数据中台(八) 数据建设
数仓层建设
统一数仓层站在业务的视角,不考虑业务系统流程,从业务完整性的角度重新组织数据,统一数仓层的目标是建设一套覆盖全域、全历史的企业数据体系,利用这套数据体系可以还原企业任意时刻的业务运转状态。
数仓建设步骤

1.划分数据
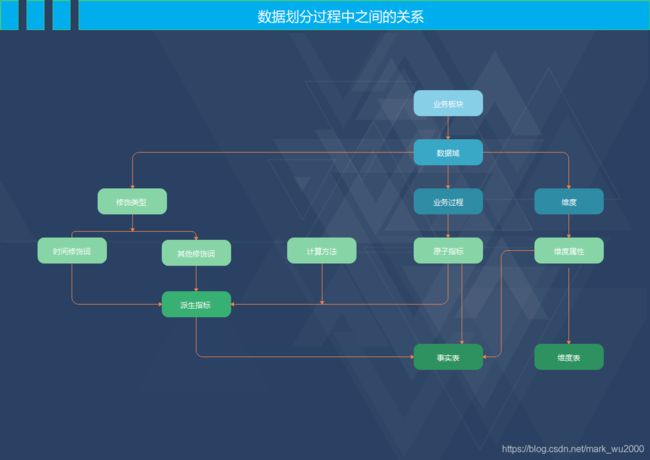
划分数据主要包括业务板块、数据域、业务过程,并对它们对它们进行标准命名,包括英文名称、中文名称、英文简称。


2.构建总线矩阵
总线矩阵的每一行对应都对应机构中的一个业务过程,每一列都和一个业务维度相对应,用叉号填充显示的是和每一行相关的列。

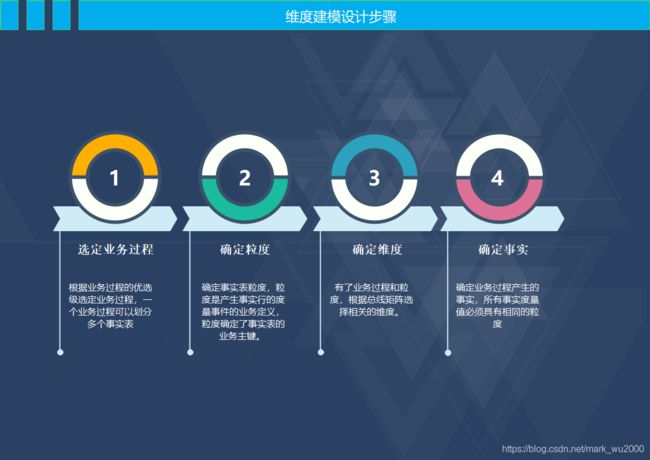
3.设计数据模型
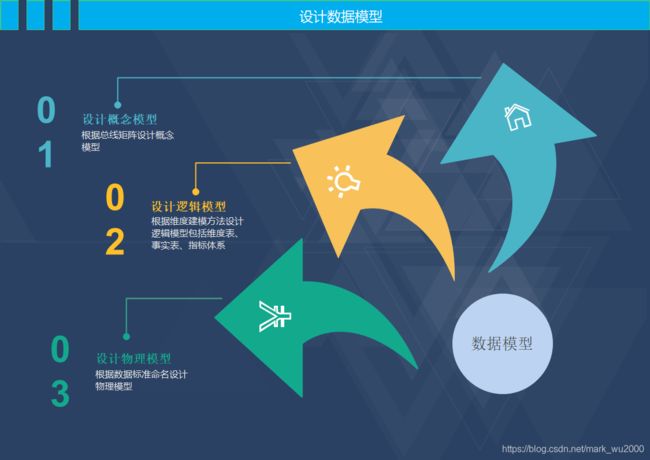
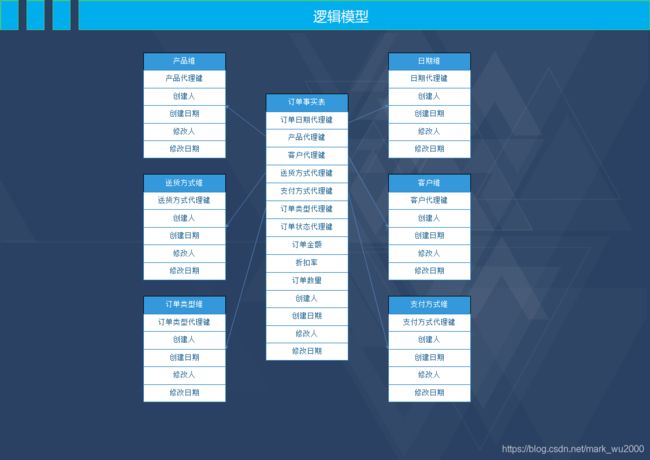
维度表:维度表是对业务过程的上下文描述,主要包含代理键、文本信息和离散的数字。它是进入事实表的入口,丰富的维度属性给出了对事实表的分析切割能力,它一般是行少列多。
事实表:事实表存储了从业务活动或事件提炼出来的性能度量,它主要包含维度表的外键和连续变化的可加性数值或半可加事实。事实表产生于业务过程中而不是业务过程的描述性信息。它一般是行多列少,占了数据仓库的90%的空间。
指标:指标是业务过程中产生的度量事实。它分为原子指标和派生指标。
原子指标:原子指标是基于某一业务事件行为下的度量,是业务定义中不可再拆分的指标,是具有明确业务含义的名词,体现明确的业务统计口径和计算逻辑。原子指标=业务过程+度量
派生指标:派生指标是对原子指标业务统计范围的圈定。派生指标=时间周期+修饰词+原子指标+计算方法
修饰词:修饰词是除统计维度以外的对指标进行限定抽象的业务场景词语,修饰词隶属于一个修饰类型。修饰类型是限定条件的字段名称,不包括时间区间,修饰词就是字段的值。
计算方法:计算方法是指标的数学计算方式,比如汇总、平均、最大、最小等。
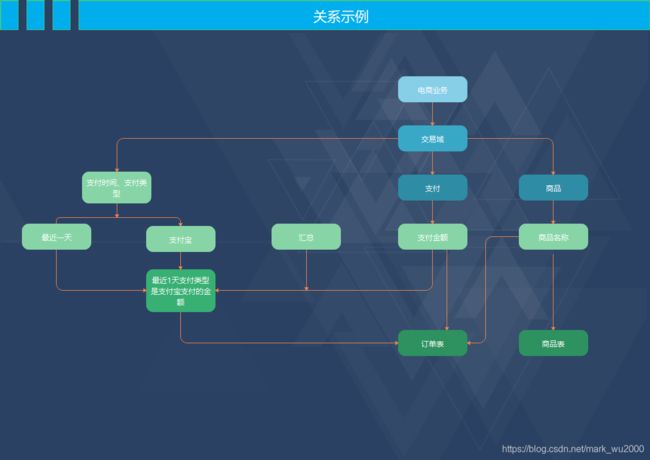
例如:最近1天支付类型是支付宝支付的金额。

4.数据开发
1.数据映射详细设计
通过元数据产品或文档的形式记录目标表和源表的映射关系和转换规则,主要包括源表的元数据信息和目标表的元数据信息。
2.代码开发

3.配置调度任务

4.数据测试

5.代码发布
按照规范流程提交代码,进行发布。
6.数据验证
开发人员和业务人员共同验证数据是否符合预期。
标签层建设
标签层建设,一方面让数据变得可阅读、易理解,方便业务使用;另一方面通过标签类目体系将标签组织排布,以一种适用性更好的组织方式来匹配未来变化的业务场景需求。
标签是利用原始数据,通过一定的加工逻辑产出,能够为业务所直接使用的可阅读、易理解,有业务价值的数据。

标签层建设步骤

1.确定对象
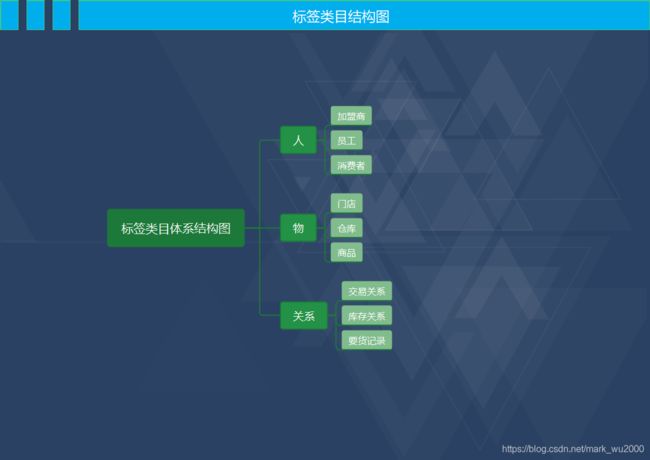
确定哪类对象需要建设标签,对象是客观世界研究目标的抽象,对象有实体的,也有虚拟的。可把对象分为人、物、关系三大类。
2.设计标签体系
标签类目:是标签的分类组织方式,是标签信息的一种结构化描述,目的是管理、查找标签,一般采用多级类目。
标签类目体系:是对业务所需标签采用类目体系的方法进行设计、归属、分类。具体的人、物、关系对象为根目录,根目录下可以设置类目结构,类目结构通常分为一级类目、二级类目、三级类目等。
1.设计标签类目体系结构
按照人、物、关系把对象进行分类、汇总,形成企业的标签类目体系结构图。
2.设计标签类目体系
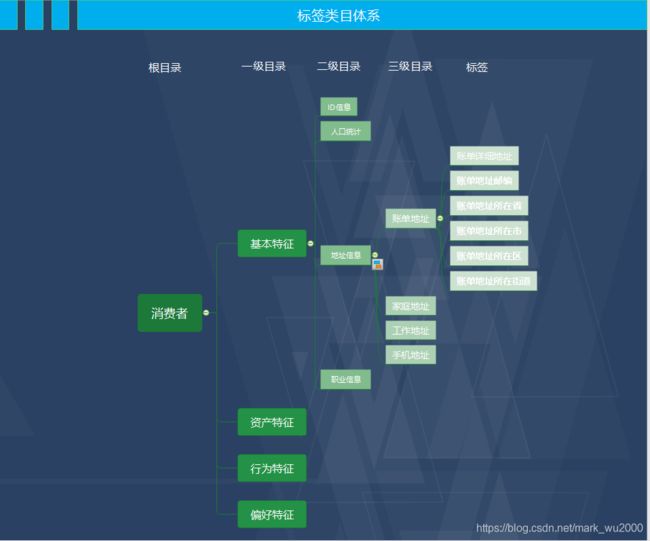
2.设计标签
根据业务需求和数仓数据现状进行调研分析形成标签设计文档。下图是客户的标签设计文档:

3.标签标准模型设计
标签物理模型一般按照标签类目和标签数量均衡拆分成多个物理表,比如根据客户的二级目录进行拆分,拆分成ID信息表、人口统计表、地址信息表、职业信息表。
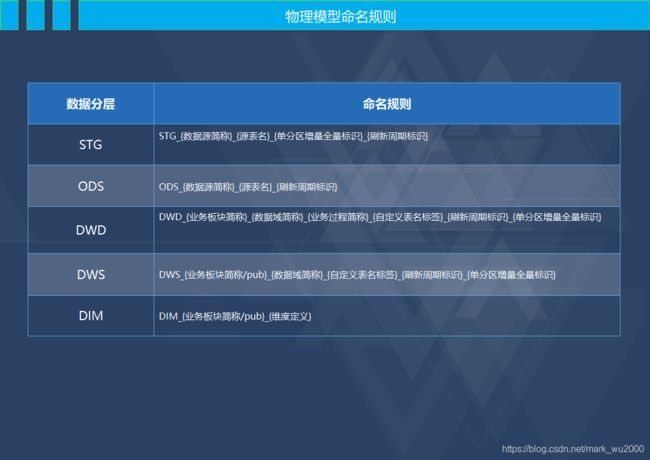
数据库表名命名规则:TDM_{根目录简称}_{一级目录简称}_{二级级目录简称}_{刷新周期标识}_{单分区增量全量标识}
4.数据开发
1.数据映射详细设计
2.代码开发
通过ID-Mapping技术将同一个具体对象的不同ID标识打通,形成SUPER_ID,完成对该对象的全面数据的刻画。
3.配置调度任务
4.数据测试
5.代码发布
按照规范流程提交代码,进行发布。
6.数据验证
开发人员和业务人员共同验证数据是否符合预期。
应用层建设
应用数据层是按照业务使用的需要,组织已经加工好的数据以及一些面向业务的特定个性化指标加工,以满足最终业务应用的场景。它是构建在统一数仓层与标签数据层之上。
应用层建设步骤

1.物理模型设计
根据数据服务需求设计物理模型,主要以宽表、K-V表等形式组织。
数据库表名命名规则:ADS_{业务板块简称/pub}_{数据域简称}_{业务应用简称}_{自定义表名标签}_{刷新周期标识}
2.数据开发
1.数据映射详细设计
2.代码开发
根据统一数仓层与标签数据层进行关联查询落地成数据应用层表,还有根据不同的业务场景,同步到不同的存储介质上。
3.配置调度任务
4.数据测试
3.代码发布
按照规范流程提交代码,进行发布。
4.数据验证
开发人员和业务人员共同验证数据是否符合预期。
服务层建设
数据资产只有形成数据服务被业务所使用,才能体现其价值。数据服务需要抽象成可管理、可复用、可监控的统一标准下的数据服务体系。
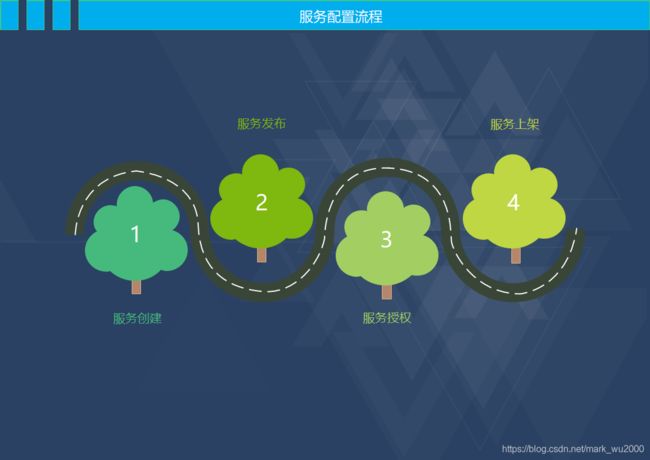
常见的服务构建过程
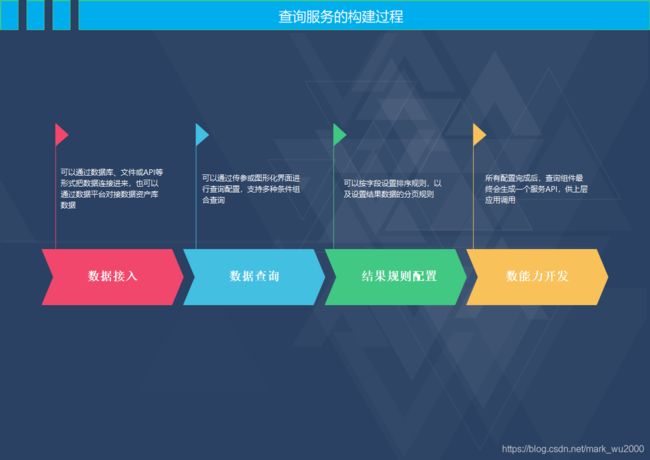
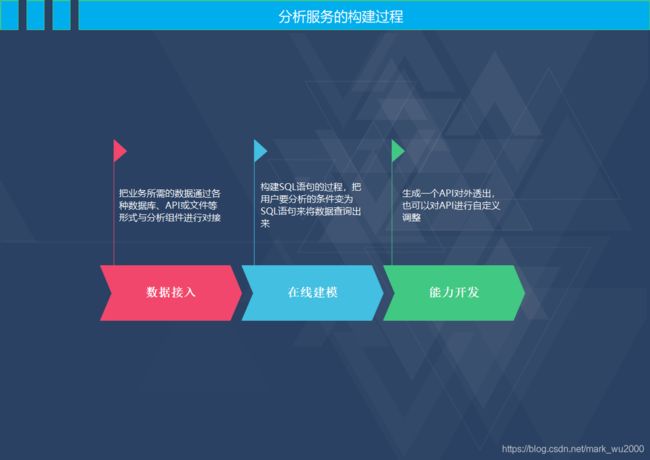
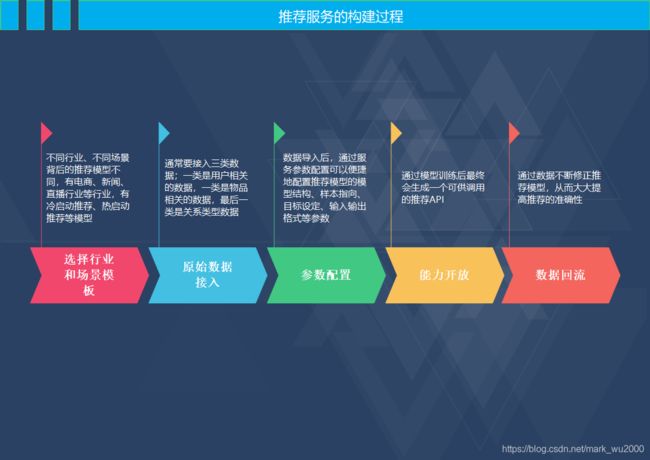
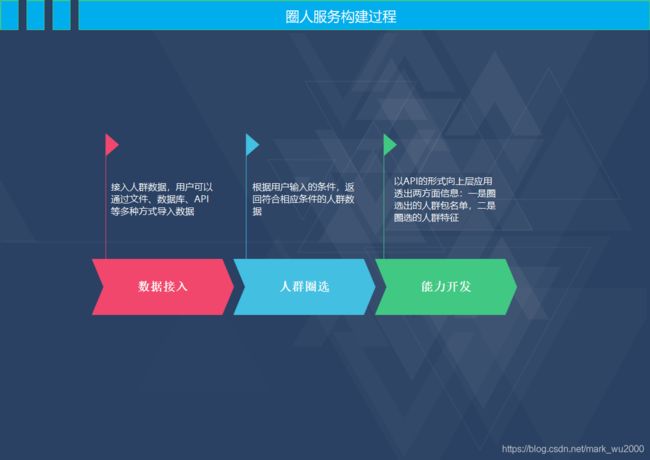
服务配置流程