用互相关层和全卷积层来组成网络头,用于计算分类得分(记为 S \mathcal{S} S)和包围框回归(记为 B \mathcal{B} B)。Siamese RPN 块记为 P \mathcal{P} P。
进一步地我们发现微调的 ResNet 能够提升性能。把 ResNet 特征提取器的学习率设置为 RPN 部分的 1 / 10 1/10 1/10,使特征表示更适合跟踪任务。与传统的 Siamese 方法不同,深度网络的参数可以一起进行端到端的训练。据我们所知,端到端地训练一个这么深的网络,用于跟踪任务的,我们是第一个。
Layer-wise Aggregation
利用了深度网络之后,我们可以把不同深度的层聚合起来。直观地讲,视觉跟踪任务需要丰富的表示,从低层次到高层次,从大尺度到小尺度,从细到粗的分辨率。尽管卷积网络有的深度特征,但是一个孤立的层是不够的,混合、汇聚这一些特征表示,能够提高 recognition 和 localization 的推理。
在先前的工作中,用的是一些比较浅的网络,像 AlexNet ,那些网络的多级特征并不能提供非常丰富的特征表示。而 ResNet 中的不同层会更有意义,因为感受野的变化很大。在前面那些层主要关注的是较低层次的信息,例如颜色、形状等,这是定位(localization)所必须的,不过缺乏语义信息。后面几层的特征含有更丰富的语义信息,在一些具有挑战性的场景中,如运动模糊、巨大变形,这可能是有益的。使用这种丰富的层次信息是为了帮助跟踪。
在我们的网络里,通过提取多个分支的特征来协同进行目标定位。对于 ResNet-50,我们从最后 3 3 3 个残差块中提取的多级特征来做 layer-wise 的汇聚。我们将这几个输出分别称为 F 3 ( z ) \mathcal{F}_3(\textbf{z}) F3(z), F 4 ( z ) \mathcal{F}_4(\textbf{z}) F4(z), F 5 ( z ) \mathcal{F}_5(\textbf{z}) F5(z)。如图(3)所示, c o n v 3 conv3 conv3, c o n v 4 conv4 conv4, c o n v 5 conv5 conv5 的输出被分别放进 3 3 3 个 Siamese RPN 模块。
由于 3 3 3 个 RPN 模块输出的空间分辨率尺寸是一样大的,因此直接对 RPN 的输出做加权和。 S a l l = ∑ l = 3 5 α i ∗ S l , B a l l = ∑ l = 3 5 β i ∗ B l (2) \mathcal{S}_{all} = \sum^5_{l=3} \alpha_i * \mathcal{S}_l \;,\quad \mathcal{B}_{all} = \sum^5_{l=3} \beta_i * \mathcal{B}_l \tag{2} Sall=l=3∑5αi∗Sl,Ball=l=3∑5βi∗Bl(2)
由于作用域不同,分类的结合权重和回归的结合权重是不一样的。这个权重也随着网络进行离线的端到端训练。
与之前的工作相比,我们的方法没有明确地把卷积特征相结合,而是分别学习分类器和回归。值得注意的是,随着骨干网深度的显著增加,我们可以从视觉-语义层次结构的多样性中获得实质性的收益。
Depthwise Cross Correlation

互相关(cross correlation)模块是一个关键的操作,它将两条支路的信息相嵌起来。
SiamFC 利用互相关操作获得单个通道的响应图,用于目标的定位。
SiamRPN 添加了一个很大的卷积层(UP-Xcorr)将互相关进行扩展,以嵌入更高级别的信息(例如anchor)。但是他的 up-channel 模块太大,造成参数分布严重不平衡(RPN 模块的参数量是 20 M 20\text{M} 20M,而特征提取器只有 4 M 4\text{M} 4M)。使得训练优化很困难。
本小节将介绍一个轻量级的互相关层,称为深度互相关(Depthwise Cross Correlation,DW-XCorr),为了使信息关联更有效率,DW-XCorr 层的参数量比 SiamRPN 中的 UP-Xcorr 要少 10 10 10 倍,性能与之相当。
为了做到这一点,我们用了 conv-bn 块来调整每个残差块输出的特征,使其适应跟踪任务。基本上,包围框的预测和 anchor based 的分类都是对称的,这与 SiamFC 不同。为了对差异进行编码,模板支路和搜索支路经过两个不共享权重的卷积层。然后两个特征图具有相同的通道数,在每个通道上各自做互相关,再用一个 conv-bn-relu 层来融合不同通道的输出。最后,再加上分类头和回归头。
通过将交叉互相关(cross-correlation)操作替换为深度互相换(depthwise correlation),可以显著地减少计算量和内存。这样的话,模板分支和搜索分支的参数量取得了平衡,使得训练过程更加稳定。
我们还发现了一个有趣的现象,如图(5)所示。
同一类的物体在相同的通道上具有较大的响应(车子在第 148 148 148 通道,人在第 222 222 222 通道,人脸在第 226 226 226 通道),而其它的通道会被抑制。这种特性可以被压缩,因为 depth-wise cross correlation 操作几乎是正交的,每个通道代表一些语义信息。我们同样分析了用 up-channel cross correlation 产生的热力图,它的响应图的可解释性较差。
实验
数据集与评价
Training
我们用的 backbone 是在 ImageNet 上预训练过的,经过证明,用这个权重来初始化其它任务是很好的。我们用 COCO、ImageNet DET、ImageNet VID、YouTube-BoundingBoxes 这几个数据集来训练,对于跟踪任务,让我们的网络学习一种概念,来度量两个目标之间的相似性。在训练和测试中,我们用的目标(template)图的尺寸是 127 127 127 像素,搜索(search)图的尺寸是 255 255 255 像素。
Evaluation
我们用 OTB-2015、VOT2018、UAV123 来关注短期的单目标跟踪任务。在 VOT2018-LT 来评估长期跟踪性能。在长期跟踪中,目标可能长时间离开视场或完全被遮挡,这比短期跟踪更具挑战性。我们还分析了我们的方法在LaSOT 和 TrackingNet 上的泛化性,这两个数据集是近年两个最大的单目标跟踪基准。
实现细节
Network Architecture
实验部分我们按照 DaSiamRPN 的设置进行训练和推理。我们在这个降低了下采样倍数的 ResNet-50 上添加了两个卷积层来对 5 5 5 个 anchors 做 classification 和 bounding box regression。在 conv3、conv4、conv5 上各用一个 1 × 1 1\times1 1×1 的卷积层把特征维度降至 256 256 256。
Optimization
优化器用的 SGD,在 8 8 8 个 GPU 上训练,每个 minibatch 是 128 128 128 pairs 的图片(每张 GPU 上 16 16 16 对)。训练 12 12 12 个小时后收敛。前 5 5 5 个 epoch 用 0.001 0.001 0.001 的 warmup 学习率来训练 RPN 支路,后面 15 15 15 个 epoch 整个网络的学习率从 0.005 0.005 0.005 指数衰减到 0.0005 0.0005 0.0005。momentum 为 0.9 0.9 0.9。regression 的损失是标准的 smooth L 1 L_1 L1 损失,训练损失是分类和回归损失的总和。
消融实验
Backbone Architecture
特征提取器的选择至关重要,因为参数的数量和层的类型直接影响跟踪器的内存、速度和性能。我们比较了不同的模型结构,图(6)展示了用 AlexNet、ResNet-18、ResNet-34、ResNet-50、MobileNet-v2 作为骨干的性能。我们在 OTB2015 上用成功率的 AUC (Area Under Curve) 作为纵坐标,用 ImageNet 上的 top1 accuracy 作为横坐标,来报告他们的性能。我们观察到 SiamRPN++ 能够从更深的网络中受益。

表1也表明了从 AlexNet 换成 ResNet-50 后,在 VOT2018 上的性能提升了不少。另外,我们的实验表明对网络骨干部分进行精调是很关键的,能极大地提升跟踪性能。

Layer-wise Feature Aggregation
为了探究 layer-wise 特征汇聚的影响,我们用 ResNet-50 训练了 3 3 3 个变体,它们都只用单个 R P N RPN RPN。我们发现只对 c o n v 4 conv4 conv4 用 RPN 就能达到很有竞争力的性能,得到 0.374 0.374 0.374 的 EAO,而深一层或者浅一层都会变差,性能会掉 4 % 4\% 4%。 如果用两个分支, c o n v 4 conv4 conv4 和 c o n v 5 conv5 conv5 结合能得到提升,结合另外两个则没有提升。尽管如此,robustness 还是提升了 10 % 10\% 10%,这是我们跟踪器的主要缺陷。将 3 3 3 个 c o n v conv conv 都结合起来的话,accuracy 和 robustness 都得到稳定的提升,在 VOT 和 OTB 上提升了 3.1 % 3.1\% 3.1% 和 1.3 % 1.3\% 1.3%。总的来说,做了 Layer-wise Feature Aggregation 之后,在 VOT2018 上取得 0.414 0.414 0.414 的 EAO,比单个 layer 高 4.0 % 4.0\% 4.0%。
Depthwise Correlation
和 UP-Channel Cross Correlation 相比,我们的 depthwise correlation 在 VOT2018 上提高了 2.3 % 2.3\% 2.3%,在 OTB2015 上提高了 0.8 % 0.8\% 0.8%,如表(1)所示。这在一定程度上是因为两个分支的平衡参数分布使学习过程更稳定,收敛性更好。